
基于频繁项集挖掘的发布/订阅分布式系统运行模式识别
2020-09-10 06:50:48吴雯君沈卓炜曹玖新
网络空间安全 2020年8期
吴雯君,沈卓炜,曹玖新
〔东南大学网络空间安全学院,江苏南京 211189;网络空间国际治理研究基地(东南大学),江苏南京211189〕
1 引言
发布/订阅分布式系统是基于数据分发服务[1](DDS)中间件开发的分布式系统,构件间采用发布/订阅模式通信。系统广泛应用于各种关键领域,如自动驾驶汽车、医疗系统等。随着系统规模日益庞大,构件关联日趋复杂,其安全可靠运行面临着挑战[2]。若系统构件出现异常,可能会导致整个分布式系统失效,造成严重的损失。如攻击者利用某一构件作为攻击“入口”[3],发布某个主题的错误消息,订阅该主题的构件接收消息后执行错误操作。因此对系统进行状态监控,把握构件间的发布订阅关系,监测异常状态,保障系统安全十分必要[4]。
这类系统在正常运行过程中往往存在多种运行模式,对其开展实时监控的策略为:将系统当前的运行状态与已知的正常模式匹配,判断系统是否处于异常状态。因此,根据已有监控状态数据识别出系统中存在的运行模式,是系统异常状态监控的前提条件和基础。对于这类系统的监控工具来说,由于独立于系统,不了解其业务逻辑,只能掌握其底层通信中间件层的发布/订阅事件日志数据,因此在这类系统中识别运行模式尤为困难。
Apriori算法[5]是挖掘频繁项集的经典算法,用于挖掘数据中潜在的模式或规则,FP-growth算法对Apriori算法进行了改进,提高了运行效率。这两种算法均基于支持度阈值挖掘且以假设为前提:数据库中各个项的重要性相同且均匀分布[6]。而在大多数系统中,每种运行模式运行时长的占比不同且重要程度存在差异,按照支持度挖掘,很有可能挖掘不出运行时长短但重要的运行模式。因此,本文针对发布/订阅分布式系统的运行特点,在中间件层面采集构件的历史通信数据,利用改进的加权频繁项集挖掘算法,挖掘系统运行模式。根据挖掘结果构建的知识库对系统的异常检测工作有重要意义。
2 运行模式挖掘流程
发布/订阅分布式系统中的业务逻辑对应运行模式,改变构件间的交互关系就可切换模式。构件利用中间件分发消息,基于主题可构建构件间的交互关系。针对系统的通信机制和运行特点,设计了运行模式挖掘及应用流程,如图1所示。
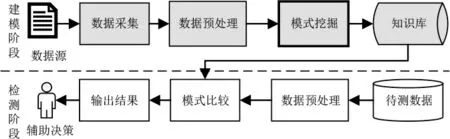
图1 系统运行模式挖掘及应用流程
