
基于氨基酸的仿刺参产地信息认证方法研究
2020-09-05 03:45冉明衢李亚芳赵新达
光谱学与光谱分析 2020年9期
吴 鹏, 李 颖*, 刘 瑀, 陈 晨, 冉明衢, 李亚芳, 赵新达
1. 大连海事大学航海学院, 辽宁 大连 116026 2. 大连海事大学环境信息研究所, 辽宁 大连 116026 3. 大连海事大学环境科学与工程学院, 辽宁 大连 116026
引 言
仿刺参(Apostichopus japonicus)是海参纲(Holothuroidea)中最具营养价值与经济价值的一类[1]。 仿刺参体内富含皂苷等高活性物质, 具有抗肿瘤, 降低血脂, 改善非酒精性脂肪肝, 抑制脂肪堆积, 抗高尿酸血症, 促进骨髓造血, 抗高血压等医学功效[2]。 2017年中国共计养殖仿刺参538亿头, 年产量219 907 t, 行业总产值超过40亿美金。 食品欺诈是一种极其有利可图的行为, 不法商贩通过不正当手段误导, 甚至直接欺骗消费者, 从而获取不法暴利[3]。 通过地理标志产品保护规定的设立, 可以有效保护质量、 特色和声誉取决于其产地地理特征的食品, 提升优质产地食品的经济价值[4]。 尽管法规的设立能够预防食品产地欺诈事件的发生, 但面对高额的利益诱惑, 食品欺诈事件屡禁不止[5]。
氨基酸是蛋白质的基本组成单位, 细胞的一切新生、 修复与更新都与氨基酸息息相关。 生物体中的氨基酸含量直接体现了其富含的营养价值, 不同种类氨基酸的含量反映了其摄食初级生产者的种类与比例[6]。 与脂肪酸相比, 仿刺参体内含有更多的氨基酸, 氨基酸中的碳元素约占到仿刺参总碳量的一半, 是仿刺参新陈代谢活动的最主要参与者[7]。 特定化合物同位素分析技术(CSIA)结合了稳定同位素分析技术和特定化合物组成分析技术的双重优势, 可以更精确地阐述海洋食物网中营养物质的流动路径[8]。 特定化合物的碳稳定同位素特征提供了一种更加深入理解营养物质富集的手段, 在食品产地信息认证领域取得了良好的效果[9]。
