
消费信贷智能决策模型系统设计与实现
2020-09-10 12:29杜一谦
中国新技术新产品 2020年13期
杜一谦
摘 要:消费信贷风险管理是一个广交的领域,其中银行的内部控制更是变化多端。为了提升风控核心竞争力,基于先进的数据仓库Hadoop技术建立银行信用贷款的智能决策系统,并运用多种数据挖掘及分析工具,充分利用银行现有数据,通过决策引擎及模型接口实现智能决策引擎风险识别和防控,判定银行是否应该发放贷款。该系统的建立对银行信用管理和风险预测具有指导意义,为银行消费信贷业务的拓展提供参考和依据。
关键词:消费信贷;智能决策;大数据技术
中图分类号: TP311 文献标志码:A
0 引言
近年来,随着我国经济转型升级逐步推进,消费金融行业进入了快速发展时期。面对愈加严峻的互联网风险环境,大数据、人工智能等技术逐渐进入消费信贷决策领域,科技与金融的结合日益严密。生物识别、OCR技术、用户画像、反欺诈模型、信用模型等技术成为必不可少的核心信贷决策环节。
随着外部市场环境的不断变化,仅仅依靠传统的信贷决策方式已不能满足银行消费信贷业务发展的需要,正确及时地决策成了银行业各机构生存与发展的重要保障,智能决策模型系统的搭建(以下简称“系统”)至关重要。
1 系统设计思想
智能决策引擎模型系统的设计需要结合业务实际,做到功能完备的同时,又具有可發展性,能够应对未来的市场变化。系统的设计主要考虑以下3个方面。
1.1 多维识别,防范欺诈
消费信贷业务前端一直面临着大量欺诈客户的攻击,随着身份伪冒、团伙欺诈等风险愈演愈烈,科技反欺诈成为系统中必不可少的一环[1]。首先通过内嵌人脸活体识别、指纹识别、声纹识别等前端生物识别技术进行客户身份认证。其次通过银行卡四要素鉴权技术,进一步进行客户身份核实。最后通过OCR等文字识别技术,进行申请资料的识别,将纸质或图像材料转为电子化信息,使其能够供决策模型系统后续使用。
1.2 海量数据,流畅运行
随着业务的不断发展,沉淀的数据量及数据维度呈指数级增长,传统的Oracle数据库架构在运行高维、大批量数据时显得力不从心,模型迭代进度受数据处理速度制约。
在该背景下,系统设计搭建基于Hadoop框架的大数据平台,采用非结构化的数据存储方式和分布式计算功能,使模型开发在大数据运算过程中更加灵活和高效。
1.3 实时决策,智能预警
智能决策引擎模型系统主要运用于自动化审批,对于系统的实时处理能力有着极高的要求。同时,高并发的审批过程也会伴随一定概率的错误进程,需要建立智能化的预警机制。
系统设计采用“决策引擎+Python模型接口”的方式,扩展自动化审批功能的同时,大幅缩短单笔审批时间。同时,系统需要通过设置相关策略,实现对单位时间内申请量、审批结果等统计信息的实时预警,帮助业务人员及时发现并快速解决问题。
2 系统结构
