
基于机器学习的心电图诊断研究
2020-09-08 08:12王官军吴婷汪龙唐祖胜
实用心电学杂志 2020年4期
王官军 吴婷 汪龙 唐祖胜
心电图作为临床最常用的检查手段之一,在心肌梗死、心律失常等疾病的诊断中有不可替代的作用。但在临床应用中,心电图诊断易受判读医师个人经验及主观因素影响而出现差错,因此,越来越多的研究聚焦于心电图信号的自动判读[1-3]。传统心电图辅助诊断技术易受干扰因素影响,存在鲁棒性不佳、泛化性能不强的缺点,难以适用于临床[4-5]。近年来,人工智能在医疗应用领域高度渗透[2],在图像识别、智能诊断等方面取得了可喜的成绩[3],而基于人工智能的心电诊断正是今后心电报告的发展方向[6]。中国优质医疗资源过度集中于大中型城市及大型教学医院,偏远落后地区及基层医疗机构诊疗水平较低,心电图判读准确性不高一直是亟待解决的问题;同时,医院大量心电图均依靠人工诊断,耗时费力,这种落后的心电图判读方式制约着中国心电事业的发展[7],因此,中国亟须建立人工智能心电诊断系统。

图1 训练集心电图可视化Fig.1 Visualization of a case of training set ECG
机器学习是人工智能领域最主要的分支,通过提取数据特征进行数学建模来自动学习数据的内在规律[8-9]。常见的机器学习模型包括K-近邻(K-nearest neighbor, KNN)、决策树、随机森林(random forest, RF)、支持向量机(support vector machine, SVM)、Logistic回归等[9-10]。快速、准确的心电图辅助诊断技术成为当前医疗领域研究的热点[5,11-12]。