
一种基于遗传算法的智能电网调度方法
2020-09-15 02:10:58吴海伟王晓忠朱法顺
计算机与现代化 2020年9期
吴海伟,王晓忠,朱法顺
(1.国网江苏省电力有限公司,江苏 南京 211106; 2.国网南京南瑞集团公司(国网电力科学研究院),江苏 南京 211106;3.国电南瑞科技股份有限公司,江苏 南京 211106)
0 引 言
智慧电网这个概念作为能源电网的现代化机制,近些年已经频繁出现在传统电力行业的各个角落[1-4]。在智慧电网中,传感器、计算机和通信网络被整合到发电、输电、配电和负载元件等传统电力行业组成元素中[5-7]。这种机制能够收集各种信息,控制发电量和需求,甚至可以预测能源消耗。例如,智能电表被放置在用电负载单元上(如家庭、办公楼)时,可用于收集非常精细的实时需求数据,并帮助系统运营商通过地理或时间维度来估计未来的用电需求[8-10]。对负载行为的评估可以与生成的数据信息结合起来,从而实现在更高阶的需求场景下的需求响应策略。从这个方面来看,智慧电网升级了现有电网,使现有基础设施得以重新利用,并降低了部署成本[11-12]。
但这种类型的网络势必会带来一系列的问题,由于必须从电网中收集大量数据,所以需要相应的大数据技术来对这些信息进行管理[13-14]。此外,大量元素需要利用并行处理技术来进行跟踪,这就导致了冗余的增加,所以需要对系统分析进行优化[15]。
1 智慧电网的组成及数据来源
智慧电网是利用信息技术和通信技术对电网发电、配电和消耗进行优化。智慧电网体系结构由3个主要系统组成:电力系统、通信系统和信息系统[12]。正确的架构是确保智慧电网功能完善的必要条件。未来智慧电网的设计和分析需要对电网拓扑结构和大数据综合网络控制的影响,以及物理层与网络层之间复杂的交互进行基础性的洞察,其中包括支持通信、信息、网络以及计算系统等。智慧电网结构可以表示为一个分层结构,主要包括:电力系统层、通信层以及信息架构层,其中作为数据来源,信息架构层具有非常重大的研究价值[16]。
1.1 信息架构层
智慧电网之间的通信对于确保电网的灵活性、可扩展性、可靠和高效性是非常重要的。图1展示了整个智慧电网的信息架构,从图中可知,信息架构主要分为市场、生产、传输、配电、消费者几个部分。在每个部分中,又可以细分为很多小类,其中既有传统的电网组成部分,如控制系统等,也有新兴的组成部分,如各类智慧应用、电子商务/互联网、分布式发电等。在每个子类中都产生了大量信息数据。
