
函数调用路径测试用例自动生成的方法研究
2020-09-15 04:48牟永敏
计算机工程与应用 2020年18期
沈 晴,牟永敏
北京信息科技大学 计算机学院,北京 100101
1 引言
软件测试可以提高软件的可靠性[1]。在软件开发周期,软件测试是软件开发过程中不可或缺的环节,如果利用人工的方法实现测试需求,会耗费大量人力物力,所需成本占比高达50%以上,因此研究人员致力于实现自动化测试,降低软件测试成本。随着软件规模日趋大型化和复杂化,及时发现并修复软件中存在的错误可以很大程度上避免软件使用过程中发生故障带来的损失,但同时也给软件测试带来进一步的挑战,自动化测试的重要性日益凸显。其中,测试用例对保证软件测试的充分性和可靠性有着重要影响,一组合理的测试用例可以帮助测试人员找出程序中的错误。人工设计测试用例需要测试人员具备丰富的经验,且不可避免地受到人为因素影响,可能无法保证测试的充分性,因此,测试用例自动生成技术对提高软件测试的效率有着重要意义。根据测试方法的不同,可以分为四大类型:随机测试方法、基于搜索的测试方法、模型检测测试方法以及符号执行测试方法[2]。
1983年Bird等人[3]提出随机法,易于实现且十分高效,一些研究会将它作为基准方法之一[4],但对于较为复杂的程序,随机法很难达到较高的覆盖率。为保证测试用例均匀地分布在搜索空间,提出自适应随机测试方法[5],但覆盖率低的问题依然存在。基于搜索的测试用例自动生成方法[6]将测试用例自动生成问题转化为函数优化问题,并利用遗传算法[7]、粒子群优化算法[8]、蚁群算法[9]以及一些优化后的进化算法[10]等来寻找最优解。但同样存在总体覆盖率较低的问题,并且很大程度上受限于适应度函数,容易进入局部最优解中,尤其在大型复杂程序中效果不理想,会产生大量冗余用例。模型检测方法是一种形式化验证方法,包括许多的验证技术[11],通过模型检测器搜索整个系统的状态空间,根据生成的反例分析识别并修复软件中的错误,但是模型创建难度较大,不同的模型的效果差异较大,并且由于状态爆炸问题会导致性能下降。
符号执行是King[12]于1976 年提出的一种重要的形式化方法和程序分析技术,被广泛应用于程序测试领域[13]。采用抽象符号代替程序变量,程序计算的输出被表示为输入符号值的函数,根据程序的语义,遍历程序的执行空间,符号执行技术能够以尽可能少的测试用例实现高覆盖率,从而挖掘出复杂软件程序的深层错误,但在实际应用中不可避免地会遇到许多限制条件,如路径爆炸、约束求解等问题。
在此基础上,本文将研究粒度提升至函数,用函数调用路径图替代控制流图,从函数层面分析程序执行过程,提出一种基于函数调用路径的测试用例生成方法,分析程序抽象语法树得到函数调用关系和执行路径,结合符号执行技术生成与函数调用路径对应的全局测试用例集。该方法类似于状态合并,将语句块合并,且最大程度保留程序信息。实现在不降低测试覆盖率的同时,提高符号执行的效率。
