
基于深度学习的道路障碍物检测方法
2020-09-04 10:01彭育辉郑玮鸿张剑锋
计算机应用 2020年8期
彭育辉,郑玮鸿,张剑锋
(福州大学机械工程及自动化学院,福州350116)
0 引言
基于车载激光雷达的感知系统是无人驾驶技术中主要的汽车“视觉”方案[1],其首要任务是对道路障碍物进行检测,即准确地估计出不同三维目标物体的类别和位置。由于三维目标物体的复杂性,导致其算法呈现出多样性。近年来,基于深度学习的处理算法在三维物体特征提取方面表现出了优异性能,受到了国内外研究学者的普遍关注。
基于深度学习的三维目标检测主要通过间接、直接和融合等手段对激光雷达获取的三维点云数据进行处理。间接的手段主要将点云先做“体素”化处理[2-5],再投入深度神经网络进行训练学习。苹果公司提出了VoxelNet[6]特征学习网络(feature learning network),将点云通过体素特征编码(Voxel Feature Encoding,VFE)作张量化处理,再投入区域候选网络(Region Proposal Networks,RPN)进行训练及验证;还可通过加入反射强度因素对 VoxelNet 作改进[7],如 Yan 等[8]加入稀疏卷积网络后,提出了稀疏嵌入式卷积检测网络(Sparsely Embedded CONvolutional Detection,SECOND)模型。直接的手段则是把原始点云数据原封不动地投入设计好的深度神经网络进行训练学习[9-10],如 PointNet[11]直接将原始点云投入深度神经网络进行训练。但当训练数据集出现破损时,网络的识别能力将下降[12]。将多尺度网络与PointNet 结合也可以提高网络的局部特征提取能力[13],如后续提出的 PointNet++[14]能通过学习获得点云的区域特征;以YOLO(You Only Look Once)[15]的加强版本 YOLO v2[16]为基础的 Complex-YOLO[17]和YOLO3D[18]直接对点云进行训练学习,目标识别速度快。二维目标检测的技术已十分成熟,可以做到精确地识别行驶过程中遇到的车辆[19]。融合的手段以点云数据为主、图像数据为辅的方式进行目标检测,目标识别平均精度比前述的两种处理方法要高,但是对硬件的要求也高[20-22]。基于PointNet和改进后的PointNet++,文献[23]中针对目标障碍物识别提出了Frustum PointNets,其思想是先在图像中检测出障碍物及位置,再将对应位置的点云利用PointNet++进行检测识别;百度公司联手清华大学提出了MV3D(Multi-View 3D networks)[24],将高清图像与点云分别处理,再将检测的结果经过池化处理得到最终检测结果。
