
网站资源信息自动采集技术
2020-08-25 00:51马浩铭
湖北农机化 2020年12期
马浩铭
(新疆质信通工程检测技术有限公司,新疆 乌鲁木齐 830011)
1 信息采集器
1.1 Index程序的参数设置
-n number 索引指定数目的文档后退出。注意:在运行index-n number后,运行index-D程序。如果用户使用多线程,索引的文档数目会比预定的值高一些。
-N number 设置运行索引线程的数量。只有对多个网站进行索引时,多线程索引才有意义。两个线程或多个线程不能同时对同一站点进行索引。
-R number 运行解析进程的数目。默认是线程数/5+1。如果用户的服务器解析慢的时候,用户需要增加默认值。
1.2 重新索引控制参数设置
-a 重新索引所有的文档,并忽略文档的失效状态。默认情况下,只有比Period时间早的文档才被重新索引。
-m 存储文档中词和超链接,忽略文档的修改状态。没有这个参数时,只有修改的文档才会被重新索引。
-o 优先抓深度浅的文档。这里的跳跃指的是文档的深度值。
-M继续索引先前索引任务的URLs。这些URLs会被存储在临时MySQL数据库中,这常用于调试目的。
1.3 实时数据库索引选项
-T URL索引URL到实时数据库中,需要注意的是,用户不能增加太多的文档到实时数据库中,否则检索实时数据库会非常地慢。实际上实时数据库文档的限制是依赖于硬件的,大约1000个urls,效果会比较好。实时数据库的文档归并到主数据库的命令是index-D。这个参数选项在重新索引经常需要改变的网页时候非常有用。用户可以及时地看到结果,用户可以使用-A参数一起使用。
1.4 清理数据库
-C清理数据库。用户可以控制参数来限制清理数据库的范围。注意:清理规模较大的数据库的速度会很慢。从文件中读取将要被索引、插入、清除的URLs。用户使用-做文件名,则URL列表将从标准输入进行读取。另外,指定抓取的网页需明确。
1.5 输出
-r file重定位信息输出到指定file。
-g file设置index程序的统计信息的日志文件。
1.6 停止index程序
-E安全地停止已经运行的index程序。
2 守护进程模块
Searchd是一个搜索守护进程,自动采集器利用这个守护进程,搜索index程序创建的数据库,缓存搜索结果等。它主要是监听s.cgi查询的端口,执行搜索指令并返回s.cgi查询的结果。Searchd为了加速搜索的速度——从数据库一些数据加载到内存。如果硬盘的数据改变,Searchd程序会重新加载。
2.1 基本命令参数
-D 运行searchd程序作为守护进程。用户每次运行searchd,都需要使用这个参数。
-R 在searchd失败的时候,能够自动重新启动searchd守护进程。如果用户使用这个选项,搜索引擎将不会停止。
-l logfile设置searchd将日志写入日志文件中。
2.2 错误日志
如果在启动searchd的时候,端口被其他程序占用,用户不能从控制台获得错误信息,只能从日志文件中获取,所以,在每次启动searchd程序的时候,首先要检查是否有其他程序占有该端口号,或者在searchd程序启动后,检查日志文件。
3 主要技术指标及软硬件环境
采用面向对象的设计思路,可以运行在常用的32位或64位Linux操作系统上,后台数据库采用MySQL 5.1,支持GBK、BIG5、UTF8、UNICODE等多种编码格式,可以定制采集网址、栏目,支持分页采集与网页内容动态采集。
后台数据库名为searchDB,库中的表名、字段名主要都是参照相应的英文名称命名的,如:wordurl表示“关键词所对应的url表”。管理数据库可以使用命令行工具管理MySQL数据库(命令mysql和 mysqladmin),也可以从MySQL的网站下载图形管理工具MySQL Administrator和MySQL Query Browser,也可以采用更方便操作的phpMyAdmin通过Web界面管理后台数据库。软件安装所需的具体硬件环境和软件支持要求如下:
3.1 硬件环境(表1)
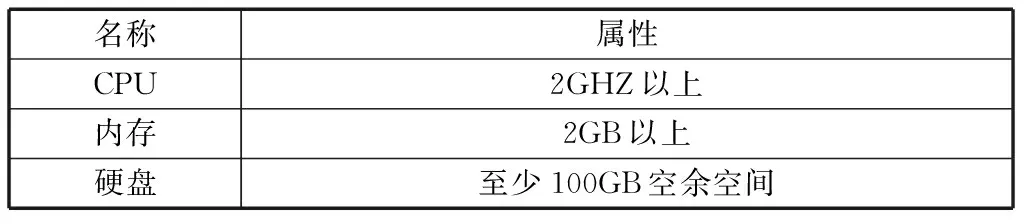
表1 硬件环境最低要求
3.2 软件环境(表2)
4 结语
笔者重点介绍了网站资源信息自动采集功能模块的相关技术,该采集器可做到在指定url种子中的相关栏目信息更新后,执行采集器采集信息时只采集最新的栏目,不重复采集,且采集过来的内容比较完整,只需简单调整一下字体格式便可快速发布,简单实用。该功能在本公司上线投入运行以来,给网站发布人员工作带来了极大的便利,取得了令人满意的应用效果。
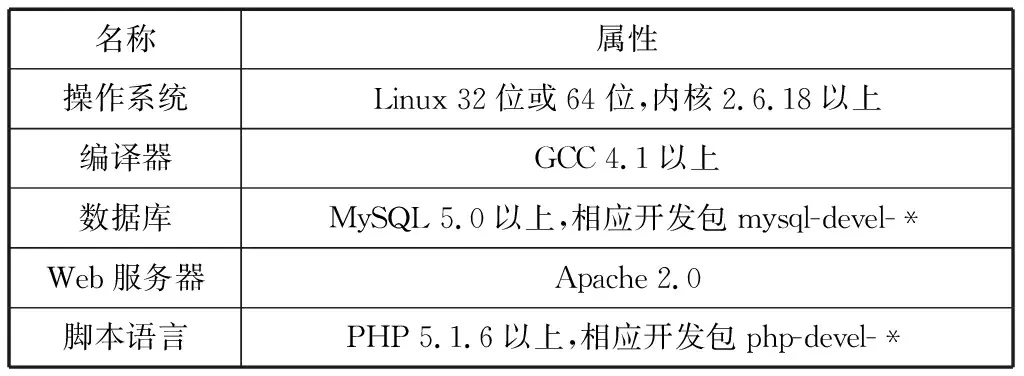
表2 软件环境要求
猜你喜欢
现代电子技术(2022年8期)2022-04-13
轻工机械(2022年1期)2022-03-23
华人时刊(2021年13期)2021-11-27
现代仪器与医疗(2021年1期)2021-06-09
陕西科技大学学报(2020年5期)2020-10-12
心声歌刊(2020年4期)2020-09-07
网络安全技术与应用(2020年1期)2020-01-07
思维与智慧·上半月(2018年10期)2018-11-30
思维与智慧·上半月(2018年9期)2018-09-22
计算机测量与控制(2017年12期)2018-01-05
