
基于Stacking多GRU模型的风电场短期功率预测
2020-09-01 01:53高金兰段玉波王宏建
吉林大学学报(信息科学版) 2020年4期
高金兰, 李 豪, 段玉波, 王宏建
(东北石油大学 电气信息工程学院, 黑龙江 大庆 163318)
0 引 言
据中国可再生能源学会风能专业委员会(CWEA: Chinese Wind Energy Association)的数据统计, 截至2018年末, 我国成为全球首个风电装机容量超过200 GW的国家。近年来风力发电发展迅速, 但由于受到气象及地形等因素的影响, 风电场出力具有很强的波动性。风电大规模的并网也给电力电网的稳定性带来了挑战。通过对风电场的历史数据进行分析, 获取未来短时间内风电场出力的变化趋势, 能为电网的调度计划提供依据, 提高电网运行的安全性、 稳定性和可靠性[1]; 同时根据国家能源局统计显示, 我国2018年全年弃风电量达到9.972×1016J, 而利用这些电量可以减少30 Gkg二氧化碳的排放。因此, 风电功率预测问题如果无法得到解决, 将影响风电并网, 造成能源浪费, 使我国政府为节能减排所作的努力大打折扣。
近年来, 对风电场短期输出功率进行预测成为学者们研究的焦点, 越来越多的新理论新方法也相继被提出。长短期记忆神经网络(LSTM: Long Short-Term Memory)模型在处理时序数据的特征信息时有很好的效果。3个门式结构的加入使LSTM神经网络在处理问题时能选择性忘记其中一部分不关键信息而把一些重要的信息关联在一起, 从而记忆起更长的序列。同时这种结构也解决了传统循环神经网络(RNN: Recurrent Neural Network)处理问题时梯度消失以及梯度爆炸的问题[2-3]。文献[4]提出了利用长短期记忆神经网络建立模型进行风电的功率预测, 与传统的循环神经网络模型的预测方法相比, 该模型在风功率预测过程中解决了处理时序问题时所产生的长期依赖性问题。文献[5]采用通过建立门控循环单元(GRU: Gated Recurrent Unit)网络预测模型实现短期风电功率预测, 该方法具有训练速度更快、 系统占用内存更少的优点。文献[6]引入BiLSTM(Bi-directional Long Short-Term Memory)算法建立模型对风电场输出功率进行预测, 该方法凭借双向循环结构, 有效减少了陷入局部最优情况的发生。
深度学习的快速发展为风电场的功率预测提供了更多的思路和方法。GRU神经网络是LSTM神经网络的一个变体, GRU保持了LSTM的预测效果, 且结构更加简单, 此外通过堆叠的设计能增加网络的深度, 提升模型预测的准确度。Stacking算法是一种集成算法, 可通过聚合多个回归模型提升预测精度[7]。笔者在GRU模型的基础上建立多个多层GRU作为第1级预测模型, 然后再以GRU为基础建立第2级预测模型, 最终在Stacking集成框架下对二者进行融合, 利用其实现风电场短期功率预测。笔者将Stacking集成融合模型引入风电场短期功率预测领域, 并探索该模型在风电场短期功率预测中的可行性。
1 算法理论
1.1 GRU神经网络