上述算法为无人车感知系统的障碍物检测与识别提供了重要的参考依据,但是仍有许多问题亟需解决。大部分算法都是直接使用原始的点云,将采集的误差也引入了参数中,如基于PointNet 的算法、基于YOLO 的算法等;在设计深度神经网络时,仅仅做卷积计算,忽略了卷积带来的数值偏移,如VoxelNet中的中间层和RPN 模块。本文尝试采用统计滤波算法将原始点云进行过滤,剔除离群点,优化待处理点云数据;通过添加最大池化层,减小卷积偏移误差,有效降低模型的过拟合,同时保证点云数据几何信息的不变性。
1 算法的总体思路
首先,利用统计滤波算法将原始的三维点云数据进行过滤,剔除离群点,减小离群点带来的误差,并对比过滤前后点之间的平均距离;其次,优化VoxelNet 的特征学习网络,进行点云数据的编码,使数据张量化;再者,对RPN 添加最大池化层,改进RPN 的检测性能,改善算法的检测精度;最后,通过多次实验分析,探讨以往算法的不足之处,体现数据预处理和最大池化对目标检测算法的重要性。基于三维点云的道路障碍物检测方法的总体框架如图1所示。
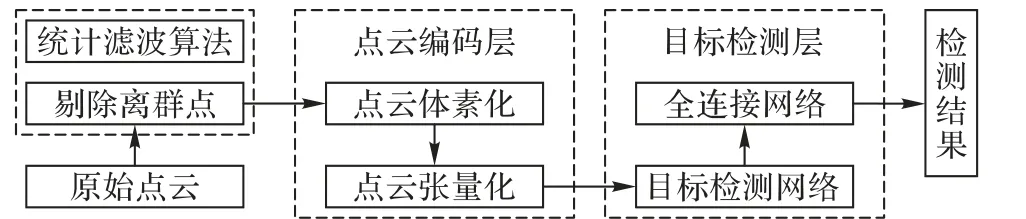
图1 道路障碍物检测方法的总体框架Fig. 1 Overall architecture of the proposed on-road obstacle detection method
2 点云预处理
在汽车无人驾驶场景下,基于深度学习的三维目标检测的主要对象是车载激光雷达扫描并采集得到的点云数据。目前业内有许多成熟完备的点云开源数据库,如悉尼城市目标数据库、KITTI 数据库[1]、Apollo Scape 自动驾驶数据库等,为研究学者提供算法训练及验证的数据支持。KITTI 数据库数据丰富,目标类别标注完备,涵盖行车过程中所需检测的目标物体,如车辆、行人、骑行者等,特别是不同类型车辆的数据可以满足车辆检测算法训练,所以本文选择以KITTI 数据库的三维点云数据作为研究对象。
2.1 点云预处理的必要性
点云在KITTI 数据集中以二进制的形式储存,根据协议转化,可以得到目标物体外廓形态的纹理信息,即空间无序点三维坐标以及每一点对应的强度值。三维点在三维几何空间中是离散且独立分布的,在处理点云过程中应该保证点云中每个点的空间无序性、特征局部性和旋转不变性。若将具有t个点的某个点云样本直接输入算法模型中训练,则输入矩阵的行的排列将有t!种可能性,不仅增加了算法的复杂度,而且会降低算法的鲁棒性,最终导致算法效率的降低。点云中的点虽然在空间中呈独立分布的状态,但是邻近点之间存在必然的空间位置关系和几何拓扑特征。若能有效地提取出某区域点云的几何特征,即可检测出该区域内点集所表示的目标物体。将得到的点云通过所设计的算法中进行训练,对点集中每个点进行平移或旋转变换计算时,不应改变点之间相对的位置关系。
激光雷达对目标物体的扫描采集时,存在着硬件上或软件上的误差,使得某个点集区域上某个位置上点的三维坐标产生偏移,出现了离群点。离群点的产生对算法模型的训练会造成一定的干扰,可能会产生多余的特征信息,影响算法的准确性,甚至使算法模型训练达不到全局最优,或跳不出鞍点。所以,有必要剔除点集中的离群点,对点云进行预处理。