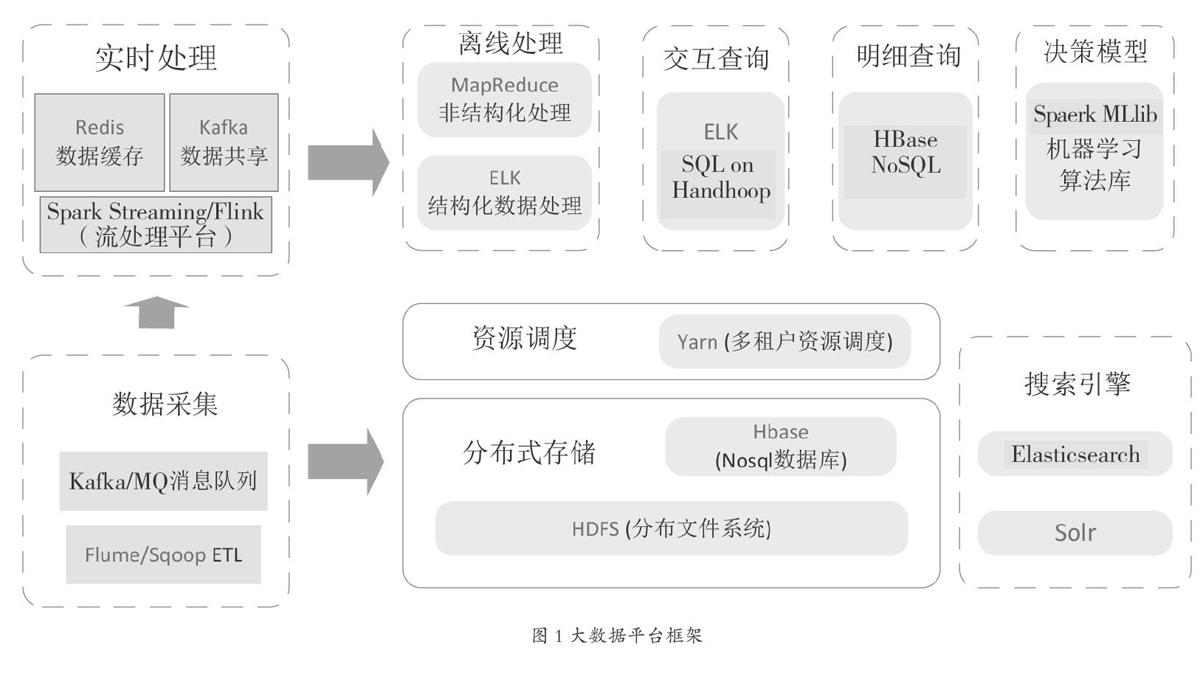
智能决策模型系统以大数据平台(Hadoop)和数据仓库(MPP)混合架构的大数据基础体系,为后续数据应用奠定了坚实基础(如图1所示)。
大数据平台负责历史数据、外部数据、非结构化数据、数据挖掘、客户画像、风控、智能决策等场景的支撑,数据仓库负责传统报表、指标等统计分析场景,两者相辅相成,共同支撑着整个数据条线的应用。
2.1 数据采集
利用大数据平台自带的数据采集组件Flume、Kafka、Sqoop,兼容各种数据源,包括流式数据(业务消息流/日志消息流等)、磁盘文件、各种数据库、其他存储系统等。采集后的数据落地到大数据平台分布式存储中,其中流式数据也可不落地直接进入实时处理应用中。
2.2 分布式存储
利用大数据平台HBase组件和HDFS组件的特性,对海量非结构化数据进行存储,支持无限拓展,线性扩展能力强,数据存储灵活。
2.3 资源调度
多租户是大数据平台大数据集群中的多个资源集合,具有分配和调度资源的能力。资源包括计算资源和存储资源。多租户将大数据集群的资源隔离成一个个资源集合,彼此互不干扰,用户通过“租用”需要的资源集合,来运行应用和作业,并存放数据。在大数据集群上可以存在多个资源集合来支持多个用户的不同需求。
2.4 实时处理
大数据平台内存数据库Redis、分布式消息队列Kafka和实时处理引擎Flink,对数据进行分布式计算,实现实时数据传输、实时数据缓存和实时数据流处理的高速处理。为智能预警和智能决策系统提供实时准确的数据服务。
2.5 离线处理
Spark和ELK为海量结构化数据和非结构化数据的离线分析处理提供技术支撑。
2.6 决策模型
基于Spark架构预置机器学习算法库和数据分析挖掘算法,提供可视化分析挖掘平台,构建实时反欺诈平台和模型训练平台。以用户数据、画像及行为的关系网络为基准,通过反欺诈模型、信用模型等进行风险分析决策,完成贷前准入、贷中监控、贷后管理的信贷全生命周期管控流程。
3 业务支撑及实现
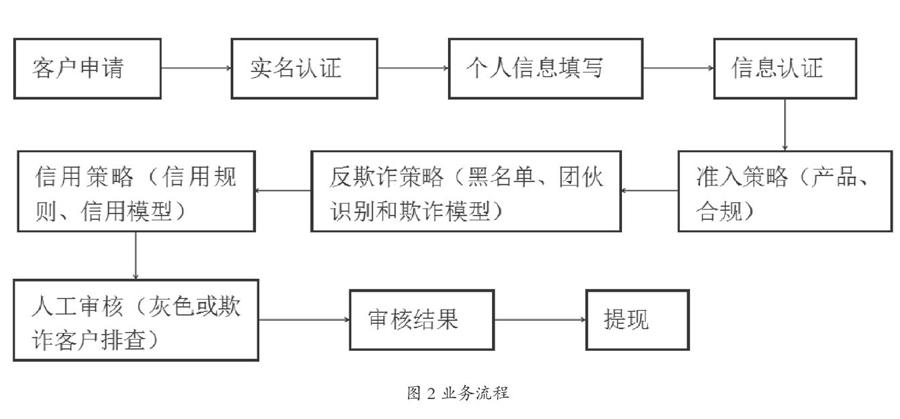
业务流程如下:客户在信息认证界面,需要进行基础认证及提额认证,其中基础认证包括填写联系人、身份证认证(上传身份证照片正反、进行活体认证和人脸识别、OCR解析并由系统判断身份证有效期)、银行卡绑定(进行四要素验证)。提额认证主要包括人行及各类其他征信源查询授权如图2所示。
客户提交贷款后,系统首先进入准入策略,筛查掉不符合公司合规要求及产品对应策略要求的客户,然后,通过反欺诈策略拦截内外部黑名单、严重多头及命中强关系欺诈规则的客户,再进入信用策略,通过人行征信和自建的子数据源等模型划分客户资质和分类,评估客户风险等级,并匹配对应额度和定价。对于评分灰色区域(评分在拒绝阈值左右)客户和反欺诈策略给出的欺诈团伙、黑中介等属性客户,进入人工审核环节,跟进并确认客户的欺诈风险和信用风险。审核通过后,短信通知客户审核结果,提醒客户后续做好还款准备等工作,并放款至绑定的银行卡。