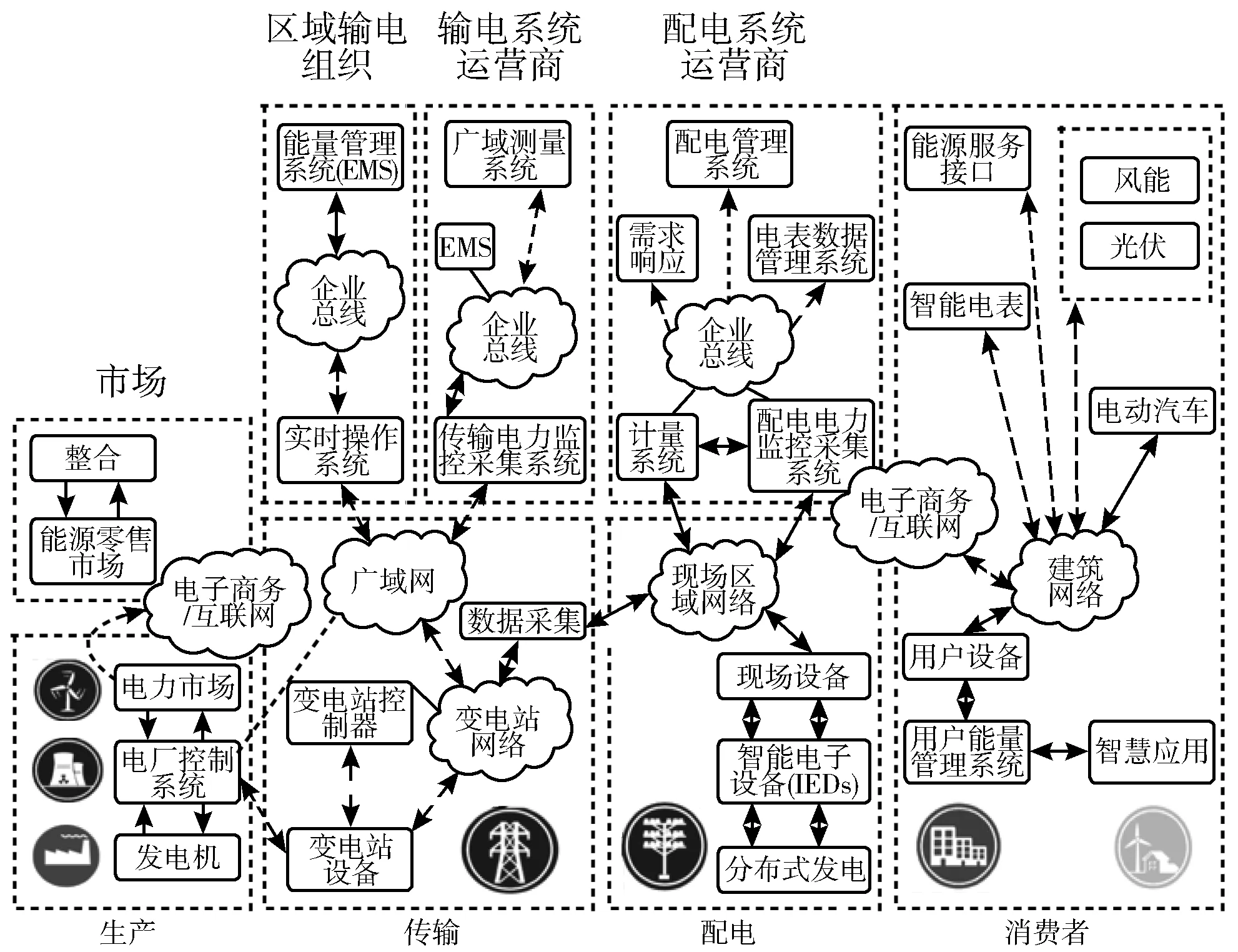
图1 智慧电网信息架构
从图1及文献[17]可知,智慧电网的电力信息系统除了图中展示的:监控与数据采集(SCADA)系统、高级计量基础设施(AMI)、计量数据管理系统(MDMS)、需求响应管理系统(DRMS)外,还包括地理信息系统(GIS)、客户信息系统(CIS)和中断管理系统(OMS)。其中DRMS和OMS是整个网络中的主要系统,因为它们与其他的系统互相交互,以保证对电网与消费者的满意度整体视野。AMI系统处理来自电力用户的数据,并相互交换信息。监控与数据采集系统则从公用领域收集数据,然后使用它来管理电网基础设施。
1.2 数据来源
智慧电网中的数据来源广泛,不同的信息系统需要采样不同的数据,如智能电表测量的能耗数据,电力基础设施设备的运行数据,分布在输配电网络上的传感器数据以及气象、地理信息等辅助数据,以及消费者所产生的社交媒体和能源市场数据。在数据分析方面,智能电网的每个领域都包含许多挑战和机遇,其中,最大的挑战是满足广大消费者的需求,提高其对电力行业的满意度。在服务提供商领域,来自智能电表、传感器和电源管理单元(PMU)的数据可用于估计能源价格和消费者行为,它使供应商能够捕获能源需求和价格之间的相互依赖性,从而加强决策过程。收集到的数据可用于设计和实施需求侧能源管理策略,根据随时间变化的电价和公用事业公司的其他付款激励,促进消费能源消耗情况的变化。这些数据还可用于需求响应机制,以最大限度地减少用电账单和改变峰值负荷需求,最大限度地降低电网运行成本,最大限度地减少能源损失和温室气体排放。但由于目前传统电力行业的局限性,对于用户的用电需求未能进行有效且合理的规划,因此,为更好地满足用户用电需求,优化资源调配,本文提出一种基于遗传算法的智能电网调度方法(Genetic-demand Side Management Algorithm, G-DSM)来规划用户的用电需求。
2 G-DSM算法原理
2.1 问题描述