2.2 基于统计滤波算法的点云预处理
点云的每个点在笛卡尔坐标系下,以x、y、z三维坐标形式存在。假设某个点云样本为:

式中:t表示样本中点云中点的总个数;pi表示样本D中无序点,只取每个无序点的x、y、z三维坐标。计算点pt的距离阈值davg:
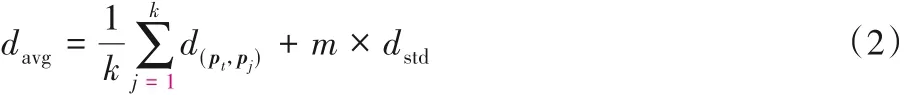
式中:k为点pt的邻近点个数;d(pt,pj)为点pt与其邻近的k个点之间的欧氏距离为阈值系数;dstd为点pt与其邻近的k个点之间的距离标准差。若某点与点pt的距离大于davg,则判定为离群点,将其剔除出点集。图2(a)为点云样本的初始视图,存在较为杂乱的离群点,点集分布不均;图2(b)为数据预处理后的视图,局部区域的点分布较为均匀,能为后续的训练提供更好的数据支撑。

图2 点云预处理前后对比Fig. 2 Comparison of point cloud before and after pre-processing
将每个点与其k近邻点之间的距离求平均,得到各点的平均k近邻距离,如图3 所示。数据预处理前的原始点云,总数量为19 031,最大的平均k近邻距离为46.60 cm,标准差为0.88;而经过数据预处理后,点的总数量为18 928,最大的平均k近邻距离为1.20 cm,标准差为0.11。离群点剔除后,点云分布均匀性更好,数据平滑度得到提高。由于点云表示的三维场景不同,经过统计滤波算法处理过后,各样本剔除的离群点个数不相同,剔除点的数量规模小于总数的10%。
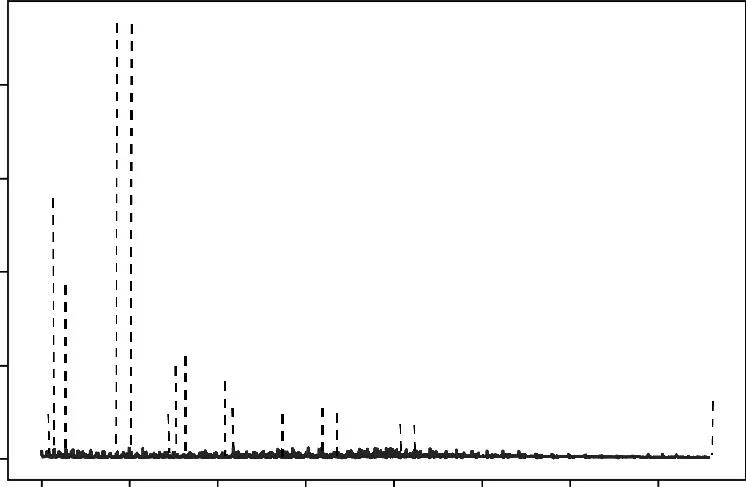
图3 点云中各点的平均k近邻距离Fig. 3 Average k-nearest neighbor distance of each point in the point cloud
为了进一步说明算法的有效性,随机抽取三个点云样本进行数据预处理,结果如表1 所示。从表1 可知,经数据预处理后,三个样本剔除点的数量在5%左右,点的平均k近邻距离的平均值减小15%左右,其标准差显著减小,即统计滤波算法有效地剔除了离群点,处理后点云表面粗糙度明显降低。
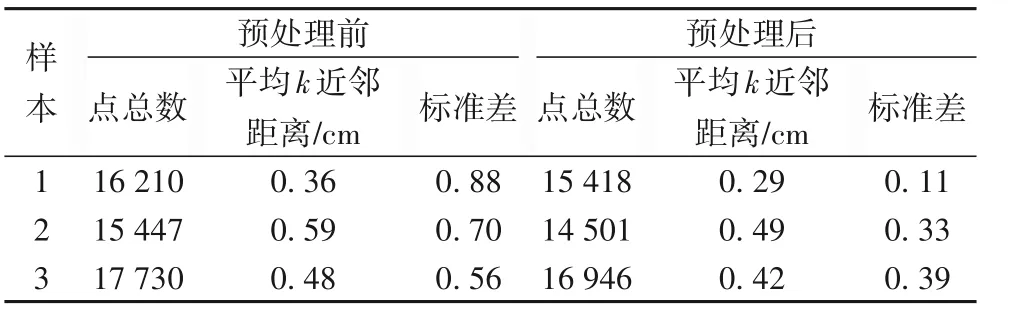
表1 数据预处理前后对比分析Tab.1 Comparison and analysis of data before and after pre-processing
3 深度神经网络
深度神经网络具有较强的信息特征提取能力,在机器视觉领域的二维图像检测方面应用广泛。针对三维点云检测目标的特征存在多样性和复杂性,引入深度神经网络以发挥其优异的性能。为实现基于三维点云的车辆检测,提出一个端到端的深度神经网络,包括两个模块层,分别是点云编码层和目标检测层。