发布/订阅分布式系统的监控分为建模阶段和检测阶段,在离线建模阶段利用运行模式挖掘结果构建的知识库可用于在线检测阶段的模式比较,决策者可以根据结果做出相应的判断。本文涉及的运行模式挖掘主要包括三个部分。
(1)数据采集
利用拦截器机制采集构件通信消息的相关信息,包括构件发布或订阅一条消息的时间、构件名称、主题和动作,其中动作分为发布和订阅。
(2)数据预处理
将采集的数据根据相同的主题和对应的发布或订阅动作构建构件间的发布订阅关系,形成发布订阅事件,其表示如表1所示,其中发布者和订阅者对应构件名称。

表1 发布订阅事件
根据事件集合,对每一组发布订阅关系以I1,I2…In进行标记得到发布订阅事件标记表,标记表的字段信息如表2所示。根据表2中的主题及其对应的发布者和订阅者能够得到系统的发布订阅关系拓扑图。对发布订阅事件标记得到事件序列,该序列呈现出两个特点[7]。

表2 事件标记表
1)规律性:发布/订阅分布式系统中构件间的发布订阅关系通常事先确定。当系统在不同运行模式下执行时,构件间产生的发布订阅事件是固定的。因此,同一模式下的发生的事件具有相关性,为运行模式挖掘奠定了基础。
2)重复性:系统在某一运行模式下运行时,构件会按照设定的发布订阅关系发布或接收消息,在不切换运行模式的前提下,事件序列会重复出现。
(3)模式挖掘
对数据预处理后得到的事件序列进行切分,以每个子序列中的事件集合作为一个事务构建事务数据库,应用加权频繁项集挖掘算法进行模式挖掘。对挖掘结果进行分析评估,可构建运行模式知识库,包括基本信息、模式事件和事件属性。异常检测时根据运行模式构建有限自动机进行模式匹配,以发现系统的异常运行状态。
3 加权频繁项集挖掘算法
Apriori算法挖掘频繁项集有两点不足:(1)多次遍历事务数据库效率低下;(2)以项的重要性相同为前提,完全依赖于支持度阈值,若阈值设置过高,会丢失较低频率的项集。在系统中,项对应发布订阅事件,项集对应运行模式,不同事件的影响程度存在差异,且每种运行模式的运行时长不同,事件的频次也存在差异。因此按照支持度挖掘会导致运行时间短但是重要的运行模式丢失。基于上述问题,本文提出了加权频繁项集挖掘算法,引入了项的权值概念,从频次和影响程度两个方面体现项的重要性,进一步得到事务的权值,利用加权支持度挖掘,并结合事务矩阵提高挖掘效率。
3.1 相关定义
本文对加权频繁项集挖掘算法给出的定义为:
设I={I1,I2…Im}是项的集合,在系统中对应发布订阅事件集合。事务数据库D中每个事务T都是项集I的子集,TI。