需求侧管理(Demand Side Management, DSM)是智慧电网中管理能源的重要特征。电力需求侧管理的目标是有效利用现有的电网产能,提高电力系统的经济性[18]。对于电网的负荷调度问题通常可以被描述为一个最小化问题[19]。由于电力市场的间歇性,可以假设实时定价(Real-Time Pricing, RTP)信号的变化是以1 h为基础,其值在1 h内是恒定的。最终目标是最大限度地减少用户的电费,同时降低峰均比(Peak to Average Ratio, PAR),以提高电网的效率。求最小化问题的公式如下:
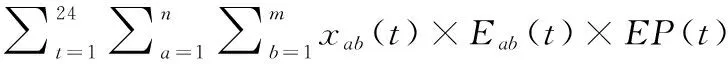
(1)
在公式(1)中,t代表时间间隔,a代表电器数量,b表示电器种类;xab(t)代表a台b型号的电器在t时间内的开关状态(即运行状态);Eab(t)代表a台b型号电器在t时间内的总能耗;EP(t)代表t时刻的电价。
公式(1)中的最大用电消耗范围可以用公式(2)表示:
(2)
其中,L(t)表示在t时刻的最大供电电力。公式(2)代表着在时间段t电力消耗的能量小于PAR的最大限制。在现实中,设备存在延时使用的情况,会因为各种因素超出预期使用时间长,进入下一个供电时间段,所以每个设备允许的最大延时使用可以用公式(3)表示:
mb=24-lb
(3)
在公式(3)中,mb表示每台b类电器最大允许延迟使用时间,lb表示每台电器的运行时长,即操作时间。
(4)
公式(4)表示a台b类电器能否在额外时间进行工作。其中,Yab表示b类电器可操控的数量共有a台。当Yab=0时,表示a台b类电器可以在运行时间结束后进行其他安排。当Yab>0时,代表a台b类电器不能在它的运行时间结束后再做进一步的安排。由实际情况可知,在时间段t中,更替的a台b类电器的数量不能大于实际可控电器的数量。此外,参与调度的电器数量不能为负,即DSM控制器仅调度可控电器,而不是系统中的所有电器。最终的电力的需求关系可以用公式(5)表示。
(5)
其中,Ctab代表可转移的b类a台电器的数量,数量A(t)表示在时间段t中的可控电器的数量集合。
2.2 G-DSM算法实现
