
结合LDA与Self-Attention的短文本情感分类方法
2020-09-15 04:47朱翌民余宇新
计算机工程与应用 2020年18期
陈 欢,黄 勃 ,2,朱翌民,俞 雷,余宇新
1.上海工程技术大学 电子电气工程学院,上海 201620
2.江西省经济犯罪侦查与防控技术协同创新中心,南昌 330103
3.上海外国语大学 国际金融贸易学院,上海 201620
1 引言
随着Web2.0时代的到来,以微博、电商为首的平台的快速发展,网民可以快速地在网络平台上表达自己的观点和看法。其中短文本逐渐成为网络文本信息的主体,与其他网络文本相比其在数量上有着巨大的优势。挖掘短文本中的情感信息和观点态度,实现对文本的情感分类有着重要的现实意义。文本情感分类包括分词、文本表示、特征提取、分类四个过程。
传统的文本情感分类模型对文本进行one-hot 编码,利用TF-IDF[1]、交叉熵[2]等进行特征提取,然后使用SVM[3]、Random Forest[4]等分类器进行分类。LDA[5](Latent Dirichlet Allocation)模型在经历了LSI[6(]Latent Semantic Indexing)、PLSI[7(]Probabilistic Latent Semantic Indexing)等技术的发展后,被广泛用于文本特征提取。例如吴江等人[8]使用LDA模型进行主题特征词选取,组成特征词库进行特征提取。胡勇军等人[9]针对短文本特征稀疏、噪声大的缺点,使用LDA模型将概率大于某一阈值的主题词分布的高频词扩展到文本中,以降低短文本分类时噪声和稀疏性的影响。近年来,深度学习算法的快速发展给文本情感分类带来了新的思路。其中基于注意力机制和LSTM(Long Short Term Memory network)的一类算法成为了主流的文本情感分类算法。其中LSTM用于获取文本的上下文依赖关系,注意力机制对LSTM 编码后的文本进行权重分配,然后进行情感分类[10-12]。例如吴小华等[11]针对分词的准确性问题提出了基于字向量的表示方法并使用Self-Attention和Bi-LSTM进行中文短文本情感分类。陶志勇等[12]使用Bi-LSTM网络进行特征提取,将双向长短时记忆网络的两个方向的输入独立输入到注意力机制进行全局权重分配。
基于LDA的文本特征提取方法作为一种概率主题模型,虽然能够获得文档之间的关系,然而在建模过程中却忽略了文档的上下文依赖关系,导致了语义信息的丢失。深度学习算法基于序列建模的方法弥补了LDA的不足。如吴彦文等[13]使用词嵌入对LDA 获得的文档特征词进行表示,然后和LSTM 编码后的文本进行拼接,用于解决数据稀疏问题。张群等人[14]通过拼接相加平均合成的词向量和经过LDA 特征扩展的短文本向量,利用kNN进行分类。
从上述可知,在短文本情感分类的过程中可以使用LDA进行特征扩展,用于解决短文本数据稀疏问题,然而现有的方法都是通过word2vec对主题特征扩展后的文本进行表示,弱化了主题特征的作用。针对这个问题,本文提出一种基于LDA 和Self-Attention 机制的短文本情感分类方法。通过使用LDA获得评论的主题词分布,并将主题词和评论文本进行拼接输入到word2vec模型进行训练,得到包含主题信息的词向量,然后使用Self-Attention机制对文本进行动态权重分配,最后通过softmax层输出进行情感分类。通过在谭松波酒店评论数据集上的实验表明,本文方法与当前主流的短文本分类情感方法相比,有效地提高了分类性能。
2 相关工作
2.1 LDA
LDA 模型是一种文档生成模型,其概率图模型如图1所示,它将文档表示为主题的概率分布,而主题表示成词的概率分布,因此LDA 可以被用来进行文本特征提取。LDA 的输入是文本的one-hot 编码,输出是文档的主题分布、主题的词分布[5]。LDA模型可以描述如下:
(1)文档的主题先验分布服从参数为α的Dirichlet分布,其中文档d的主题分布为θd=Dirichlet(α)。
(2)主题中的词的先验分布服从参数β的先验分布,其中主题k的词分布为φk=Dirichlet(β)。
(3)文档d中的第n个词,从主题分布获得其主题编号分布为zdn=multi(θd)。
(4)文档d中的第n个词分布wdn的分布为wdn=multi(φzdn)。
图1 中D是训练数据集的大小,N是一条训练数据的大小,K是主题数。