然而,目前针对心电图诊断的机器学习算法技术尚不成熟,自动报告错漏百出,临床应用存在局限性,很多医院不得不关掉心电图人工智能辅助诊断系统[7,13-14];此外,目前关于各种机器学习算法性能对比的研究很少[15-17]。鉴于上述应用及研究现状,本文利用公共数据平台上的大量心电图记录,对比4种常见的机器学习分类算法的性能,为进一步的算法研究提供理论依据。
1 研究方法
本文利用公共心电数据库心电图记录,进行4种常见机器学习分类算法的心电图诊断研究。对心电信号进行预处理并通过主成分分析(principal component analysis, PCA)降维提取特征,针对4种常见的心电图诊断,分别采用K-近邻算法、随机森林、Logistic回归和支持向量机算法进行二分类预测算法研究,并评估4种算法的预测表现。利用Python 3.7.4编程,开发环境为JupyterLab,并采用Numpy 1.18.1、Pandas 1.0.1及Sklearn 0.22.2包进行科学计算。
1.1 数据获取
数据来源于PTB-XL心电图数据库。该数据库(https://physionet.org/content/ptb-xl/1.0.1)是国际公认的大型心电数据库,且公开免费,截至2020年7月,共包含21 837条心电图记录。每条心电图记录包含10 s的心电数据,采样率为500 Hz;每条记录的总样本点为6万,均为标准12导联心电图(Ⅰ—Ⅲ、aVR、aVL、aVF、V1—V6),以专有压缩格式存储。该数据库2019年发布时对数据进行了简化,提升了机器学习的可访问性及可用性。
1.2 数据预处理
使用PTB-XL心电图数据库提供的Python工具提取心电图数据,并按照推荐方案划分训练集(train set)、测试集(test set)。经划分,训练集共有19 634例(89.9%)样本,测试集有2203例(10.1%)样本。
