
基于主题的多线程网络爬虫系统的研究
2020-08-15 13:30宋婷婷
现代信息科技 2020年7期
摘 要:网络爬虫是当前较流行的网络搜索引擎工具,其设计需要不断优化,研究也需要不断深入。主题网络爬虫抓取目标明确、抓取结果的结构性较好,更便于进行分析。该文报告了网络爬虫技术的现状,从主题网络爬虫的基本结构入手,对当前主题网络爬虫主流系统的系统功能架构和主要功能模块进行了研究,并分析了当前主流系统的多线程管理模式,特别对基于Java开源框架的爬虫系统的多线程进行分析,为网络爬虫性能的提高提出更进一步的方法。
关键词:多线程;主题;网络爬虫
中图分类号:TP391.3 文献标识码:A 文章编号:2096-4706(2020)07-0083-04
Research on Multi-threaded Web Crawler System Based on Theme
SONG Tingting
(Minjiang University,Fuzhou 350108,China)
Abstract:Web crawlers are currently popular web search engine tools,and their design needs to be constantly optimized,and research needs to be constantly deepened. Topic crawlers have clear crawling targets and better structure of crawling results,which is easier to analyze. This article reports on the current status of web crawler technology. Starting from the basic structure of the theme web crawler,the system functional architecture and main functional modules of the current mainstream system of the theme web crawler are studied,and the multi-thread management mode of the current mainstream system is analyzed. In particular,the multithreading of the crawler system based on the Java open source framework is analyzed,and a further method for improving the performance of the web crawler is proposed.
