
基于802.11帧的无线设备指纹生成方法
2020-09-10 06:51刘玉洁李娜姚晓张玉健许昱玮
网络空间安全 2020年8期
刘玉洁,李娜,姚晓,张玉健,2,许昱玮,2,3
〔1.东南大学网络空间安全学院,江苏南京 211189;2.网络空间国际治理研究基地(东南大学),江苏南京211189;3.网络通信与安全紫金山实验室,江苏南京,211111〕
1 引言
随着移动设备的普及,无线技术由于提供低成本和随时随地的网络连接,已成为现代计算平台的重要通信方式。然而,无线网络由于其普及性、开放性和商业价值,也正吸引着各种形式的网络攻击,其中无线节点的仿冒最为常见,带来了严重的安全和隐私威胁。因此,如何对无线设备的真实身份进行有效识别,是应对上述威胁而亟待研究的重要问题。
对于早期的无线设备,MAC(Media Access Control)地址因其确定性和唯一性,常被用作设备的身份标识,但也带来隐私泄露问题。作为一种防止追踪的对策,MAC地址随机化被用于隐私保护,但也使得MAC地址不再适合作为无线设备的身份标识[1]。此外,研究者还尝试从其他特征中提取无线设备的身份指纹,按照指纹生成的前提可分为有连接方式和无连接方式:前者需要指纹提取者与无线设备建立连接,可获得丰富的特征值,但降低了指纹提取者的安全性;后者无需与目标无线设备建立连接,增强了安全性和灵活性,但特征获取受到限制[2]。
为应对无连接方式的技术挑战,本文提出了一种基于802.11帧的无线设备指纹生成方法。通过提取802.11协议管理帧的特征值,利用信息熵(Entropy)和相似哈希(Similarity Hash,SimHash)生成无线设备指纹,实现了无连接方式下的细粒度识别和相似度发现。
2 概念和相关工作
2.1 802.11工作机制
802.11 协议的站(Station,STA)与接入点(Access Point,AP)建立连接分为被动扫描和主动扫描两种方式:被动扫描是由STA侦听AP定期发送的信标帧(Beacon),通过信标帧获取AP信息;主动扫描则是由STA广播探测帧(Probe Request),而从探索响应帧(Probe Response)中获取AP信息,如图1所示。由此可见,信标帧和探测帧是在无连接方式下获取无线设备特征值的主要来源,其中STA和AP均为本文所述的无线设备。
2.2 相关工作
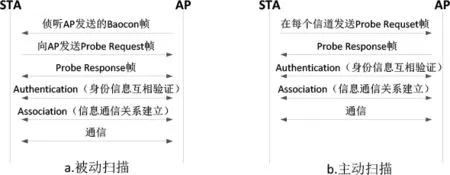
图1 802.11协议的被动扫描和主动扫描过程
