
改进的YOLOv3网络在钢板表面缺陷检测研究
2020-08-19 10:42:30朱洪锦范洪辉周红燕余光辉
计算机工程与应用 2020年16期
徐 镪,朱洪锦,范洪辉,周红燕,余光辉
1.江苏理工学院 机械工程学院,江苏 常州 213001
2.江苏理工学院 计算机工程学院,江苏 常州 213001
1 引言
随着工业技术的发展,自动化缺陷检测的研究越来越受到人们的重视。当钢板或零件表面存在一些瑕疵和缺陷,如磨损、裂纹、碰伤、麻点、划伤和变形等,将会导致机器使用过程中产生不正常的振动和噪声,加快缺陷面与空气接触后进一步的氧化与磨损,严重时甚至会引起机器的损坏和一些事故性的人员伤亡情况。而传统的人工裸眼检测,存在劳动强度大、工作效率低、产品成本较高的问题,且容易受到检测人员在员工素质、检测经验、肉眼分辨率和眼部易疲劳等诸多因素影响[1]。因此,许多人提出了各种检测表面缺陷的方法,具体可以分为两类:传统机器视觉检测法和深度学习检测法。
传统机器视觉检测法是先利用工业相机采集图像,经过传统图像方法处理后,再利用机器学习方法得到想要的结果。例如郭慧等人[2]提出了由计算机算法处理得到缺陷的特征样本,再利用支持向量机(SVM)模型对钢板表面缺陷进行类型识别。例如汪以歆等人[3]利用基于机器视觉的比对检测算法,来检测物体表面缺陷。这些方法的优点是速度快,对特定缺陷精度高,但受光照和人为影响较大,对图片特征提取能力弱,应用面小。
近年来,国家鼓励大力发展人工智能技术,深度学习的一系列方法也被引入到表面缺陷检测中。深度学习能够通过卷积神经网络提取缺陷图片的特征并进行学习,再将学习后的模型应用到相似缺陷的检测中,精度高,速度快,且能够适应不同类型的缺陷。比较流行的深度学习算法可以分为两类:一类是Faster-RCNN[4]、Mask-RCNN[5]等基于区域的目标检测算法,这类算法虽然精度高,但由于其将缺陷特征提取、缺陷区域建议网络、缺陷边界框回归和缺陷分类整合在一个网络中,导致速度很慢,实时性不能保证。另一类是SSD[6]、YOLO[7]等利用回归思想直接标出目标所在图片位置和类别的算法,这类算法很大程度上弥补了基于区域的算法,在速度上有很大的提升,精度上略微降低,有很大的应用前景。例如张广世等人[8]采用密集连接网络(DenseNet)结构代替原有的网络结构,提高特征提取能力,取得了不错的缺陷检测能力。
本文也将使用深度学习的方法对钢板表面缺陷进行检测,对YOLOv3[9]整体网络进行改进,使用轻量级MobileNet[10]网络代替原有模型中的Darknet-53网络,以减小网络参数量;构建齿轮缺陷数据集并进行数据增强以防止过拟合;加入空洞卷积来提高对于小尺寸缺陷的检测能力;利用Inceptionv3[11]结构增加网络深度和宽度的同时减少参数。本文整体结构分为以下四大部分:网络原理介绍,网络结构改进,实验结果分析和改进讨论。
2 YOLOv3网络原理介绍