G-DSM算法的主要目的是为了对智慧电网中属于不同能耗级别的大量可控制电器进行管理。每种类型的负荷都有不同的功耗模式和不同的运行时长,因此,设计方案应能解决所有这些错综复杂的关系。然而,目前许多常用于调度的算法,如LP、OSR以及动态规划等,由于其复杂性,这些算法无法处理电网中大量的设备。遗传算法提供了给定问题的近似最优解,它具有解决这类复杂问题的潜力,因此本文使用遗传算法来改进调度算法,提出G-DSM算法来解决成本优化问题。
首先,应用程序请求DSM控制器获得连接权限,然后,DSM控制器对每个时隙中的设备进行累积处理,最后,通过求解最小化问题给出一个完整的模式。G-DSM算法开始执行时,当设备向DSM控制器发送请求时,它将根据预先执行的G-DSM算法的结果采取相应的行动。
在G-DSM算法中,染色体模式代表解。在调度过程中,染色体(chromosome)被认为是一个代表电器开关状态的位数组。因此,染色体的长度取决于可控装置的数量,具体用公式(6)表示。
Lengthofchromosome=N
(6)
其中,N是每个区域中可控制的负载数。在评估适应度函数后,染色体群会有一个随机初始化的过程。在这种情况下,使用适应度函数的评估利用公式(1)来完成。
G-DSM算法的具体流程如图2所示。
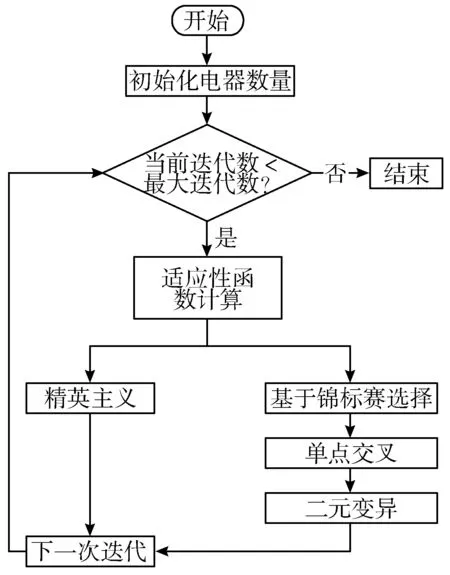
图2 G-DSM算法主要流程
在每一次迭代中,通过交叉和变异产生新的染色体群体。本文中主要采用单点交叉和二值变异。算法的收敛性取决于交叉率和变异率。较大的交叉率意味着较快的收敛速度,较大的变异率意味着较优解的丢失,导致算法过早收敛。有时,在遗传算法的早期就发现了近似最优解,但由于交叉和变异而使得近似最优解丢失。对于该问题的最好解决办法是从数量上进行统计。精英主义(Elitism)被用来记住这个解决方案,并将其代代相传。在现有种群的基础上,采用基于锦标赛的选择方法形成新的种群,当满足生成条件时,算法终止。具体G-DSM算法如下:
算法1G-DSM的调度算法
输入:电器数量
输出:G-DSM算法调度结果
初始化t=0
随机初始化代表不同模式电器的种群的数量
Whilet<24:
利用公式(1)计算适合性
从满足约束条件的最佳种群中选择模式,这个模式即为染色体,代表解。
检查染色体中的所有设备状态,
Ifxab=1,la=la-1
Fork=1 to种群规模
选择随机的2对染色体
IfPc>rand1
交叉这对
