
EdgeMI:资源受限条件下深度学习多设备协同推理
2020-08-21 01:01薛峰方维维
现代计算机 2020年20期
薛峰,方维维
(北京交通大学计算机与信息技术学院,北京100044)
0 引言
深度神经网络(Deep Neural Networks,DNN)在诸多工业领域中取得了突破性的成就,如语音识别、图像检测与自动驾驶等[1-2],但是DNN 计算需要消耗大量的算力和存储空间。基于云计算的解决方案不仅会导致过高的通信延迟和极高的带宽成本,而且可能会引起对隐私泄漏的极大关注。同时,物联网设备快速增加,由此产生的数据大爆炸现象不能仅依靠云计算方案解决[3-4]。
为了应对这些挑战,研究人员提出边缘计算[5],它指的是在靠近物联网设备和数据源的网络边缘提供计算服务。与传统的云计算解决方案相比,边缘计算的优点包括低延迟、高能效、带宽减少和增强隐私。然而边缘设备在计算、存储、通信和能源等资源方面受到限制,因此无法提供良好的硬件支持,使得边缘设备无法进行DNN 模型计算或者计算缓慢[6]。
本文提出了EdgeMI,一种根据边缘设备计算能力和网络带宽进行自适应的DNN 多设备推理框架,实验结果表明,与文献[7]工作相比,EdgeMI 在受限的边缘环境下可以取得更好的效果。从以下两个方面总结我们工作的贡献:①提出了一种基于边缘设备计算能力和网络带宽的卷积层划分方案,使用时间预估模型预估卷积层和全连接层的计算时间和通信时间,精确划分计算任务,均衡设备负载,加快多设备推理;②提出了一种边缘多设备数据调度方案,减少边缘设备间的数据交换,降低数据传输时间,进一步提高多设备推理性能。
1 相关工作
DNN 模型通常由卷积层和全连接层组成,例如VGG16、AlexNet 和ResNet,卷积层参数较少,但是会消耗86.5%-97.8%的算力,全连接层参数多并占据87.1%的存储空间[7]。以VGG16 为例[8],共有参数138M,模型存储527MB,单图像计算需要15.5G 浮点计算(Floating-Point Operations Per Second,FLOPS)[9]。边缘设备推理时,VGG16 每层的计算耗时、通信耗时均不同,如图1所示。

图1 VGG16网络层计算时间和通信时间
针对边缘环境设备算力和存储等资源难以满足DNN 模型计算需求的问题,研究人员进行了大量的研究,主要分为以下两个方面:DNN 模型压缩和多设备协同处理技术。