本研究提出了一种融合多源数据处理方法认证仿刺参产地信息的新方法。 通过充分发挥不同描述角度数据的价值, 使其挖掘出数据背后隐含的规律, 建立了准确性更高、 稳定性更好、 体系架构更完善的产地信息认证模型。 构建了仿刺参产地信息认证系统, 有效地监管与防止食品产地欺诈事件的发生, 维护品牌产地从业者与消费者的切身利益。
1 实验部分
1.1 样品
仿刺参样品采集于2015年11月, 共采集到有效样品156个: 其中氨基酸含量样品78个, 氨基酸碳稳定同位素样品78个。 共包括长海县(CH)、 獐子岛(ZZD)、 霞浦(XP)、 普兰店(PLD)、 瓦房店(WFD)、 威海(WH)、 担子岛(DZD)、 莱州(LZ)和牟平(MP)9个产地的样品。 仿刺参的体长范围15~19 cm, 体重范围100~130 g, 霞浦样品的参龄为1年, 其他8个产地的样品参龄均为2年。 样品捕捞后立即存储在无菌塑料袋中, 采用4 ℃恒温冷藏, 防止其因高温产生自溶酶而水解。 在实验室内解剖去除沙石、 内脏和石灰环, 留取体壁并用超纯水洗净, 冷冻干燥48 h后用玻璃研钵磨制粉末状, 过80目网筛并干燥保存。
1.2 数据测定
取仿刺参样本20 mg放入pyrex(耐高温)试管中, 加入2 mL的6 mol·L-1HCl溶液, 向试管中充N21 min去除空气, 在110 ℃恒温密闭条件下酸水解24 h[10]。 水解液在430 g条件下离心10 min, 取上清液注入强阳离子交换柱, 提取出纯化氨基酸。 由于氨基酸为两性离子不易挥发, 而气相色谱分析需要对象具有良好的挥发性, 因此采用Metges改进的方法将氨基酸衍生化成对应的N-新戊酰基-O-异丙醇酯(NPP)[11]。 向冷却后的NPP中加入2 mL CH2Cl2, 将混合物逐滴通过6 cm硅胶(200~400目)层析柱(内径4 mm), 去除多余的酰化剂等杂质。 在室温下用N2将滤液吹干, 得到纯化的NPP, 最后将其溶于0.2 mL乙酸乙酯中。