图1 LDA概率图模型
从模型假设可知,已知每个文档的文档主题的Dirichlet 分布与主题编号的多项式分布满足Dirichletmulti 共轭,使用贝叶斯推断的方法得到文档主题的后验分布。同样已知主题词的Dirichlet 分布与主题编号的多项式分布满足Dirichlet-multi 共轭,通过贝叶斯推断得到主题词的后验分布。然后通过使用Gibbs采样的方法去获得每个文档的主题分布和每个主题的词分布。
2.2 word2vec模型
文本信息需要被编码成数字信息才能进行计算处理。传统的模型使用基于one-hot 编码的方法的BOW(Bag of Words)模型,该方法通过构建词典,统计文本的词频信息,对文本进行编码。然而,one-hot模型的编码方法孤立了每个词,无法表达出词之间的关系,导致语义信息的丢失。而且,当词的种类过多时,还会带来维度爆炸的问题。因此,提出了词的分布式表示,将经过one-hot编码的词,映射到一个低维空间,并保留词之间的语义信息。word2vec 模型是目前主流词分布式表示模型,word2vec包含两种模型,分别是CBOW与Skip-Gram。CBOW 模型通过输入中心词相关的词的词向量,输出中心词的词向量。Skip-Gram则相反,通过输入中心词的词向量,输出上下文的词向量[15]。两种模型的结构如图2所示。
2.3 attention模型
注意力机制是一种权重分配机制,通过模仿生物观察行为的过程,将内部经验和外部感觉对齐从而增强观察行为的精细度,在数学模型上表达为通过计算注意力的概率分布来突出某个关键的输入对输出的影响[16-17]。其首先被提出应用于图像特征提取过程,而后被Bahdanau等人[10]引入到自然语言处理领域。如公式(1)所示,其中k(ikey)与v(ivalue)一一对应,通过计算qt(query)和各个ki的内积,求得与各个vi的相似度,然后进行加权求和与归一化。

图2 word2vec模型结构

其中,Z是归一化因子,为输入词嵌入向量的维度,起到调节因子的作用,使得内积不至于过大。
3 模型描述
本章介绍了本文提出的短文本情感分类方法,主要包括四个部分:第一部分,训练LDA 模型,得到每条评论的主题词分布,设置主题数、主题词提取阈值,进行主题词提取;第二部分,将前述提取到的主题词和原有评论内容进行拼接输入到word2vec 模型进行训练;第三部分,使用Self-Attention 机制进行动态注意力更新;第四部分,通过softmax层进行情感分类,根据情感分类准确率确定最佳主题数和主题词选取阈值。研究框架如图3所示。
3.1 评论主题信息提取
统计语料集的词频信息建立字典,对文本进行BOW编码,输入到LDA 模型中,获得每条评论的主题分布d_t=[z1,z2,…,zK],其中z为每个主题编号的概率。然后找到每个主题的词分布t_w=[w1,w2,…,wN],其中w为字典中每个词的分布概率。则每条评论的主要特征词可以表示为如公式(2)所示:
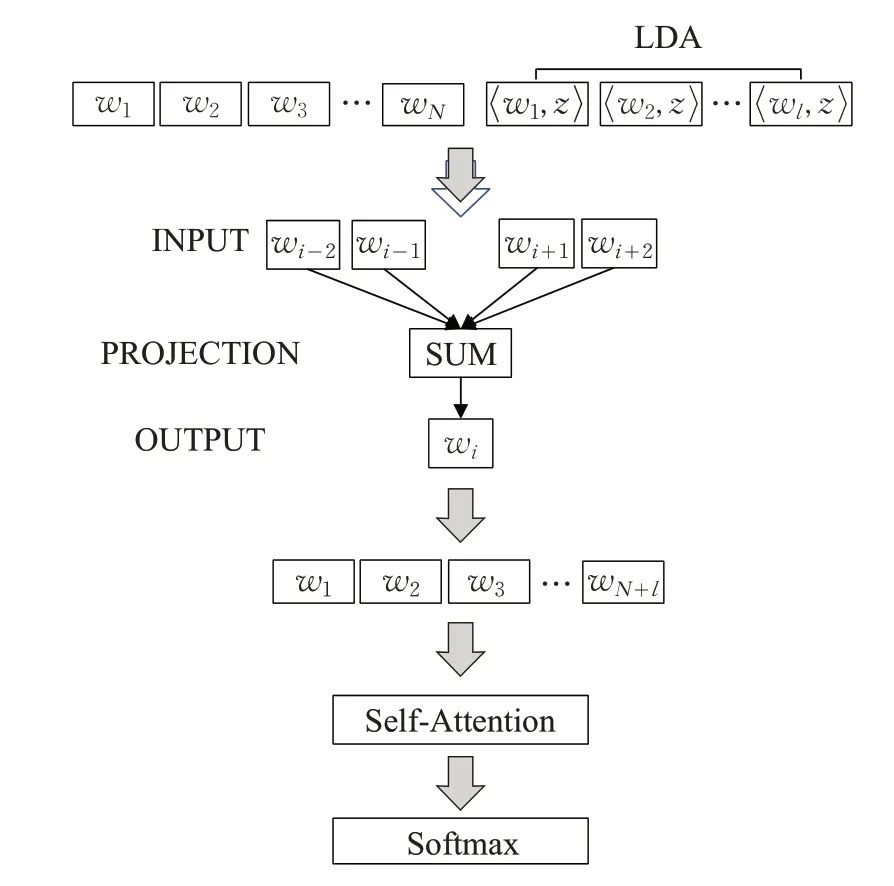
图3 研究框架

