
基于CART分类算法的学生在线学习行为评价研究
2020-09-11 08:01:30杜宇
云南民族大学学报(自然科学版) 2020年4期
杜 宇
(云南交通职业技术学院 交通信息工程学院,云南 昆明 650500)
全面了解学生学习过程的影响因素,关注每一个学生个体的差异表现,根据学生的个性学习特点,对学生个体的学业情况重新数字画像,是教育大数据的重要应用.对学生学习行为进行评价并不仅仅是为学生的学习结果划分等级,而是使用大数据分析方法对学生学习行为进行数字画像,并全面地评价学生学习过程质量.其主要应用包括:①数字画像.基于大数据分析的学习行为数字画像,能清晰地看到学生各阶段学习行为带来的不同影响和结果,能准确刻画出不同学生个体的学习特征.②风险预测.风险预测可以帮助教师根据学生的阶段性学习情况,预测后面学习中将可能出现的不好的结果,及时发现学生在学习过程、教师在教学过程中出现的问题,找出解决方案,反馈教学过程,让教师提前对这部分学生提出警示,调整学习路线,改进教学策略.③激励.科学合理的学习评价可以激发学生学习的内在动力.学生可以在学习评价数据中清晰地了解到自己在学习中成绩的进步及付出的努力,同时也能通过学习中出现的问题和不足转化为努力学习的动力,激励自己不断地前进.④学习导向.学习评价具有很重要的导向作用,评价的结果可以帮助教师了解教学的不同阶段,学生的不同学习情况,为教学者调整教学目标和教学内容起到重要的指导作用.
1 学生在线学习行为特征分析
不同的网络学习平台对学习数据的归类方法不同,但所反映的行为含义是一致的.本文的研究数据全部来源于“超星”学习通网络学习平台记录的学生学习行为数据.根据对学习通平台的调研,以及学生实际使用情况,平台主要自动记录了教与学过程中的三类数据:学生上课活动量,主要是学生课中的活动轨迹.包括签到数、投票数、选人数、抢答数、评分数、测验数(课中测)、问卷数、分组任务数、在线课堂(参与率)数;学生课程完成情况,主要是统计学生完成各种学习任务的数量.包括任务点完成数(教师发布的各项学习任务完成情况)、视频点完成数(微课视频、操作演示视频的观看情况)、作业完成数(课后作业完成情况)、章节测验(章节测验情况)、考试完成数(期中、期末考试次数);学生学习访问量趋势,主要是从学生、班级、课程3个角度记录学生使用学习通平台访问课程资源的次数,包括本学生访问量、所在班级访问量、课程整体访问量.
1.1 数据预处理
本文的模型实际运用场景为课程学习学期中,学生未进行期末考试前,给学生进行学习总体情况数字画像,并对综合成绩进行风险评价.教师根据预测的评价结果对学生进行个性化学习指导,目的是让学生对自己上半学期的学习有清晰的自我认知,并及时发现学习出现偏差的学生,使这部分学生尽快调整学习路线,最终能够通过课程考核.
基于目前云交院使用的学习通网络学习平台的数据统计,结合学生学习行为特征的分析内容,本文选取的属性值见表1.
自主学习测评表现定义为:学生在一门课程的学习中,除了上述学习行为数据能够明确地被学习平台记录之外,还会存在一些线下自主学习行为没有被平台记录到平时成绩中,把这些学习环节也考虑到特征数据中,归结为自主学习表现.但实际情况是线下的学习行为目前确实很难全面、有效地采集到,因此缺失率较大,在后面的研究中只能予以丢弃.

表1 数据特征选取
1.2 探索性数据分析
1.2.1 任务点完成率

表2 各分数段任务点完成率
其中各分数段的学生中没有完成课程任务点的占比为0百分比占比.
将成绩分布细化到5分1个组,每组学生的任务点完成率均值分布,见下图1.
从上面的图表分析可以看出,90分以上的学生,0任务点完成率占比几乎为0;60分数段以下的学生0任务点完成率占比和60分数段以上的学生有显著差异,为14%;把学习成绩分组细化后的数据表明,高分数段的学生任务点完成率明显高于低分数段的学生,其中90分数段以上的学生平均一门课程任务点完成率比80~89分数段的学生高,大约是7%.而60分数段以下的学生平均一门课程的任务点完成率不到60分数段以上学生的一半.上面数据分析表明学生登录平台完成教师发布的各项课程任务点情况在各分数段上是有显著变化的,从不同分数段的平均任务点完成率得出,学习效果好的学生普遍愿意积极配合教师完成所布置的学习任务,而学习效果差的学生,特别是不及格的学生,普遍对课程的各项任务采取消极、不学的态度.研究结果认为学生登录平台的任务点完成率对学生学习效果会产生较大影响.