模型压缩研究大致归类为网络剪枝、知识蒸馏、低秩分解和紧凑卷积核设计[10-11]。网络剪枝探索DNN 模型冗余参数,试图去除不重要和冗余的权重,Han 等人[12-13]提出了一种基于权重的剪枝方法,先剪枝再微调训练恢复推理精度,通过训练量化和Huffman编码来增强剪枝,将原始网络压缩为轻量级神经网络,然而,这些非结构化剪枝方法产生了稀疏权重矩阵,没有专用的硬件和软件库难以运行。Hinton 等人[14]提出知识蒸馏简化网络,但知识蒸馏技术仅对图像分类任务有着良好的效果,图像检测和识别效果一般[15]。
多设备协同处理技术分为边-云协同和本地多设备协同,Teerapittayanon 等人[16]提出网络边缘端-云端协同的方式,将计算任务切割、划分到边缘端和云端,有效避免边缘端设备计算能力低下的问题;Kang 等人[17]提出一个轻量级的调度器Neurosurgeon,采用层级计算划分DNN 策略,适应各种DNN 模型和硬件平台,在延迟和能量方面可取得良好的效果;Li 等人[18]提出早期退出技术[19]和边缘-云端结合的方式,在推理时间受限的条件下,完成计算任务,边-云协同非常依赖云端计算能力,中间传输不可靠,数据易泄露隐私无法得到保障。Mao 提出MeDNN[20]和MoDNN[7],基于设备算力的计算任务划分方案BODP,在各边缘设备算力接近且网络带宽良好的条件下,BODP 有效提高了边缘集群计算速度,但是忽略了设备的异构性和网络状态的差异性;Zhao 等人[21]提出一种用于自适应分布的框架Deep⁃Things,在严格资源约束的物联网边缘簇上执行DNN推理,使用Fused Tile Partitioning(FTP)划分方案,方块划分方案复杂,设备间数据频率交互偏高。模型压缩技术与多设备协同处理技术是相互正交的,可混合使用多方面加速DNN 推理。
2 EdgeMI框架介绍
在该部分,我们将介绍EdgeMI 框架和原理,框架如图2 所示,由三部分组成,①边缘计算集群;②卷积层划分方案;③边缘集群调度策略。
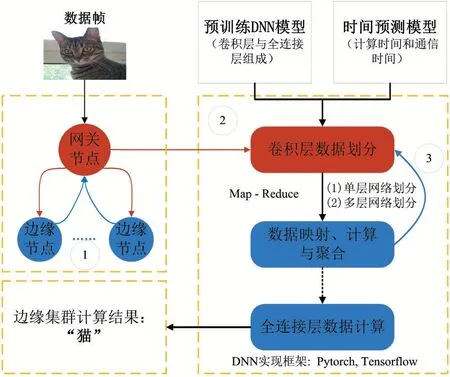
图2 EdgeMI框架
后续将介绍EdgeMI 框架、算法描述和实验结果等,表定义常用变量以及介绍变量的含义。
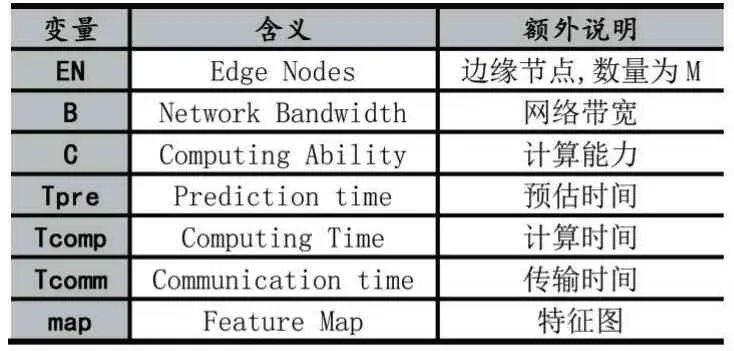
表1 变量定义及说明
2.1 时间预估模型
卷积层运算时间与FLOPs 具有相关性,通过计算FLOPs 可预估卷积层计算时间。文献[9]介绍了卷积计算和全连接层矩阵计算的FLOPs 的,公式(1)定义卷积运算浮点计算量,假设特征图map 进行卷积运算,H 表示map 的高度,W 表示map 的宽度,Cin表示卷积计算的输入通道个数,Cout表示卷积运算的输出通道个数,K表示卷积核的大小。公式(2)定义全连接层矩阵运算的FLOPs,其中I 表示全连接层的输入维数,O 表示全连接层的输出维数。