通过设置阈值,选取D_W中超过阈值的词作为评论文本的主要词特征。
3.2 文本向量化
为了更好地实现对评论文本进行聚类,本模型将主题信息融合到评论文本词向量训练的过程。使用LDA获得该条评论的主题信息,和原有的评论内容进行拼接,作为评论与主题信息结合后的向量表达。将前述得到的融合主题信息的评论文本作为输入,训练CBOW模型。假设词向量的维数为dk,每条评论文本可以表示为一个行数是词向量的维度dk,列数是评论文本长度N与主题特征词的个数l之和的文本矩阵W=<w,wz >。其中w为评论文本的词向量表示,wz为通过LDA 获得该评论文本的主题特征的词向量表示。CBOW模型损失函数如公式(3)、(4)、(5)所示[15,18]。

其中,wi为某个中心词,s为中心词左右窗口大小,P(wi|wi-s,…,wi+s)已知上下文中心词为wi的概率大小计算方法如下:
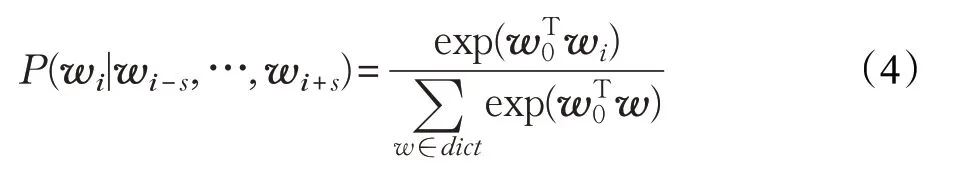
其中w0是wi上下文词向量的均值,dict为字典。

通过在评论文本中融合主题的特征信息,从而使得编码后的词向量在高维空间同类信息之间的余弦距离更小,使得相同主题评论文本在向量空间的聚类效果更好。
3.3 Self-Attention机制
传统的注意力机制通过计算源端的每个词与目标端的每个词之间的依赖关系来更新训练参数,Self-Attention机制仅通过关注自身信息更新训练参数,不需要添加额外的信息。将前述通过CBOW模型得到的融合主题特征的评论文本向量输入到Self-Attention层,通过公式(6)计算权重分布:

3.4 模型训练
使用交叉熵作为损失函数,利用Adam更新网络参数。公式(7)计算评论文本向量γx属于类别yx的概率,n_c为类别的数目。以公式(8)为损失函数,通过迭代更新参数,最小化监督标签gx和预测标签之间的交叉熵。

3.5 模型描述
本文提出的模型可以描述如下:
输入:带标签短文本数据集。
输出:训练好的分类模型。
步骤1对数据集进行分词、去停用词等预处理过程,得到处理后的数据集doc。
步骤2将数据集doc输入到LDA 模型,得到每个短文本的主题概率分布和每个主题的词语的概率分布,根据公式(2)构建每条评论的主题特征词矩阵D_W。
步骤3根据步骤2 的结果选取每条评论的主题特征词,并和原评论进行拼接输入到word2vec 模型进行训练,构建融合主题信息的词向量模型,得到每条评论与主题特征词的词向量表示W。
步骤4添加Self-Attention层,根据公式(6),对步骤3的向量表示的评论结果,进行自注意力计算。
步骤5根据分类准确率选择LDA 模型的主题数K,主题词选取阈值。
步骤6通过迭代训练更新模型参数,进行文本分类。
4 实验分析
4.1 实验环境
实验的硬件和软件的配置保证着实验的顺利进行,本文实验的环境如表1所示。