指纹技术常用于无线设备的身份识别和数字取证等,现有的无线设备指纹生成方案可分为有连接方式和无连接方式。在有连接方式下,指纹提取者需与设备建立实际连接。Shetty等人在有连接模式下通过分析流量特征将授权主机与恶意接入主机进行区分[3]。Gao等人利用TCP/UDP数据包到达时间IAT(Inter-Arrival Time)作为签名生成AP类型指纹[4]。Monica等人设计了一种名为WiFiHop的客户端工具,通过中继带水印的数据检测伪AP[5]。这些基于有连接的方法可以获得更多特征信息,但增加了指纹提取的前提条件且暴露了提取者的身份。在无连接方式下,指纹提取者无需与设备建立连接,而是通过侦听设备主动发送的信标帧或探测帧提取设备的指纹信息。杨从安提出为每台使用数字联盟服务的移动设备下发唯一识别ID作为设备指纹[6]。Robyns等人提出对单个帧进行逐位熵分析从而构建发射机的指纹的方法[7]。Li等人利用802.11信标帧中的时间戳和信号字段作为高斯分布算法和朴素贝叶斯分类中的数据来生成接入点指纹[8]。无连接方式下的指纹提取者是隐身的,但获取有效信息受限。
3 指纹生成方法
本文提出的指纹生成方法是在无连接条件下通过侦听802.11管理帧提取无线设备的指纹信息。本节以探测帧为例,详细介绍指纹生成的设计思路、特征选择以及指纹生成算法。该方法可同理推广到利用信标帧生成指纹的场景。
3.1 设计思路
无连接情况下的指纹生成以设备发出的802.11管理帧为分析对象,进行特征选择和指纹生成。在特征选择阶段,需考虑特征的稳定性及区分度。可采用信息熵对其进行衡量,信息熵越小,特征越稳定。在指纹生成阶段,需对特征进行量化评估,兼顾特征内容、特征贡献度、指纹结果相似度分析三个方面:对特征内容使用一种压缩映射的转换,即哈希(Hash)算法;特征贡献度通过特征信息熵值体现,信息熵越高,贡献度也越大;利用局部敏感的SimHash算法[9]对特征内容和特征贡献度进行整合,生成的SimHash值可用作相似度评估。
可以看到,无论是在特征选择还是指纹生成,都需要计算各特征的信息熵。对于任意特征X,在探测帧中所有取值为{x1, x2,..., xn, xn+1},其中,x1, x2..., xn表示n个不同的取值,xn+1=U表示取值为空,即该特征在当前帧中不存在。特征X所有取值的概率密度函数p(xi)的计算公式为:

由此,该特征的信息熵可表示为:
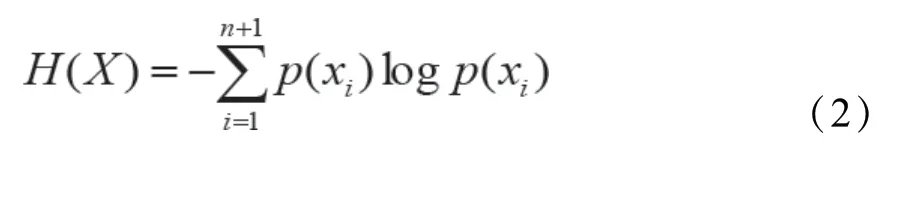
3.2 特征选择
特征选择的目标是提取在同一设备中保持不变、而在不同设备中差别较大的特征。