4 风控模块及其安全性
决策模型主要运用于自动化审批,对于系统的实时处理能力有着极高的要求[2]。同时,高并发的审批过程也会伴随一定概率的错误进程,需要建立智能化的预警机制。
4.1 反欺诈模块
反欺诈模块由身份验证、黑名单、团伙识别、反欺诈模型等多个子模块组成,从不同角度打击不同形态的个人与团体欺诈,可以有效防范各种欺诈形态,减少风险损失,保护客户的利益。
4.1.1 严格的身份验证
系统采用活体检测、人脸识别、OCR技术和银行卡鉴权等多种技术相结合,对申请者的身份进行严格的验证,增加身份伪冒的成本。这些环节均在信贷产品申请环节中嵌入并实时进行核验,保证了风险控制的准确性和申请时效性的平衡。此外对同一设备登录不同账号等高风险异常行为进行严格控制,有效防止账号被盗、黑中介代客下单等欺诈行为。这些技术在征信查询之前就可以对欺诈客户进行有效拦截,降低欺诈风险的同时,也可以保护客户利益不被违法分子侵害。
4.1.2 黑名单
利用历史积累的申请数据与表现数据,形成内部的黑名单并持续更新。黑名单可以对风险较高的历史客户进行快速识别,可以有效节省征信成本与系统资源。
4.1.3 欺诈团伙识别
传统的信贷审核只以单笔申请的角度对客户进行审视,无法获得不同申请之间的关联关系。而消费信贷申请的欺诈行为中,团伙欺诈占较大一部分,相较于个人欺诈也会带来更大的风险损失。团伙欺诈具有组织性强、攻击隐蔽、手段复杂等特点,传统的风险控制手段无法应对一直更新的复杂攻击手段,效率和准确率都有一定限制。针对该问题,建立了关系网络模型,通过积累沉淀信贷生命周期中的客户数据,寻找不同申请之间的关联性,并通过社群发现等图算法,定位高风险的欺诈团体。当新的客户来申请时,系统可以通过算法快速定位其与高风险欺诈团体是否有关联。关系网络模型随着数据的积累定期进行更新迭代,能应对一直更新的欺诈手段。
4.1.4 反欺诈模型
信用风险模型注重对所有客户进行分级,一般采用经典的逻辑回归算法,体现出主要特征与风险之间的线性关系。而欺诈客户一般可以通过一些手段进行包装,导致信用风险模型无法抓取极少部分人的异常行为。因此针对欺诈客户,开发了专用的反欺诈模型,对异常行为进行大量的特征衍生,采用随机森林、梯度提升决策树、神经网络等机器学习的领先算法,抓取大量特征与欺诈风险之间的非线性关系,对异常客户进行甄别。
4.2 信用模块
系统的信用模块主要结合内外部数据,由信用规则和信用模型组成,对客户进行风险评级。
4.2.1 信用规则