表1 实验环境配置
4.2 实验数据
本文使用哈工大谭松波老师整理的酒店评论数据集,共6 000条,其中正向情感评论3 000条,负向情感评论3 000 条,数据类别分布均衡。对数据集中评论的长度进行统计得到评论长度分布如图4所示。其中,共有6 000条数据,评论的长度30以下的有3 198条,在20以下的有1 601条。因此,如何对评论文本中的短文本数据进行合理的处理,使得短文本情感分类成为研究的重点。
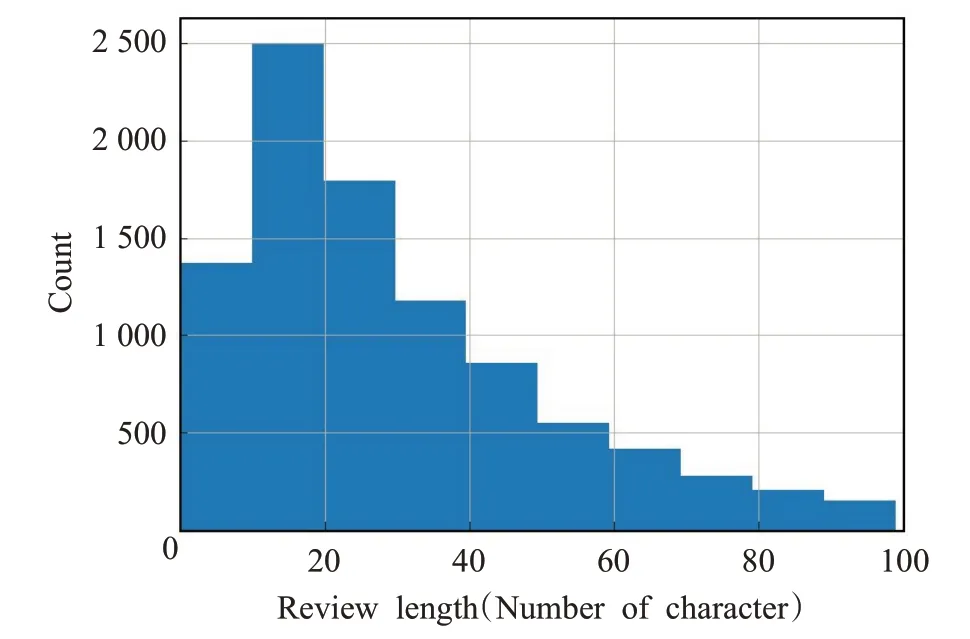
图4 数据集长度分布
对分词后的数据用词云表示如图5 所示,其中“服务”“入住”“早餐”等为酒店评论的热点词汇。

图5 数据集词云
4.3 参数设置
深度学习模型参数设置十分关键,该模型主要由三部分参数组成,分别是LDA、word2vec、Self-Attention三个模型的参数,参数大小设置如表2所示。
4.4 LDA主题词提取
将酒店评论语料集经过预处理后输入到LDA 模型,得到语料库的主题词概率分布和每条评论的主题概率分布。使用公式(2)计算添加到每条评论中的主要词特征。根据情感分类准确率选择主题词选取阈值为0.03,对添加到评论中的主题词进行统计,在指定LDA主题总数为30、35、40、45时,评论中满足阈值条件的主题词如表3所示,其中包含了酒店评论中的软硬件配置以及顾客的情感态度和服务水平等各种信息。
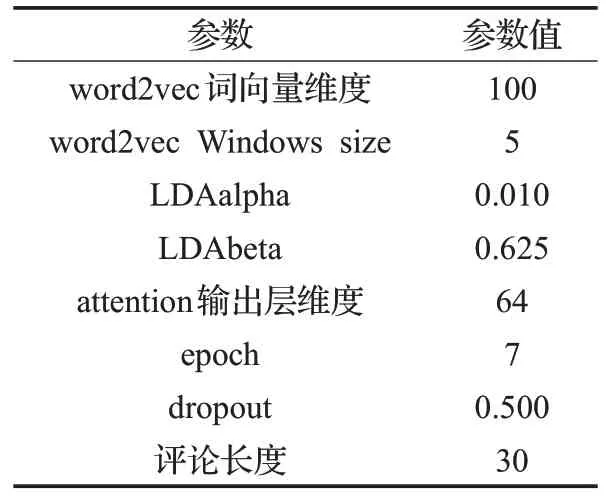
表2 实验参数设置