YOLOv3[9]是基于 YOLO[7]和 YOLOv2[12]算法 改 进而来。
YOLO网络不同于Faster-RCNN[4]等网络,而是将目标检测问题转化成逻辑回归问题,将图像分割成不同网格,每个网格负责相应的物体,使得支持多标签对象在保持精度下,检测速度更快。
YOLOv3 采用了Darknet-53 的网络结构作为图像特征提取主干网络,它是借鉴残差网络ResNe(tResidual Network)[13]的做法,在层与层之间设置快捷链路,适当地跳过卷积,解决了在逐步加深网络时出现模型难以优化的问题,这样可以提取出更多图像上的特征。YOLOv3摒弃了YOLOv2采用pass-through结构来检测细粒度特征,而使用特征金字塔(FPN)的多尺度检测方法,结合残差网络将图片转化成三个不同尺度的特征图来检测大中小三类物体。YOLOv3的网络结构如图1所示。
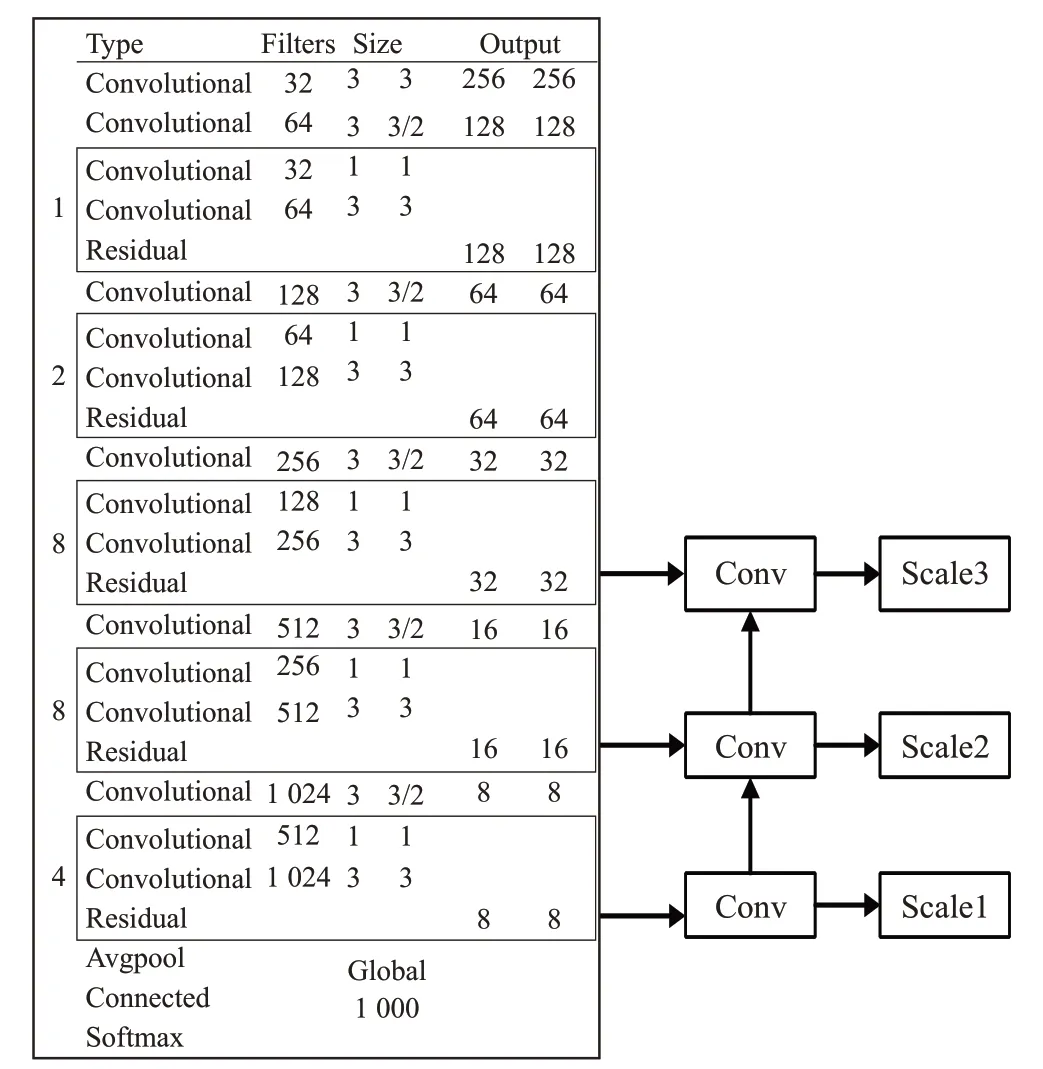
图1 YOLOv3网络结构图
由于越卷积图像表征信息丢失越多,YOLOv3吸取了YOLOv2采用K-means聚类得到先验框的尺寸,为每种下采样尺度设定3 种先验框,总共聚类出9 种尺寸的先验框,分别为(10×13),(16×30),(33×23),(30×61),(62×45),(59×119),(116×90),(156×198),(373×326)。在最小的13×13特征图Scale1上应用(116×90),(156×198),(373×326)检测较大的物体。在中等26×26特征图Scale2 上应用中等的先验框(30×61),(62×45),(59×119)来检测中等大小的对象。而在最大的52×52特征图Scale3上采用(10×13),(16×30),(33×23)检测较小的物体位置。
3 网络的改进
为了使网络在减小网络参数的同时保持精度,并提升实时性,对原网络做了以下调整,主要包括三点修改。
3.1 加入各类版本的MobileNet网络
由于YOLOv3 仿照ResNet-53 结构提出Darknet-53网络,虽然可以提取有效的特征信息,但该网络结构复杂,导致参数过于复杂,从而在实用性上并不理想。因此利用MobileNet可以有效地减少参数的同时获得一定的精度。
3.1.1 使用MobileNetv1作为主干网络
MobileNetv1[10]由谷歌在2017 年提出,用于将CNN网络轻量化,使之可以转嫁于移动设备或者嵌入式设备中,其中亮点为提出了深度可分离卷积(Depthwise Separable Convolution)。深度可分离卷积是将传统卷积分为Depthwise 卷积和Pointwise 卷积两步。假设用DK×DK表示卷积核尺寸,用DF×DF表示输入的特征图尺寸,分别用M、N表示输入和输出的通道数,当步长为1且存在padding时,传统卷积的计算总量是:

而深度可分离卷积计算量为:

两者相互比较,计算量缩小为原来的:

MobileNetv1采用Relu6作为激活函数,图2是传统卷积,图3是深度可分离卷积。使用更多的Relu6,既增加了模型的非线性变化,又提高了模型的泛化能力。改进YOLOv3网络中Conv2D均采用Relu6函数。
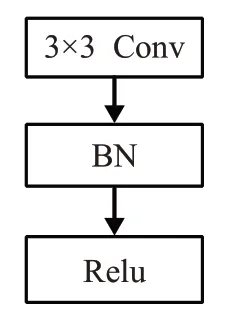
图2 传统卷积
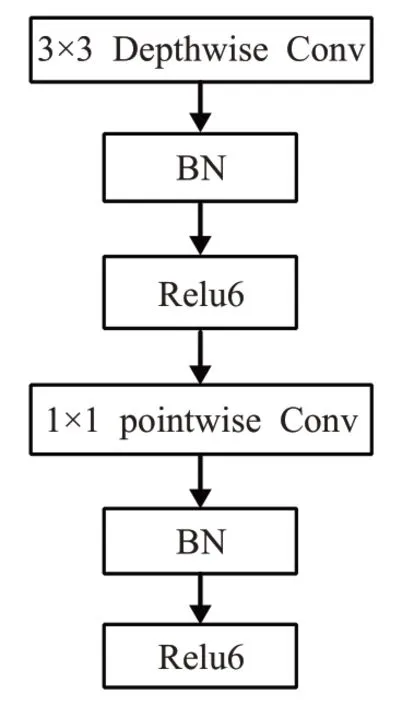
图3 深度可分离卷积
参考Darknet-53将MobileNetv1网络分割成三块不同特征提取图,第一个提取层提取出52×52×256特征图用于检测较小物体,第二个提取层提取出26×26×512特征图用于检测中等物体,第三个提取层提取出13×13×1 024特征图用于检测较大物体。保证精度的同时又提高了网络的实时性。
3.1.2 使用MobileNetv2作为主干网络
MobileNetv2[14]是在 MobileNetv1 上做的改进,是在2018 年提出来的,相对于MobileNetv1 主要做了两点改进:
(1)虽然MobileNetv2和MobileNetv1都是采用DW(Depth-wise)卷积搭配PW(Point-wise)卷积的方式来提取特征,但为了避免Relu对特征的破坏,MobileNetv2在DW 卷积前面加入了一个PW 卷积并且去掉了第二个PW的卷积,即线性瓶颈(Linear Bottlenecks)结构。
(2)参考ResNet的结构设计出了逆残差结构(Inverted residuals),在3×3网络结构前利用1×1卷积升维,在3×3网络结构后再利用1×1卷积降维。先进行扩张,再进行压缩。
3.1.3 使用MobileNetv3作为主干网络
MobileNetv3[15]是MobileNet 的最新版本,是在2019年提出来的,作为轻量级网络它的参数量还是一如既往地小。作为第三版的它主要综合了以下特点:
(1)吸收以前版本的优点,结合使用了Mobilenetv1的深度可分离卷积和Mobilenetv2的具有线性瓶颈的逆残差结构。
(2)引入了MnasNet[16]中基于挤压和激励(Squeeze and Excitation)结构的轻量级注意力模型,可以更好地调整每个通道的权重。
(3)发现swish 激活函数能够有效提高网络的精度,表示如下:

然而,由于swish的计算量太大,提出了h-swish(hard version of swish)公式表示如下:

如图4所示,这两个函数从函数图像上可以看出两者之间很相似。
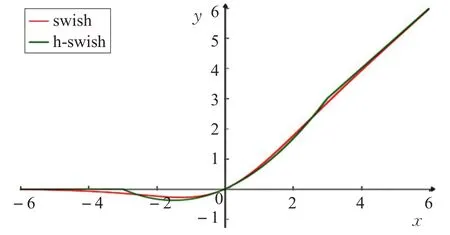
图4 swish和h-swish曲线图
3.2 引用空洞卷积
空洞卷积是在标准的卷积核中注入空洞,以此来增加特征图的感受野。图5 是传统卷积运算,图6 是空洞卷积运算。可以明显地看出空洞卷积既可以扩大感受野,也使卷积时捕获了多尺度的上下文信息,更利于缺陷部位的检测。在改进的YOLOv3 网络中加入一个超参数称之为dilation rate(膨胀率),在第一个特征提取图上加入1 倍的rate,在第二个特征提取图上加入2 倍的rate,在第三个特征提取图上加入4 倍的rate,以此使图片缺陷部位更加明显。
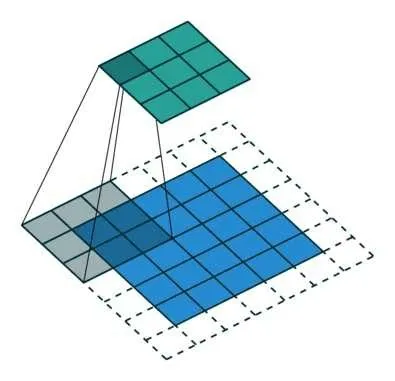
图5 传统卷积运算
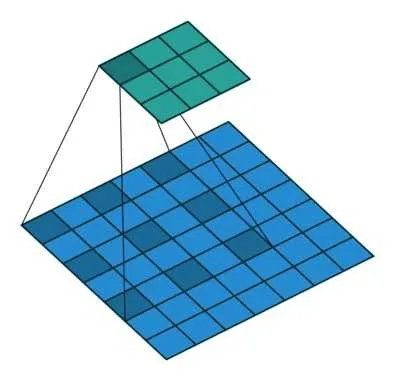
图6 空洞卷积运算
3.3 加入Inceptionv3结构
Inceptionv3[11]模型是谷歌Inception 模型的第三代,其模型结构与Inceptionv2模型发表在同一篇论文里,两者模型结构差距不大,相比其他神经网络模型,Inception模型最大的特点在于将神经网络层与层之间的卷积运算进行了拓展。Inception 网络采用不同大小的卷积核卷积,使得网络层存在不同大小的感受视野,最后拼接起来达到不同尺度的特征融合。结合Inceptionv3 中三种模型,将YOLOv3原网络最后一层中Conv2D 3×3卷积改为Inception 3×3 卷积结构。主要利用1×3 的卷积和3×1 的卷积代替原有的3×3 卷积,再利用两个1×1 卷积融合后得到Inception结构,相对于以前网络的数据参数量有大幅度的减小。其结构如图7所示。