End
IfPm>rand2
通过变异选择下一代(迭代)
End
End
End
t=t+1
End
在算法中Pc代表交叉率,意味着个体交叉产生的后代个数与总个数的比值,虽然较大的交叉率代表着得到最优解的概率大,但是会增加运算开销。所以一般Pc取值为0.6~1。Pm代表变异率,表示种群中突变的基因占总基因的百分比。如果突变率太小,则无法对基因进行筛选,如果突变率太大,则好的基因会出现丢失。所以Pm值的范围是0.005~0.01。
3 实验与结果
3.1 实验部署
本文数据分析平台使用了Apache Spark工具。相对于目前主流的数据分析平台,Apache Spark的运算速度更快。相对于Hadoop,Spark的运行速度是其的100倍,并且更适合解决迭代问题[20-23]。与Hadoop和其他数据分析工具相比,Spark是一款轻量级软件。Spark在独立和群集模式下工作。Apache-Spark支持诸如Ntfs、Ext、Hadoop等分布式文件系统,与其他大数据处理工具相比,处理时间和处理所需的内存都非常少。Apache Spark支持的编程语言有Java、Scala、Python SQL和R等。本文主要使用Java编程语言对算法进行了实现。
3.2 实验结果
将算法应用于济南市甸新佳园和平里4号楼的用电需求调度管理中。该栋楼一共有8种不同类型的1000多台不同额定功率的可控基本家用电器。一般来说,居民区负荷具有低功耗和小占空比的特点。不同类型的家用电器及其额定功率见表1。
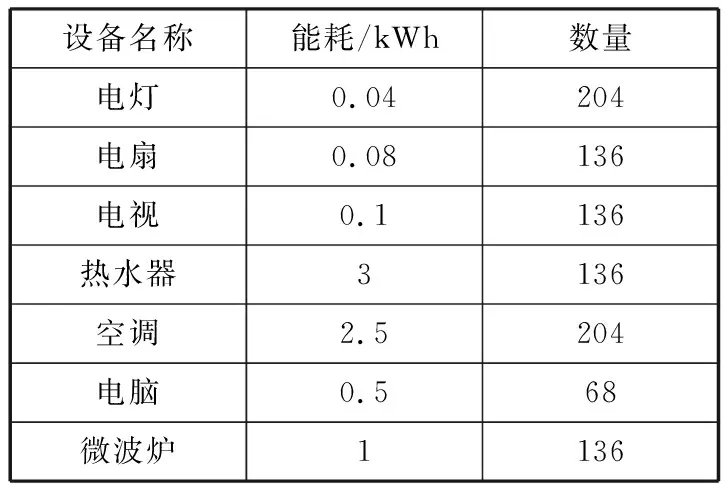
表1 居民区的可控设备
实时定价数据如图3所示。
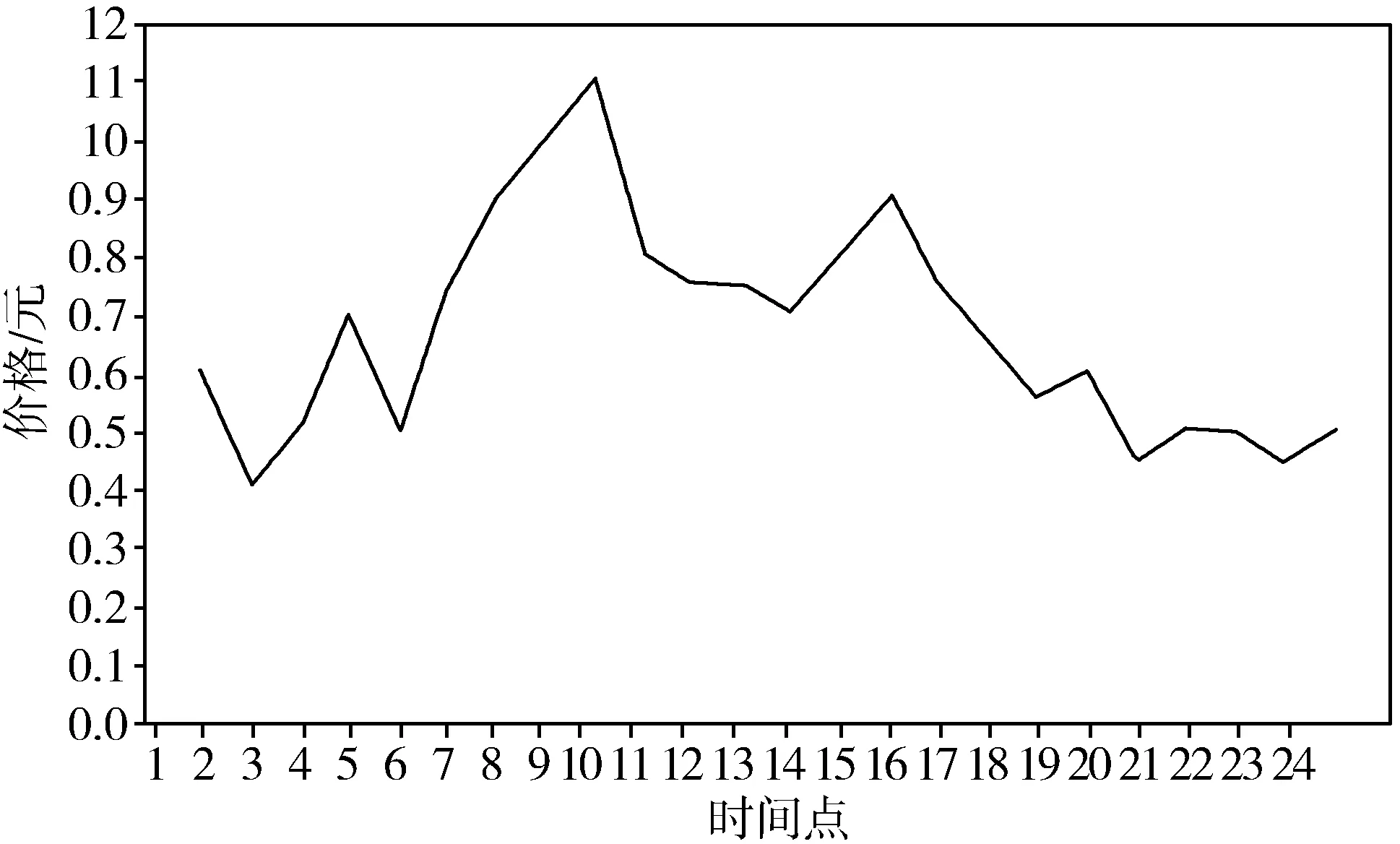
图3 实时电力定价图
通过智慧电网使用G-DSM算法进行调度的运行结果与未施行G-DSM算法结果对比如图4~图6所示。
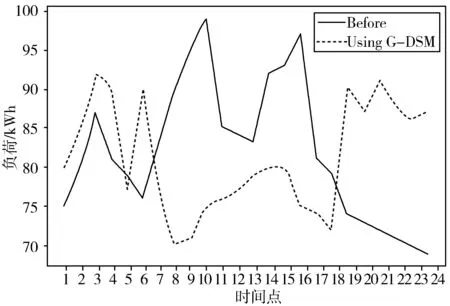
图4 规划前和规划后和平里4号楼每天电力消耗对比图
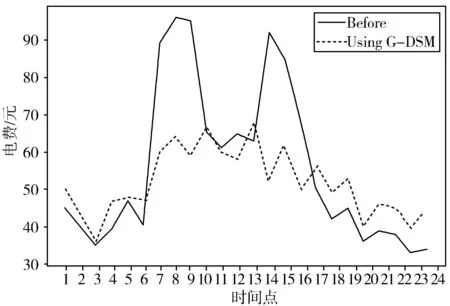
图5 规划前和规划后和平里4号楼每天用电花费

图6 规划前后住宅区域能耗对比图