2 相关研究
2.1 路径覆盖测试技术
路径覆盖是软件测试充分性的一个重要准则[14],可归结为面向路径的测试数据生成问题[15],核心是选取最小测试用例集,覆盖程序的所有可执行路径(如果程序图中有环,则要求每个环至少经过一次)。
2.1.1 基路径分析方法
由于完整路径集合数量过于庞大,在实际中很难实现,因此基本路径测试方法应运而生。基于基路径的软件测试是一种缩小规模的路径测试技术,最小化路径组合的数量,减少重复测试的次数,使路径测试得以实现。
目前基路径分析主要算法有McCabe法[16]、Halstead法等。
2.1.2 函数调用路径分析方法
基本路径覆盖测试在一定程度上缩小了路径的数量,但其路径数量会随着程序的规模和复杂度的增大呈指数增长,使得精确率不甚理想,对循环结构带来的在路径数量上的影响以及重叠路径识别的处理方法仍存在一定缺陷。
面向函数调用路径的思想是在回归测试和路径覆盖测试基础上发展起来的,简化了面向基路径的测试缺陷,使得面向基路径的测试工作量大幅减少。基于函数调用关系的路径覆盖测试技术以路径覆盖为基础,将函数调用与控制逻辑结合起来,把路径单元从语句提升至函数,通过对被测程序的源代码进行静态和动态分析,分别获取包含控制逻辑的静态函数调用路径以及动态函数调用序列,将动态获取的序列转化成静态逻辑路径,建立测试用例和路径上的对应关系[17]。
2.2 符号执行技术
符号执行自提出以来,经过了传统符号执行、动态符号执行、选择性符号执行三个发展过程[18],但仍存在一些困难。
路径爆炸问题是制约符号执行在现实程序分析中应用的主要因素。在符号执行的分析过程中,每个分支节点都会衍生出两个符号执行实例,就串行程序而言,一个具有n个条件语句的程序段就有可能包含2n条路径。
目前已有状态合并、冗余路径剪枝、采用启发式搜索方法对程序路径空间进行搜索以及优化回归测试集等方法缓解路径爆炸问题,但仍存在一些问题,比如状态合并会一定程度上影响程序分析的准确性;启发式搜索在面临长路径搜索时,路径的计算和筛选需要耗费较长时间,且可能无法得到符合的路径。
3 基于函数调用关系的路径优化
目前能够生成函数关系图的工具,如CallTree、Codeviz、Source Insight、DGML 等,生成的函数调用关系并不包含控制逻辑,属于函数包含关系图;另一类工具,如 AlgoView、GNU CFlow 等,基于语句的分析,同样不能得到函数粒度的调用路径。
文献[19]对比了正则技术、开源工具以及语法树三种提取函数调用关系的方法。对于正则技术,通过多次扫描源代码以匹配函数调用相关信息,获取函数调用关系。对于开源工具,通过CTags和Cscope获取并解析代码树中的索引,生成基于函数调用的依赖关系,获取函数调用信息。语法树主要是通过Yacc 和Lex 构建语法树来提取函数调用关系。从准确率上说,三者中基于语法树的提取方法效果最佳,因此本文基于抽象语法树提取函数关键信息。

