
大学生上网行为关键字匹配引擎的研究和应用
2020-09-10 07:22:44张兰
环球市场 2020年3期
张兰

摘要:随着社会快速的发展,人们生活节奏越来越快,各方面的竞争越来越激烈。比如在校大学生的就业、学习、生活、爱情和自我意识等方面经常会遇到心理失衡等问题。大学生心理危机的早期识别和预警对于高校降低和减少因心理问题而导致的意外伤害事件具有重要作用。如今网络、数据等概念已经十分紧密地渗透于人们的生活、学习和工作中。一个大学生使用移动设备一天产生的数据流量可能高达数百兆。借此我们采用的Intel开源的Hyperscan引擎,利用大学生上网流量的关键字匹配技术,来分析其上网行为数据,可达到快速有效的对大学生心理危机进行识别和预警。
关键词:关键字;匹配;引擎;上网行为
一、引言
在互联网普及的时代,人们的生活都离不开手机等移动终端,而大学生是其中最主要的群体之一。近年来,在校大学生除了专业课程的学习和能力培养外,其心理健康问题也越来越受重视。大学生作为祖国未来繁荣发展的栋梁之材,我们更应该关注他们身心的健康发展,通过其上网行为分析,发现有心理问题的隐患,并进行有针对性的预警和介入,将这些隐患扼杀在萌芽状态,避免酿成一些无法挽救的悲剧。
上网用户行为的研究与心理学、社会学、社会心理学、人类学以及一切与网络行为的学科密切相关。具体讲网络用户行为研究就是分析网络用户的构成、特点及其行为活动上所表现出来的规律[1]。从行为学的角度,个体网络行为是单个个体在网络上所表现出来的行为,是由个体的个性决定的,短期的个体行为可能并不具有明显的规律,但长期的个体网络行为则具有一定的稳定性。因此,对用户上网行为的研究是具有现实意义的。本文重点在研究传统的字符串匹配技术与更适合大规模流量数据的关键字匹配技术Hyperscan引擎,并将其应用于大学生上网行为分析与心理预警领域。
二、传统关键字匹配算法的相关研究工作
关键字匹配也称字符串匹配、模式匹配,一直是计算机科学的研究热点,尤其是信息时代数据爆炸式的增长对字符串匹配算法的性能提出了更高的要求。字符串匹配算法根据不同的需求类型可分为单模匹配、多模匹配、正则表达式匹配等。经典的算法在整个字符串匹配算法的研究过程中起到了举足轻重的地位,后续大部分算法都是在经典理论基础上进行改进,下面分别介绍不同类型算法中最具代表性的典型算法。
(一)AC算法
在多关键字匹配算法中,最著名的要数由Aho和Corasick在1977年提出的基于前缀搜索的AC算法,该算法是基于有穷自动机的,从前往后进行匹配,自动机建立过程建立三个函数:状态跳转函数goto,输出函数output,失效函数failure。匹配过程是从零状态出发,每次扫描文本中的一个字符,在当前状态情况下,查看扫描到的字符,利用94盛。函数、failure函数跳转到下一个状态。如果跳转到的状态的outpul函数不为空,表示命中了某个关键字,输出该关键字[2]。
(二)Wu-Mamber算法
Wu-Mamber算法是基于后缀搜索的多模匹配算法,通过使用所有模式中最短串的长度作为扫描窗口,并且每次从后扫描两个字符,来提高扫描效率,另外使用了哈希技术,建立三个表Shift表、Prefix表、Hash表,利用Hash算法将扫描到的两个字符映射成不同的hash值存放在不同的表中。Wu-Mamber算法具有初始化时间短,内存占用少的特点,但匹配速度不如AC算法稳定,当字符不能等概率出现时容易造成匹配速度下降,并且Wu-Mamber算法是对所有模式中最短串的长度敏感的。