图7 修改Inceptionv3结构图
3.4 修改后网络总结构图
结合以上特点得到三种修改的YOLOv3 网络结构如图8所示。
YOLOv3-mobileNetv2 结构和YOLOv3-MobileNetv3结构只需仿照YOLOv3-MobileNetv1 结构选取其中的三个尺度即可,图9 和图10 为 YOLOv3-MobileNetv2 网络与YOLOv3-MobileNetv3网络结构的简略版本。
4 实验结果与分析
4.1 实验平台

图8 YOLOv3-MobileNetv1结构修改图
本实验在Windows10 操作系统下完成。计算机CPU 为i7 9700;内存为16 GB;GPU 为RTX2070s,其显存为8 GB;运行软件为Anaconda3.6 平台下的VScode(Visual Studio Code);Python版本为3.6.4;安装了Cuda10.0和Cudnn7.5.1 帮助GPU 进行加速运算,同时在软件中安装 Tensorflow1.13.1、Opencv4.1 和 Numpy1.14.2 等一系列的第三方的库来支持代码的运行。
4.2 数据集
4.2.1 数据选择
本实验选用德国DAGM 钢板表面缺陷数据集,该数据集总共有10 大类缺陷,有训练集和测试集。选取其中三类缺陷中的训练集用于训练,将碰伤命名为class1、麻点命名为class2,并将划伤命名为class3,每类1 150张图片(含缺陷150张),共计3 450张图片。由于图片为512×512 png格式,不利于训练,用代码将图片分批次转换成416×416 jpg 格式,用于神经网络的训练。所有图片中3 000张完好,450张图片存在缺陷,将其打乱顺序放入同一个文件夹,再按照训练集和测试集9∶1的比例,选出前3 105张作为训练集,后345张作为测试集。

