
基于双模型组合的月度售电量预测分析
2020-08-28 09:04杨晔
中国设备工程 2020年16期
杨晔
(国网江苏省电力有限公司昆山市供电分公司,江苏 昆山 215334)
月度售电量其中含有电力供求双方的各种信息,同时,也是对电网运营和需求侧进行准确预测的基础,能够促进电网的协同运营。为此,需要从偶然和必然两种角度入手,针对月度售电量形成波动问题的驱动因素进行深入解析,进一步明确相关预测应该是非惯性预测和惯性预测的重叠。
1 研究背景
月度售电量作为电力系统运行中供需双方的竞争表征,准确预测月度售电量,能够促进电力需求侧管理工作的全面优化,同时,还能够进一步提高供电企业营销、生产以及基建等多种环节的工作质量,但按照历年来不同地区月度售电量相关大户数据的分析结果发现,研究对象变化呈现出一种非线性特征,整体层面上十分复杂,证明其会被多种不同性质因素进行协同驱动。
月度售电量中的不同类型预测技术有其不同的适用范围和侧重点,而以单一模型为基础的预测方法无法准确全面总结概括不同时段和不同区域的特性需求,比如,某一模型应用到甲供电企业中能够起到有效的作用,但应用到乙企业中却无法发挥成效。模型在这一时段内有效,但却无法保证在下一时段内的有效性。本文就此针对月度售电量提出了一种全新的预测思路,从不确定性和确定性两种角度入手,针对使售电量出现变化的内驱动力进行详细分析,随后,以县级供电企业中的应用关切和数据采集实际状况入手,分别选择其中具有突出代表性的模型预测偶然分量和必然分量,最后,按照组合预测思路,全面整合两种单一模型,从而为了使综合误差达到最小化标准。如此便可以有效优化月度售电量相关预测工作。
2 创建预测体系
县级供电企业中的常见态势如下,引入先进的自动化调度技术,从电网数据采集层面得到明显提高,但系统外部各种和售电量变化的相关数据信息要想实现足量获取存在较大难度。随着电力技术持续更新和国民经济的发展,相关配网规模也持续扩大,整个结构越加复杂化,从而导致大量模糊因素的积累。第一种态势证明县级电网于大数据短缺消除中依然需要进行继续创新改革,为此针对月度售电量进行预测过程中,不可避免会应用那些对数据要求较小的模型。第二种态势证明针对月度售电量进行预测建模过程中,应该针对待测区域内真实状况实施统筹思考。
除此之外,结合驱动因素进行分析,发现售电量变迁主要是被惯性支配,同时,还会受到不同地区内产业、人口和经济因素的影响,属于一种偶然性范畴。其中,需要特殊说明的是,月度平均气温变化和月度售电量存在一定联系,但此次研究中便不结合该点内容进行考虑。主要原因如下:通过分析理念关于气候变化的大数据发现,每年相同月份相关气温会形成一定的变化浮动,但整体变化并非十分明显,由此来看,随着时间跨度持续加大,能够有效降低单日气温变化影响。同时,气温对月度售电量影响主要是从空调负荷中体现出来,在新时期经济发展背景下,保持一种稳定、健康的发展状态,大部分区域中空调负荷都处于一种惯性上扬趋势,人们行为会被惯性思维所影响,为了追求舒适生活而应用空调是一种必然惯性因子。综上所述,结合预测选型要求,设计电量预测体系框架如图1所示。
上述LOGISITC模型能够代表月度售电量按照惯性趋势的发展状况,同时,相关模型也比较适用于贫信息场景下相关预测工作,仅需要一些简单历史数据即可。层次分析加模糊聚类模型,能够充分显示出待测空间中的独特实情,证明月度售电量相关发展状况呈现出一种非惯性趋势,同时,结合最小二乘法,能够确保两种模型按照最优权重开展全面组合,促进预测精确度的全面优化。
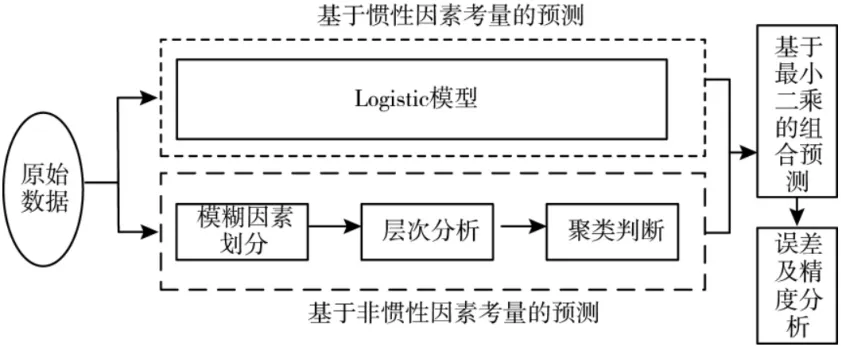
图1 电网月度售电量相关预测模型
3 不同区域建模
(1)LOGISTIC模型。辖区内固定区域电网中,因为电力应用中的惯性思维推力影响,即便是在没有各种外加条件情况下,逐年月度售电量将会呈现出一种S形的变化趋势。而S形曲线和人们所预测的LOGISTIC模型较为相似,所以通过其当成一种惯性预测分析模型较为适合。对于此次而言,由于预测目标是月度售电量,所以需要逐月创建预测公示。举例说明,结合预测需求,将其中某一年当成待预测年,比如,2021年,从之前连续数年的1月月度售电量作为主要参考依据,数量在10~20个左右为宜。随后,将历史月度售电量数据作为基础,结合MATLAB软件内的NLINFIT函数作为非线性回归,如此便能够得到一种未知系数值,从而形成各项系数预测公式,如果想预测2020年,则只需将相关数据代入其中即可。