图1 函数调用路径生成过程
3.1 整体框架
提出一种函数调用路径静态提取方法,通过分析抽象语法树和字节码序列,得到函数间的依赖关系以及相应的控制条件;设计关键信息提取算法,获取函数调用关系,从而构建函数调用关系模型;以函数为节点,同时结合程序控制条件,生成包含控制信息的函数调用关系图,如图1所示。
3.2 函数调用路径生成
3.2.1 相关定义
定义1(函数调用关系)指两个函数之间的调用,用R表示,其中R={(Fi,Fj)|Fi是源函数,Fj是被调用的函数} 。如果在源函数中存在多个函数调用,则按调用的先后顺序表示调用关系,如R={(F0,F1),(F1,F2 )},表示源函数中的函数调用关系为F0 →F1 →F2。
定义2(函数调用关系模型)表示单个函数的函数调用关系,用三元组T(M,R,S)表示,M是函数集合,R表示函数间的调用关系,S表示源函数。
图2代码段中main函数,用函数调用关系模型T(M,R,S)表示,其中M={main,f1,f2,f3},R={(main,f1,O),(f1,f2,O),(f2,f3,B)},S={main},O表示顺序调用,B表示分支调用。

图2 示例源代码
定义3(函数调用路径)根据函数调用关系得到的由程序入口到出口的一个函数名序列,表示为Pi={Fi1,Fi2,…,Fim},Fij为函数名,Fij和Fij+1的关系表示为顺序执行或Fij调用Fij+1[20]。
定义4(函数调用路径集)函数调用路径的集合,表示为B(S,C)={P1,P2,…,Pn},C是函数调用关系准则,用来判断函数是否被调用以及函数以何种方式被调用。例如:v1=F(x),其中v1表示变量,F(x)表示函数;语句v1=F(x),表示将函数F(x)返回值赋值给v1,故该语句以函数返回值参与表达式运算的方式调用函数,S是源代码,Pi是函数调用路径[21]。
定义5(函数调用路径图)表示为一个有向图FCG(V,R),V是FCG中所有节点的有穷非空集合,R是相连节点之间边的有限集合,满足R⊆V×V,具体描述如下:
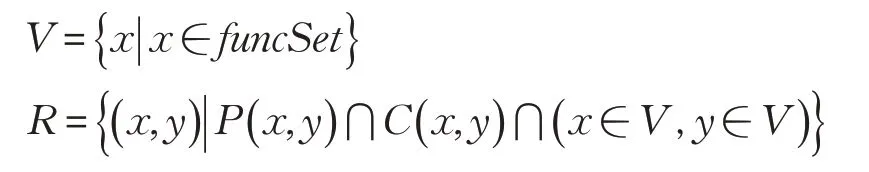
其中,funcSet是函数调用路径图中的节点集合;R是函数调用路径图中节点之间的关系集合,P(x,y)表示从x到y的一条通路,C(x,y)表示从x到y通路上的控制条件。
3.2.2 函数关键信息抽取
以Python语言为例,抽象语法树是一个深层嵌套的树形结构,鉴于需要对不同类型节点进行不同的处理,本文采用访问者模式实现对抽象语法树的遍历,使节点类与作用于自身的操作相互独立。
步骤1访问者从抽象语法树根节点开始对抽象语法树中的关键节点类型进行遍历,基本关键节点类型如表1所示。

表1 基本关键节点类型
步骤2判定节点类型是否为关键节点类型。
步骤3如果节点类型是关键节点类型,则通过抽象访问者进行转发,直接访问具体访问者visit_Key(node),(如visit_Assign(node)是基于赋值关键字的访问者)。提取相应的关键信息;反之,则调用通用访问者,统一处理。
步骤4对提取到的所有信息进行约减和自动补全,得到生成函数调用关系所需的关键信息列表。
其中,关键节点类型具体算法描述如下:
算法1关键信息抽取算法
输入:抽象语法树文本AST Text
输出:关键信息列表KeyInfoList,函数字典FuncInfoDict
1.Begin
2.tree<-AST Text;//获取 ast对象

表2 分支语法结构-关系模型
3.FOR node in tree DO //遍历每一个节点
4.type<-node.type;//根据节点类型,调用访问者
5.IF existFunc(type) THEN
6.visit_Key(node);//如果存在具体访问者
7.ELSE generic_visito(rnode);//如果不存在
8.ENDIF
9.END FOR
10.FuncInfoDict<-completeFuncDic(t);//补全函数字典
11.//补全关键信息列表
12.KeyInfoList<-completeFuncInfo(FuncInfoDict);
13.END
在抽象访问者中数据结构的每个节点都能够接受来自访问者的调用,该算法结合先序遍历的思想,从根节点开始向访问者传入节点对象,而访问者则反过来执行基于该节点对象的操作,提取函数关键信息列表。
3.2.3 语句结构分析
(1)分支调用关系
语法中的分支结构大致分为三种:缺省型、标准型和多分支型。对应的关系模型如表2所示。
(2)循环调用关系
常用的循环控制关键字包括while、for等,且循环控制流结构相似。对应的关系模型如表3所示。