定义1 事务矩阵M
通过遍历原始事务数据库,利用矩阵M存储事务,并对事务去重、计数。当事务数据库中重复事务较多时,能够极大地压缩事务数据库[8~9]。

定义2 项的影响度
项即发布订阅事件,其影响度E(Ij)与构件间的发布订阅关系有关。影响度的计算参考了PageRank算法计算过程,该算法通过分析网页间的链接关系,对网页重要性进行评估[10]。基于构件发布订阅关系拓扑图,评估各个构件的影响度:各节点不再是网页而是构件,有向边由链接变成发布订阅关系。计算公式为:
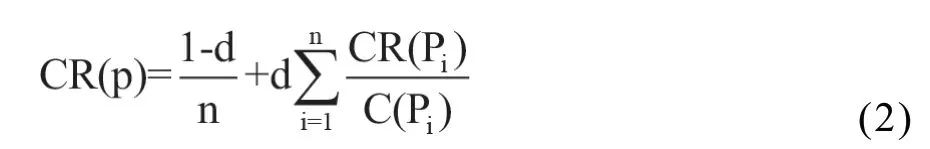
其中,CR(p)表示构件p的影响度,n为构件总数,pi表示订阅构件p的第i个构件,C(pi)表示订阅构件pi的构件数,CR(pi)/C(pi)表示构件pi传递给每个订阅者的CR值,d为阻尼因子取值0.85。E(Ij)定义为发布订阅事件中发布者构件的CR值。
定义3 项的权重
项的权重是与项的特性相关的值,设项Ij对应的权重为w(Ij),权重与项在事务数据库中出现的频次和项自身的影响度有关,权重定义为:
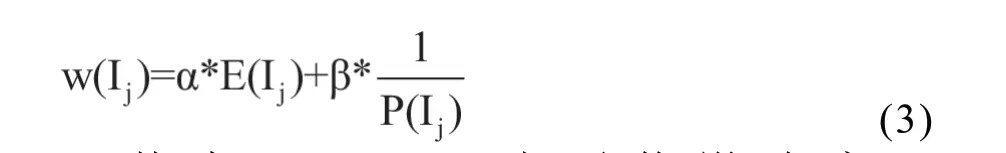
其中,E(Ij)为项的影响度,P(Ij)=Count(Ij)/|D|表示项Ij在事务数据库中出现的概率,Count(Ij)为项Ij的频次,|D|表示数据库的事务总数,以P(Ij)的倒数体现项Ij在的频次方面的重要性。α和β分别表示项的影响度和频次影响程度的系数,令α+β=1,根据实际场景调整α和β的取值,实现有效挖掘。
定义4 事务的权重
事务的权重为事务中包含项的权重的平均值乘以事务计数,|Tk|表示事务中项的个数,则第k个事务Tk的权重为:
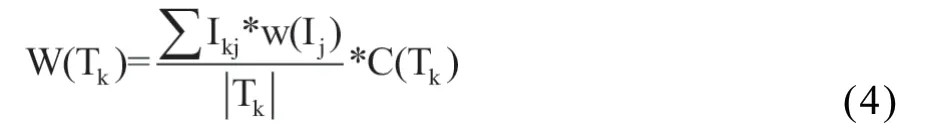
定义5 项集的加权支持度
项集的加权支持度为包含项集的事务权重之和与所有事务权重总和的比值,项集t的加权支持度计算公式为:

3.2 算法描述
基于上述定义,本文提出了加权频繁项集挖掘算法如表3所示。

表3 加权频繁项集挖掘算法
4 实验与结果
4.1 算法应用实例
实验基于实验室自主研发的“信息集成管理软件”DDS中间件产品模拟了自动驾驶汽车的控制系统。应用构件包含若干个传感器、数据处理和分析的控制器以及控制行驶的执行器,应用构件利用中间件进行通信,如图2所示。
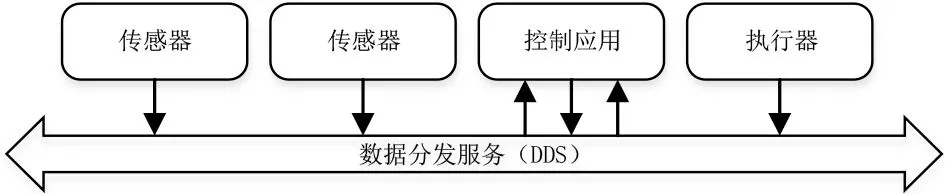