1.2.1 缺失值处理 删除训练集中367例(1.9%)缺少标签的心电图数据,共得到19 267例训练样本;测试集数据无缺失值。对1例训练集心电图进行可视化处理,如图1所示。
1.2.2 心电图截取 心电图波形形态的异常往往体现在每个心电导程中,因此,可以对心电信号进行逐导程分割。心电图截取长度是影响分类结果的重要因素,截取1 s的心电数据基本可包含所有的波形特征[18]。本文以Ⅱ导联R波最高点来确定截取范围(R波最高点之前150个数据点,之后350个数据点),截取1 s的心电图片段进行分类研究,如图2所示,图中加粗部分为下采样后的心电图。
1.2.3 去基线 由于基线偏移会对特征值提取造成很大障碍,尤其是在心肌梗死、ST-T改变的预测中,基线偏移会对模型预测造成很大干扰,导致特征无法被有效识别,因此,在分析心电图数据前需要通过预处理消除信号基线。通过采用插值方法,可先在心动周期中找到基线,再用所有数据减去基线,即可得到去基线的心电图数据[18-19]。如图3所示(图中虚线为基线),本研究的心电数据存在明显的基线漂移。采用PR段作为基线,先取每个导联PR段上10个数据点的均值作为基线的近似值,然后用所有数据减去该近似值,即可得到去基线的心电图数据,如图4所示。
1.2.4 主成分分析降维 心电图数据经裁剪,合成一个6000(500×12)维的特征矩阵。由于特征维数太大,计算开销过大,且存在过拟合风险,因此需要进一步减少特征向量维数,本文采用PCA方法。PCA通过正交线性变换进行降维,用方差来衡量信息量,可在显著降低特征维度的同时,保留绝大部分方差,并在一定程度上降低噪音[20]。训练集特征矩阵经PCA降维后,累积可解释方差贡献率曲线如图5所示,图中n为降维后保留的特征个数。