
嵌入注意力和特征交织模块的Gaussian-YOLO v3目标检测
2020-09-04 10:00吴亚娟罗南超郑伯川
计算机应用 2020年8期
刘 丹,吴亚娟,罗南超,郑伯川
(1. 西华师范大学计算机学院,四川南充637009; 2. 阿坝师范学院计算机科学与技术学院,四川阿坝623002;3. 西华师范大学数学与信息学院,四川南充637009)
0 引言
先进驾驶辅助系统(Advanced Driver Assistant System,ADAS)利用安装于车上的各种传感器,如摄像头、雷达、激光和超声波等,实时采集车内外场景数据,实时分析判断,提醒驾驶者注意异常交通和道路情况,使驾驶者尽早察觉可能的危险,提高驾驶安全性。对车辆和行人等的目标检测是ADAS 中重要的任务之一。ADAS 中不仅对目标检测的准确性要求高,而且不能漏掉对小目标的检测。
目标检测的任务是识别出图像或视频中的感兴趣物体,同时检测出它们的位置,被广泛应用于机器人导航、智能视频监控、工业检测、航空航天等诸多领域。同时,目标检测也是身份识别领域的一个基础性算法,其效果直接影响后续的特征识别、步态识别、流量计数、实例分割等任务。
目前,目标检测已经广泛采用基于深度神经网络的检测方法,如两阶段的Faster R-CNN(Faster Region-Convolutional Neural Networks)系列方法[1-4],一阶段的单次多框检测(Single Shot multibox Detector,SSD)系列方法[5-10]和 YOLO(You Only Look Once)系列方法[11-13]。YOLO v3[13]由于采用了更多尺度检测框和更简洁的网络结构,因而具有检测速度快、能检测小目标等优点。随后的 Gaussian-YOLO v3[14]利用 Gaussian 模型来对网络输出进行建模,使得网络对输出每个检测框的不确定性进行抑制,提高了检测位置的准确性。
基于驾驶者角度观察到的前方道路情况复杂多变,目标种类多,大小目标都有。距离远的图像区域内目标物体通常尺寸小,特征不明显,难以对其准确检测定位。YOLO v3虽然具有检测小目标的能力,但是对远距离多个小目标的检测能力不够理想,容易漏检;而Gaussian-YOLO v3虽然抑制了检测框的不确定性,但没有能提升对小目标的检测能力。
注意力机制[15]通过三元组(key,query,value)提供一种有效捕捉全局上下文信息的建模方式。近年来,注意力机制被广泛应用于自然语言处理和计算机视觉领域。文献[16]中指出人类看东西时不是将目光放在整张图片上,而是根据需求将注意力集中到图像的特定部分。如果在计算机视觉处理中对人的注意力机制进行建模,将其应用到一些视觉任务中,将更有利于完成这些任务,如图像分割、目标检测等。Google Mind 团队提出在循环神经网络(Recurrent Neural Network,RNN)[17]模型上使用注意力机制来进行图像分类,取得了较好的结果;Xu 等[18]将注意力机制引入到了图像描述领域,也取得了不错的效果;文献[19]中提出的注意力mask 通过给每个特征元素都找到其对应的注意力权重,同时形成了空间域和通道域的注意力机制;文献[20]中运用注意力设计了一个通用的非局部神经网络来描述图像每个像素对前后帧图像的贡献关系,从而改善与可视化理解相关视觉任务的可解释性;文献[21]中提出的一种轻量、通用的注意力模型(Convolutional Block Attention Module,CBAM)更关注目标物体本身,比基准模型有着更好的性能和更好的解释性。可见,注意力机制能提高计算机视觉任务的性能。