3.1 点云编码层
对点云数据的体素特征进行编码处理,采用文献[6]的体素特征编码VFE 作体素特征的提取。利用设计的全连接层(Fully Connected Network,FCN)对同一个体素网格区间进行逐点提取,FCN 由线性层、批处理规范化层(BatchNorm)和整流线性单元(Rectified Linear Unit,ReLU)构成。再采用逐点最大池化(element-wise max pooling)提取每个体素网格的聚集特征。最后将得到的两个特征数据进行广播(broadcasting)操作,将逐点的特征拼接在一起。本文利用两个VFE 和一个FCN构成完整的体素特征提取器,最终得到四维张量数据,如图 4 所示,图中的C、H、W、D分别表示四维张量的维度,H、W、D维度指的是体素网格提取出的聚集特征尺寸大小,这些特征又构成新的C维度。
VFE层的处理方法类似于图像处理中对像素点的特征提取。但是,由于点云的无序性,通过设计出一个空体素体,将点云投入此空体素体中进行体素体分块分组处理,从而实现对无序点云进行有序的三维网格形式的体素化,同时兼顾点云局部特征。本文对划分后的所有体素格进行采样,并初步提取特征信息。由于在点云数据投入网络训练前已经完成数据预处理过程,所以对所有的点都可以采样提取。
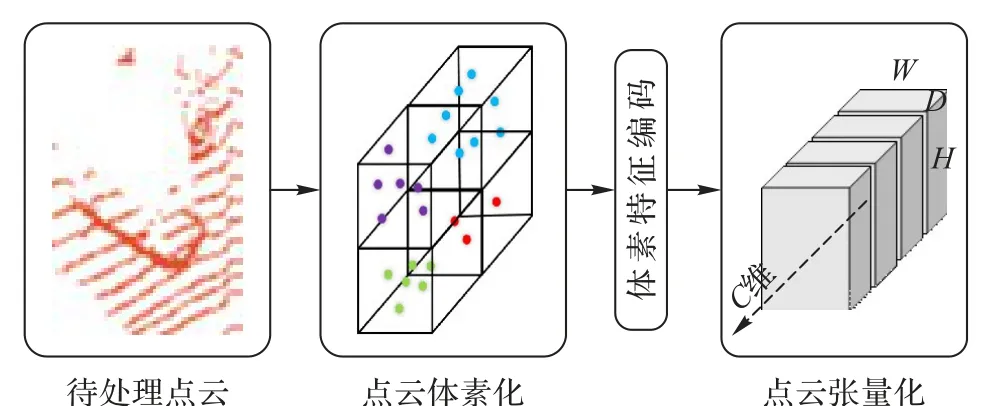
图4 数据张量化Fig. 4 Tensorizing of data
3.2 目标检测层
更快速区域卷积神经网络(Faster Region-based CNN,Faster R-CNN)[25]中的 RPN 在图像目标检测技术中已经十分成熟且有效,使用非极大值抑制(Non-Maximum Suppression,NMS)选定目标最终的预测边框。在三维目标检测中采用的深度神经网络模型[6,8]的目标检测大都移植了RPN 作为三维目标区域候选网络,并取得了良好的效果。为便于特征的提取和提高计算效率,以RPN 作为基础,本文提出了一种增加最大池化模块的目标检测架构,如图5所示。

图5 目标检测层架构Fig. 5 Architecture of object detection layer
算法中卷积层(Conv)不仅起到压缩数据的作用,更重要的是通过设定的激活函数,提取有可能的目标信息特征。本文设计的卷积层,过滤器设为3,步幅取2,不作填充处理,激活函数为ReLU函数。
受到YOLO 间隔插入最大池化模块的启发,保留VoxelNet 网络中的全卷积神经网络架构,像YOLO 一样合理地增加了最大池化层,强化了网络的性能。卷积计算是卷积神经网络中重要的操作,由于共享权值参数的设计,使得卷积层不仅能提取到有用信息,而且计算量比全连接神经网络的计算量要小。一个卷积核则对应得到一个特征映射,卷积核的数量也称通道数(channel),同样通道数量也等于特征映射的数量。若检测的特征增加,而设计出多个不同的卷积核,则得到多个不同的特征映射,此时由原始数据而得到了多个特征映射,通道数量增加,即此层的神经元数量增加,此时卷积网络中层的维度增加,训练的成本也随之增加。此时算法框架中需引进池化层,进行适当的降维处理。