图9 YOLOv3-MobileNetv2结构修改图
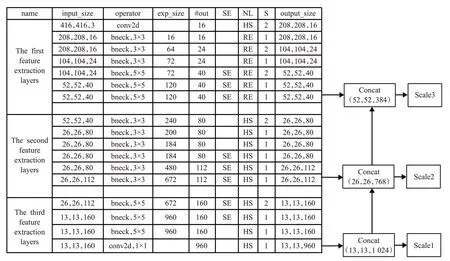
图10 YOLOv3-MobileNetv3(large)结构修改图
4.2.2 数据标注
数据集的标注比较耗费时间和专注力,需要获得数据集图片的各种缺陷信息。可以利用labelImg 软件对图片进行人工标注,将图片的长宽和深度,缺陷框的xmin、ymin、xmax和ymax等信息存入到.xml文件中,适用于神经网络的训练。将训练集和测试集中存在缺陷的450 张图片进行数据标注,生成.xml 文件,最后利用格式转换程序得到包含图片路径、名称、缺陷框标签和位置的.txt训练文件。
4.3 模型训练
按照修改部分改进网络,从而完成网络搭建,实验一共训练4个网络模型:YOLOv3,YOLOv3-MobileNetv1,YOLOv3-MobileNetv2,YOLOv3-MobileNetv3。每个网络训练800 epochs(轮次),共计约22小时。每个网络使用如下方法训练:先将网络的最初学习率调为0.01,batch_size(一次训练所选取的样本量,其大小影响模型优化和速度,根据网络参数和GPU内存大小进行调整)调为8,让loss(损失值)大范围下降训练300 epochs,得到初始loss值。再将学习率调低至0.001,让loss适当范围浮动训练300 epochs,最后将学习率调至0.000 1,让loss 小范围浮动训练200 epochs 得到最终的训练集损失值。图11 为YOLOv3-MobileNetv3 训练集的每轮epochs下loss下降图,横坐标为epochs值,纵坐标为loss值;图中的(1)和(2)为截取部分epochs放大图。
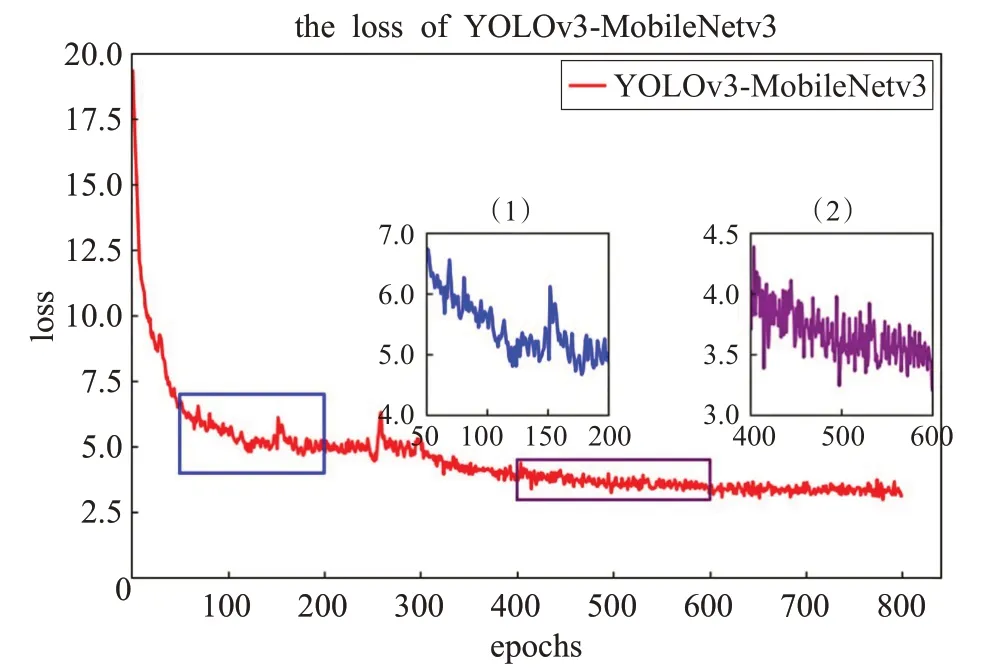
图11 YOLOv3-MobileNetv3的网络训练损失函数变化图
由图11(1)和(2)可以看出网络YOLOv3-MobileNetv3在50 epochs到200 epochs时下降很快,在400 epochs到600 epochs时趋于稳定,loss值在4.0到3.0之间,说明神经网络训练是有一定效果的,再调低学习率对训练效果影响不大,网络最终收敛在3.1左右。
重复使用以上方法训练的YOLOv3-MobileNetv1最终 loss 为 3.2,YOLOv3-MobileNetv2 最终 loss 为 3.4。由于YOLOv3 采用Darknet-53 结构,导致参数量较大,显存容量不够,只能将三次的batch_size缩小,都调整成4,训练得到的loss为4.1。得到的权重文件大小与训练时间如表1所示。
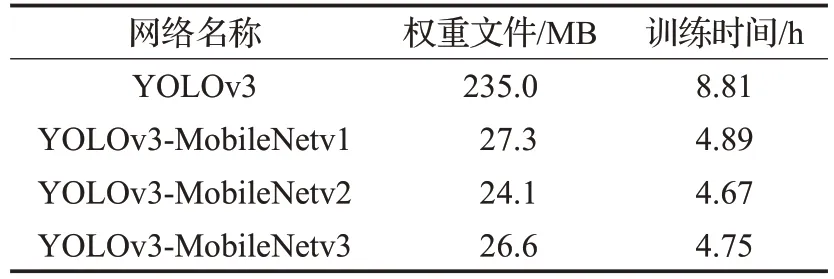
表1 网络权重文件和训练时间对比表
由表1 可知,在加入了MobileNet 类的结构作为主干网络,并用Inceptionv3 减小参数总量后,使权重文件比原先缩小了约88%,训练时间也缩短了一大半。更小的权重文件意味着更简单精巧的网络结构可以移植到性能差一点的移动端平台上,在不丢失精度的情况下也可以完美地运行得到想要的结果。
4.4 模型效果测试
调用训练好的YOLOv3-MobileNetv3 权重检测测试集的缺陷图片,得到的检测图片如图12~图14所示。