LSTM神经网络因为独有的门式结构, 使其被广泛应用于时间序列预测任务。然而因其复杂的内部结构, LSTM神经网络的训练通常需花费很长时间。GRU是由Chung等[8]提出的LSTM的一种变体, 它较LSTM的结构更加简单, 并且在保留LSTM性能的前提下其训练速度也更快。GRU的结构如图1所示。

图1 GRU的单元结构Fig.1 GRU unit structure
GRU将LSTM单元结构中的遗忘门和输入门合并成了一个重置门, 因此GRU单元相比LSTM单元结构只有两个门, 分别是重置门和更新门, 既图中的rt和zt。重置门有助于捕捉时间序列的短期依赖关系, 更新门有助于捕捉时间序列的长期依赖关系[9], GRU的前向传播公式如下
rt=σ(Wr·[hbt-1,xbt]+br)
(1)
zt=σ(Wz·[ht-1,xt]+bz)
(2)
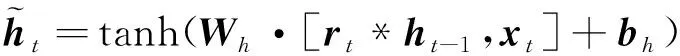
(3)

(4)
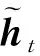
1.2 多层GRU模型
为提升预测模型对时间序列信息的提取能力, 笔者在此引入了多层GRU神经网络模型。通过搭建多层GRU神经网络, 使单个GRU单元的输出不仅到达本层的下一个GRU单元, 而且到达下一个堆叠层的GRU单元, 从而增加了网络深度, 提高运算效率, 最终获得更好的准确性。多层GRU模型的结构如图2所示。
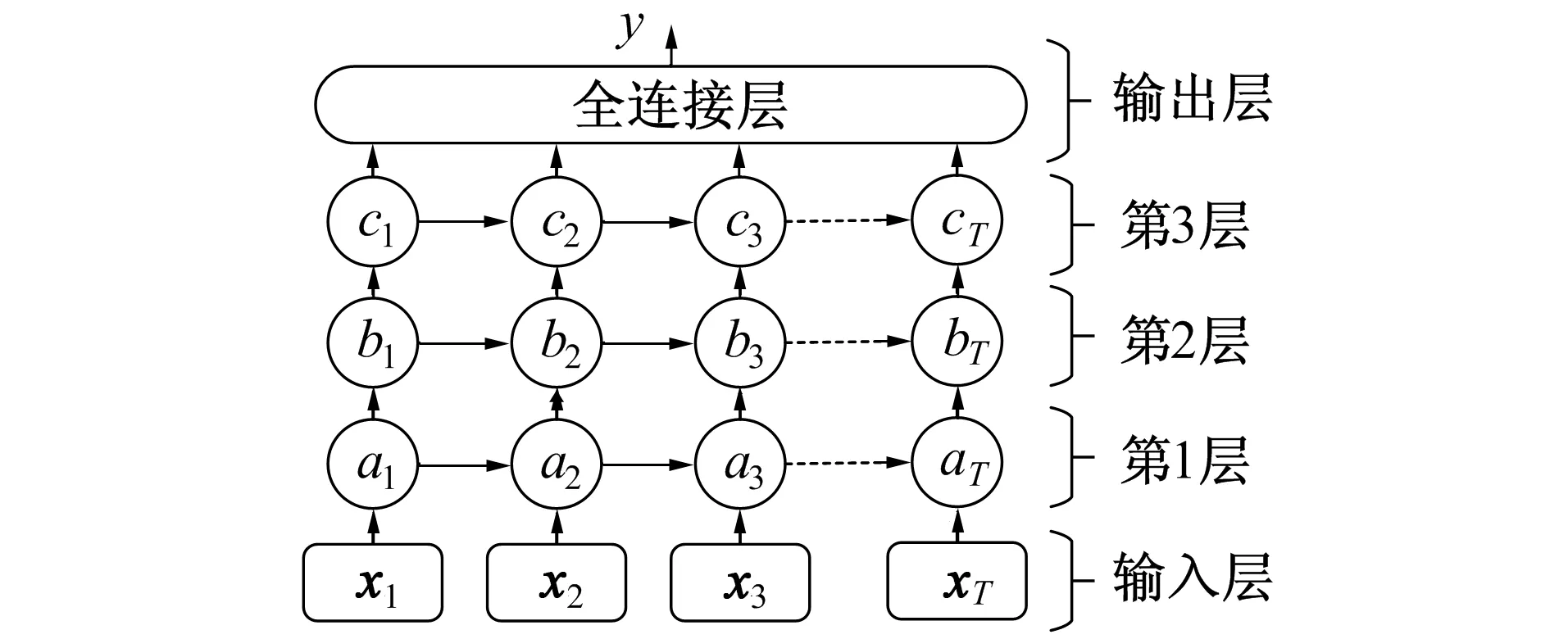
图2 多层GRU模型的结构图Fig.2 Structure diagram of a multilayer GRU model
在多层GRU模型中特征信息的提取部分由3层堆叠的GRU层完成, 而预测回归部分则由全连接层完成。图2中每个节点代表一个GRU单元, 对于时间序列T的特征序列{x1,x2,…,xT}, 输入到第1层GRU网络{a1,a2,…,aT}, 从低维的时间层面分析数据的时序关系, 之后令第1层的输出进入第2层GRU{b1,b2,…,bT}以及第3层GRU{c1,c2,…,cT}, 2、 3层的特征信息处理包含了上一层的学习输出以及高维的时间关系。最后利用全连接层将特征样本进行映射得最终的预测值, 模型的训练利用Adam优化算法调整每个GRU单元的权重以及偏置向量, 经几个循环迭代后, GRU的输出值在训练集上逐渐接近真实值, 得到最终的多层GRU预测模型。
1.3 Stacking算法
在预测模型中, 笔者的目标是训练出在各个方面都稳定且性能良好的模型, 但实际情况通常并不理想, 有时只能获得具有某些偏好的模型。集成学习通过组合几种模型以提高预测能力, Stacking算法是集成算法中最为典型的一种[12]。Stacking算法的集成学习方式如图3所示。

图3 Stacking算法的集成学习方式Fig.3 Integrated learning method of Stacking algorithm
Stacking集成学习算法首先将原始训练集划分为若干子训练集, 之后通过各子集训练初学习器, 将初学习器的学习结果作为输入使第2级的元学习器进行学习, 第2级的元学习器能发现并且纠正第1级初学习器中的预测误差, 提升整体的预测效果。其算法表示如下。