表3 循环语法结构-关系模型
这种语法与if-else 的结构类似,结合Z 路径覆盖思想,采用二分支结构,两个分支分别为执行循环体和不执行循环体。
3.2.4 函数调用关系模型的建立
以算法1的输出作为输入,即以关键信息列表Key-InfoList为输入,构建局部调用关系模型,再将局部关系模型以一定规则组合为全局函数调用关系模型。
步骤1遍历关键信息列表中的每一个元素,判断元素类型,执行相应操作。
步骤2如果元素是第一个节点,则创建新的空函数调用关系模型;如果元素是分支或循环的开始或结束标记,如if、while 和for 等关键字,根据函数调用关系模型构建原理,向左插入子模型;如果元素是其他分支标记,如elif、else等关键字,则向右插入子模型,表分支调用。得到局部调用关系模型。
步骤3遍历局部模型获取标识为Begin 的作为程序入口点。
步骤4从入口点开始,将每一个函数的调用关系模型依次插入到全局的函数调用关系模型中,插入的模型的叶节点的左孩子指向被替代的那个函数的左孩子。
步骤5遍历全局函数调用关系模型,获得全局函数调用路径集合。
具体算法描述如下:
算法2全局函数调用关系模型建立算法
输入:关键信息列表KeyInfoList
输出:全局调用关系模型GlobalModel
变量:entryModel:程序入口模型
ModelList:局部调用关系模型
1.Begin
2.FOR i<-0 to KeyInfoList.length DO
3.flag<-FALSE
4.list<-KeyInfoLis(ti)
5.FOR j<-0 to list.length DO
6.IF lis(tj).index()==0 THEN
7.model<-createMode(l“Begin”)
8.ENDIF
9.//如果是第一个节点,则创建节点
10.IF lis(tj)==“elif”or lis(tj)==“else”THEN
11.flag<-TRUE //标识置真
12.ENDIF //如果节点类型是分支关键字
13.IF lis(tj).index()==list.length THEN
14.model.insertLef(t“END”)
15.ENDIF
16.IF flag==FALSE THEN
17.model.insertLef(tlis(tj))
18.ELSE model.insertRigh(tlis(tj))
19.ENDIF
20.ENDFOR
21.IF i==0 TNEN
22.entryModel<-model
23.ELSE ModelList<-ModelList+model
24.ENDFOR
25.FOR i<-0 to entryModel.length DO
26.value<-entryMode(li)
27.FOR j<-0 to ModelList DO
28.model<-ModelLis(tj)
29.IF model.containsHead(value) THEN
30.value.data<-model.data;
31.model.leaf<-value.subMode(l);
32.value.leftchild<-model.leftchild;
33.ENDIF
34.ENDFOR
35.GlobalModel<-GlobalModel+entryModel;
36.ENDFOR
37.END
4 符号化执行
4.1 输入变量与控制变量的影响关系
由于不是所有控制条件中的变量都能直接作为测试用例输入程序,因此需要分析控制变量与输入变量之间的关系,本文利用信息流规则对信息流进行分析。
目前针对高级语言中赋值语句、条件语句、循环语句等信息流规则较为简单,因此提出一种扩展的语句信息流规则,具体定义如下:
(1)赋值语句
规则1v1=v2;则有<v2→v1,v1=v2>。
规则2v1=v2op,…,opvn;op代表运算符,则有<v2→v1,v1=v2op,…,opvn >,…, <v2→v1,v1=v2op,…,opvn >。
规则3v0--,--v0,v0++,++v0;则有<v0→v0;v0=v0+1>。
规则4v0op=v1;则 有<v0→v0∧v1→v0;v0=v0opv1>。
规则 5v0op0=v1op1…vi opi…opn-1vn(1 ≤i≤n);则有<v0→v0∧v1→v0∧…∧vi→v0∧…∧vn→v0;v0=v0op0(v1op1…vi opi…opn-1vn)>。
(2)函数调用语句
规则6v1=F(x),x为变量或表达式;则有<x→R(R为F(x)的返回值集合),R→v1,F(x)前置条件→F(x)后置条件;v1=R >。
规则7v1=F(x1,x2,…,xn)(1 ≤i≤n),xi为变量或表达式;则有<xi→R(R为F(x)的返回值集合),R→v1,F(x1,x2,…,xn)前置条件 →F(x1,x2,…,xn)后置条件>。
(3)控制语句
规则8if/while(v0op0vc0…opi vci)v1=n(n为常量,1 ≤i,vc代表常量或变量);则有<v0→<v0→v1,vc0→v1,…,vci→v1;(v0op0vc0…opi vci)→ (v1=v2)>。
规则9if/while(F(x)op0vc0…opi vci)v1=n(n为常量,1 ≤i,vc代表常量或变量);则有<x→R(R为F(x)的返回值集合),R→v1,vc0→v1,…,vci→v1;(v0op0vc0…opi vci)→ (v1=n)>。
根据上述信息流规则分析得到两个变量之间的关系并进行组合,得到控制流影响关系树,每棵树的根节点都是输入变量,叶子节点是要分析的控制变量。具体算法如下:
算法3控制变量与输入变量关系分析算法
输入:源代码
输出:控制变量与输入变量之间的关系表达式
变量:inputList:输入变量集合
controlList:控制变量集合
relationList:变量之间的关系集合
relation:输入变量与控制变量之间的关系
1.Begin
2./*读取Python源代码,分析得到输入变量集合、控
3.制变量集合,依据信息流规则分析变量的关系*/
4.FOR i<-controlList.size()-1 to 0 DO
5.//如果该变量已分析过,则跳出
6.IF controlList.ge(ti)THEN break;
7.END IF
8.//如果待分析变量是输入变量,则继续循环
9.IF controlList.get(i) in inputListTHEN continue;
10.END IF
11.FOR j<-relationList.size()-1 to 0 DO
12./*如果待分析变量是关系树的子节点,将此关
13.系树加入到此变量的关系树集合中*/
14.IF controlList.ge(ti)is relationList.childnode
15.THENrelation=combine(relation,relationList.ge(ti))
16.END IF
17.ENDFOR
18.print relation
19.ENDFOR
20.END
遍历每棵控制流影响树:从叶子节点开始,自底向上广度优先遍历,将路径上的关系表达式以图3所示递推公式链的形式组合输出,得到控制变量与输入变量的关系链。