1.2.2 在线学习时长
学生学习过程中另一个重要的因素还有在线学习时长,主要包括课前、课后完成教师发放的各类在线课程资源的学习时间,及有效停留时间的情况统计.反映的是学生能否主动、认真参与到预习和复习的学习环节.同样对1 022个样本进行分析,将不同学习时长的学生按照成绩分组: 90~100、80~89、70~79、60~69、60分以下.分别对不同学习时长各个分数段的学生进行统计,计算出各个分数段的学生人数占该在线学习时长总人数的百分比.实验数据见表3.

表3 各分数段不同在线学习时长占比
从表中可以明显看出,在线学习时间在100分钟以下的学生随着分数的降低而呈上升的趋势,绝大部分分布在70分以下分数段;而在线学习时间达到150 min以上的学生随着分数的降低明显快速下降,在 80~89分数段间占比较多;200 min以上在线学习时间的学生没有60分以下,在90~100分数段间明显占比较大.显而易见,能较好执行教师布置的课前、课后预习、复习任务的学生,更愿意花时间完成各项课程资源的学习,获得的学习效果与所花时间成正比,而较少花时间在预习、复习环节上的学生或者是学习习惯较差,或者是学习意志较薄弱,学习目标不明确,不能坚持完成教师布置的学习任务.能否配合教师的学习要求是将知识技能内化于心,掌握学习技能的重要标志之一,因此认为在线学习时长对学生学习效果会产生较大影响.
另外,用访问数、章节测验得分、课程视频得分、讨论数,进行相关系数求解,相关系数见下表4.
2018年将是国际大石油公司的投资拐点年,连续3年的投资下降趋势将正式结束。根据近期各公司公布的年度预算,5家公司2018年合计投资约为1000亿美元,同比小幅增长。涨幅受限的主要原因是这些公司仍要确保优先分红,同时投资者对公司的决策制约较大。

表4 综合成绩与其它变量的相关系数
2 评价模型与算法实现
明确问题和需求后,根据问题的分类,选择模型和算法.选择模型和算法考虑的因素包括:数据训练集的大小、特征的维度、所要解决的问题是否是线性可分、特征是否独立、对性能有哪些要求等.
分类问题是找出数据集中的一组数据对象的共同特点并按照分类模式将其划分为不同的类,其目的是通过分类模型,将数据集中的数据项映射到给定的类别中[1-4].回归分析反映了数据集中数据的属性值特性,通过函数表达数据映射的关系来发现属性值之间的依赖关系.本文尝试使用分类——回归的算法生成决策树模型.模型程序基于scikit-learn python机器学习库实现,使用scikit-learn中的DecisionTreeClassifier库函数进行分类.决策树算法采用CART树算法.
研究实验当中使用了如下2种方法进行预测,即分类和回归.
分类:给定某个学生学习行为特征为‘优’、‘良’、‘中’、‘低’四类
回归:给定某个学生学习行为特征量化为分值.
2.1 分类
首先按0~19分为低等级;20~39分为中等级;40~50分为良等级;51~60分为优等级规则,对连续的学生成绩离散化处理.
对所有特征归一化处理.将数据集按8∶2比列划分训练集和测试集.
建立决策树模型,得出分类正确率,见下表5.
对分类树模型进行参数调优.用GridSearchCv寻找决策树分类模型的最好参数.当采用Gini系数计算不纯度,最大树深度为28,且平衡样本分类权重时,模型效果提升最明显, 也是目前的最佳模型,正确率达到了0.914 729.
测试模型在训练集的正确率为1,在测试集的正确率为0.941 7.
利用Graphviz库模型可视化.