图12 第一类缺陷图

图13 第二类缺陷图

图14 第三类缺陷图
从图12~图14的几组图片可以看出,训练好的模型对缺陷图片有较好的检测结果。
4.5 性能对比
文章采用平均检测准确率(mAP)和帧率(FPS)对检测算法进行对比。
4.5.1 mAP对比
在目标检测中,利用某类模型准确率P(Precision)、召回率R(Recall)计算出平均准确率AP(Average Precision),最后把均值平均精度mAP(mean Average Precision)作为目标检测模型的性能评估标准。利用以下公式:

本文设置一个IOU(交并比)。IOU 是模型所预测的检测框和真实框的交集和并集之间的比例,设置IOU阈值为0.5。
TP:检测框中正确,且IOU大于阈值的。
FP:检测框中错误,且IOU小于阈值的。
FN:真实正确的框,却没有被模型检测到的。
参考以上公式,本文选取德国DAGM 钢板表面缺陷数据集中三类测试集缺陷图,每类缺陷各100 张,共计300 张缺陷测试图,打乱顺序,然后将图片由.png 格式转换成.jpg 格式,利用labelImg 软件标注出缺陷位置。先利用训练好的.h5格式的权值文件加载到模型中测试图片,再与标注后的图片进行对比,如图15所示。

图15 标注图片与检测图片对比图
运用上述方法得到四种网络结构各类缺陷的AP图,平均准确率AP 即图中阴影部分的面积占比。其中横坐标是召回率,纵坐标是某类模型准确率。例如YOLOv3中class1缺陷AP图如图16所示。

图16 YOLOv3中class1缺陷的AP图
具体每类网络中各类缺陷的AP数值如表2所示。

表2 网络各类缺陷AP对比表
再由式(8)可得到四种网络模型各自的mAP值:

其中YOLOv3-MobileNetv3模型的mAP图如图17所示。

图17 YOLOv3-MobileNetv3的mAP图
具体各类网络mAP数值如表3所示。

表3 网络mAP对比表
由表3 可知,由于 YOLOv3 采用 Darknet-53 作为特征提取层,参数量较大,在该数据集上并没有较好的表现,mAP 值仅为 78.49%。YOLOv3-MobileNetv1 网络mAP 为95.39%,较于 YOLOv3 提升 21.5%,YOLOv3-MobileNetv2 网络 mAP 为 96.5%,较 于 YOLOv3 提升22.9%。YOLOv3-MobileNetv3 由于它的特征提取主干网络MobileNetv3 吸收了MobileNetv1 和MobileNetv2的优点,加入孔空洞卷积并采用Inceptionv3 优化结构,mAP 为96.75%,相比于YOLOv3 提升了23.3%,具有较好的精度值。
4.5.2 FPS对比
FPS 是图像里的定义,是指画面每秒传输帧数,即视频中的画面数。本文使用的显卡为RTX2070s,其四种网络处理图片速度的对比结果如表4所示。