池化层在卷积神经网络中起到了压缩数据的作用,尤其可以保持点云几何信息上的不变性。若仅仅只做卷积计算,则会造成预测值的偏移。因此本文提出增加最大池化层(MaxPool),不仅可以减小偏移,而且可以最大地保留三维目标物体的纹理信息。本文设计MaxPool(ps,s,input)作为最大池化层的最小单元模块,其中:ps 代表pool size;s 则表示strides。为了操作的便捷性,本文将padding 的参数设定为same,使模块的输入与输出的张量形状一致。本文算法加入的最大池化层,过滤器设为3,步幅取2,作填充处理,保持张量尺寸不变。在原有的全卷积层1 中插入一个最大池化层,数据流经过的路径为:一个卷积层,一个最大池化层,两个卷积层。原全卷积层2 中也同样地插入一个最大池化层,数据流经过的路径为:两个卷积层,一个最大池化层,四个卷积层,原全卷积层3的操作与原全卷积层2一致。
3.3 损失函数及部分参数选取
损失函数是不可或缺的一个模块,设计如下:

式中:Lpro为区域得分损失函数模块,即分类器,与Faster-RCNN 中的分类器模块一致;Lreg为目标候选区域位置模块,即回归器。设定候选目标(三维)边界框(xi,yi,zi,li,wi,hi,θi),其中 (xi,yi,zi)为中心位置坐标,(li,wi,hi,θi)为长、宽、高及角度。设定真实目标(三维)区域,其中为中心位置坐标为长、宽、高及角度。Lreg的设计如下:
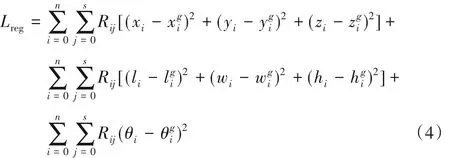
式中:n 为点云样本体素个数;s 为候选目标边界框的个数;Rij使用SmoothL1函数[25]。
本文对KITTI 原始点云数据的裁剪开度为0°~90°,与KITTI 高清镜头的开度(opening angle)一致。本文采用VoxelNet等论文中对车辆、行人和骑行者的anchors,这些数值符合实际目标大小的取值,例如对于车辆,本文使用的w、l、h分别为1.6 m、3.9 m、1.56 m,对于行人和骑行者的w、l、h 分别为0.6 m、0.8 m、1.73 m 和0.6 m、1.76 m、1.73 m。本文采用随机梯度下降法(Stochastic Gradient Descent,SGD),训练的学习率为0.001,随机梯度下降法简单且容易跳出局部极小继续训练,使设计的模型在训练过程中更快地向真实的模型靠近,达到预期值。
4 实验结果与分析
4.1 数据集及实验环境