输入: 训练集D=(x1,y1),…,(xm,ym), 其中xi∈Rn,yi∈{-1,+1}; 初级学习算法ζt,t=1,2,…,T; 次级学习算法ξ。

2)初始化次级训练集:D′=Ø。
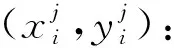
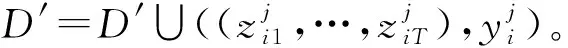
5) 训练次级学习器:h′=ξ(D′)。
2 基于Stacking算法融合多个多层GRU的预测模型
2.1 基于Stacking集成融合多层GRU模型分析
笔者在Stacking的集成学习框架下融合多个GRU预测模型, 在Stacking融合模型的第1级中选择3个多层GRU预测模型, 模型的第2级选用单层GRU模型纠正第1级中3个多层GRU模型的预测偏差, 并防止过拟合情况产生。基于Stacking集成融合多层GRU模型的整体结构如图4所示。
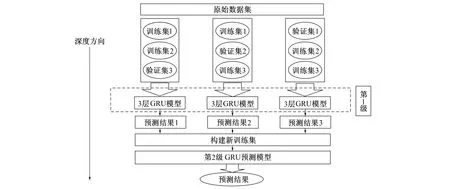
图4 Stacking集成融合多个GRU模型Fig.4 Stacking integration integrates multiple GRU models
首先利用交叉法, 将原始数据集划分为3个子数据集, 并确保每个数据集相互独立, 对第1级的每个3层GRU预测模型, 用两个子数据集作为训练集, 另外一个子数据集作为验证集。第1级中的3个不同的3层GRU预测模型都可生成一个预测结果, 将这3个预测结果重新合并为新的数据集。之后再利用第2级的GRU预测模型对新生成的数据集进行学习, 生成最终的预测结果。模型经过反向传播训练调整GRU单元的权重以及偏置向量, 最终生成Stacking集成融合的多层GRU预测模型。Stacking框架中的每个模型的训练方式统一采用Adam算法进行优化, Adam是一种自适应学习率的方法, 它利用梯度的1阶矩估计和2阶矩估计动态调整GRU模型中每个参数的学习率。Adam算法优化GRU模型的过程为
通常, 训练任何基于学习的模型, 最终的训练过程都可看作是一个优化问题。使损失函数最小化是序列预测任务中重要的一步。损失函数
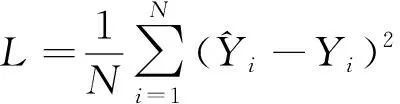
(11)
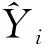
2.2 Stacking集成融合模型的风电场短期功率预测流程
Stacking集成融合模型的风电场短期功率预测步骤如下。
首先对数据进行预处理。风力发电输出功率的历史数据由于设备监测、 风机检修等原因, 导致获取的数据有缺失, 如风电场在有风正常运行过程中输出功率是不可能为零的, 这时如果数据中出现了0即为数据缺失。目前针对风功率数据集缺失数据处理的方法有很多, 如删除法、 加权调整法, 笔者采用滑动平均法对原始数据进行预处理。
其次对归一化的数据集Xm进行处理构建输入数据。对时间序列数据集, 以指定步长L为截取单位将数据集分割成多个片段, 建立训练样本XT={Xj|(n-1)l+1≤j≤nl},T∈{1,2,3,…,p}, 其中p表示分割成的片数, 将分割成的片数建立输入层作为模型的输入, 利用风电场历史数据划分的训练样本集对Stacking融合模型进行训练。