假设FLOPs 与计算时间逻辑回归模型如公式(3)所示,y 表示计算时间,a 表示设备计算能力,x 表示FLOPs,b 表示卷积计算固有时间开销。如何求得该逻辑回归模型?设置不同大小的特征图H*W(H 与W 不一定相等),在边缘设备上进行卷积运算,多次计算求平均值。记录FLOPs 与计算时间,使用最小二乘法求得回归方程。在卷积运算和全连接层运算前,根据已知的输入、输出等参数计算FLOPs,根据边缘设备的FLOPs 计算时间回归方程可预估卷积计算时间。

通信开销Tcomm=D/B,D 表示传输数据的大小,B表示网络带宽,分为发送数据通信开销和接受数据通信开销。
2.2 卷积层划分方案
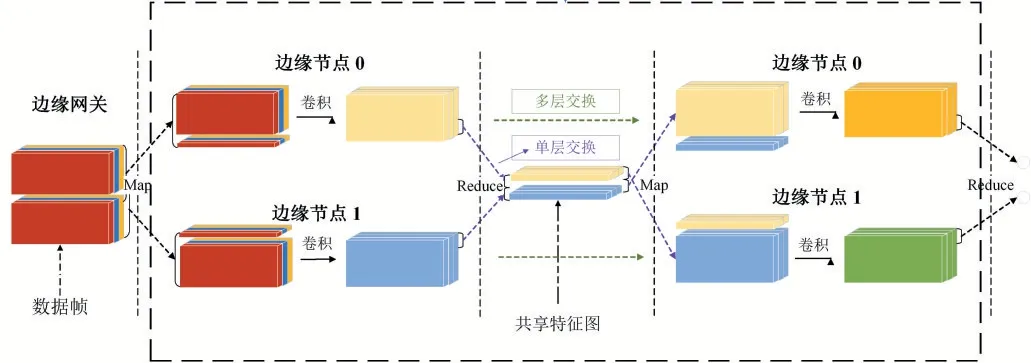
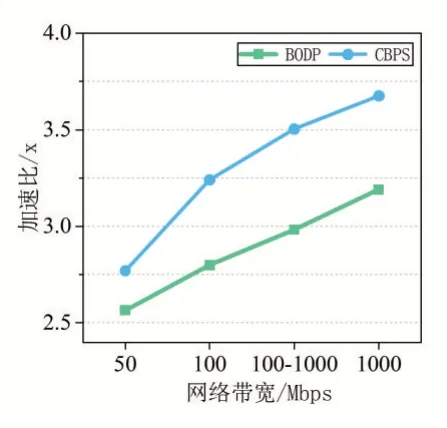
传统的卷积层划分方案通常保持层输入的结构对称性,划分为二维网格形式,但是该方法导致设备间数据依赖较多,并不适合网络边缘环境。文献[7]提出的基于算力的划分方式BODP,各边缘设备间重叠数据较少,有利于降低边缘设备间的交换频率,减少通信时间。本文提出了基于设备算力与网络带宽的划分方式CBPS(Computation-Bandwidth Partitioning Scheme),降低边缘节点的空闲等待时间。

图3 卷积层划分方案
假设边缘集群有M 个节点,编号依次为0,1,2,…,M-1,i 表示第i 个边缘节点,其算力为Ci,网络带宽为Bi。Ctotal表示所有边缘节点的算力之和,边缘集群按照算力初始化划分长度,划分依据为ENi的算力所占总算力的比例,边缘节点i 所分配的长度leni,如公式(5)所示,其中W 表示特征图map 的宽度。

划分长度初始化完成后,使用时间预估模型预测边缘节点的耗时Tpre,包括计算时间Tcomp和通信时间Tcomm,如公式(6)所示,Tcomp值大小与节点的算力等因素有关,根据之前提到的公式(3)预估计算时间,Tcomm值大小与网络带宽和数据量大小有关,分为发送数据耗时和接受数据耗时,如公式(8)所示。
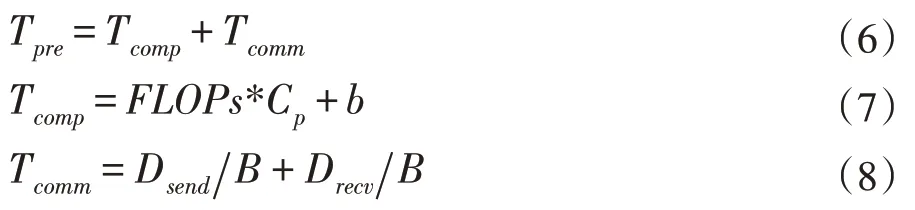
为了使得每层卷积运算的速度最快,耗时最小,即最小化边缘集群中max(Tpre),优化步骤为:①根据划分范围和时间预估模型,计算出边缘集群预计耗时{Tpre},找出{Tpre}中最大值max 与最小值min;②调整步长为Wstep,即最大值max 对应的划分长度减Wstep,最小值min 对应的划分长度加Wstep,重新计算边缘集群的{Tpre};③判断终止条件:最大值Tmax与最小值Tmin差值是否小于Ttolerate,若符合终止条件,则停止迭代求解,否则继续步骤(1)。整个过程如算法1 描述。