(2)模糊聚类建模。当下新常态是整个经济大环境的主要特征,基于该种背景下,大部分地区中的月度售电量也呈现出波动增长状态,并非是单边上扬形式,而该种波动和地域空间布局、产业配置以及人口特征等密切相关。产业、布局和人口等涵盖城镇化实施中的核心内容,下面包括各种干分级要素,不同地区在该方面存在一定差异。为此需要针对相关要素实施提炼,并以层次分析法为基础,融合专家经验,获得各要素在月度售电量影响方面的权重配置,引入模糊聚类,针对权重处理结束后的样本数据实施聚类比较,得到预测数值,上述内容便是结合非惯性因素形成的预测思路。以某个县城为例,对城市要素体系进行全面整理提炼,形成一种基础思路,勾画出以模糊聚类和层次分析等方法为基础的售电量预测流程。
(3)最小二乘法应用。文中所介绍的两种模型都有其不同考量和侧重点,其应用劣势和优势也各不相同,为此需要取长补短,不能随意偏废,针对两种模型组合系数进行考量时,需要将两种模型预测误差减到最少,至于最小二乘法也比较符合该种期望。通过分析实际发展状况,需要先针对单一模型实施验证性预测,获得预测偏差序列。通过未知数方法,设定两种单一模型于不同月份内组合系数。把偏差矩阵和系数向量有效融入到最小二乘法内,使合成偏差最低系数向量求解出来。
4 案例分析
(1)历史样本分析。以某一供电企业从2010~2018年的月度售电量历史数据作为基础样本,并对相关数据开展初步观察分析,能够了解到以下内容:第一,是立足于整体角度分析,不同年份、同一月份中的月度售电量变化趋势呈现出一种扁平S形式,证明LOGISTICS相关模型吸纳存在一定合理性。第二,是从细微角度入手进行准确辨识,其中,大量月份是不存在逐年波动性的,鉴于层次分析以及模糊聚类模型也存在一定有用之处。
(2)单一模型预测。通过LOGISTIC模型针对研究阶段中的数据信息实施验证性预测,了解相应的误差状况。通过分析发现,因为模型能够将事物惯性变迁准确揭示出来,同时,相关售电量变化也在较大程度上满足惯性原则,为此相关预测工作从总体层面没有偏离事物轨迹。模型因为属于一种贫信息预测,针对产业、人口以及经济等影响因素都无须考量,为此一定会产生预测偏差过大的问题,某些月份超出了4%的对标指标,由此能够看出,需要借助其他模型进行辅助判断。依托层次分析和模糊剧烈模型开展验证性判断,因为篇幅限制,此次仅展示2018年11月的结果。通过分析历年相似度聚类分析结果能够发现,2014、2016和2018聚类水平低于0.92,归属一类,为此开业计算2018年11月手月度售电量和11年5月相比,有所增长,并对2018年11月的月度售电量增长状况进行准确估测。最终结果如表1所示。

表1 预测结果分析
通过分析上表能够发现,模糊聚类加上层次分析这种预测方法有效融入专家知识,能够清晰表达多模糊因素,提高月度售电量相关预测准确度。
(3)双模型组合预测。通过两种单一模型针对2011~2018年实施按月预测验证后,以最小二乘法为基础,计算组合模型内不同模型相关权重系数,并创建逐月组合模型。因为前面所说的验证性预测到2018年年末截止,结合近大远小的基础原则,最新创建而成的组合模型和2019年预测最为契合。通过分析最新组合模型对2019月度售电量进行预测,结果发现,组合预测模型在实际应用中,相关预测准确性得到了明显提升,同时,和单一模型比较,相关预测成效也十分稳定。
5 结语
综上所述,此次尝试以最小二乘法拟合而成的双模型组合为主进行准确预测,相关案例结果证明,层次分析模糊聚类加上LOGISTIC模型,能够对电量销售中的各种偶然性因子和必然性因子产生统筹影响。为了进一步提升预测准确性,应该结合气温因子进行综合考量。
猜你喜欢
中学生数理化·八年级物理人教版(2022年3期)2022-03-16
中学生数理化·八年级物理人教版(2021年3期)2021-07-22
铁道通信信号(2019年6期)2019-10-08
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
现代计算机(2016年17期)2016-02-28
中国记者(2015年8期)2015-05-09
中学生数理化·八年级物理人教版(2014年1期)2015-01-09
中国记者(2014年4期)2014-05-14
中学生数理化·八年级物理人教版(2014年2期)2014-04-02