在保留150个降维后特征的同时,仅损失少量信息(2.82%)。PCA降维前的心电图如图6所示。经PCA降维后,再将降维后的主成分映射到原特征矩阵所在的特征空间,并进行可视化处理(图7)。对比降维前后的心电图,发现降维后的心电图保留了绝大部分原心电图特征,仅在少数细节处与原心电图稍有不同。后续所有心电图数据均采用PCA方法处理,将特征矩阵降至150维。

图2 截取1 s心电图数据

图3 原始心电图信号
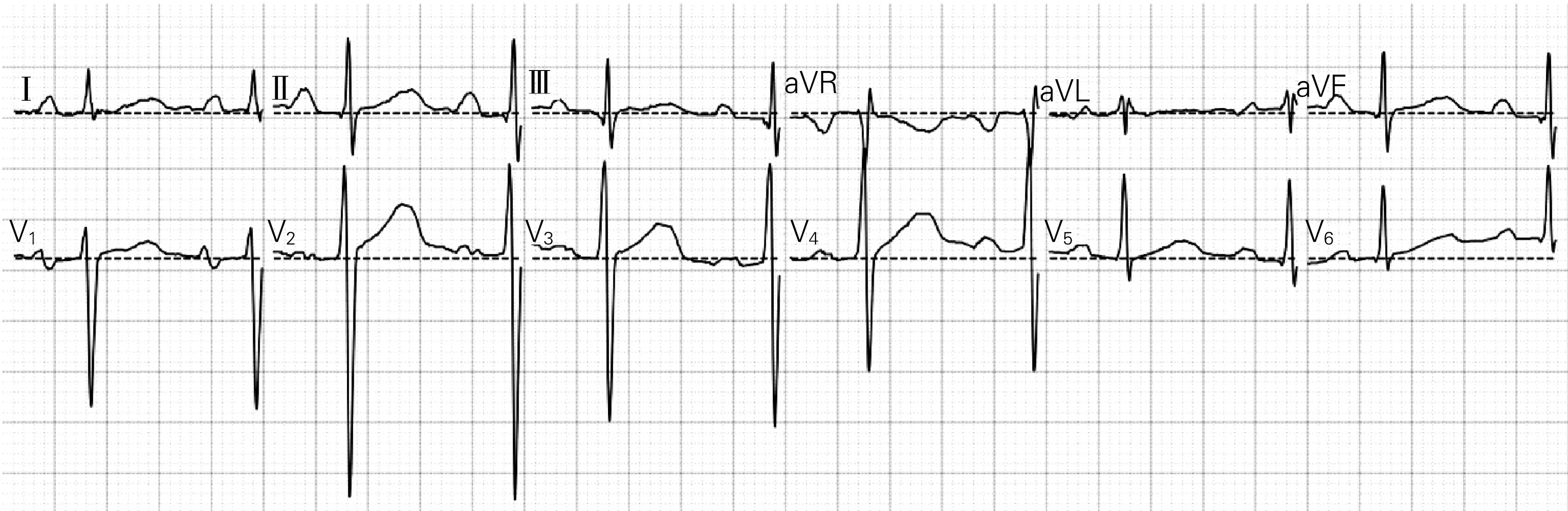
图4 去基线后的心电图信号

图5 累积可解释方差贡献率曲线
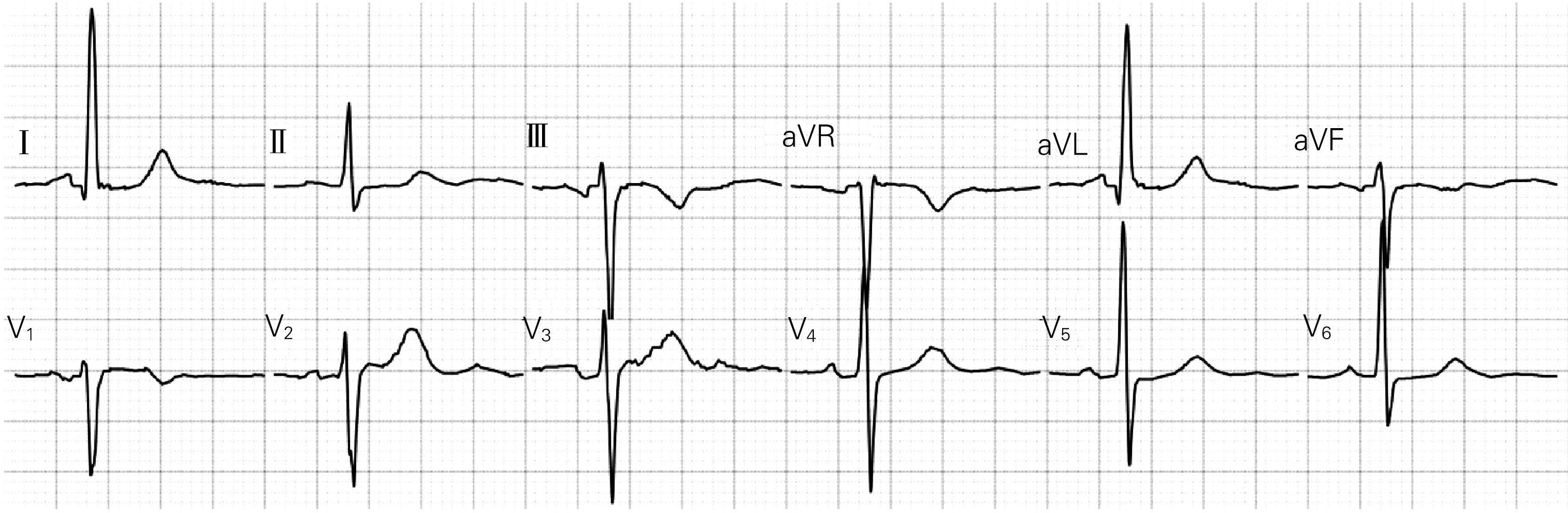
图6 主成分分析降维前心电图
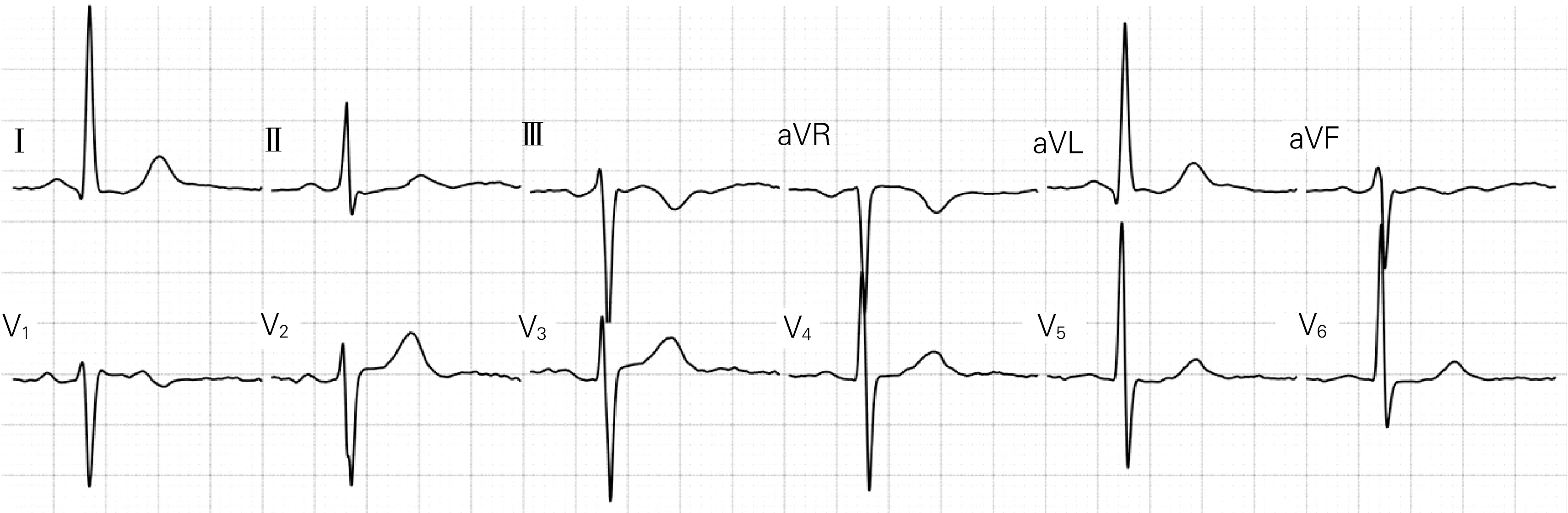
图7 主成分分析降维后映射到原特征空间的心电图
1.2.5 样本不平衡问题处理 近年来,不平衡学习问题作为机器学习的研究领域之一得到密切关注,其本质是数据分布不均衡,导致很多机器学习分类算法的性能被削弱。机器学习算法在不平衡数据集上训练时,倾向于将样本预测为多数类。尽管如此可以得到较高的准确率,但会导致很低的召回率,从而出现预测模型无法将正样本准确分类的情况,甚至造成预测模型完全失效。数据不平衡问题广泛存在于机器学习的各个领域。相对于多数类样本,少数类样本通常携带更为重要的信息,具有更高的错判代价。因此,多数情况下,我们应当更加关注少数类样本的分类准确性。要处理样本不平衡问题,通常是从数据、算法和集成三方面着手。数据层面的方法通常为上采样、下采样和混合采样[21-22]。