Algorithm 1 卷积层划分方案
输入:神经网络特征图map,大小为H*W,H 表示特征图map 的高度,W 表示宽度,M 台边缘节点ENs,计算能力Ci,网络带宽Bi,(i=0,1,…,M-1),迭代步长为Wstep
初始化:根据边缘节点ENi的算力Ci,根据公式()初始化划分长度,并存储在len[]中
1:Procedure INT PARTITION(M)
2:使用时间预测模型预测边缘节点i 的总耗时
3:计算边缘节点的FLOPs=2H*leni(CinK2+1)Cout,得到Tcomp和Tcomm,对于每个边缘节点:
4:找出预计时间的极值
5:计算差值Tdiff=Tmax-Tmin
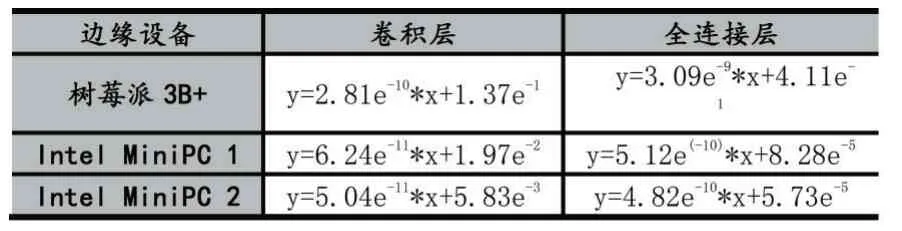
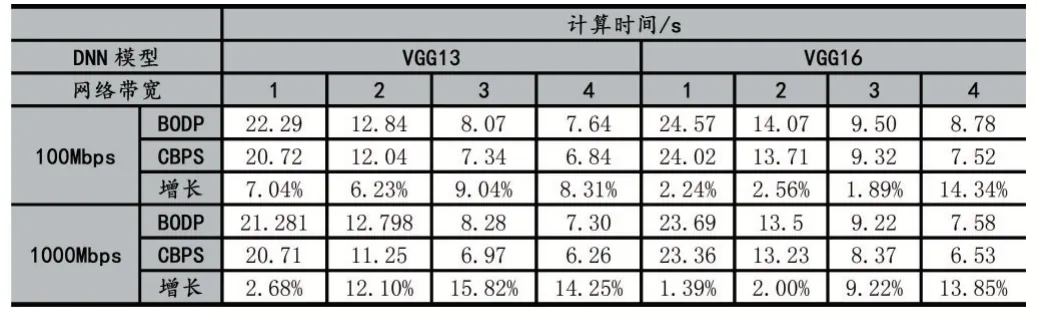
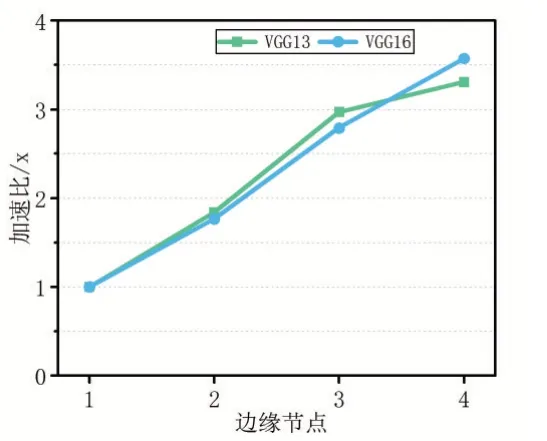
6:IfTdiff 7: 结束迭代求解过程,返回len[] 8:else: 9:lenarg(max)=max-Wstep 10:lenarg(max)=max-Wstep 11: 回到步骤(2)继续计算 12:输出:卷积层划分结果len[] 之前我们探讨了基于算力和网络带宽的卷积层划分方案CBPS,调度策略总体按照Map-Reduce 方式。边缘网关对卷积层数据划分后,根据划分映射依次发送至边缘节点进行计算,待计算任务完成后,由边缘网关聚合各节点的计算结果,整个过程我们称为数据调度,根据边缘网关与边缘节点EN 间的数据交换频率分为两种调度策略:单层交换和多层交换。如图4 所示,单层交换策略即边缘节点每层卷积运算均会与边缘网关交换数据;多层交换即边缘节点进行多层卷积运算后才会与边缘网关交换数据。 特征图的卷积结果不仅与输入特征图相同位置的数据相关,而且与该区域四周的数据相关,具体外扩范围的确定与卷积核大小相关, 图4 单层交换与多层交换策略对比 单层交换策略中,边缘节点ENi的划分范围[indexstart,indexend]一般情况表示为公式9,当i=0 时,令indexstart=0;当i=M-1时,令indexend=W-1。 多层交换策略中,假设经过a 层卷积运算后边缘节点与边缘网关数据交换,划分范围一般表示为公式10,当i=0 时,indexstart=0;当i=M-1时,indexend=W-1。 EdgeMI 采用的深度学习开发框架为PyTorch 1.3,通信协议为TCP/IP,编程语言为Python 3.6.9。