取1 μL氨基酸酯化溶液通过气相色谱仪, 色谱分离(GC)条件为: 采用无分流方式进样, 进样口温度280 ℃; 初始加热至70 ℃并保持1 min, 以3 ℃·min-1的速度加热至220 ℃, 再以10 ℃·min-1的速度加热至300 ℃并保持8 min, 最后以1.2 mL·min-1的恒定流速充入纯度≥99.999%的He作为载气。 气相色谱分离后酯化氨基酸再经过气质联用仪进行质谱分析, 质谱分析(MS)条件为: 传输线温度250 ℃; 离子源温度230 ℃; 通过能量为70 eV的EI电子进行电离。 最终由GC-MS实验得到GC保留时间和MS谱图, 与标准谱库(NIST2008)进行比较, 确定出氨基酸的种类, 并计算得到每种氨基酸的含量数据。 测定氨基酸碳稳定同位素数据时, 酯化氨基酸色谱分离后, 其中1/10通过气质联用仪, 得到GC保留时间和MS谱图, 确定出氨基酸的种类; 剩余9/10进入稳定同位素比质谱仪, 测定出相应氨基酸的碳稳定同位素数据。
1.3 处理方法
现有食品产地认证方法的研究多侧重于化学计量工具方面, 在数据处理方法上只停留在简单运用已有方法进行产地分类的层面, 受制于样本数量与食品实际数量的巨大差距, 将产地认证方法推广到尚未测量的数据时会存在明显偏差。 当研究人员选择处理方法时, 会选择一种他所期望的“最佳”分类方法, 而不是从数据自身特征的角度进行最优方法的选取[12]。 受制于对可用方法上的知识限制与数据特征的不确定性, 选取单一认证方法无法充分发挥出数据的价值。 以深度神经网络为例, 需要通过对大量数据的不断训练, 才能展现出神奇的分类效果, 而食品产地信息认证领域往往解决的是小样本问题, 采用结构简单的机器学习方法, 得到的认证结果会更加准确。