最后将风电场功率的预测样本的特征数据输入至Stacking融合模型, 数据将依次进行第1级多层GRU模型以及第2级GRU模型的处理。第1级模型中的多层GRU模型能深度提取风电场历史数据的特征信息, 第2级GRU模型能纠正第1级中多个GRU模型的预测偏差, Stacking融合模型将汇总两级模型的输出结果, 得到最终风电场的功率输出值。
Stacking融合模型的预测流程如图5所示。
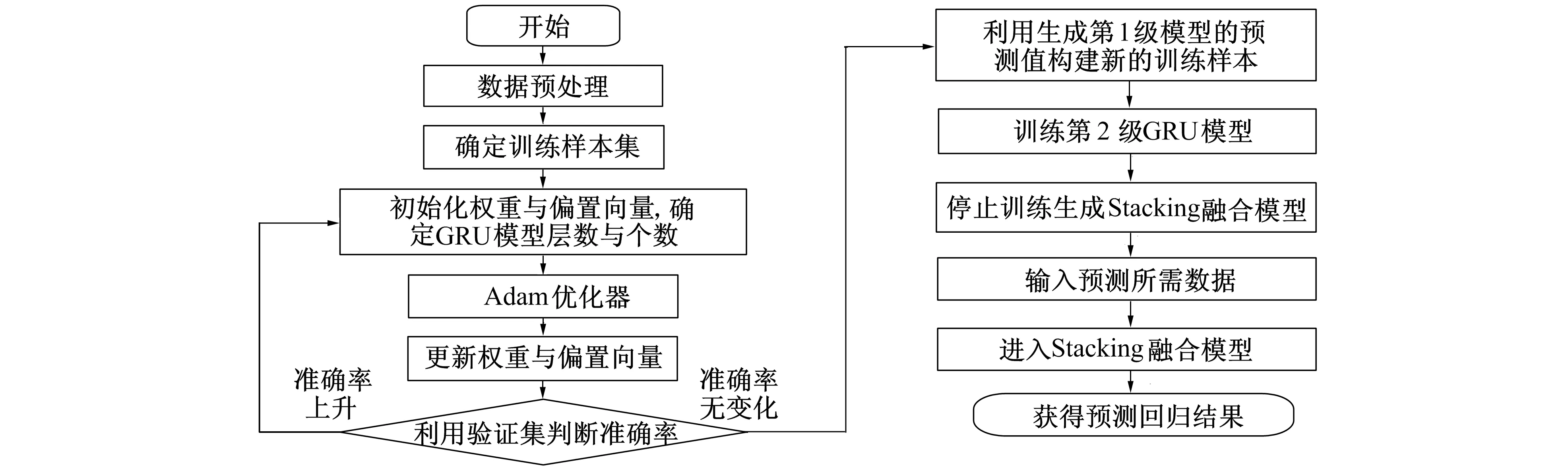
图5 Stacking融合模型的预测流程Fig.5 The prediction process of the Stacking fusion model
2.3 算法评价指标
在回归类预测问题中经常采用平均绝对误差(MAE: Mean Absolute Error)、 均方差(MSE: Mean Squared Error)、 决定系数(R2)、 平均绝对百分比误差(MAPE: Mean Absolute Percentage Error)进行预测评价, 其计算公式分别如下
3 仿真分析
实验数据来自宁夏太阳山发电场2017年全年的发电数据。采样分辨率为15 min, 每日的采样点为96个时刻。实验以Stacking融合模型进行建模实现风电场短期功率预测, 同时分别以LSTM、 多层GRU、 XGBoost及Stacking融合模型进行风电场功率预测实验, 并对几组模型的预测效果进行比较分析。实验应用的软件平台为Python3.7, 运行环境为Keras以及谷歌第2代人工智能学习系统TensorFlow, 利用的Python库为Pandas库、 Matplotlib库和Numpy库等。
3.1 实验参数设置及模型架构
Stacking融合模型的具体参数设置如表1所示。

表1 Stacking融合模型中参数的设置
Stacking融合模型中第1级的3个多层GRU模型采用3+1结构(3层GRU和1层全连接层)。第1级模型中的3个多层GRU中每层的激活函数选择tanh, 第1个3层GRU模型中每层的细胞个数选为64, 第2个3层GRU模型中每层的细胞个数选为128, 第3个3层GRU模型中每层的细胞个数选为256; 第2级单层GRU模型的细胞个数选为128, 激活函数tanh。每个GRU模型的全连接层细胞个数为1, 激活函数选择Linear。网络的优化器选择Adam, 损失函数采用均方误差。
3.2 模型训练
衡量模型的好坏最重要的一个因素就是其损失值。通过风电场历史数据构建训练集对模型进行训练, Stacking融合模型的损失函数曲线如图6所示。
图6中的损失值都是经过50次迭代训练, 使用训练集与验证集测试模型的损失值, 损失值越小、 越平稳代表当前模型训练得越好。
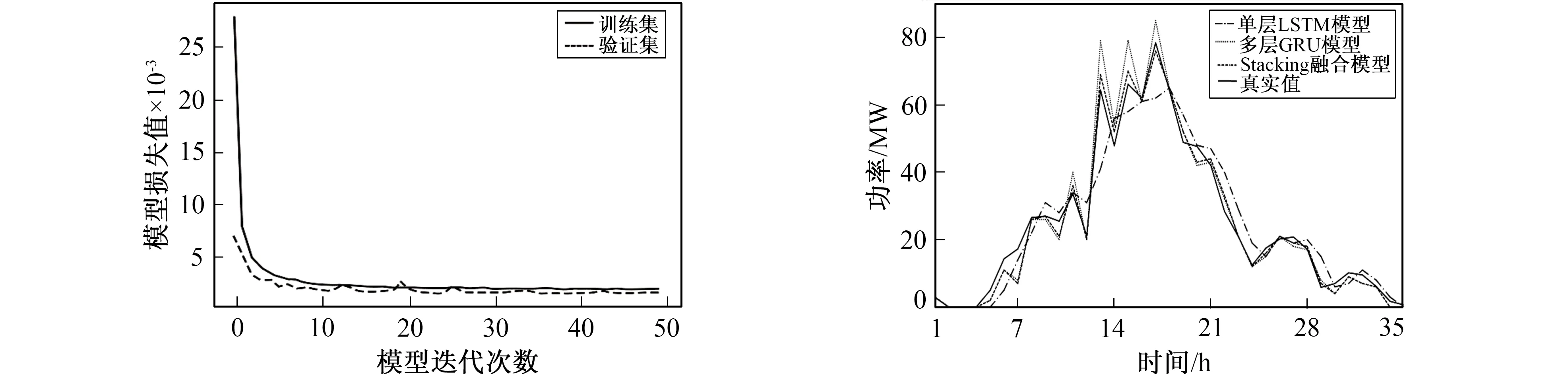
图6 训练集与验证集损失值对比曲线 图7 晴天发电功率预测对比曲线 Fig.6 Comparison curve of loss between Fig.7 Comparison curve of power training set and validation set generation forecast on sunny days
3.3 实验对比