表4 网络处理速度对比表
由表4可以明显看出YOLOv3修改后的网络在处理图片速度上有着较为明显的提升,YOLOv3-MobileNetv2性能在改进的网络中最差为每秒40帧,YOLOv3-MobileNetv3性能为每秒43帧,虽不如YOLOv3-MobileNetv1的每秒47.6帧,但相比于YOLOv3每秒提高了21帧,可以满足流畅的视频处理,对于性能差一点的平台有更好的移植性。
综合以上实验结果,YOLOv3-MobileNetv3 在mAP和FPS上均有不错的效果,不但比YOLOv3网络提取特征模型参数量大大减小,训练时间也大幅度缩短,比YOLOv3更具有在工业上应用的前景。
5 讨论
5.1 MobileNet主干网络分析
利用MobileNet系列网络作为YOLOv3特征提取网络,上述实验已证明其可行性。
由图18 可以看出图片送入MobileNet 网络中卷积出的图片输送到FPN(特征金字塔)中,通过三个检测层分别检测出大目标、中目标和小目标缺陷。在保持精度的同时提高了帧数,有一定运行效率,在工业上有应用前景。
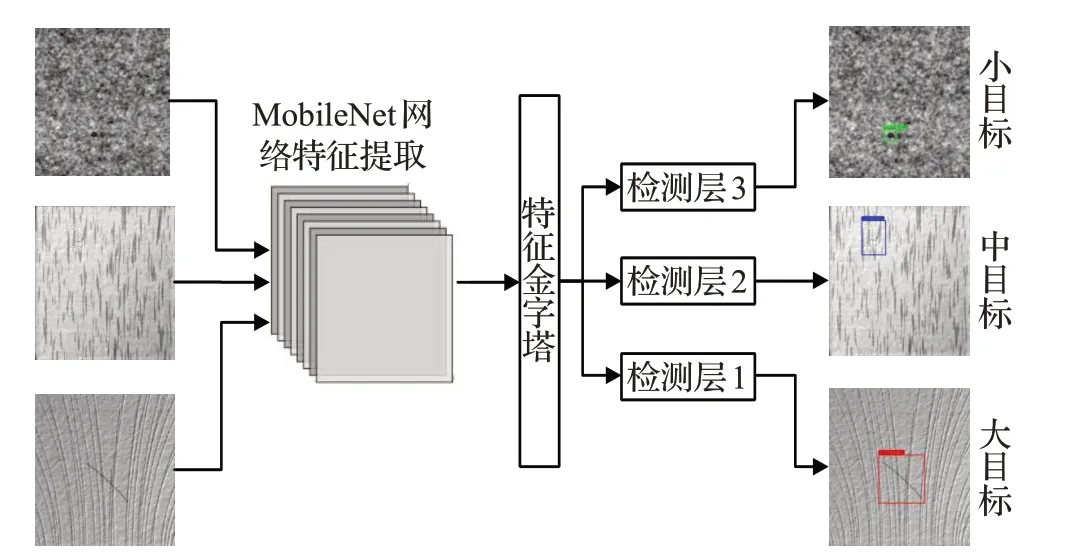
图18 MobileNet卷积网络作用图
5.2 空洞卷积分析
以分类为class3的划痕缺陷为例,捕获部分网络提取层中信息,以验证空洞卷积效果。如图19所示,图(a)为缺陷原图,图(b)为加入空洞卷积后截取一个通道的图片,可以明显看出适当加入空洞可以扩大感受野,图(c)所示该通道网络最后卷积图,可以看出缺陷部位信息明显,易于网络的训练与检测。

图19 空洞卷积效果图
5.3 Inception结构分析
Inception在网络中采用非对称卷积进行修改,即将在原有YOLOv3网络最后一层中3×3卷积分解为3×1和1×3 卷积,这样做可节省33%([(9-6)/9])的计算量,再利用两个1×1 卷积叠加构成Inception 结构。利用此结构既加深了网络深度,也减少了参数总的计算量。以分类为class1的碰伤缺陷为例,验证该结构下不同大小感受视野下不同尺度的特征融合部分仿真结果,如图20所示。

图20 Inception结构卷积效果图
最后检测效果如图21所示。

图21 最终检测效果图
结合图20 和图21 可以看出,经过Inception 结构卷积后左上角的缺陷特征明显,证明了Inception结构对缺陷部位检测有促进作用,具有可行性。
6 结束语
本文使用一种改进后的YOLOv3 网络对工业上钢板表面进行缺陷检测,修改了德国DAGM 钢板表面缺陷数据集,使之适应网络的训练;使用轻量级MobileNet网络来代替YOLOv3原有网络中的Darknet-53网络,适当减少参数量的提取;加入空洞卷积,提高网络对小目标缺陷的检测能力;在网络结构最后一层卷积中加入了Inception 结构,可以进一步减少参数总量并加深网络。从实验结果可以知道,修改后的YOLOv3在精度和速度上都有明显的提升。下一步工作是优化模型算法,将网络移植到性能更差的移动端设备上。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
电子制作(2018年19期)2018-11-14 02:37:08
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
自动化学报(2017年11期)2017-04-04 02:52:58
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:53
管理现代化(2016年3期)2016-02-06 02:04:41
管理现代化(2016年3期)2016-02-06 02:04:13
智能系统学报(2015年4期)2015-12-27 09:37:52
噪声与振动控制(2015年4期)2015-01-01 07:08:21