(三)SBOM算法
SBOM算法是基于子串搜索的多模匹配算法,一般在当前窗口内从后向前扫描,能够识别模式串集合P中的某个模式串的子串,并在此基础上进行比较验证。较早出现的基于子串的多模匹配算法是Multi-BDM,由于实现复杂,实际很少使用。SBOM算法使用了FactorOrack这一数据结构。在进行预处理过程中将根据所有模式串构造模式匹配的Oracle结构,以匹配窗口的最长字串。
三、Hyperscan引擎
对于精确字符串匹配,过去的几十年里从理论到技术都己经进行了深入的研究,并取得了重大的突破,出现了多个接近理论性能卜限的算法,如AC、WU-MANBER、SBOM等等。这些经典算法在网络安全检测中发挥了巨大的作用。.然而,随着网络的不断发展,攻击者也在不断地针对各种安全检测技术进行躲避和隐藏,这使得网络中关键字检测变得越来越复杂,简单的精确字符串模式已经难以准确地描述其特征。因此,正则表达式以其强大、灵活的表达能力,迅速成为描述新一代规则的主要工具。
(一)常规的正则表达式匹配算法
正则表达式构造了一系列字符串规则,使得文本处理变得更加灵活方便,但是也给匹配算法提出了难题。通常正则表达式匹配过程如图所示。首先将正则表达式构造成一颗解析树,再根据一定的方法将解析数转化为非确定的有穷自动机侧(NFA)。下一步直接使用NFA进行搜索的优点是内存占用小,但在处理每个字符时,处理活动集合中的状态都必须被逐个处理,匹配时间慢.若将NFA转化为DFA来处理,那么一个字符则的后续状态只有一个,但当所有状态编译成DFA时,会造成巨大的内存消耗,当前的硬件条件无法满足如此大的内存需求。因此目前的研究热点在于如何调和NFA与DFA在时间和空间上的矛盾。
(二)Hyperscan正则表达式引擎
Hyperscan是一款来自于Intel的高性能的正则表达式匹配库。它是基于X86平台以PCRE为原型而开发的,Intel将此高速正则表达式匹配引擎Hyperscan開源了,基于BSD许可[3]。这个基于自动机的引擎经过了多年开发,经过不断优化与完善,效率非常之高,虽然没有pcre等对正则语法支持全面,但非常适用于网络设备。用户可以在网络设备数据面使用Hyperscan进行规则匹配,实现高性能网络流量数据包检测分析等应用,其工作流程主要分成两个部分:编译期(compiletime)和运行期(run-time)[4]。
1.编译期
Hyperscan自带C++编写的正则表达式编译器。它将由正则表达式形成的n条规则作为输入,针对不同的IA平台,用户定义的模式及特殊语法,经过复杂的图分析及优化过程,生成对应的数据库。另外,生成的数据库可以被序列化后保存在内存中,以供运行期提取使用。
2.运行期
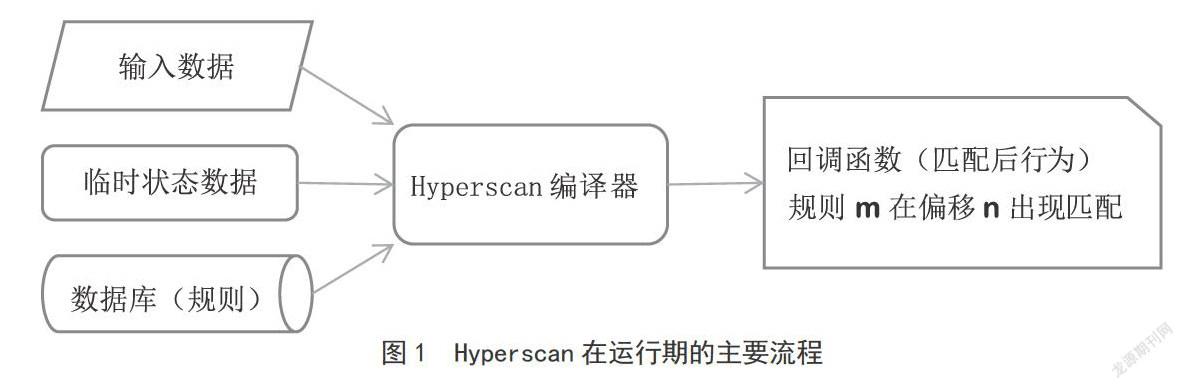
Hyperscan的运行期是通过C语言来开发的。图1展示了Hyperscan在运行期的主要流程。用户需要预先分配一段内存来存储临时匹配状态信息,之后利用编译生成的数据库调用Hypemcan内部的匹配引擎(NFA,DFA等)来对输入进行模式匹配。Hyperscan在引擎中使用Intel处理器所具有的SDvID指令进行加速。同时,用户可以通过回调函数来自定义匹配发生后采取的行为。由于生成的数据库是只读的,用户可以在多个CPU核或多线程场景下共享数据库来提升匹配扩展性。