在进行数据处理方法选择时, 遵从没有免费午餐理论(NFLT), 即针对食品产地认证领域的所有问题, 所有方法的期望是相等的, 没有任何一种方法可以表现得比其他方法更好[13]。 为了充分的挖掘出隐藏在数据背后的价值, 采用来自8个家族的12个机器学习方法进行数据处理, 利用数据自身特征主动计算出最佳方法, 消除人为选择的干扰。 在经过不断训练与优化得到最佳分类方法之后, 没有直接采用奥卡姆剃刀原则, 选择性能最佳且最简单的分类算法进行产地信息的认证; 而是将不同分类方法建立出的模型, 采用集成学习构建出一个泛化能力更强的产地信息认证整体。
1.4 认证模型
认证模型由样品预处理、 数据测定、 主成分分析、 分类方法建立、 模型优化、 认证方法集成和在线系统构建7部分组成, 整体结构如图1所示。
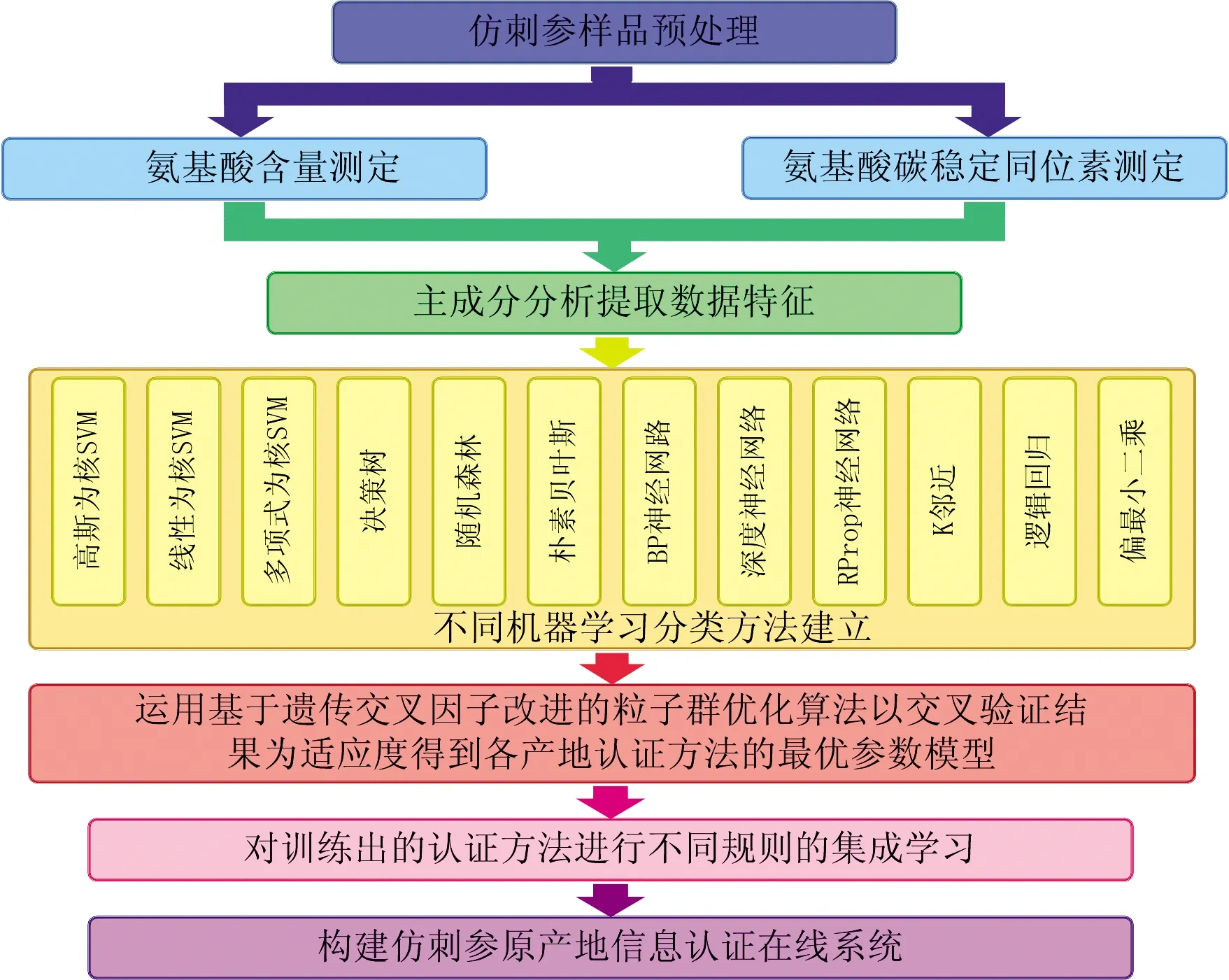
图1 认证模型的整体结构
1.4.1 主成分分析提取特征
主成分分析(PCA)是数据发掘领域常用的一种统计与降维算法, 利用彼此不相关的综合变量代替数量较多的原始变量, 在降低维度的同时保留数据自身有价值的信息。 通过总方差不变的线性变换, 提取出最具产地识别特性的氨基酸类别, 去除随机误差影响, 聚集产地特征, 提高模型的运算速度与计算精度。
1.4.2 机器学习分类方法选择
为了充分发挥数据自身的价值, 选择一定数量且具有足够广泛代表性的分类方法。 利用Manuel等在UCI数据库中121个数据集上对17个分类器家族的评估结果, 选取了最优的8个家族12个分类方法进行认证模型的训练[12]。 选择的12个分类方法为: 高斯径向基为核的支持向量机、 线性为核的支持向量机、 多项式为核的支持向量机、 决策树、 随机森林、 朴素贝叶斯、 BP神经网路、 深度神经网络、 RProp神经网络、 K邻近、 逻辑回归与偏最小二乘。