图3 递推公式链
4.2 变量符号化
以图4中源代码为例,根据算法1、算法2可得到图5所示函数调用路径图。

图4 示例代码
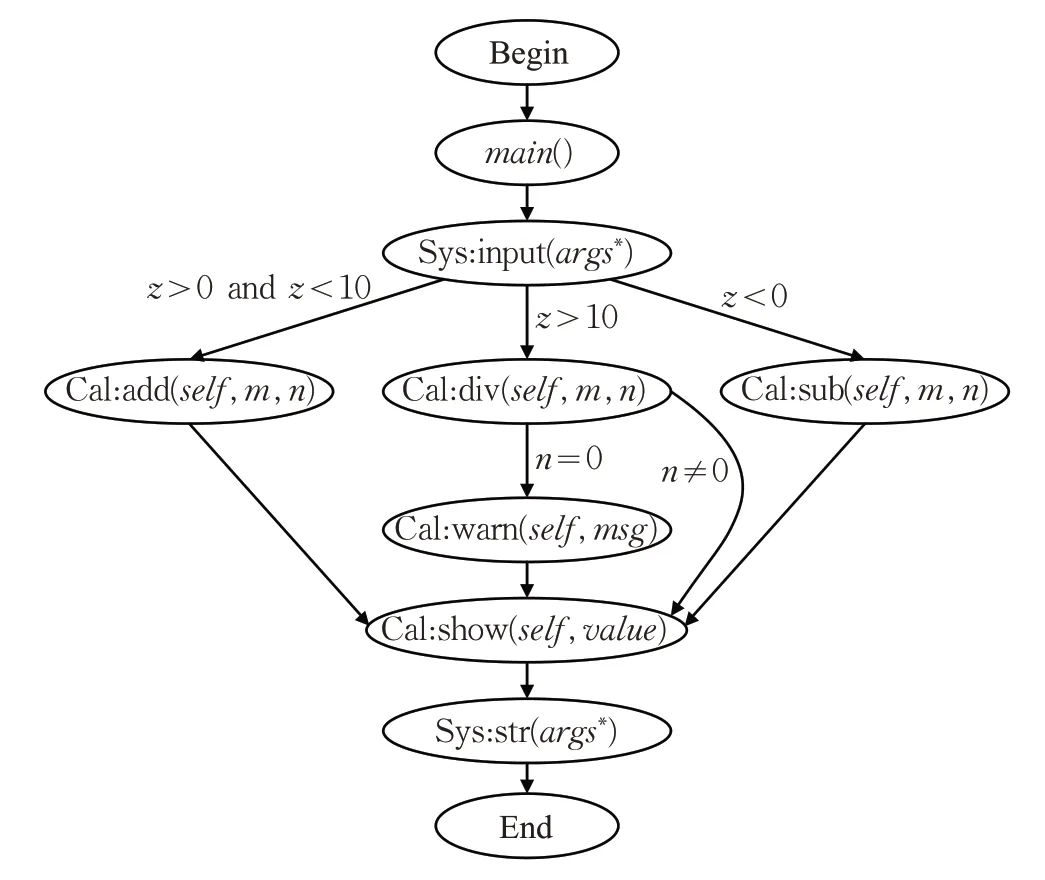
图5 函数调用路径图
根据算法3 生成控制变量与输入变量的递推公式链,得到控制变量与输入变量之间的关系表达式集合。
分析源代码得到输入变量集合,为每一个输入变量设置符号值,推导出控制变量的符号表达式。分析结果如表4所示。