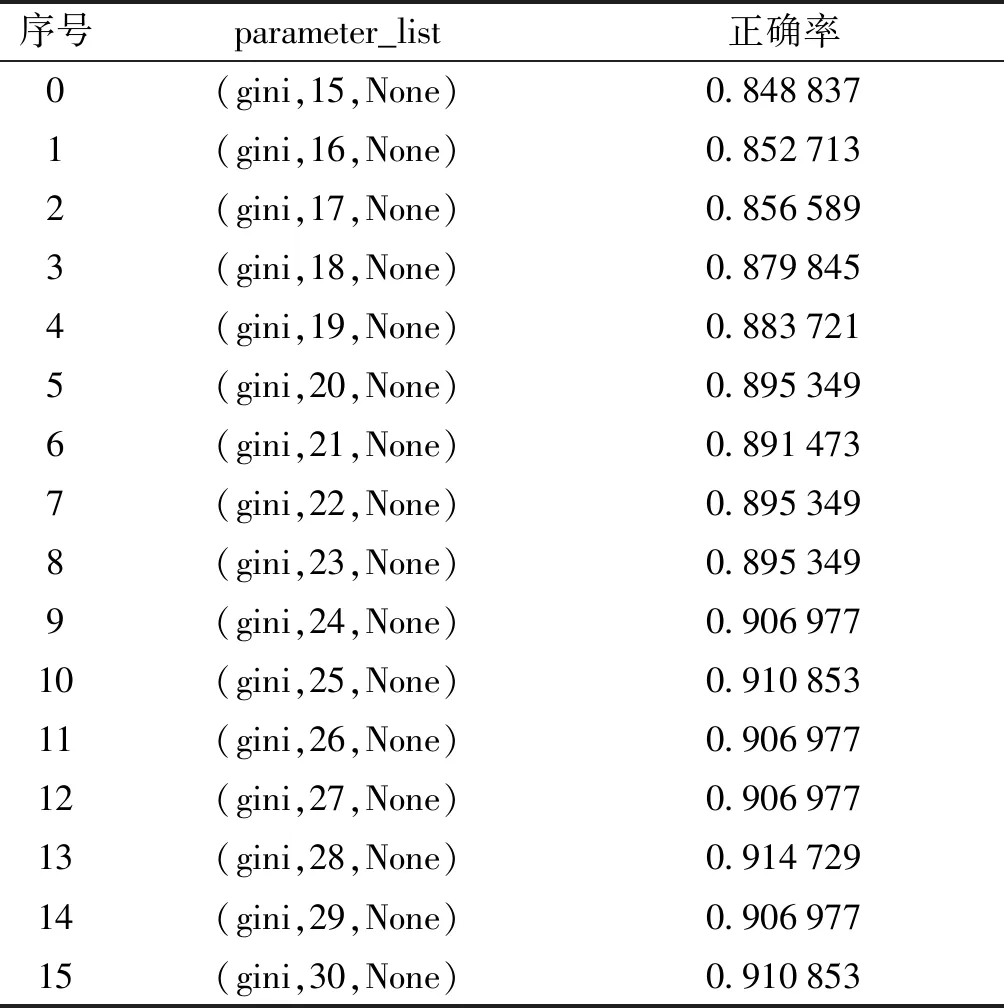
表5 分类正确率
2.2 回归
首先画数据相关性图,观察各数据之间的关系.
对数据进行归一化处理.
用GridSearchCv寻找决策树回归模型的最好的参数.Max-depth 树的最大深度,防止模型过拟合.Max_featurs 最大利用几种特征进行决策.
测试模型在测试集上的表现:训练集上的误差 0.195 063 689 179 375 44,测试集上的误差 3.298 117 475 728 157 3.见图2.
利用Graphviz库模型可视化.
输出预测变量特征重要性:

表6 输出预测变量特征重要性
可以看到对综合成绩的高低影响中上面5个特征值影响最大.其中在线学习时长的影响性最高,其次是任务点完成率和章节测验得分,课程视频得分、讨论数也有一定的影响.总体来说,大部分因素对综合成绩的高低都会产生影响,即学习结果是受到多个因素共同影响的,过去单独以一两个结果性数据来评价学业质量的方式是不全面和客观的.
2.3 模型验证
利用一组测试数据对实验模型进行五折交叉验证平均值评估模型性能.不重复的将训练集划分为5份,其中4份用于模型的训练,剩下一份用于测试.利用一组测试数据对实验模型进行性能测量,测试数据中总共包括257个学生的学习信息数据,其中有69个学生为有风险的,188个学生为没有风险,总体正确率为91.7%,符合预期.见表7.

表7 五折交叉验证评估模型性能
3 评价模型的应用
基于学习效果影响因素的重要性排序关系,对网络学习平台的学习行为进行权重设置.