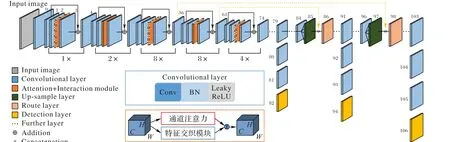
图1 整体网络结构Fig. 1 Overall network structure
目标检测是对图像中特定关注的区域进行识别并定位。在应用目标检测算法时,如果在需要关注的目标区域投入更多的注意力资源,获取更多的细节信息,抑制其他区域信息,从而使目标检测算法从大量信息中快速获取到高价值信息,将有利于提升目标检测的性能。
本文通过借鉴SENet(Squeeze-and-Excitation Networks)[22]网络中的注意力机制,在Gaussian-YOLO v3 中嵌入注意力机制和特征交织模块,从而提升Gaussian-YOLO v3 的目标检测性能。主要改进包括以下两点:
1)引入文献[21]中的注意力模型,自适应校准每个通道的特征响应值,自动获取每个特征通道的权重,根据通道权重增强有用特征,抑制不重要特征;
2)引入文献[23]中的特征交织模块,通过不同通道的特征交织混合,丰富特征信息,有效解决网络前向传递信息丢失、小目标难检测的问题,提高网络对小目标的特征提取能力。
1 嵌入注意力和特征交织模块的Gaussian-YOLO v3
本文方法在Gaussian-YOLO v3 中添加通道注意力机制,自主学习每个通道的权重,从而增强关键特征、抑制冗余特征;同时在Gaussian-YOLO v3中增加特征交织模块,提高对小目标特征的提取能力。嵌入注意力和特征交织模块的Gaussian-YOLO v3的网络结构如图1所示(参照文献[14]),图中虚线框部分是嵌入注意力和特征交织的改进模块。
YOLO v3 的主干网络是Darknet53,该网络使用步长为2的卷积来实现5 次下采样,降低了池化带来的梯度负面效果。同时使用了23 个残差模块,在增加网络深度的同时降低产生过拟合的风险。Convolutional layer 层是YOLO v3 的基本组件,该组件由 Darknetconv2d+BN+Leaky ReLU 构成。85、97 层是上采样层,通过上采样提升深层特征图大小,并与浅层特征图进行级联形成 Router 层[24]。如 85 层将 16 × 16 × 256 的特征上采样得到32 × 32 × 256的特征,再将其与61层32 × 32 ×512 的特征级联得到 32 × 32 × 768 的特征。82、94、106 特征图为检测层,在三条预测支路采用全卷积结构。三个检测层的大小分别为:16 × 16 × 45、32 × 32 × 45 和 64 × 64 × 45,由于感受野大小不同,因此用于分别检测不同尺度大小的目标。检测层每个网格单元设置3个检测框,因此每个网格单元预测向量长度为:3 × (10 + 4 + 1) = 45,其中 10 对应 BDD100K 数据集[25]的 10 类,3 表示每个网格单元包含 3 个检测框,4 是每个检测框4 个位置偏移量,1 是每个检测框包含目标的置信值。9个检测框的大小采用文献[14]对BDD100K数据集聚类得到的结果。
为了进一步提升特征表达能力,本文在主干网络的每个残差模块中的相邻两个卷积层之间加入一个同时融合了通道注意力和特征交织的特征融合模块构成新的残差模块。通道注意力模块有利于提取重要特征[26],而特征交织模块有利于丰富特征信息。通道注意力模块和特征交织模块将在后面作更详细的介绍。