1.4.3 交叉验证与粒子群优化算法
交叉验证是一种预测在未知数据上表现的模型评价方法。 通过交叉验证可以有效了解模型的准确率、 稳定性和对新样本的泛化能力, 挑选出性能最优的分类器与模型参数, 预防与限制过拟合与欠拟合的发生, 挖掘出有限数据背后隐藏的价值。
采用马尔科夫蒙特卡洛(MCMC)方法进行训练数据的采样, 在进行不同K值100次交叉验证前生成一条马尔科夫链使其收敛至平稳分布, 保证待采样的数据符合后验分布, 消除数据划分的干扰, 保证对于不同分类器与不同粒子的评价标准一致。
对于已经确定好的数据集合, 通过调整分类器的参数可以使其达到最佳的工作表现。 因此, 采用基于遗传交叉因子改进的粒子群优化算法(GPSO)优化模型参数, 得到最为稳健的单体分类器[14]。
1.4.4 认证方法的集成学习
集成学习是将一系列训练好的分类器, 利用集成规则组合起来, 构成一个比单体分类器更加强大的认证整体。 经过训练并优化好的分类器就像是一位专家, 采用的方法是其擅长的理论, 想要一位专家解决所有问题是不现实的。 幸运的是, 利用集成学习将所有专家的智慧汇聚在一起, 能够针对食品产地认证领域的所有问题提供一个接近最优的方法[16]。
2 结果与讨论
2.1 仿刺参数据测定结果
氨基酸含量样品共测定出16种特征氨基酸, 氨基酸碳稳定同位素样品共测定出14种特征氨基酸。 通过置信水平为95%的单总体图基检验, 剔除无法有效认证的氨基酸种类, 选取出氨基酸含量数据13种, 氨基酸碳稳定同位素数据10种。 对不同产地的氨基酸数据, 采用箱型图方法分析数据的分布, 检测异常值的干扰, 最终建立出仿刺参氨基酸数据库。 仿刺参氨基酸样品的气相色谱图如图2所示, 产地为长海县的氨基酸碳稳定同位素数据箱型图如图3所示。