表4 变量符号化结果
利用函数调用关系模型和控制流分析得到图6 所示程序的符号执行树,符号执行树的叶子节点为程序函数调用路径对应的符号表达式。
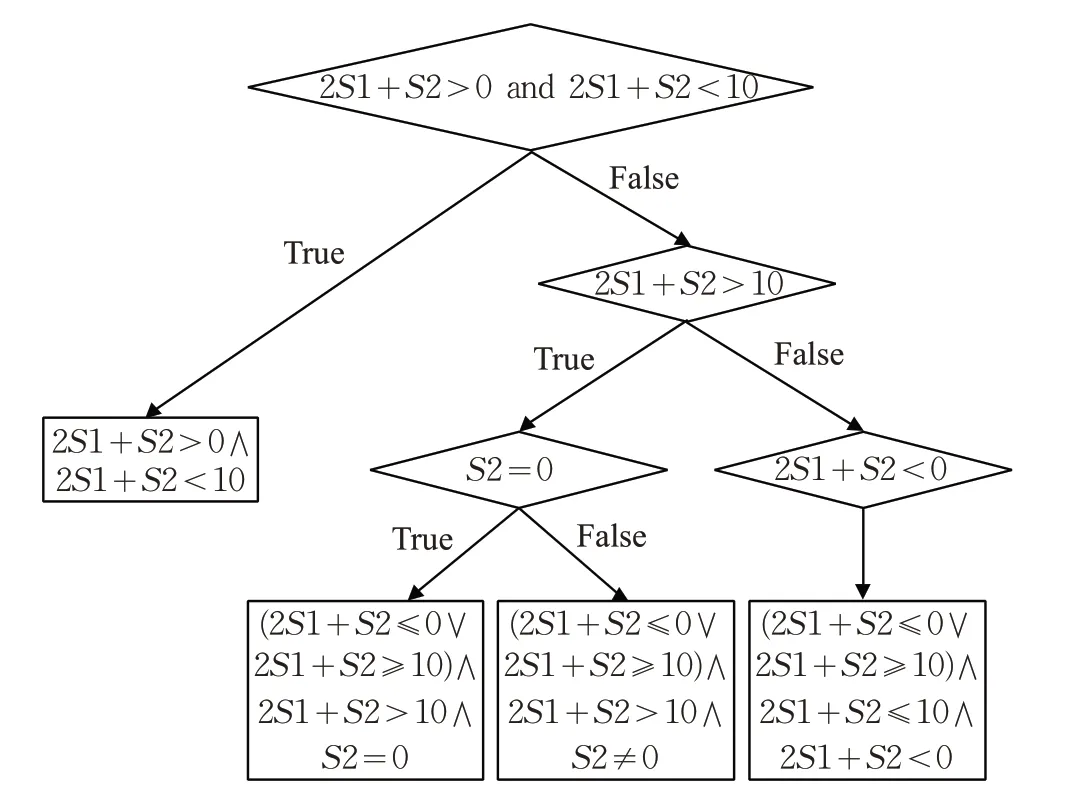
图6 符号执行树
4.3 约束求解
采用深度优先搜索算法(DFS)遍历符号执行树,收集每条函数调用路径对应的符号表达式。利用SMT求解器对符号表达式进行求解,SMT是一阶逻辑表达式,其在编译优化,形式化验证都可以用到该模型理论,符号执行测试中利用该模型理论对于收集的路径约束组成的表达式求解,比如收集到a<b∧b-5=c路径条件下的一组表达式进行SMT 求解,根据其理论模型会就计算出一组值{a=5,b=10,c=5},这组解即为一组测试用例数据。SMT求解器从输入到输出的执行流程如图7所示。
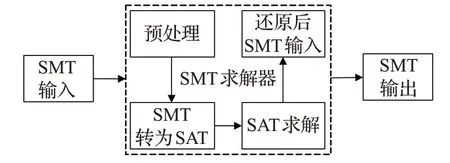
图7 SMT约束求解执行流程
微软的Z3 求解器能够满足几乎所有求解理论,求解范围更广,对于复杂程序下的非线性约束表达式也有较好的表现,因此选用Z3 求解器对符号表达式进行求解,得到对应的测试用例集合。
4.4 冗余路径剪枝
在程序分析过程中有些路径是冗余的,冗余路径剪枝可以简化路径空间,提高分析效率,总结出以下两种路径可对其进行剪枝处理:
(1)如果两条路径到达同一个程序点,并且到达该程序点的约束集相同,则可以对其中一条进行剪枝。
(2)对每条路径的约束信息进行可满足性判定,如果该约束是不可满足的,则意味着不存在能驱动该路径具体执行的测试用例,该路径为冗余路径,可以直接进行剪枝。
(3)图8 左侧为示例源代码,右侧是其对应的函数调用路径图。以此为例,分析冗余路径剪枝策略。