1.1 Gaussian-YOLO v3网络输出策略
YOLO v3的输出结果中,目标类别是概率值,但目标框位置是确定值,不是概率值,无法获得每个预测框的可靠性。Choi 等[14]利用 Gaussian 模型来对网络输出进行建模,在基本不改变YOLO v3 结构和计算量的情况下,建模之后能够输出每个预测框的可靠性。如图2 所示(图像来源于文献[14]),Gaussian-YOLO v3 通过增加预测框位置的概率输出和改进网络的损失函数,实现了对预测框可靠性的输出。
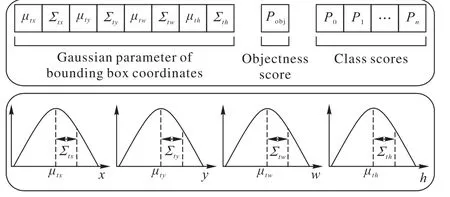
图2 基于Gaussian分布的YOLO v3网络输出[14]Fig. 2 Output of YOLO v3 network based on Gaussian distribution[14]
采用的Gaussian模型为:
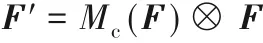
其中μ(x)为均值函数,Σ(x)为方差函数。
预测框位置所采用的损失函数为:
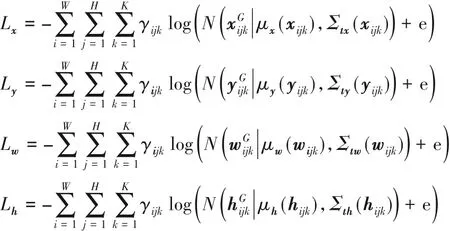
其中:γijk为是否是最合适的预测框,值为1 表示是,0 表示否。预测框的可靠性C由三部分的乘积构成:
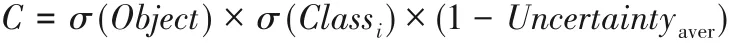
1.2 通道注意力模块
图1中的通道注意力模块如图3所示。
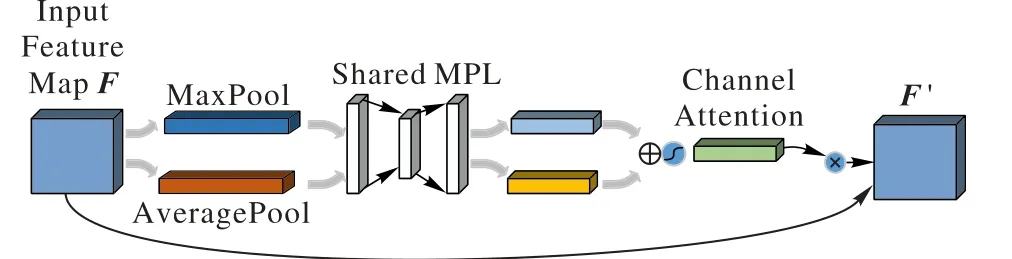
图3 通道注意力模块Fig. 3 Channel attention module
通道注意力模块完成下列公式的计算:
其中:F ∈ RH×W×C为输入特征图,F′∈ RH×W×C为经过注意力提升后的特征图;H、W、C 分别表示特征图的长度、宽度和通道数;⊗表示逐元素乘法;Mc(F)表示对F 在通道维度上作注意力提取操作。Mc(F)的计算公式为:
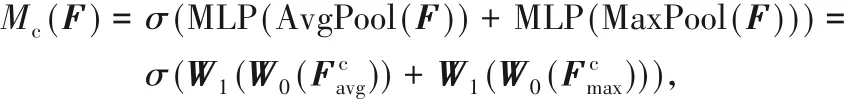
图4 展示了添加注意力模块和没有注意力模块时,第一个检测层(82 层)中目标置信值的情况(只显示高于阈值0.8的置信值,并映射到原图上)。图4 中深色部分是目标置信值较高的地方,可以看出,本文设计的通道注意力模块使深色区域部分更多,而没有添加注意力模块的Gaussian-YOLO v3 对部分真实目标物体给予相对更低的置信值(部分低于阈值,没有显示出来)。这说明添加注意力模块增强了特征图中目标区域的信息,抑制了非目标区域的信息,提升了网络对前景目标和背景的区分能力。

图4 目标置信值对比Fig. 4 Comparison of object confidence
1.3 特征交织模块
目前常见的卷积神经网络提取特征的方法大多都以分层方式进行,即每层各个通道采用相同的方式提取。这种分层方式要么对每一层使用多个尺度的卷积核进行提取特征,如SPPNet(Spatial Pyramid Pooling Network)[27],要么是对每一层提取的特征进行融合,如 FPN(Feature Pyramid Network)[28]。本文在加入通道注意力的同时加入了一种特征交织模块。通过在同一层特征图内不同通道之间建立连接,交织不同通道的特征,解决网络前向传递信息丢失、小目标难检测的问题,提高网络对小目标的特征提取能力。特征交织模块结构如图5所示。

图5 特征交织模块Fig. 5 Feature interwine module