通过实验结果可知,所提出的G-DSM方案能够有效地管理所选区域内的大量可控负载。该算法通过改变负载来最小化成本和峰均比,家庭用户可以在价格较低时安排其最大负荷。从图4中可以清楚地看出,居民楼的峰值负荷从98.8 kWh降至91 kWh,峰值负荷降低了约7.96%。图5中,用户通过适当的负荷调度,将每日电费降至最低,电费从每天1367元减少到每天1269元,每天电费减少了约7.13%。
一般来说,住宅区有大量的可控电器,图6显示了将G-DSM算法应用扩大到整个小区(共10栋楼)的调度结果,并与算法应用前的情况进行了对比。从图中可以看到,通过G-DSM算法,整个规划后的一天用电消耗的差有明显的下降,并且一天中的用电消耗较为平均。因此,针对RTP信号,居民区域用电负荷得到了有效的管理。
4 结束语
本文研究了DSM在新兴智慧电网中的应用效果及其对消费者行为的影响。目前,通过适当的优化算法和技术来实现最优的负荷调度已经成为人们关注的焦点。在研究工作中,本文利用遗传算法提出了多种类型可控电器的G-DSM算法,将负荷调度问题定义为成本最小化问题,并用遗传算法求解,实验结果表明,G-DSM可使济南甸新佳园和平里4号楼住户有效地利用电力能源,并且减少了用电开销费用。整个G-DSM算法可以运用于整个智慧电网,尤其是在配电网络中,通过降低峰值负荷需求,提高了配电网的容量和可靠性。该策略非常适用于未来的智慧电网。
猜你喜欢
经营者(2023年10期)2023-11-02 13:24:48
新高考·高二数学(2022年3期)2022-04-29 05:08:09
新高考·高二数学(2022年3期)2022-04-29 05:08:09
文萃报·周五版(2022年14期)2022-04-12 23:56:30
中国化肥信息(2021年12期)2021-04-19 12:25:22
中学生数理化·中考版(2020年12期)2021-01-18 06:59:44
中学生数理化(高中版.高二数学)(2020年11期)2020-12-14 07:36:40
中国品牌(2019年10期)2019-10-15 05:56:42
小学生必读(中年级版)(2018年10期)2019-01-04 05:11:10
电子制作(2018年17期)2018-09-28 01:56:56