图2 氨基酸样品气相色谱图

图3 长海县氨基酸碳稳定同位素数据箱型图
2.2 主成分分析提取结果
经过主成分分析舍弃掉贡献率小于1的主成分, 保留下氨基酸含量数据的前5个主成分; 氨基酸碳稳定同位素数据的前7个主成分。 在保证每一类都有训练样本的条件下, 依次对前N个主成分进行初始种群规模为50, 遗传进化代数为40的模型运算, 计算得到最优前100项不同K值交叉验证的平均准确率, 结果如表1和表2所示。
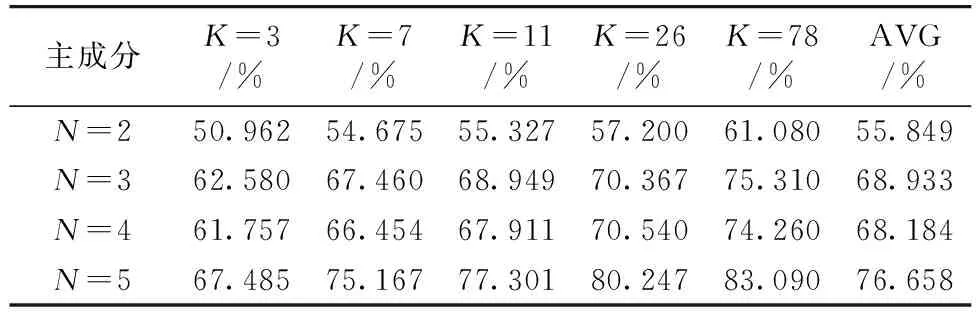
表1 氨基酸含量模型的平均准确率
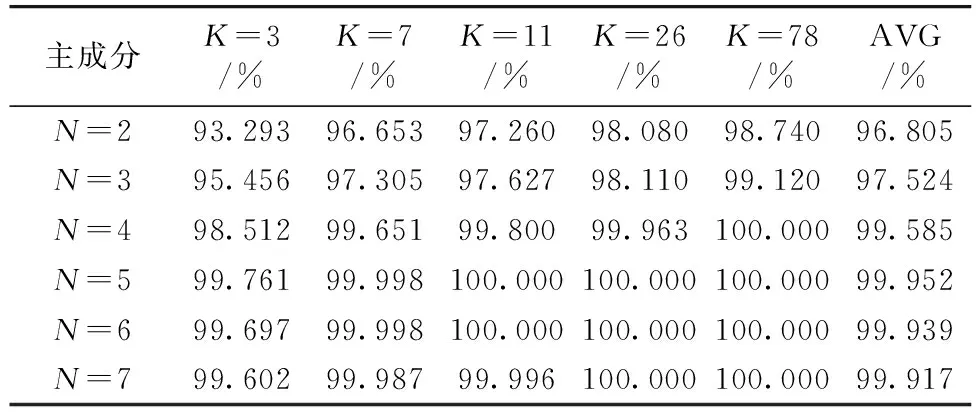
表2 氨基酸碳稳定同位素模型的平均准确率
选取前5个主成分作为氨基酸含量模型的输入, 累计贡献率为98.727%; 选取前5个主成分作为氨基酸碳稳定同位素模型的输入, 累计贡献率为95.982%。 图4和图5为氨基酸含量与氨基酸碳稳定同位素数据前3个主成分的空间分布, 氨基酸碳稳定同位素数据具有更加显著的产地聚集特性。
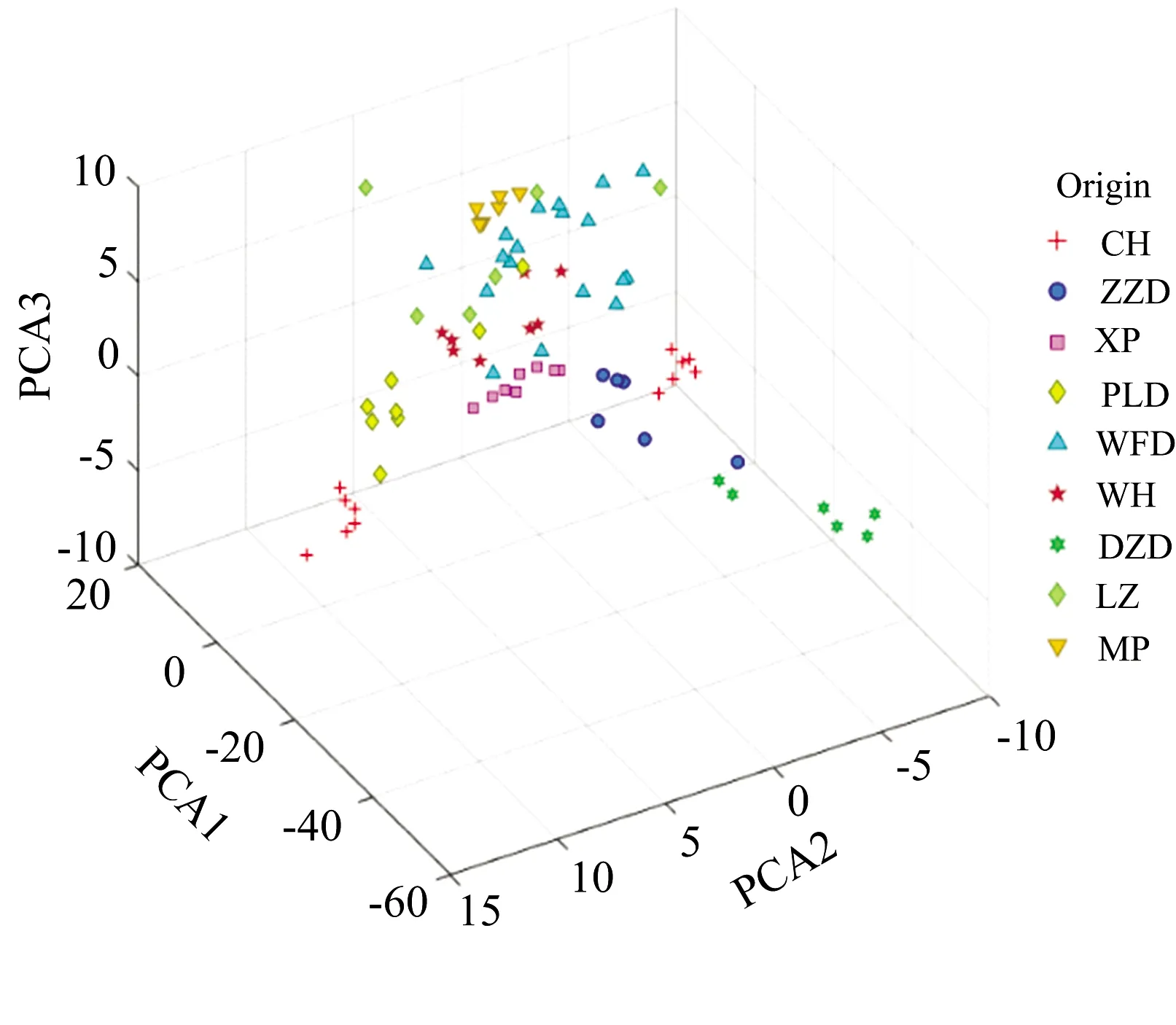
图4 氨基酸含量数据主成分分析结果
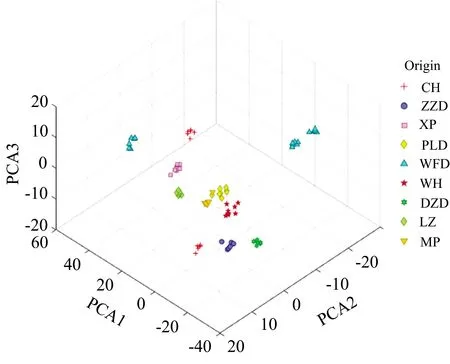
图5 氨基酸碳稳定同位素数据主成分分析结果
2.3 机器学习方法分类结果
利用Accord.NET与Math.NET框架下的机器学习程序集设计并优化24个不同方法的分类器。 运用GPSO与交叉验证方法, 在参数区间内随机设置每个模型参数的初始值, 进行种群规模为100, 进化代数为100, 自我学习因子c1为1.496 18, 社会学习因子c2为1.496 18, 权重w为0.752 9的模型参数优化, 得到性能最优的单体分类模型。