Hypersca归支持Intel处理器多平台的交叉编译,且对操作系统无特殊限定,同时支持虚拟机和器场景。Hyperscan实现了对PCRE语法的基本涵盖,对复杂的表达式例如“.*”和“[^>]*”不会有任何支持问题。在此基础上,Hyperscan增加了不同的匹配模式(流模式和块模式)来满足不同的使用场景。
根据规则复杂度的不同,H即~能支持几万到几十万的规则的大规模匹配。与传统正则匹配引擎不同,Hypcxscaa支持多规则的同步匹配。在用户为每条规则指定独有的编号后,Hypercan可以将所有规则编译成一个数据库并在匹配过程中输出所有当前匹配到的规则信息。
四、大学生上网行为关键字匹配实验
首先利用抓包软件获取网络应用的通信报文,对报文进行协议分析,并通过端口、地址以及应用层净荷(关键字的相关信息)的横向对比分析,得到其独有的特征作为识别的关键,包括源端口、报文方向、报文长度、地址、动作类型、优先级、规则等。而这些规则可以写在一个单行上,或者在多行之间的行尾用分隔,各条规则之间用分号隔开。
实现匹配的流程为:首先是初始化、将上述构造的正则表达式输入Hyperean,编译成内部的模式数据库,同时分配运行时的状态保存空间。之后,对每条输入的HTTP报文进行模式匹配,对于每条报文都需要提取多个字段,在Hyperean匹配过程中,通过回调函数和所匹配编号《每条输入的正则表达式均有唯一的一个编号对应),在相应的结构体中记录所提取字段的起始位置和长度;这边的结构体是共用的,需要在匹配完成后,判别当前到来的是请求报文还是响应报文,重新保存到数据报文所对应的结构体中,其流程图参看图1的Hypersean匹配主要流程图所示。
本次对比实验选取的正则表达式,既有纯字符串,又有各种正则规则,测试运行于Intel Xeon E5-2699@2.30GHz的单核上,选取本地随机数据(750K)作输入循环2000次。Hyperscan完成测试的用时以及吞吐量如表1:
从结果可见,采用此关键字匹配引擎处理网络流量的吞吐量达到若干G以上,而完成所有规则匹配时间仅5秒不到。因此,在网络场景中,同一规则库往往需要匹配多条网络流,而日夕伴rean的高扩展性为此提供了有力的支持。同时可以看出,将日Lyperscan引擎用于对大学生上网行为数据的关键字检测匹配是高效、准确的可行方案。
参考文献。
[1]黄光球,胡晓婷,刘通.基于突变理论的网络异常行为分析方法[J].微电子学与计算机,2006.
[2]李伦,李东,田志宏.一种针对大规模URL关键字的多模匹配算法[J].智能計算机与应用,2o1).
[3]李建山高性能采集软件关健技术研究和实现[D].北京邮电大学,2017
[4]邰仕强.基于运营商大数据和深度学习的OTT终端识别技术的研究与实现[D].南京邮电大学,2019.
猜你喜欢
华人时刊(2022年1期)2022-04-26 13:39:28
动漫界·幼教365(大班)(2019年10期)2019-10-28 01:54:09
商周刊(2017年22期)2017-11-09 05:08:31
现代经济信息(2016年27期)2016-12-16 08:58:39
移动通信(2016年20期)2016-12-10 09:37:34
科学与财富(2016年15期)2016-11-24 13:48:34
中小企业管理与科技·下旬刊(2016年10期)2016-11-18 20:00:08
河南电力(2015年5期)2015-06-08 06:01:46
皖西学院学报(2015年5期)2015-02-28 17:52:46
智能计算机与应用(2011年4期)2012-05-15 02:24:18