就医学数据而言,很多数据集都是不平衡样本,正负样本比例差异较大,敏感性、特异性差异较大,导致模型的鲁棒性较差,而心电数据往往存在样本数量不平衡问题[2]。本研究存在样本不均衡问题,所有分类中正样本比例均显著低于负样本比例。欠采样使最终的训练集丢失部分数据;而过采样会导致一个数据点在高维空间中出现多次,增加过拟合风险,很多研究通过在过采样中加入少量随机噪声来减少这类风险。本文基于心电图多导程特点,利用过采样方法采集不同的心电导程,如图8中加粗部分所示。由于心电采集过程中背景噪音的存在,不会出现完全一致的数据点,因此避免了上述简单复制所带来的问题。表1为训练集过采样前后的正样本比例数据,经过采样后,训练集正负样本比例大致相同。
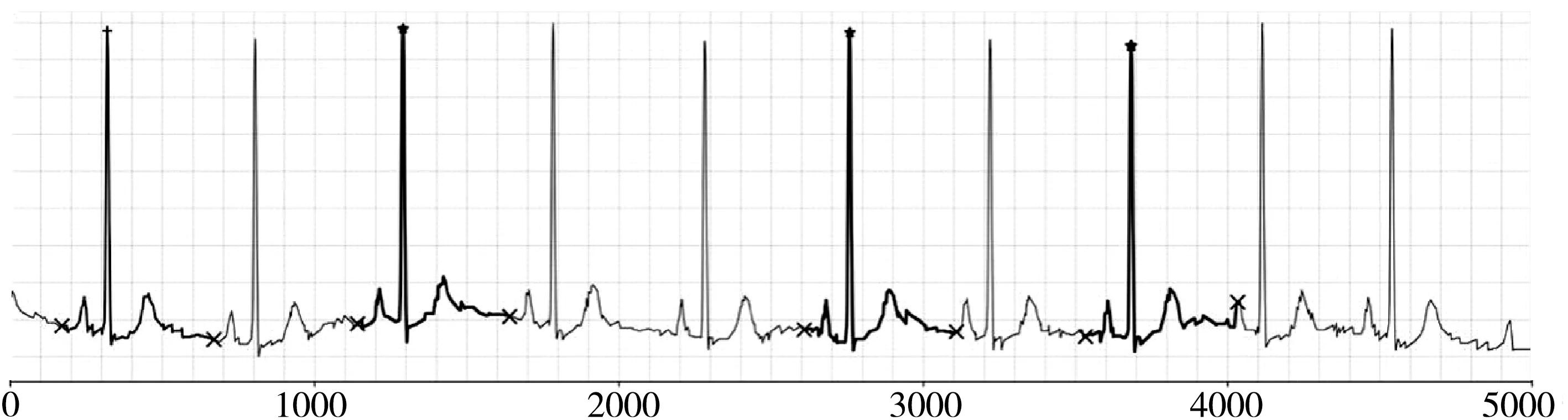
图8 利用心电图多导程特点进行过采样

表1 过采样前后训练集正样本比例 n(%)Tab.1 Positive sample ratio of training set beforeand after oversampling
2 结果
为降低模型预测的结构风险,本研究采用K-折交叉验证方法估计模型误差。K-折交叉验证是机器学习领域应用最多的泛化误差估计方法。它通过将训练集等分为K份,依次使用其中的K-1份数据作为训练集训练模型,剩下的数据作为验证集测试模型,各得到K个训练集和验证集,将这K个模型的平均误差作为泛化误差的估计[23]。

图9 4种算法的准确率对比
本研究采用5-折交叉验证,通过反复绘制学习曲线,不断优化模型超参数,选择对验证集平均预测准确率最高的模型。采用K-近邻、随机森林、Logistic回归、高斯核函数支持向量机这4种经典的机器学习算法,分别针对传导阻滞、心肌梗死、ST-改变和心肌肥厚进行二分类预测;通过对比测试集的模型预测准确率、召回率和精准率,评价模型的优劣。