图8 示例程序对应函数调用路径图
由本文测试用例自动生成算法可得到3 条测试用例,将其作为程序输入分别执行程序,可得到每条测试用例对应的函数实际执行路径,如表5所示。

表5 测试用例执行路径
以TC1为例,把a=2 作为程序输入执行程序,从语句粒度分析,将先后经过源代码第15、16、17、18、01、02、03、04、07、08、06、11、12、02、03、04、07、08、06、11、12行;从函数粒度分析,则先后经过main、f1、f2、f4、f2、f4,故 函 数 的 实 际 执 行 路 径 为main→f1 →f2 →f4 →f2 →f4 。
当 0 <a≤3 即执行测试用例a=2 时,程序实际执行过程中函数间调用关系R0<a≤3={(main,f1),(f1,f2),(f2,f4)};当a>3 即执行测试用例a=4 时,函数间的调用关系Ra>3={(main,f1),(f1,f2),(f1,f3),(f2,f4)};当“a≤0 ∪a不是整数”即执行测试用例a=0 时,函数调用关系Ra≤0∪a不是整数={(main,f5)} ,分析可知R0<a≤3⊂Ra>3,即TC1 实际执行路径的函数调用关系集合是TC2 实际执行路径的函数调用关系集合的子集,同时TC1实际执行路径中包含的函数集合也是TC2 的子集。因此在函数级别TC2包含TC1,表6进一步分析TC1、TC2的语句覆盖情况,1表示语句被覆盖,0表示未被覆盖。
根据表6 可知,TC2 的语句覆盖集包含TC1 的语句覆盖集,因此在语句粒度TC2 可以完全囊括TC1 的执行语句,故TC1 对应的路径在此例中为冗余路径,进行剪枝。

表6 语句覆盖情况
如若将此段代码修改为图9所示,则TC1执行语句集合中的09 行无法被TC2 囊括,此时不能对TC1 对应的路径进行剪枝操作。

图9 变更后示例程序
5 实验分析
评测方法主要通过两个实验进行验证,实验1 从github 下载(https://github.com/tianxy0621/TT.git)五个不同规模、内含多种语法结构的Python 实例源代码:_color.py、_pycallgraph.py、_config.py、_tracer.py、_memory_profiler.py。
以此作为数据集并用本文的算法分别进行实验,自动生成程序的测试用例集合,分析随程序规模的扩大,覆盖率、效率等因素的变化。实验2 采用同实验1 的数据集,将本文算法生成的函数调用路径数与传统符号执行算法路径条数进行比较,并分析其原因。