图2 自动驾驶汽车控制系统
控制系统中存在三种运行模式:正常行驶、刹车和转弯,该系统的构件发布订阅关系拓扑图如图3所示。其中圆形表示构件,箭头表示发布订阅关系,I1-I6表示发布订阅事件,正常行驶模式下事件I1,I2,I3,I4对应的构件间存在交互,同样刹车模式为I1,I2,I3,I5事件,转弯模式为I1,I2,I3,I6事件。
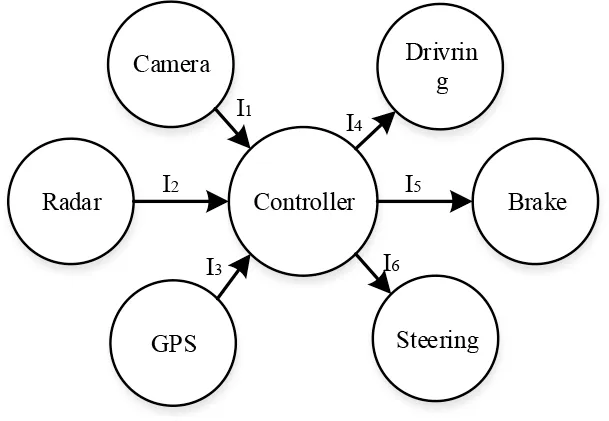
图3 发布/订阅关系拓扑图
利用拦截器机制在中间件层采集系统运行一段时间的构件间发布/订阅数据,其中大部分时间是正常行驶,转弯和刹车所占时间比例较小。对数据预处理后执行加权频繁项集挖掘算法,设置最小支持度阈值Supmin=0.2,项的权重系数α=0.5,β=0.5。对挖掘结果取最大频繁项集得到最终结果,见表4。
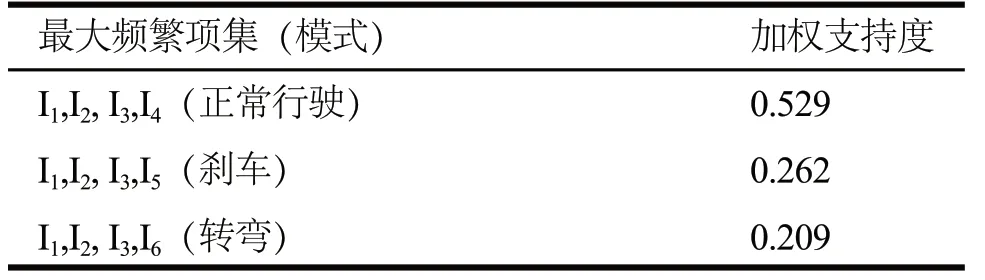
表4 频繁项集挖掘结果
实验表明,本文提出的方案能够挖掘出系统中存在的运行模式,对挖掘结果分析处理后构建运行模式知识库,可用于进一步的异常检测。
4.2 算法分析与验证
利用实例中采集的数据,通过两组实验验证本文提出的加权频繁项集挖掘算法的有效性和效率。
(1)算法的有效性
算法的有效性检验是测试本文提出的算法和Apriori算法产生的频繁项集和对应的支持度情况,同时验证了α和β系数的取值对支持度的影响。令最小支持度阈值Supmin=0.2,计算4-项集的支持度,实验结果如表5所示。
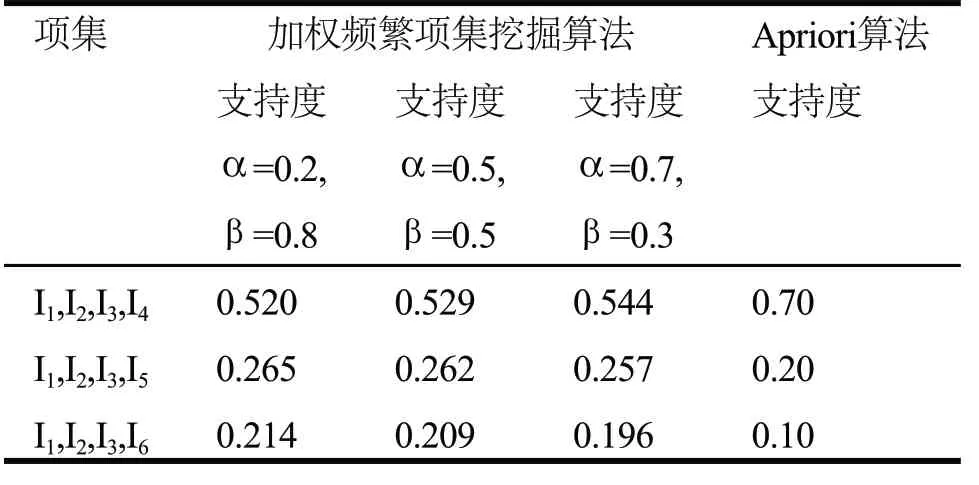
表5 4-项集挖掘结果
从表5可以看出,加权频繁项集挖掘算法的挖掘结果中包含小概率发生事件的I5和I6的项集支持度相较于Apriori算法都有所提高,包含I4的项集支持度有所降低,项集的加权支持度趋于均值。实验表明,通过对项从影响度和频次两个方面进行加权,提升了发生次数少且有价值的项的支持度,能够挖掘出包含小概率发生事件的运行模式。
同时,加权频繁项集挖掘算法中随着参数值α的增大,对项的影响度的侧重增加,在支持度均值之上的项集支持度逐渐提高,均值之下的支持度逐渐降低,项集的支持度区分更加鲜明。当α取0.7时,项集{I1,I2,I3,I6}的支持度低于最小支持度阈值,对项的频次的侧重过低,因此α取0.5既从频次方面提高项集支持度,又体现影响度对支持度的影响。
(2)算法的效率