根据人行报告和外部数据显示的申请人不同阶段的申请、发放、还款等行为数据,衍生出不同时间序列维度下的数据标签,从收入负债、资金紧迫性等方面评估申请人的还款意愿和还款能力,形成强风险规则组合。
4.2.2 信用模型
信用模型运用数据挖掘方法,通过对客户的基本信息特征、行為记录、交易记录等大量原始数据进行分析,挖掘数据中客户存在的行为模式、信用特征,预测客户未来的信用表现。信用模型的主要功能是以科学的方法将风险模式数据化。提供客观风险量尺,减少主观判断。提高风险管理效率、节省人力成本。其主要包括2个方面的内容。1)算法研究。目前系统主要运用逻辑回归、决策树、聚类等常规算法,实现对客户的分层和评级,这些算法可解释性高、稳定性好。同时,XGB、CNN等前沿算法模型也在系统中同步运行,但由于该类算法近乎黑箱,无法有效解释其中变量与风险的关系,一旦模型出现异动,无法准确定位原因并进行有针对性地处置,同时模型稳定性较低,区分度随时间下降较快,因此仅作为主模型的补充和交叉验证。此外,在新模型迭代的过程中发现,如果建模样本中不包含拒件客户,会导致在训练过程中表现较好的新模型,迭代后业务风险反而有所上升。所以在模型开发过程中应使用拒绝推断算法,纳入历史拒件样本,更准确地评估整体样本风险,避免因模型迭代导致的风险波动。2)模型应用。为了持续筛选风险防控效果最优的模型,同时保证不同特征的客群能有一定风险表现供后期模型优化,系统中设置了一定比例的冠军挑战审批流,比较各个模型的风控效果及各类特征客户的实际表现,用于逐步优化迭代模型。在线上业务发展过程中发现,不同客群的风险表现有一定差异,根据整体客户风险表现对模型阈值采用一刀切的方式,会导致不少好客户被拒之门外,过件率较难提升。结合客户画像的研究结果,在模型评分阈值的制定上纳入了“分客群”的思想,根据客群资质灵活调整模型阈值,提升过件率的同时降低风险。
5 结语
项目上线以来,累计实现自动审批逾900万笔,服务客户逾500万人,审批时效在1 min以内,模型表现也稳步提升。该项目极大地节省了人工成本,降低风险损失,优化客户体验,借助科技创新推进普惠金融。
参考文献
[1]吴雷,杨仪,吴传威,等.基于多层架构的信用卡反欺诈系统研究[J].金融科技时代,2018(1):41-45.
[2]单良,乔杨.数据化风控:信用评分建模教程[M].北京:电子工业出版社,2018.
猜你喜欢
商展经济(2022年17期)2022-09-14
——基于期限结构视角
科技和产业(2021年11期)2021-11-23
消费导刊(2018年23期)2018-07-14
赤峰学院学报·自然科学版(2017年7期)2017-05-09
山东大学学报(哲学社会科学版)(2017年2期)2017-03-14
新媒体研究(2016年20期)2016-12-02
探索(2013年1期)2013-04-17