特征交织模块将输入特征图按通道分为s 个通道组,分别由x1,x2,…,xs表示,每组都有相同的宽和高,通道数为输入特征图的1/s。每组的输出yi通过如下公式计算。

其中:Ki为3× 3的卷积核;s为比例尺寸控制参数,设置s= 4。在同一个特征图的不同通道组包含了不同感受野大小的特征,相比一个原始的3× 3 的卷积核,进行特征交织后的特征图具有更加丰富的特征。
2 实验结果
实验电脑硬件配置为:双核Intel Xeon CPU E5-2650 v4@2.20 GHz,内存大小为264 GB,4 块Tesla P40 显卡,每块显存24 GB。软件系统配置为:Ubuntu 16.04LTS,CUDA 9.0,CUDNN 7.3,Python3.6编程语言,Darknet深度学习框架。
为验证本文方法的有效性,在BDD100K 数据集上对YOLO v3、Gaussion-YOLO v3和本文方法进行对比。BDD100K数据集由伯克利大学AI 实验室发布,包含10 万段高清视频、10万张关键帧(每个视频的第10 s关键帧)以及相应的标注信息。本文实验使用10 万张关键帧图像以及每帧图像的道路目标边界框标注数据。道路目标共有10 个类别,分别为:Bus、Light、Sign、Person、Bike、Truck、Motor、Car、Train、Rider,总共约有184 万个标定框。针对目标边界框标注,10 万张图像数据集分为7万张训练集、2万张测试集和1万张验证集。
2.1 模型训练
在训练阶段,主干网络采用在ImageNet 上预训练好的模型参数。训练时,采用动量为0.9,初始学习率为0.001,学习率下降参数为0.000 1,衰减系数为0.000 5,图像输入尺寸为512 × 512。通过调整饱和度、曝光量、色调增加训练样本。使用小批量随机梯度下降进行优化,每次迭代的批量大小为512,经过45 000 次左右迭代后网络收敛。图6 是本文改进网络训练过程中的损失函数变化曲线,纵轴为平均损失值,可以看出网络损失处于稳定下降状态后最终收敛。模型收敛后,交并比(Intersection over Union,IoU)的值稳定在0.8 左右,意味着检测准确,获得了相对可靠和有效的目标检测网络模型。

图6 网络训练损失函数曲线Fig. 6 Loss function curve of network training
2.2 检测结果
图7 是三种方法在BDD100K 数据集的部分图像上的检测效果。图7 中浅色箭头所指的目标是YOLO v3 或者Gaussion-YOLO v3 漏检,但是却被本文方法检测到的目标。深色箭头所指目标是在GT(Ground Truth)中误检目标。从图7中可以看出本文方法对目标的检测与GT中标注更一致。
测试测试集时,采样平均精确率均值(mean Average Precision,mAP)和F1分数评价检测性能,计算公式如下:
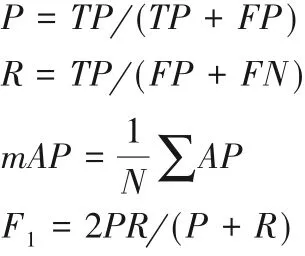
其中:TP(True Positive)是正确检测目标数量,FP(False Positive)是误检目标数量,FN(False Negative)是漏检目标数量;AP(Average Precision)是每类物体平均精确率,其值等于Precision-recall 曲线下方的面积;N是总的类别数量。精确率(P)和召回率(R)在实际中是相互制约的,单独比较会有失平衡,所以使用了F1分数作为综合评价指数,F1分数同时兼顾精确率和召回率,是两者的调和平均数。