相对于传统的粒子群优化算法, 通过引入遗传算法中的交叉变异算子, 在每次遗传进化中以粒子不同K值各100次交叉验证的平均准确率为适应度, 前一半粒子直接进行下一代演化, 后一半粒子与前一半粒子进行交叉遗传。 这样不断有新的粒子进入到种群中, 提高了种群的多样性与全局寻优能力, 在保证收敛速度的同时, 也防止了模型陷入局部最优解的问题。
图6为24个单体分类模型的优化结果, 每个矩形的上边界为最优项的精度, 下边界为第100项的精度, 矩形中的红线为前100项的平均值。 最佳的前9个模型均使用氨基酸碳稳定同位素数据, 体现了CSIA更加优秀的产地认证特性; 最佳方法为高斯径向基为核的支持向量机与K邻近算法, 两者的前100项精度都达到了100%。 图7为氨基酸碳稳定同位素模型的优化过程, 证明了GPSO结合交叉验证能够快速高效地提高模型性能。

图6 单体分类模型优化结果

图7 氨基酸碳稳定同位素模型优化过程
2.4 认证模型集成结果
以训练好的24个单体模型的最优项精度为权重, 选择出100个用于集成的单体分类器, 再从对应模型的前100项参数中随机选取出每个分类器的参数, 最后利用不同的集成学习规则进行100个好而不同分类器的集成。 选取了5种不同的集成规则进行认证, 规则的具体描述如表3所示。

表3 集成规则的描述
表4为不同集成规则认证模型进行不同K值100次交叉验证的结果, 多数投票规则的认证准确率明显优于其他规则。 因此, 选取多数投票规则构建产地认证模型, 平均准确率为99.67%, 形成了融合多源数据处理方法认证仿刺参产地信息的完整体系。
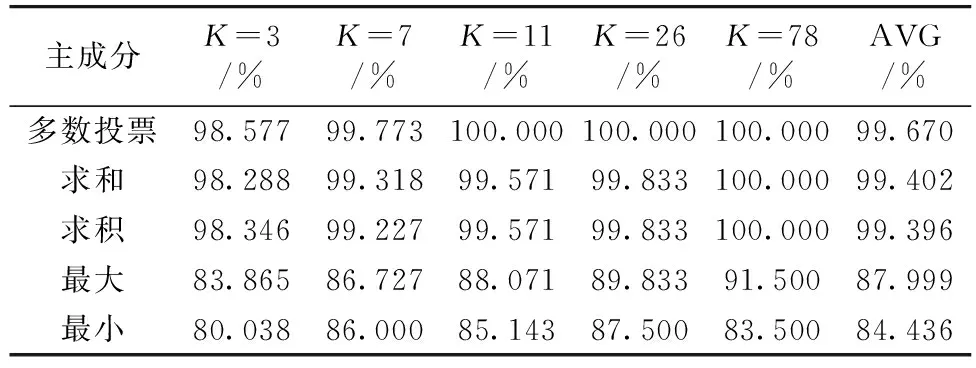
表4 不同集成规则交叉验证结果
2.5 产地信息认证系统