不同算法针对测试集的预测准确率、召回率和精准率分别如图9—图11所示。针对传导阻滞、心肌梗死、ST-T改变、心肌肥厚这4类心电图,支持向量机算法预测的准确率分别为84.8%、81.3%、82.0%和88.1%;召回率分别为55.0%、52.6%、62.9%和39.1%;精准率分别为69.8%、65.3%、64.1%和49.6%。支持向量机算法预测的准确率、召回率明显高于其他3种算法;其精准率与K-近邻算法相当,均明显高于其他两种算法。综合来看,以预测准确率、召回率及精准率来评估模型优劣,支持向量机对上述4种常见心电图分类的预测表现总体上优于其他3种算法。
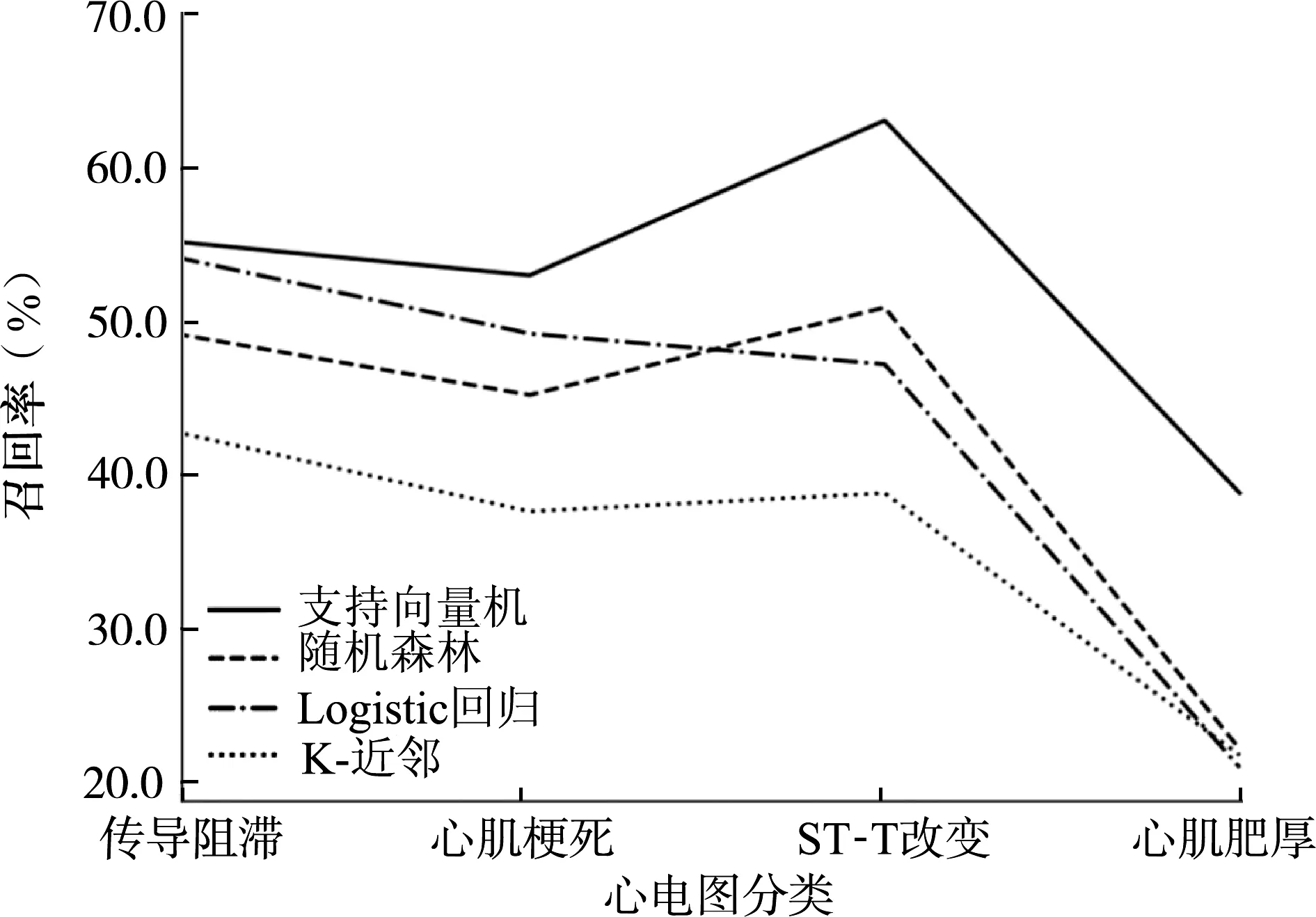
图10 4种算法的召回率对比

图11 4种算法的精准率对比
为了进一步评价模型优度,选取不同的判定阈值,得到不同的假阳性率(false positive rate,FPR)、真阳性率(true positive rate,TPR),再以FPR为x轴、TPR为y轴,绘制不同算法针对不同心电图诊断的工作者特征(receiver operating characteristic,ROC)曲线,并计算曲线下面积(area under curve, AUC)。由FPR和TPR的定义可知,曲线越靠近左上,AUC值越大,模型预测效果越好[19]。上述4种算法针对不同心电图分类的ROC曲线对比如图12—图15所示。由图12—图15可见,支持向量机算法的ROC曲线在4种心电图类别上均最靠近左上角,且AUC值均高于其他3种算法,因此,支持向量机算法在ROC曲线评价指标上优于其他3种算法。