本文实验采用KITTI 数据集中的7 000 多个点云训练样本。在进行数据的过滤和训练前,随机将点云样本分成训练集和验证集,各自约占50%。近3 500个样本对于复杂场景的监督式算法学习是不够的,故在训练过程中对训练样本进行扩充。在训练开始前先提取训练集样本中所有已标定的目标点云数据及其标签,随后在训练过程中随机地选取并插入在当前训练样本中。这种方法的使用,不仅增加了训练样本数量,而且可以模拟不同环境下的目标。
基于谷歌公司TensorFlow 进行深度神经网络架构的搭建,实验的环境配置为因特尔Xeon Silver 4108 处理器,64 GB运行内存,英伟达GTX1080Ti 11GB显存显卡。
4.2 实验流程
本文算法VNMax的实验流程具体如下:
1)数据预处理。对KITTI 数据集进行划分,对训练集进行统计滤波处理,剔除离群点。
2)数据扩充准备。建立新的点云数据库,存放训练样本中的已标定的目标及标签。
3)算法训练。设定完成整个训练集为一次迭代,迭代次数为200。
4)样本测试。采用测试集进行算法的测试。
4.3 结果分析
将处理好的点云数据投入本文设计的深度神经网络中进行训练,在TensorBoard 中训练和验证的损失值折线图如图6所示,smoothing 设为0.6。从图6 可知,当训练集的迭代次数超过50 000,损失值在1左右波动,并趋于平缓;对于验证集数据,迭代次数小于2 000,损失值急剧下降并在1.8 左右波动,且无上升趋势,说明算法并未出现过拟合现象。
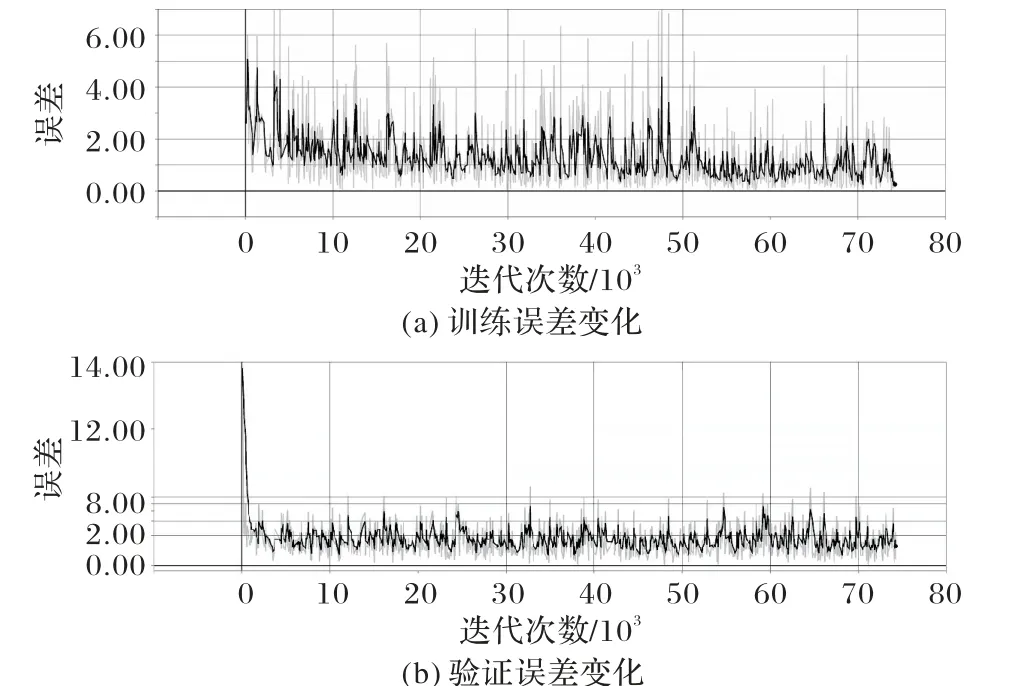
图6 训练及验证误差Fig. 6 Loss values of training and validation
在同样的运行环境条件下,将同样处理好的点云数据投入VoxelNet 进行训练,与本文设计的深度神经网络架构结果对比如表2 和表3 所示,采用KITTI 数据集评价体系,对车辆检测不同算法所得到平均精度进行比较。表2 和表3 中的算法 VeloFCN、Complex-YOLO 和 VoxelNet 分别指文献[26]、[17]和[6]的实验检测结果,训练采用的数据均为原始点云数据。VoxelNet(filtered)指的是VoxelNet 模型训练并使用滤波处理后的数据;VNMax 指的是本文沿用VoxelNet 的体素编码网络并嵌入最大池化层的新深度神经网络模型,并且对原始点云数据作滤波处理。表中简单、中等和困难分别表示KITTI数据检测任务的难易程度,即点云数据的稀疏程度。困难程度的点云数据最稀疏,训练学习难度最大。
表2 的对比表明本文所提出的算法在车辆检测和定位上所得到的平均精度普遍优于VoxelNet模型。增加的最大池化层提高了算法的特征提取能力,减小了由多层卷积带来的误差,在KITTI 官方服务器中,算法VoxelNet 的车辆定位在简单、中等和困难任务的精度分别为:34.54%、31.08% 和28.79%,本文提出的算法 VNMax 分别高出 11.30、6.02 和3.89个百分点。