DNN 模型类型有VGG13 和VGG16。边缘设备采用树莓派3B+,Intel MiniPC CPU 800MHz、900MHz,使用Wondershaper 设置边缘节点网络带宽,带宽范围:50-1000Mbps。 表2 边缘设备算力-FLOPs 回归模型 我们采用不同的边缘设备作为实验平台,并设置不同宽度与高度的特征图map,5 次计算取平均值,以降低偶然误差,利用最小二乘法求得回归方程。各边缘设备算力回归模型如表2 所示,其中算力回归直线的斜率越低,表示该边缘节点的计算能力越强,同样的FLOPs,计算耗时更少,回归方程与Y 轴的截距为正值,表示边缘设备在卷积计算过程中的固有时间开销。根据回归模型求得的卷积计算和全连接层矩阵预估时间,与实际计算时间有一定的误差。表2 中同一边缘设备,卷积层和全连接层的算力回归模型斜率不同,即卷积层和全连接层计算相同的FLOPs 耗时不同,是由于边缘设备内存不足导致与swap 分区数据交换,交卷积运算与全连接层运算的swap 分区交换频率导致回归模型斜率的不同。 利用边缘设备的算力值初始化卷积层划分长度,根据步长迭代优化求解,最小化计算时间。DNN 模型选择VGG13 与VGG16,边缘节点数量设置为4。本文所提划分方案和文献[9]划分方案BODP 两种划分进行对比实验,(1)在理想网络带宽条件下,设置网络带宽均为1000Mbps;(2)在较差网络带宽条件下,设置网络带宽为100Mbps。实验结果表3 所示。同一DNN 模型,本文所提卷积层划分方案CBPS 在良好网络状态稍优于BODP 方案,但是在较差网络状态下的CBPS 性能明显高于BODP,最高达到14.34%。在图5 中,不同网络带宽条件下,CBPS 加速比均高于BODP,加速比最高为3.57x。BODP 方案仅依据算力进行卷积层长度划分,当某个边缘节点网络状态较差,易导致边缘网关长时间等待该边缘节点返回的计算结果,使得其他已完成计算任务的边缘节点处于空闲等待状态,造成总体计算时间的上升。CBPS 利用网络状态,重新调整划分长度,使得边缘网关在相近的时间内收到边缘节点返回的计算结果,边缘网关空闲等待时间越短,边缘集群的计算速度越快。 表3 BODP 与CBPS 性能对比 图5 CBPS与BODP加速比对比 图6 单层交换与多层交换策略性能对比 单层交换和多层交换两种调度策略,单层交换策略设定,即在卷积运算后边缘节点间进行数据交换;多层交换策略设定,在多次卷积运算后池化层前边缘节点间进行数据交换。边缘节点数量设置为4,DNN 模型选择VGG13 和VGG16。网络带宽设置为1000mbps。