为研究所采用模型的预测性能, 首先选用晴天和雨天作为两种测试对象, 将Stacking融合模型的预测结果与单层LSTM模型、 多层GRU模型结果以及真实值做对比。
针对预测日为晴天, 从2017年8月24日12时起, 利用以上3组模型对未来35 h的风电场输出功率进行预测, 结果如图7所示。
由图7可看出, 基于Stacking融合模型预测得到的风电场输出功率曲线与真实的输出功率相比较, 曲线变化趋势基本相同。在风电场输出功率比较平缓时, 各个模型的预测效果差别不大, 但当风电场的输出功率变化比较大时, Stacking融合模型的预测曲线更接近真实值。
在预测日为晴天时, 各模型的性能评估指标如表2所示。

表2 晴天Stacking融合模型与其他模型的性能评估指标
在晴天的35 h的预测过程中, 由表2可看出, 单层LSTM的决定系数为0.90, 多层GRU的决定系数为0.97, Stacking融合模型拥有最高的判定系数0.98, Stacking融合模型预测的平均绝对误差相比较单层LSTM模型和多层GRU模型分别降低了2.66和0.90, 均方差指标相比较前两者也分别降低了39.39和12.51, 展示了其有效的风电场短期功率预测能力。
针对预测日为雨天, 从2017年8月7日0时起, 利用3组模型对未来35 h的风电场输出功率进行预测, 预测对比曲线如图8所示。
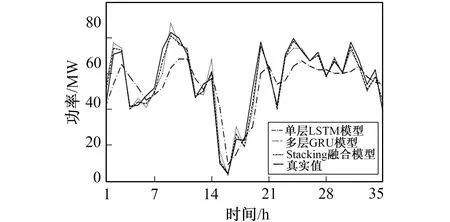
图8 雨天发电功率预测对比曲线Fig.8 Comparison curve of powerforecast in rainy days
雨天的风速等气象条件频繁剧烈变化, 导致风力发电功率剧烈波动产生多个尖峰, 可以看出在风电场输出功率激增时, 多层GRU预测模型和Stacking融合模型表现更好, 这是因为单层的LSTM对风电场历史序列的时序数据特征捕捉能力有限, 而多层的GRU模型的设计提升了时序特征模型的记忆和计算能力。此外因为Stacking集成融合的模型能纠正单个模型的预测偏差, 因此其相比较单一的多层GRU模型预测准确性更高。利用Stacking融合模型与其他模型的性能评估指标如表3所示。

表3 雨天Stacking融合模型与其他模型的性能评估指标
在雨天的35 h的预测中, Stacking融合预测模型的决定系数为0.96,此外, 笔者还将Stacking融合模型与XGBoost模型做了对比。XGBoost模型同样属于集成算法, 其本质是利用Boosting算法集成多个相关联的决策树, 在利用两种算法进行预测时, 选用预测日为2017年8月10日, 从14时起, 预测未来6 h的风电场输出功率变化情况, 预测误差对比曲线如图9所示。

图9 Stacking融合模型与XGBoost模型预测误差对比曲线Fig.9 Comparison curve of prediction error between Stacking fusion model and XGBoost model
由图9可看出, Stacking融合模型的预测误差更小, 性能相比传统的XGBoost集成模型更优秀。