将来自同一设备的探测帧作为数据集,利用公式(2)计算各特征的信息熵,选出对于同一设备保持稳定,即信息熵为0的特征。随后,在不同设备的探测帧中执行同样的操作,选出对于不同设备具有区分度,即信息熵不为0的特征。将两次字段选择结果取交集,最终得到的稳定且具有区分度的特征包括Request、HT Capabilities、Extended Capabilities、VHT Capabilities、Vendor Specific。其中,前四个特征为802.11协议定义的标准字段,而Vendor Specific则是厂商自定义字段,可定义多个子字段。除了上述特征外,信息元素序列也对无线设备具有良好的标识性。信息元素序列是指探测帧的Element ID序列组合,以及Vendor Specific的子字段序列。由于不同设备发出的探测帧携带的报文信息不尽相同,所包含的信息元素字段及顺序也不同,因此,信息元素序列可以作为标识无线设备的特征参数。将信息元素序列和特征字段内容两部分的信息进行整合,最终得到13个可用于指纹生成的特征,如表1所示。
3.3 指纹生成
指纹生成阶段的目标是形成对所提取特征的抽象描述以及挖掘不同指纹值的内在联系。已选取的特征可用于内容表达和贡献度量化两个方面:内容表达是直接利用Hash算法进行压缩映射,而贡献度量化则通过特征信息熵体现。特征信息熵通过公式(2)在特征值去重过的指纹集中计算得到。局部敏感的SimHash算法可以整合特征内容Hash值与特征参数贡献度,且在一定程度上还可以表征原内容的相似度。因此,将特征信息熵作为权重,计算SimHash得到设备指纹,通过比较不同SimHash值的汉明距离,从而判断两个指纹的相似度。
SimHash算法分为五个步骤:分词、Hash、加权、合并和降维,具体过程如图2所示。
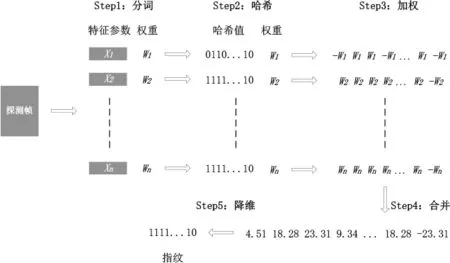
图2 SimHash指纹生成算法示例
3.4 算法实现
记目标帧P,初始数据集Spackets,特征值去重后的指纹集Sfeature,特征参数集SX={X1,X2,...,Xn},其中X1即信息元素序列TagSeq,
X2,...,Xn为P中的特征字段。无线设备指纹生成的过程如算法1描述所示。
算法1 基于802.11帧的设备指纹生成算法
输入:初始数据集Spackets,目标帧P
输出:目标帧指纹F
produce GenerateFingerprint(Spackets,P)begin
1 以Spackets为基础构建指纹集Sfeature
2 for X in P do
3 将X的Element ID添加进TagSeq
4 if X in SXthen
5 特征参数赋值Xi=X
6 if X is Vendor Specific then
7 将X的OUI添加进TagSeq
8 end if
9 end if
10 end for
11 特征参数赋值X1=TagSeq
12 if SXnot in Sfeaturethen