表3 LDA提取主题词示例
为了研究情感分类过程中准确率、添加到文本中的主题词数目以及主题词种类之间的变化关系(主题词数目表示总共添加多少词到模型训练中、主题词种类表示总共添加了多少个不一样的主题词到文本中)。
设置主题数目变化范围为K∈[0:100],以5 为步长,绘制准确率、主题词数目、主题词种类随着主题数的变化曲线。其中为了便于观察,对实验结果进行了归一化处理。如图6所示,主题词的种类随着主题数的增加而不断增加;主题词数目先随着主题数不断上升,在主题数为30达到了最大,而后不断下降并趋于稳定;准确率刚开始随着主题数不断上升,在主题数为35,准确率达到了最高,而后开始下降,并在一定范围内波动。

图6 准确率及主题信息随主题数K 变化曲线
由此可以看出,模型分类的准确率与添加到评论中主题词总数和LDA 模型的主题总数相关,但可以直接由LDA 模型的主题总数进行确定,且不会随着添加到评论中主题词的种类的增加而增加。
4.5 评价指标选取
本文采用Precision、Recall、F1-Score对实验结果进行评测[19]。Precision用来描述所有预测该类别的测试数据中,真正是该类别的数据所占的比率。Recall用来描述所有该类别的测试数据中,预测为该类别数据所占的比率。F1-Score综合了Precision和Recall两个指标,定义如下:

TP表示将真实正样本预测为正样本,FN表示将真实正样本预测为负样本,TN表示将真实负样本预测为负样本,FP表示将真实负样本预测为正样本。
如表4所示,本文选取了五种基于词向量、LSTM和Self-Attention相结合的算法[10,20]进行复杂度和准确率的对比分析。由于五种模型都使用了word2vec 词向量,因此word2vec模型复杂度可以忽略。因此对比模型可以划分为4种基于LSTM的模型和1种基于Self-Attention的模型。根据文献[21],LSTM单层的复杂度为O(n×d2),Self-Attention单层复杂度为O(n2×d),其中n为序列长度,d为词向量的维度。当n <d时,Self-Attention模型单层复杂度低于基于LSTM 模型单层复杂度。本文使用的LDA 模型的复杂度为O(K×N),其中K为主题数,N为字典的大小。因此本文提出的模型复杂度低于基于LSTM 模型,而高于只使用Self-Attention 的模型。与基于LSTM 的模型相比,不仅降低了模型复杂度,而且提高了分类准确率。与只使用Self-Attention的模型相比,本文提出的添加了主题信息的情感分类模型提高了情感分类的准确率。

表4 酒店评论数据集评测结果对比 %
5 结语
本文提出了基于注意力机制的评论文本情感分类方法,使用LDA获取评论文本的主题信息,将文本的主题信息和评论文本进行拼接融合,输入到CBOW 模型进行词向量训练,实现词向量在高维空间的主题信息聚类,使用Self-Attention 机制进行动态权重分配,有效地避免了由于文本长度过短导致文本情感分类准确率降低的问题,实验证明了本文提出的情感分类方法优于主流的短文本情感分类方法。其中主题信息的提取是决定本文提出的情感分类方法准确性的重要因素,无效的主题信息不仅不能提高分类的准确性,还会降低分类的准确性。本文通过人工筛选的方式提取主题信息,但人工的方式带来了工作量大的问题,因此下一步研究的重点是如何自动提取有效的主题信息。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
中国医学计算机成像杂志(2020年6期)2020-03-14
时代英语·高二(2018年7期)2018-12-03
时代英语·高二(2018年3期)2018-06-06
高中生学习·高三版(2016年9期)2016-05-14
中国骨与关节杂志(2016年12期)2016-01-23
新高考·高二数学(2015年11期)2015-12-23
西北工业大学学报(2015年1期)2015-02-22
西北工业大学学报(2015年1期)2015-02-22