通过上述学习行为数据的实验分析可知,对学生期末综合成绩影响最大的5个特征因素,分别是学生在线学习时长,任务点完成率,章节测验得分,课程视频得分及讨论数.因此,教师利用网络学习平台进行课程建设时,可先将反映这5个特征的权重设置为:学生在线学习时长(包括课程访问数、课程资源阅读数及课后作业)共占40%;任务点完成率(包括各项课堂互动活动、签到)共占25%;章节测验得分占15%;课程视频得分(主要是课前慕课学习)占10%;讨论数(包括对讨论话题的回复、讨论区对课程内容的发帖)共占10%.其次,在课程开始一段时间之后,可以以一月时间为数据采集周期,在综合成绩风险评价模型输入包含学生5项主要学习特征的行为数据,模型输出学生综合成绩所属“优”、“良”、“中”、“低”的类别,从而对每个学生的阶段性学习进行一次风险评价.对处于“中”、“低”类别的学生,还应给出该生当月学习评价报告.报告具体内容包括“学生上课活动量情况”、“学生课程完成情况”和“学生上课访问量趋势”,依据这3个维度的统计数据形成学生学习画像,并从前面分析的五个主要学习特征值给出分析说明,最终得出学生的个性化学习指导意见.
从阶段性的学习风险评价结果中,教师对学生当前的学习状况能有一个较为客观的了解,并观察到学生在学习过程中是否偏离了正确的学习轨道,是否存在期末综合成绩不及格的风险.对于有不及格风险的学生,教师对照“学习评价报告”中存在风险的特征指标,对学生进行谈话、了解,帮助学生分析产生风险的原因,并对这类学生的学习过程进行及时干预,有针对性地改善学生学习效率.
利用大数据分析方法的学业诊断评价不是最终评价,而是学生在学习过程中的阶段性评价.教师同时可以在教学的各个阶段利用学习评价模型对学生进行评价.所得出的评价结果可以让教师清晰地了解到教学的各个阶段学生的学习情况,对学生进行个性化的学习指导,并且根据预测风险学生人数的多少及时了解教学中出现的问题,改善教学策略.
4 结语
随着教育大数据研究应用的深入,研究者和教育者都尝试利用大数据的方式优化教学,并应用到教学的各个环节[5-9].智慧网络学习平台的推广应用为记录学生学习行为提供了数据基础,但如果对记录的数据不做进一步的深入计算,教育者仍然观察不到学生的学习过程,不能了解每个学生的学习情况,也无法对他们进行针对性指导,提高学生的学习效率,改善教师教学策略.因此,本文尝试使用机器学习算法中的CART分类算法,针对学生在线学习行为数据展开详细的分析、计算,以期建立学生成绩风险评价模型.模型可应用于针对学生的阶段性学习结果,反馈学生的学习状况以及教师教学情况,预警学习效果有风险的学生及时调整学习路线,教师调整教学策略.同时学生也可以及时、客观地了解目前的学习状况,引导、促进学习者的学习.该研究也可以为其它课程的学习监控和指导个性化学习提供机器学习模型,并为后续个性化学习服务方案提供了大数据实践应用的借鉴经验.
当然,目前的研究中还存在许多局限性,比如数据质量问题.笔者所在学校推广使用的学习通网络教学平台所记录的学习行为数据与教师实际教学过程中呈现的数据还存在一定的偏差,学习行为指标还不能完全贴合实际.其次,学校信息化建设的程度还有待进一步提高,各个部门的业务数据还未实现共享,比如学工处数据目前还不能与学习行为数据互通互访.最后,现阶段教学者信息化教学意识不强,普遍习惯于传统的教学模式,教学过程中没有把反映学生学习行为的指标设计到教学方案中,致使许多学习行为指标没有得到留存,数据记录较少,或是数据统计特征值不规范,缺失率较高.因此数据与理想中预期差别较大,导致研究产生局限性.今后,可以继续对学习资源数据特征数字化,进一步挖掘个性化学习的另外2个维度:个性化学习内容和个性化学习方式,实现更进一步的个性化学习服务,即个性化内容的推送,和个性化学习空间的划分.
猜你喜欢
山西教育·招考(2023年6期)2023-08-06 16:47:05
山西教育·招考(2022年6期)2022-07-11 23:08:08
中国西部(2022年2期)2022-05-23 13:28:06
当代县域经济(2022年4期)2022-04-08 19:48:24
石油沥青(2021年4期)2021-10-14 08:50:44
军民两用技术与产品(2021年12期)2021-03-09 05:38:36
山西教育·招考(2020年6期)2020-08-10 09:06:08
山西教育·招考(2019年4期)2019-09-10 07:22:44
新课程·下旬(2017年11期)2018-01-22 08:53:46
中国教育技术装备(2015年19期)2015-03-01 02:43:07