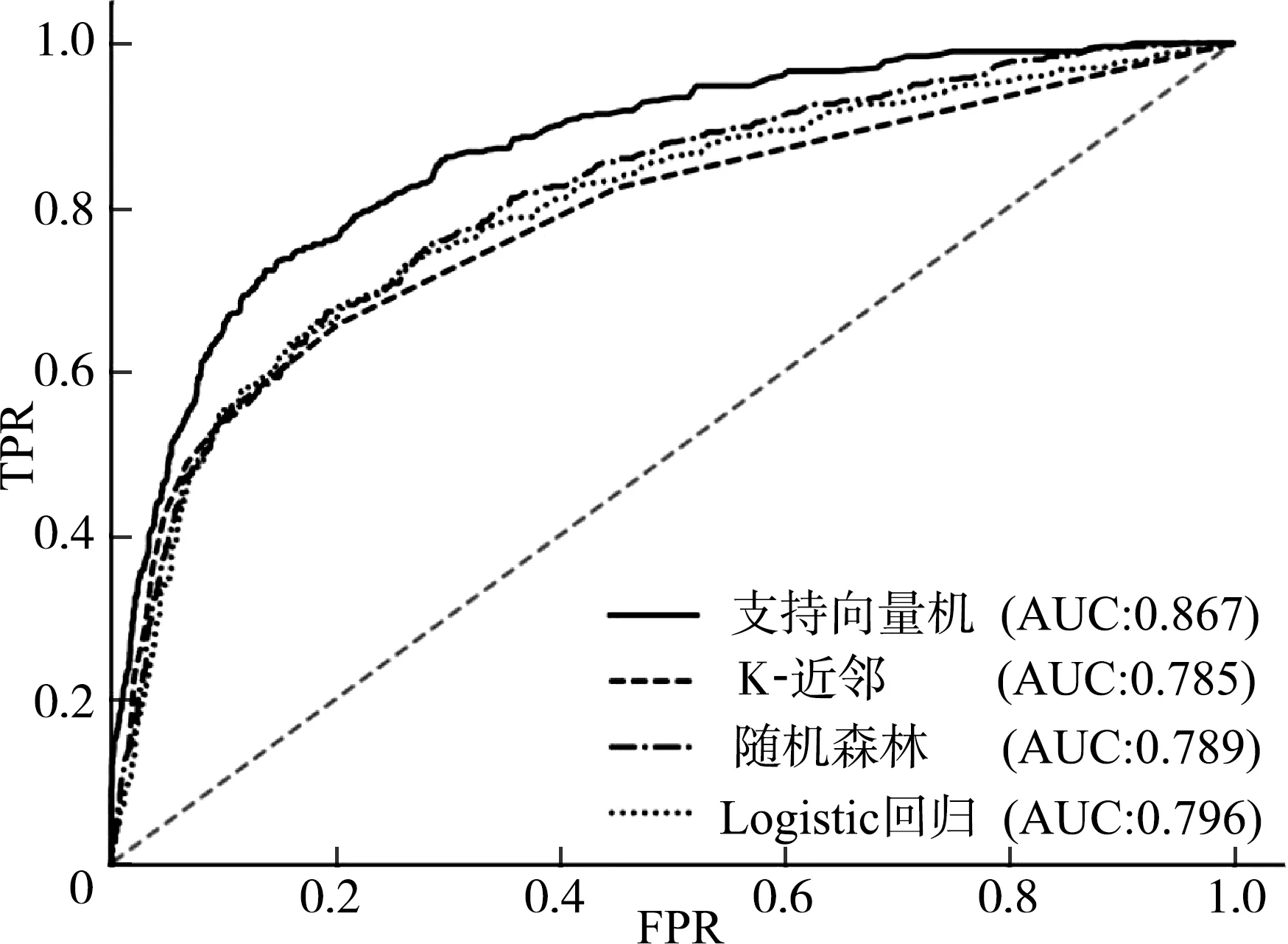
图12 4种算法针对传导阻滞的ROC曲线对比

图13 4种算法针对心肌梗死的ROC曲线对比
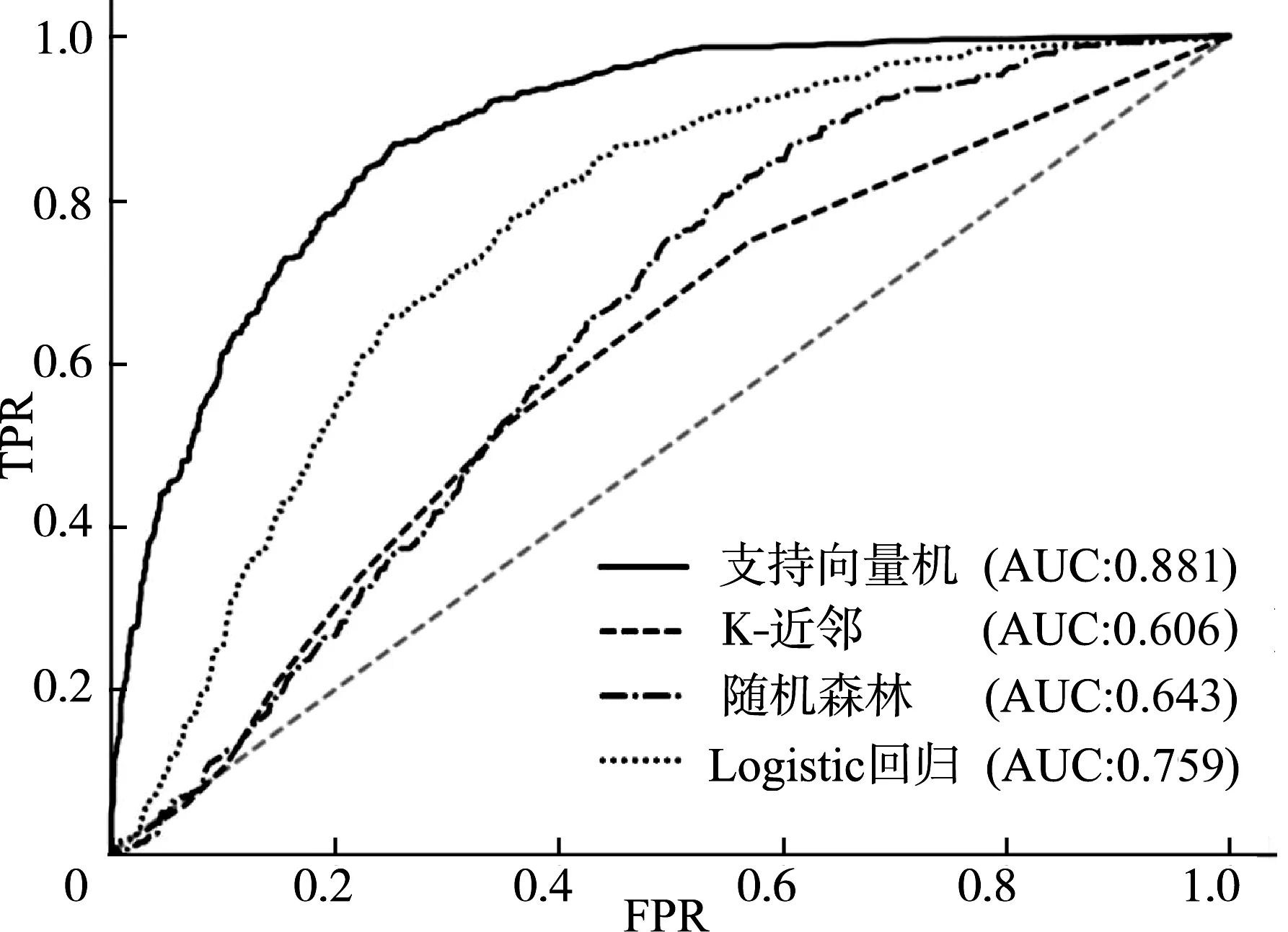
图14 4种算法针对ST-T改变的ROC曲线对比

图15 4种算法针对心肌肥厚的ROC曲线对比
综合预测准确率、召回率、精准率,以及ROC曲线模型评价指标来看,支持向量机在模型预测中的表现优于其他3种算法。需要注意的是,尽管支持向量机算法的预测准确率较高,但召回率、精准率尚达不到临床应用的要求,导致模型预测敏感性低、错判风险高,有待通过进一步研究改进模型,提升模型的预测表现,从而更好地服务于临床。
3 讨论
本研究利用PTB-XL公共心电数据库的21 837条心电图记录,进行4种常见机器学习分类算法的心电图诊断对比研究。首先,对心电信号进行缺失值删除、裁剪、去基线等预处理;然后,通过PCA降维提取特征,针对传导阻滞、心肌梗死、ST-T改变、心肌肥厚这4类心电图,分别采用K-近邻算法、随机森林、Logistic回归和支持向量机算法进行二分类预测算法研究。具体步骤如下:先通过PTB-XL数据库推荐的方法划分训练集、测试集,选择5-折交叉验证方法,运用上述4种分类算法,利用训练集数据训练模型并不断优化模型参数,再用测试集来进行模型优度评价。研究结果表明:综合预测准确率、召回率、精准率,以及ROC曲线模型评价指标来看,支持向量机在模型预测中的表现优于其他3种算法。