为了防治食品欺诈事件, 主管部门采取了加装防伪标识的手段, 但不法商家伪造标识以次充好, 更为严重的是部分从业者将其他产地的仿刺参运输到地理标志产地, 养殖几天后佩戴上合法标识进行销售。 通过构建产地信息认证系统,改变只能预防无法治理的局面, 为行业监管与消费者维权提供可靠技术支撑。 用户按照指南从终端提交仿刺参样品的氨基酸数据, 后台进行分析运算得出认证结果, 最后生成检测报告返回给前台, 在线生成的检验报告如图8所示。
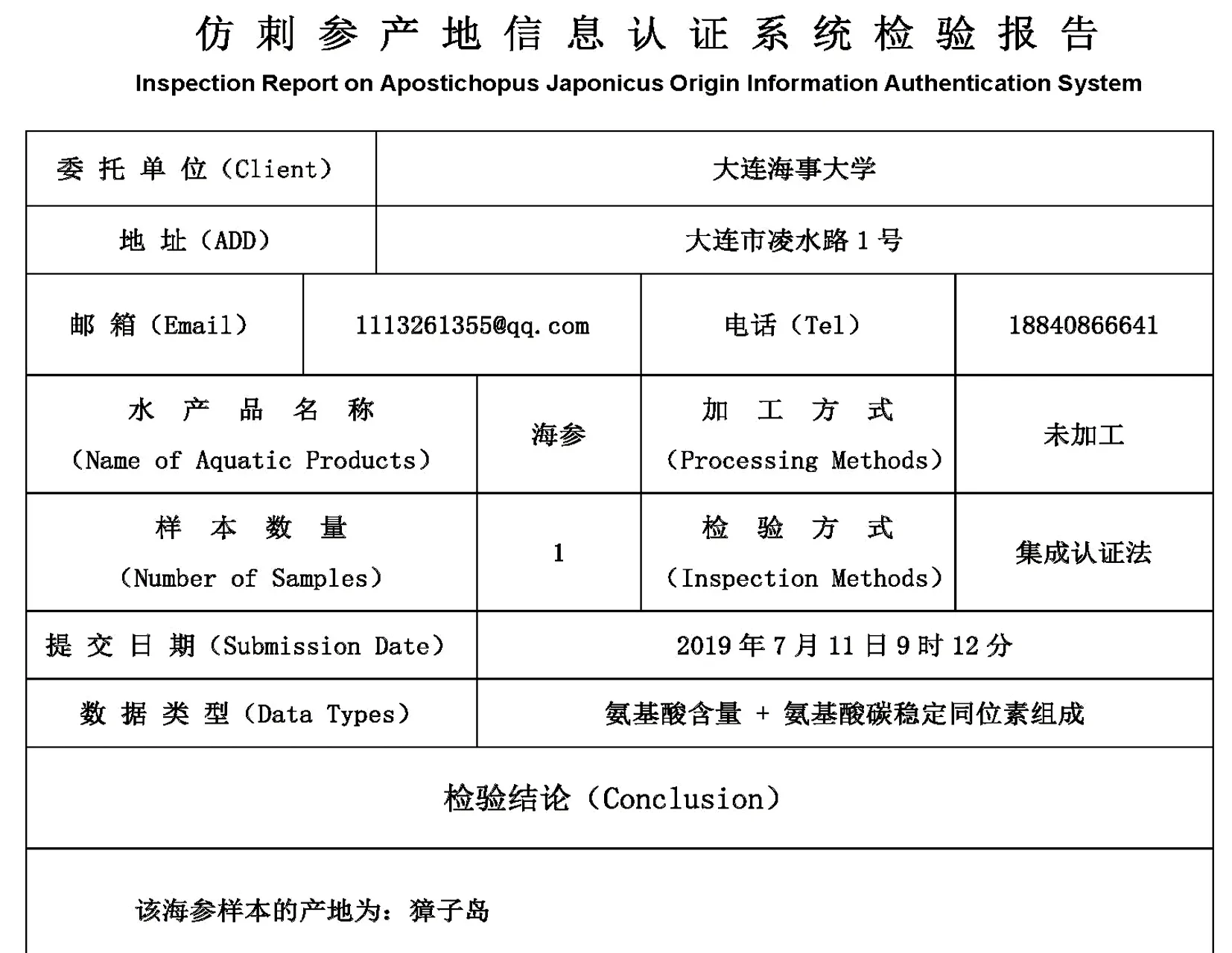
图8 仿刺参产地信息认证系统检验报告
3 结 论
通过氨基酸数据对仿刺参营养富集的详尽刻画, 采用主成分分析法降低数据维度, 聚集产地认证特性, 选取8个家族的12个分类方法, 共建立出24个单体分类模型。 运用基于遗传交叉因子改进的粒子群优化算法, 结合交叉验证与MCMC采样, 得到性能最佳的单体分类器, 最后利用集成学习汇聚单体分类器优势, 构建了平均准确率为99.67%的仿刺参产地信息认证模型。
结果表明, 基于氨基酸的多源融合认证方法, 能够挖掘出数据背后的价值, 保证产地认证准确率的同时, 有效提升模型的稳定性与泛化能力。 借助互联网技术构建了产地信息认证系统, 有效防治了仿刺参产地欺诈事件的发生, 促进了整个行业的平稳健康发展。
猜你喜欢
红蜻蜓·低年级(2021年12期)2022-01-19
红蜻蜓·低年级(2021年12期)2021-12-19
渔业科学进展(2021年3期)2021-05-12
大连海洋大学学报(2020年2期)2020-05-06
中国外汇(2019年22期)2019-05-21
意林·全彩Color(2018年9期)2018-10-12
中成药(2018年8期)2018-08-29
同位素(2018年1期)2018-01-18
中成药(2017年4期)2017-05-17
同位素(2014年3期)2014-06-13