13 更新Sfeature
14 end if
15 在Sfeature中计算各特征参数信息熵
16 将各特征信息熵作为权值
17 计算各特征哈希值
18 利用SimHash算法生成指纹F
19 return F
end
在算法1中,首先对初始数据集进行特征值去重得到指纹集(Line 1);接着提取目标帧的特征参数(Lines 2~11);然后判断目标帧的特征是否与指纹集中的特征相匹配,若不匹配则需要更新指纹集(Lines 12~14);最后利用指纹集计算各特征参数的信息熵作为权重,然后利用SimHash算法生成指纹(Lines 15~19)。
4 实验与分析
4.1 实验设置
实验采用Sapienza2013数据集[10],包含8个子数据集,共108,359个无线设备,4,825,476个探测帧。指纹算法用Python编程实现,Hash函数采用SHA256。此外,通过计算以下三个指标对算法进行评估:各特征的熵值、指纹识别粒度以及同一品牌不同设备的指纹相似度。
4.2 实验结果
(1)各特征的熵值
经过去重后,共生成4,650个不同的特征值组合,从而构成指纹库。利用公式(2)计算所有特征的熵值,结果如表1所示。可以看出,VSWPS字段的熵值最高,为9.85,且有3,559个不同的值,表明该字段复杂度最高,作为指纹字段的区分性也最好。VSNC字段,不同值有54个,但是熵值只有0.16,说明该字段内容较为接近,区分度不高。
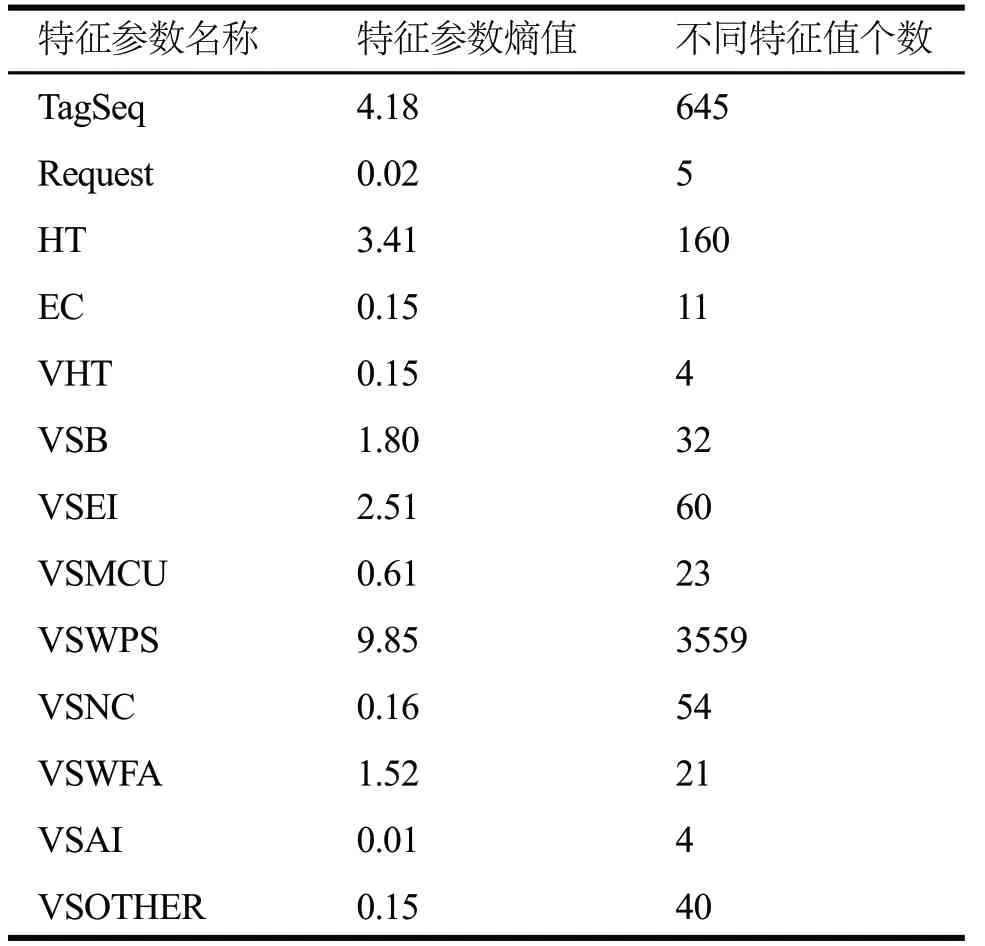
表1 特征参数在指纹库中的熵值和不同值的个数
(2)指纹识别粒度
在MAC地址随机化的趋势下,MAC地址虽已不适合作为设备标识,但可用其前三个字节识别出OUI(Organizationally Unique Identifier)信息,即设备的制造商。利用OUI与设备品牌的对照表[11]进行映射,得到设备品牌信息。为比较本文算法和品牌的识别效果,定义识别粒度的计算方式:

其中,ε为识别粒度,n为可识别出的不同类型设备数,N为数据集中的设备总数量。
8个子数据集的品牌和指纹识别粒度结果如图3所示。可以看出,在所有子数据集中,SimHash指纹的识别粒度明显比品牌高。品牌的识别粒度区间为[0.48%,1.25%],而指纹的识别粒度区间为[3.16%,5.68%]。通过比较,每个子数据集中指纹的识别粒度平均比品牌高5.68倍。由此可见,本文提出的指纹算法可实现比品牌更细粒度的设备识别。
(3)不同指纹之间的相似度
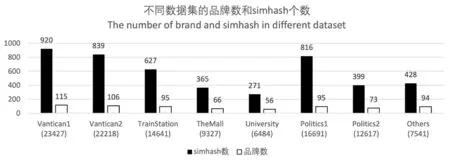
图3 子数据集中品牌和指纹的识别结果