为了验证文本提出的算法的性能,实验令最小支持度阈值Supmin=0.2,为保证实验结果不受项的影响度权重的影响,令α=0,β=1。分别使用改进的算法、Apriori算法和FP-growth算法对不同的事务数、相同事务数下不同的支持度进行实验,比较了三种算法的执行时间,实验结果如图4和图5所示。
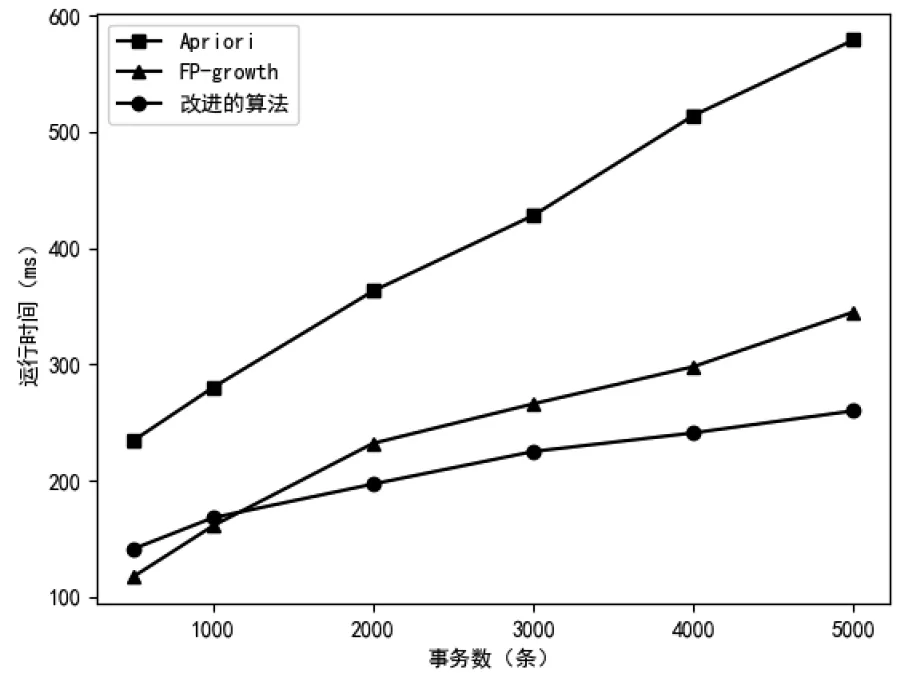
图4 不同事务数运行时间对比
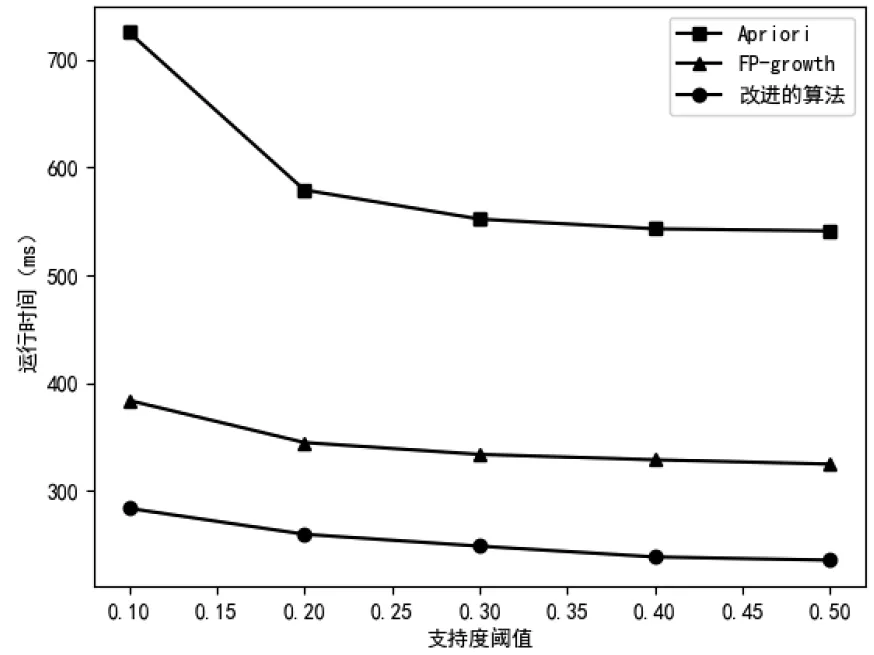
图5 不同支持度阈值运行时间对比
从图4可以看出,随着系统运行时间的增长,构建的事务数据库中的事务数越多,在不同的事务数下,本文提出的算法相较于Apriori算法和FPgrowth算法性能有了显著或有效的提升,且随着事务数的增大,处理时间的差距越大。这是因为改进算法只扫描一遍事务数据库,利用事务矩阵对事务数据库进行了压缩,减少了扫描时间,且矩阵中的与操作也减少了项集支持度的计算时间。
图5为事务数为5000时,支持度阈值选取0.1-0.5的情况下三种算法的运行时间,当支持度阈值越大,挖掘时间越短。改进的算法与Apriori算法相比运行时间随支持度阈值变化的幅度较小且在每种支持度阈值下的运行时间均优于其他两种算法。
5 结束语
本文提出了一种加权频繁项集挖掘算法应用于发布/订阅分布式系统中的运行模式识别,挖掘结果可用于系统异常状态的检测。在具体的应用场景中,通过实验分析和验证,本文提出的算法能够有效地挖掘出系统中存在的运行模式且运行效率优于Apriori算法和FP-growth算法。在后续工作中,将研究改进算法的并行化方案以处理海量的发布/订阅分布式系统运行数据,进一步提高算法的性能。
猜你喜欢
作文大王·低年级(2022年12期)2022-12-23 02:16:15
中国交通信息化(2022年10期)2022-11-17 08:19:42
当代陕西(2020年17期)2020-10-28 08:18:18
河南水利年鉴(2020年0期)2020-06-09 05:43:44
人大建设(2018年5期)2018-08-16 07:09:00
电信科学(2017年6期)2017-07-01 15:44:57
卷宗(2014年5期)2014-07-15 07:47:08
计算机工程(2014年6期)2014-02-28 01:26:12
河南科技(2014年15期)2014-02-27 14:12:51
长春大学学报(2013年8期)2013-06-21 09:04:04