表3 为车辆3D 检测及鸟瞰视图检测的平均精度对比,可以看出本文提出的算法在提高检测和定位的同时,也保持了3D检测和鸟瞰视图检测的平均精度。
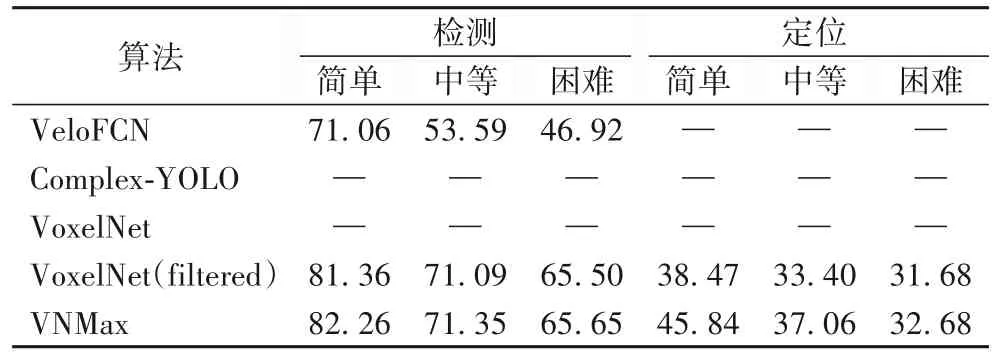
表2 车辆检测及定位的平均精度对比 单位:%Tab.2 Average precision comparison of vehicle detection and location unit:%
根据表 2、3 中的 VoxelNet 和 VoxelNet(filtered)对比可以看出,数据经过滤波后的处理对检测的性能是有帮助的。最后VoxelNet、VoxelNet(filtered)和VNMax 作对比,可以看出数据的滤波处理和最大池化层对检测的平均精度有显著的作用。本文利用TensorFlow 库进行滤波算法的编程,对每帧点云数据预处理的平均时间为0.13 s。检测算法的时间与VoxelNet检测时间相当。图7为车辆检测结果,采用点云数据检测到的结果对应地投影到图像上。
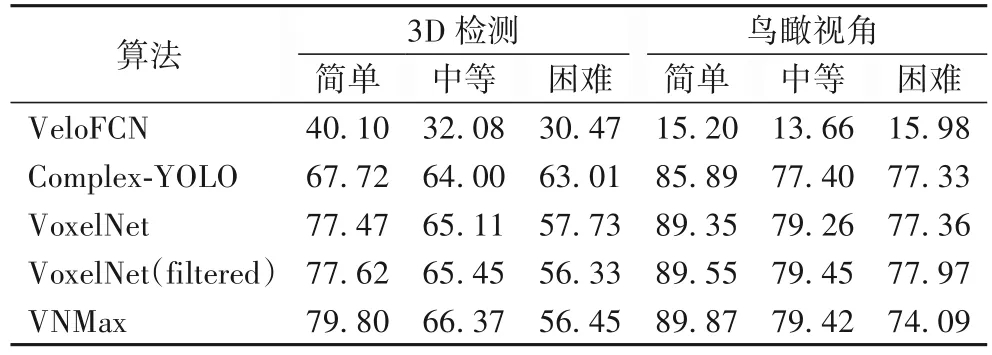
表3 车辆3D检测及鸟瞰视图检测的平均精度对比 单位:%Tab.3 Average precision comparison of vehicle 3D detection and aerial view detection unit:%

图7 车辆的检测结果可视图Fig. 7 Visibility maps of vehicle detection results
5 结语
基于车载激光雷达采集的三维点云数据,本文采用统计滤波算法对原始数据进行前期处理,使用最大池化模块的不变性优化原有的网络架构,构建了端到端的深度神经网络。实验结果表明,该滤波算法可以有效地剔除离群点,减少其他因素的干扰;最大池化模块的不变性使得网络具有更强的鲁棒性,能为无人驾驶技术的感知系统提供一种有效的目标检测算法。由于点云数据具有稀疏性,最大池化容易导致局部细节特征的忽略,在后续的工作中,可结合信息融合技术及YOLO系列版本的算法,进一步提高算法检测的精度和速度。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
材料与冶金学报(2022年2期)2022-08-10
舰船科学技术(2022年11期)2022-07-15
温州大学学报(自然科学版)(2022年2期)2022-05-30
健康体检与管理(2022年4期)2022-05-13
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年4期)2021-11-24
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