来自同一品牌的报文在一些字段上,尤其是Vendor Specific字段,可能会表现出一定的相似性,即它们之间的距离较为接近。理论上,SimHash指纹越相似,设备关联性越高。基于这个假设,本节统计了数据集中180个品牌的平均汉明距离以及相似度。相似度的计算公式为:

其中,η表示相似度,d表示平均汉明距离,len表示指纹长度,由于本文采用的是SHA256算法,故len=256。
除去只有一种指纹的132个品牌(此时无法计算平均汉明距离),得到平均汉明距离最小的前5个品牌,如表2所示。Apple品牌下指纹的平均汉明距离只有14.99,相似度高达94.15%,说明其指纹间的关联性较高,原因是其探测帧的标准化程度高。
同理,相似度最低的五个品牌如表3所示。虽然HTC品牌的指纹相似度最低,但仍达到51.75%,表明不同型号间仍具有一定的关联性。
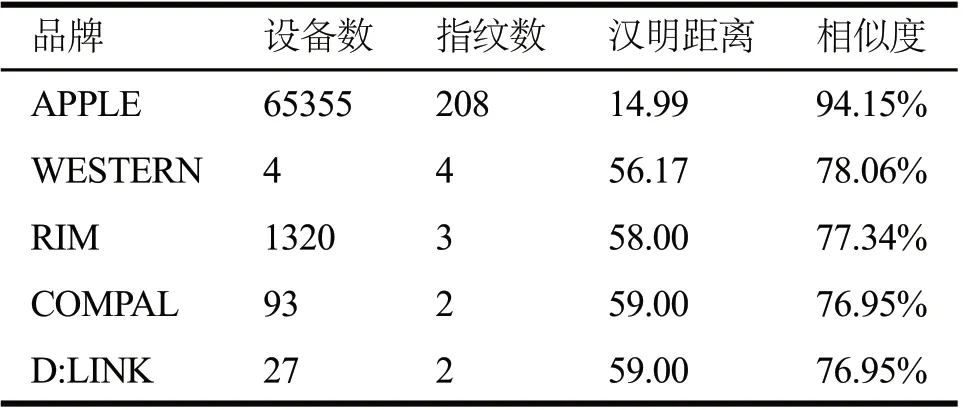
表2 相似度最高的前五个品牌
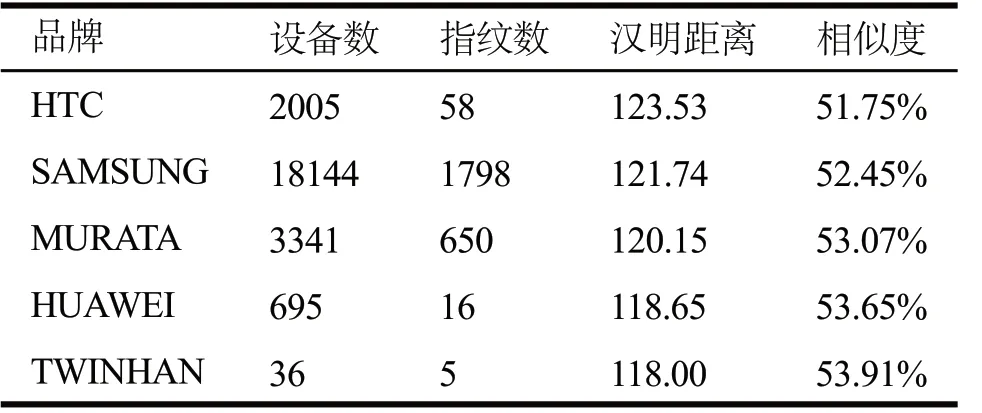
表3 相似度最低的前五个品牌
上述实验结果也表明本文所生成的设备指纹除了能够作为设备标识符,在量化评估设备间的关联性方面具有一定优势。
5 结束语
针对目前无线网络中设备指纹生成及识别的问题,本文提出了一种基于802.11帧的无线设备指纹生成方法。在未建立连接条件下,侦听无线设备的802.11管理帧,利用信息熵选取和量化帧中的特征参数,最终通过SimHash算法生成独特的设备指纹。在Sapienza2013数据集的实验表明:信息熵算法选取的特征参数具有明显的设备区分度,熵值最高为9.85;指纹识别粒度相较于品牌平均提升了5.68倍,识别效果优于品牌;同一品牌的不同指纹具有明显的关联性,最高达94.15%。由此,该算法可用于判断不同设备之间的亲缘关系。
下一步,将基于现实环境对该指纹生成方法的准确率、误报率、漏报率等做进一步分析。此外,还可以结合其他特征字段生成动态指纹,用于反MAC随机化的设备追踪。
猜你喜欢
舰船科学技术(2022年10期)2022-06-17
军民两用技术与产品(2022年1期)2022-06-01
电脑爱好者(2021年23期)2021-12-08
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
中国水运(2016年11期)2017-01-04
电子技术与软件工程(2016年22期)2016-12-26
电脑知识与技术(2016年27期)2016-12-15
科技视界(2016年20期)2016-09-29
新世纪图书馆(2014年7期)2014-09-19
新世纪图书馆(2014年7期)2014-09-19