综合上面的几组对比实验可见, 在风电场输出功率比较平缓时, 相比较于传统的XGBoost、 单个单层LSTM模型、 单个多层GRU模型, Stacking融合模型预测精度略好于上述3种预测模型。但当风电场的输出功率剧烈变化时, Stacking融合模型预测效果有明显的提升且稳定性更好。从理论上可分析Stacking融合模型优于其他模型的原因: 首先, 因为Stacking融合模型能有效减小单一预测模型在处理未知样本时泛化性能不佳的现象; 其次, 从模型的训练角度讲, 采用梯度下降法进行训练的神经网络容易收敛到误差曲面的局部最优点, Stacking融合模型通过第2级GRU模型对第1级模型进行结合, 能减少第1级模型中的单个模型优化过程中陷入局部最优点的风险。此外, 笔者采用的Stacking融合模型中第1级的3层GRU模型, 得益于其复杂的记忆网络, 能在更深层次对风电场历史数据进行抽象表达, 促进模型对于高维时间序列特征的捕捉。
为进一步验证Stacking融合模型预测的稳定性, 笔者对该地区风电场八月第1周的输出功率进行预测, 结果如表4所示。

表4 一周内5种模型预测误差统计
与其他预测模型相比, 笔者所提出的Stacking融合模型一周内所预测的平均绝对百分比误差最小, 并且可以看出, 在一周的预测任务中其表现出了稳定的预测能力。
此外, 为测试Stacking融合模型在不同月份预测效果的差异, 笔者选取了8月~12月下旬作为测试集, 进行实验对比分析。表5给出了各个月份的风资源变化情况以及Stacking融合模型预测的平均绝对百分比误差指标。

表5 8月~12月风资源变化及Stacking融合模型的预测误差指标
在5个月的统计中可看出, Stacking融合模型表现出较为出色的预测能力。11月和12月相比较前3个月风速更高, 风电场所发出的功率也明显变多。原因是本地风速具有明显的季节变化特征, 冬春季最大, 秋夏季最小。此外, 由于春冬两季的风功率波动也更为频繁且剧烈, 因此Stacking融合模型的平均绝对百分比误差在11月、 12月的预测误差略微高于前3个月。
4 结 语
笔者借鉴了深度学习领域中的前沿算法和技术, 在深度学习的基础上提出了基于Stacking融合多个不同GRU模型的风电场短期功率预测方法, 第1级中3个多层GRU模型能深度提取风电场历史序列中的特征信息, 因此在风电场输出功率波动比较大时有更好的预测能力, 第2级的GRU模型能纠正第1级模型的预测偏差, 使整个融合模型的预测泛化能力得以增强。笔者以宁夏太阳山风电场为例, 建立Stacking融合模型的短期风电场功率预测模型, 仿真结果表明该模型有更好的预测精度。
猜你喜欢
中学生数理化·八年级物理人教版(2022年6期)2022-06-05
中学生数理化·八年级物理人教版(2022年6期)2022-06-05
中学生数理化·八年级物理人教版(2022年6期)2022-06-05
太阳能(2022年2期)2022-03-07
能源工程(2021年2期)2021-07-21
船舶标准化工程师(2020年1期)2020-06-12
中学生数理化·八年级物理人教版(2019年6期)2019-06-25
电子制作(2018年17期)2018-09-28
通信电源技术(2018年3期)2018-06-26
军民两用技术与产品(2016年3期)2016-01-05