但是,本研究仍然存在局限性。虽然支持向量机算法在上述4种常见心电图分类诊断中有较高的准确率,但因召回率不高导致诊断敏感性较低,因精准率不高造成错判风险较大,因此,该算法尚不能直接应用于临床诊断。鉴于此,我们需要预测精度更高的模型。在下一步研究中,可通过以下3种方法提升模型的预测表现,① 扩大样本量:目前,中国各大医院逐步实现了心电图等医疗信息的电子化,心电图获取成本降低,使获得海量心电图成为可能。利用海量心电图训练模型可避免过拟合,从而得到鲁棒性及泛化性能更佳的预测模型。② 改进数据预处理方式:心电信号的预处理直接影响到模型的预测表现,也是极为重要的环节。研究表明,小波变换在心电图预处理中有极其重要的地位,其可以有效滤过基线漂移、工频干扰、肌电干扰等噪声,显著提升模型的预测表现。③ 深度学习算法:在图像识别领域,深度学习算法往往优于传统的机器学习算法。近年来,深度学习运用于心电图诊断的研究越来越多。卷积神经网络(convolutional neural network,CNN)是深度学习的一种经典算法。CNN采用不同的卷积核提取不同心电图的特征,通过池化层下采样降低特征维度,并可以通过加大卷积层的深度来提取深层次特征,再将池化层降维后的特征接入全连接层,最终通过Softmax层输出二分类结果的概率分布。CNN有平移不变性等优良特性,能够直接处理原始信号,其鲁棒性、泛化性能更好。
猜你喜欢
车主之友(2022年4期)2022-08-27
中国典型病例大全(2022年7期)2022-04-22
汽车实用技术(2022年4期)2022-03-07
昆明医科大学学报(2021年4期)2021-07-23
现代仪器与医疗(2021年2期)2021-07-21
心电与循环(2021年3期)2021-06-03
心电与循环(2021年1期)2021-02-05
装备环境工程(2020年3期)2020-04-03
海峡姐妹(2019年12期)2020-01-14
电子制作(2019年19期)2019-11-23