表1 列出了三种对比方法对10 类目标的平均精确率AP,表2 列出了三种对比方法的mAP、F1分数、模型运算所耗费的十亿次浮点运算量BLFOPs(Billion Float Operations)和检测速度FPS(Frames per second)。可以看出本文方法的对每类目标的AP值都高于其他两种方法;本文方法的mAP和F1分数分别为20.81%、18.17%,也高于其他两种方法;在相同设备情况下,本文模型复杂度稍有提高,但检测速度FPS 与Gaussian-YOLO v3几乎保持一致。
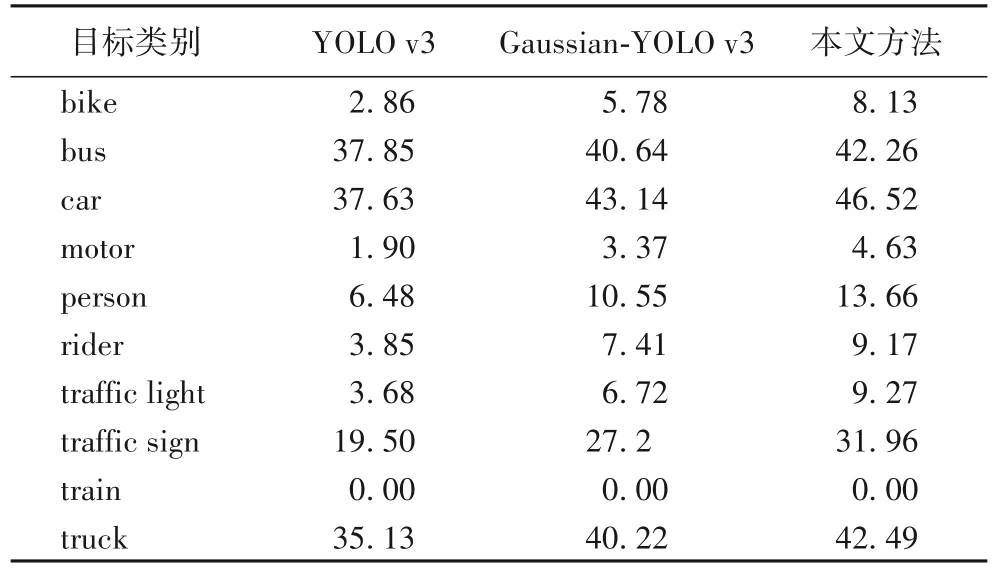
表1 目标的平均精确率比较 单位:%Tab.1 Average precision comparison of objects unit:%

表2 三种方法性能比较Tab.2 Performance comparison of three methods
2.3 小目标检测效果
本文对小目标进行了定义:设定目标面积占图像总像素比例小于等于0.3%的物体为小目标。由于网络输入图像大小为512 × 512,因此设定的小目标都不超过786 个像素。图8 为图7 原图GT中去除大目标后的小目标样例。从图8 可以观察到,本文方法能够检测到更多的小目标。
分别统计三种方法对小目标的检测情况,包括:真实标定GT数量、真正例TP数量、假正例FP数量,统计结果如表 3 所示。从表3 中可以看出,本文方法检测出的TP数量最多,同时FP数量最少。与YOLO v3相比,本文方法对小目标的检出率提高了13.49%,误报率降低了8.7%;与Gaussian-YOLO v3相比,对小目标的检出率提高了7.27%,误报率由降低了3.5%。

表3 小目标检测统计对比Tab. 3 Statistic comparison of small object detection

图7 检测定位效果Fig. 7 Detection and positioning effect

图8 小目标检测样例Fig. 8 Detection examples for small object
3 结语
本文提出的Gaussian-YOLO v3改进网络结构通过嵌入注意力和特征交织模块不仅使特征图的不同通道学习到了通道权重,而且使通道间的特征进一步交织,从而提升了原Gaussian-YOLO v3 的目标检测性能,特别是对小目标的检测性能也得到了提升。同时也注意到,不管是YOLO v3、Gaussian-YOLO v3,还是本文的改进 Gaussian-YOLO v3,对DBB100K数据集的10类目标的平均精确率均值都较低,因此还需要开展进一步的研究。在汽车自动驾驶中,远处目标由于距离远,形成的目标图像小,经过多级网络卷积后,特征不明显甚至消失,因此今后将继续探索如何提升小目标的特征表达,提升网络对小目标的检测能力。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
美食(2022年2期)2022-04-19
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
女报(2019年3期)2019-09-10
第二课堂(课外活动版)(2016年2期)2016-10-21
华人时刊(2016年17期)2016-04-05
中学英语之友·高一版(2008年10期)2008-12-11