实验结果如图6 所示,相同调度策略VGG16 的计算耗时明显高于VGG13;相同DNN 模型,多层交换策略时间低于单层交换策略。单层交换策略总体耗时由单层计算耗时和单层通信耗时组成,多层交换策略总体耗时由多层计算耗时和单层通信耗时组成,多层交换策略的计算耗时稍高于单层交换策略的计算耗时,但是同一网络状态下,后者的通信耗时明显低于前者的通信耗时,导致多层交换策略的加速比高于单层交换策略,调度策略的关键就是减少边缘节点间的数据交换频率,提高数据利用效率,最终达到边缘集群的加速。 边缘节点为2 台时,单节点平均内存减少49.11%;边缘节点为4 台时,单节点平均内存减少73.67%。边缘集群中边缘节点数量对计算时间的影响如图7 所示,VGG13 与VGG16 两个DNN 模型,随着边缘节点数量的增加,加速比逐渐增加,但是增加速率总体是降低的,边缘节点为2 台时,加速为1.84x;边缘节点为4 台时,加速比最大为3.58x。加速比的非线性增加是由于边缘节点增多,节点间数据交互增多,通信时间增加导致加速比增加速率下降。 图7 边缘节点数量对加速比的影响 本文提出了一种在边缘资源受限条件下多设备协同推理框架EdgeMI,以提高DNN 模型在边缘集群上的推理性能。主要研究点集中在卷积层分布式协同计算,提出时间预估模型预计计算和通信时间;提出基于设备算力和网络状态的划分方案CBPS,边缘集群自适应推理,降低内存占用73.67%;提出单层交换和多层交换两种调度策略,提高划分区间的重叠数据利用效率,降低边缘节点通信负载,加快边缘集群的推理速度1.84x-3.57x。未来的研究工作,将深入探讨边缘异构设备具有硬件加速功能条件下多设备协同推理问题,以及DNN 全连接层多设备协同推理问题。2.3 调度策略
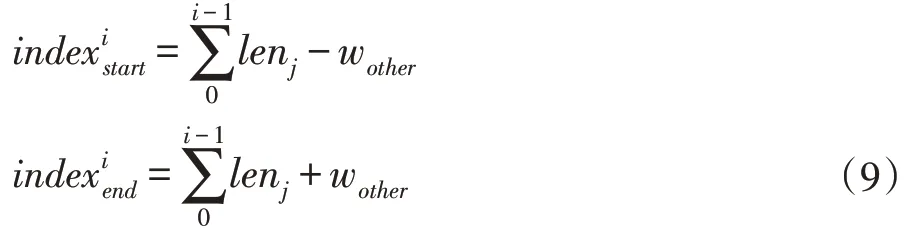
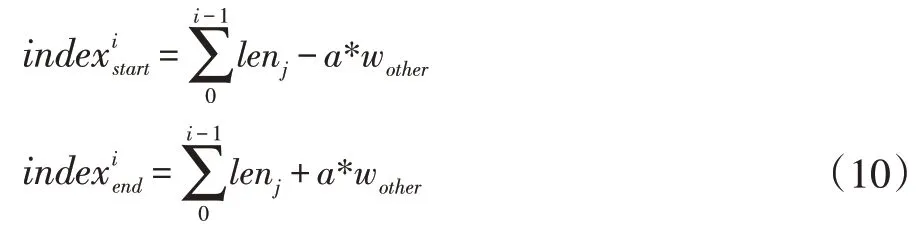
3 实验和评估
3.1 时间预测模型
3.2 卷积层划分策略CBPS

3.3 调度策略
3.4 边缘节点数量
4 结语
猜你喜欢
现代经济信息(2022年22期)2022-11-13
分子催化(2022年1期)2022-11-02
南京航空航天大学学报(2022年4期)2022-08-30
计算机应用(2022年6期)2022-07-05
科学大观园(2022年6期)2022-04-21
软件和集成电路(2019年9期)2019-11-29
中国建筑金属结构(2018年4期)2018-05-23
通信产业报(2016年44期)2017-03-13
雕塑(1999年2期)1999-06-28
雕塑(1996年2期)1996-07-13