表7 实验1对比结果

表8 实验2对比结果
5.1 实验1
为了计算测试用例自动生成工具生成的测试用例覆盖率,使用插装技术计算被测程序动态执行的路径条数,将生成的测试用例作为程序的输入,动态获得执行的函数调用路径,根据覆盖率公式:

计算本文算法对于不同规模程序的覆盖率,结果如图10所示。

图10 覆盖率变化趋势图
实验中执行时间、函数调用路径条数以及测试用例个数等其他指标数据的综合比较如表7所示。
从表7 中数据可以看出随程序规模的增加函数调用路径条数增加,同时生成的测试用例个数也随之增加。
结合图10可以看出,当源程序规模较大时,可以保证较高的覆盖率和效率,但相比小规模的程序,覆盖率有所下降,原因主要有两点:一是程序中可能存在不可达路径,导致动态执行路径小于函数调用路径数;另一个可能的原因是设计的信息流规则考虑不够充分,使得对复杂语句结构的分析不够准确。因此下一步研究工作是分析不可达路径以及完善程序信息流分析算法。
5.2 实验2
实验2 数据集与实验1 相同,利用本文算法与传统符号执行算法生成的路径条数进行比较,实验结果如图11、表8所示。
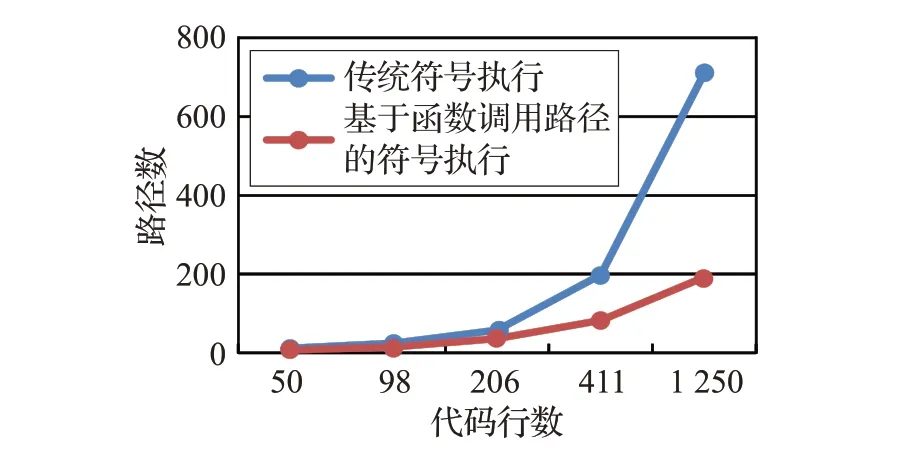
图11 传统算法对比结果
基于函数调用路径的符号执行算法首先构建函数调用关系模型,从函数角度出发分析程序,并生成函数粒度的符号执行树,利用符号执行技术求解测试用例。
最终结果表明,相比于传统符号执行算法,该方法有效缩减了路径条数,减少了生成的测试用例个数。
6 结束语
测试用例自动生成技术目前仍然是软件测试自动化的重点研究内容,用最少的测试用例达到更高的覆盖率并找到最多的错误是软件测试的目标。本文利用函数调用路径对符号执行进行优化,通过提取字节码序列和抽象语法树中的关键信息得到函数调用路径图,将其与符号执行技术相结合,约束求解生成程序的测试用例集合。
此方法将分析粒度提升至函数,减少路径数以及约束表达式的数量,一定程度上解决符号执行的路径爆炸问题。从实验结果可知,本文方法相比较于传统方法,可在不降低覆盖率的条件下,有效减少测试用例条数从而提高测试效率。
猜你喜欢
小学生学习指导(高年级)(2021年4期)2021-04-29
科教导刊·电子版(2021年1期)2021-03-26
铁道通信信号(2020年6期)2020-09-21
河北理科教学研究(2020年2期)2020-09-11
人大建设(2019年12期)2019-05-21
瞭望东方周刊(2017年42期)2017-12-05
环球时报(2017-03-30)2017-03-30
中国卫生(2015年3期)2015-11-19
浙江理工大学学报(自然科学版)(2015年7期)2015-03-01
新高考·高二数学(2014年7期)2014-09-18