Keywords:multi-thread;theme;web crawler
0 引 言
隨着全球信息化的飞速发展,如何有效抓取并利用互联网上海量数据中的有用信息成了重大挑战。传统的网络爬虫受制于带宽、系统资源等多方面条件,在某限定时间内下载数据有限、下载目标数据不够明确,已经难以满足用户的需求,主题网络爬虫应运而生。
主题网络爬虫虽在国内起步晚,但发展迅速,已经成为当前搜索引擎和网页信息挖掘中的一个研究热点。主题网络爬虫通过对整个网页按主题分块采集,再将不同块的采集结果重新整合到一起,得以提高整个网页的采集覆盖率和页面利用率。
本文是基于闽江学院的福建省教育厅中青年教师教育科研项目“基于多线程的主题网络爬虫的算法分析与性能优化”的研究成果。笔者作为项目的申请人和主持人,将从以下几个方面进行阐述。
1 主题网络爬虫的基本构成
主题网络爬虫是从一个网站的某个页面(通常是网站主页)开始,然后有选择地访问互联网的网页,获取信息。主题爬虫不追求网络覆盖率,其关注点在于与某一主题相关的内容。主题爬虫是有目的、有选择地在网络中爬行,为面向该主题的用户提供数据。主题爬虫在抓取页面时,需要对页面进行主题相关性分析、过滤,保留与主题相关的链接,将有效网址加入准备进行网页爬取的队列中,然后根据确定采用的算法策略从未爬取的队列中选择下一个设定的URL进行爬取,直到设定的策略执行完结束爬取。
主题网络爬虫的基本思想是通过机器学习的方式预先建立主题模型,在爬取过程中使用主题模型来判断当前页面和待抓取的下一条URL的主题相关度,保证尽可能少地采集与主题无关的页面,保留与主题相关的网页。主题爬虫与通用爬虫的主要区别就在于增加了判断网页内容是否与主题相关的主题判断模块和不同的网页搜索策略。
2 面向主题的多线程网络爬虫系统介绍
2.1 系统的功能架构
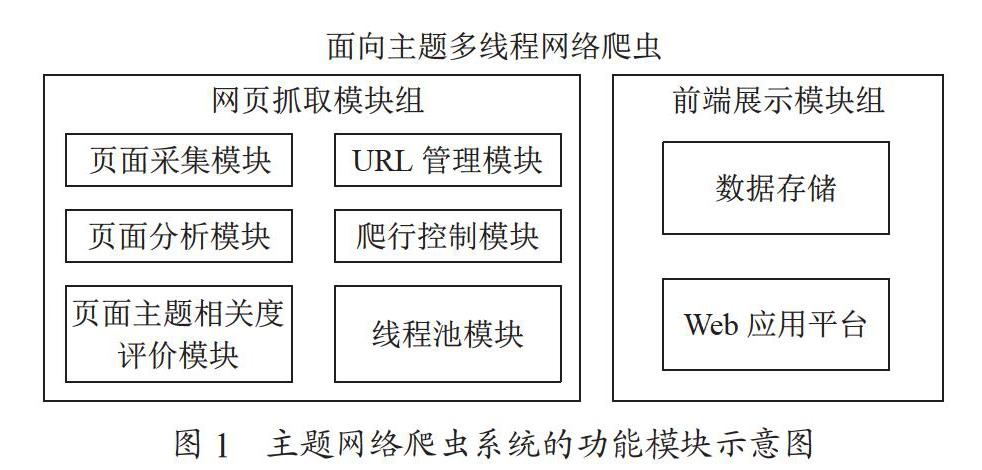
如图1所示,面向主题的多线程网络爬虫系统主要分为两大功能架构组:网页抓取模块组、前端展示模块组。主题爬虫系统的功能主要体现在网页抓取模块组,该模块组内含页面采集、页面分析、页面主题相关度评价、URL管理、爬行控制和线程池六大模块。
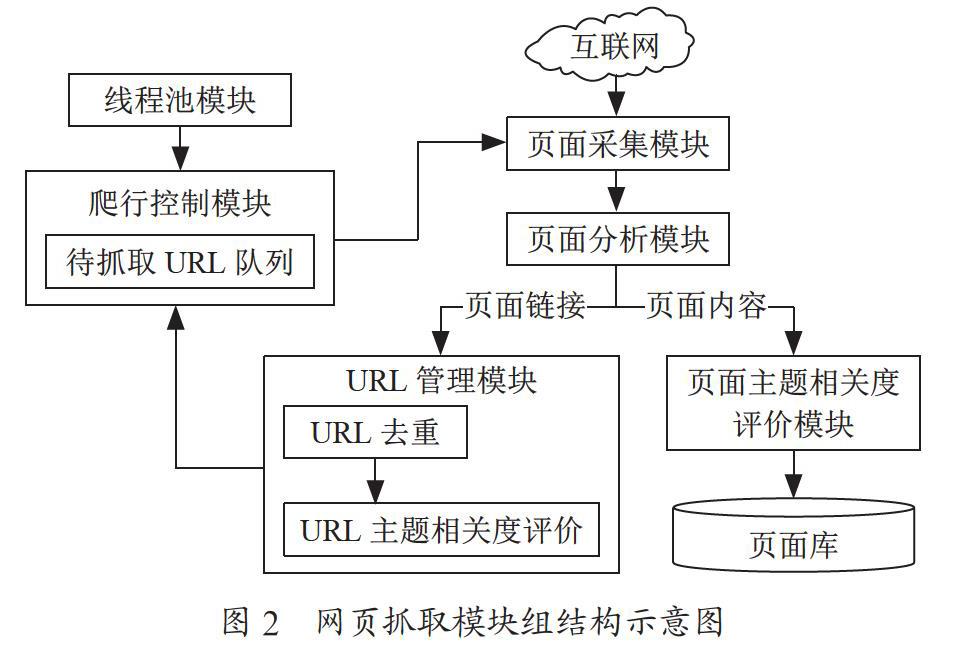
为了获取关联度较高的页面链接,通常使用URL关联模块和主题相关度评价模块,先通过页面采集模块把关联页面下载下来,这种方式可以尽可能地避免下载无关页面,节省爬取时间,减少资源消耗,提高系统性能。网页抓取模块组的结构示意图如图2所示。
2.2 系统功能模块
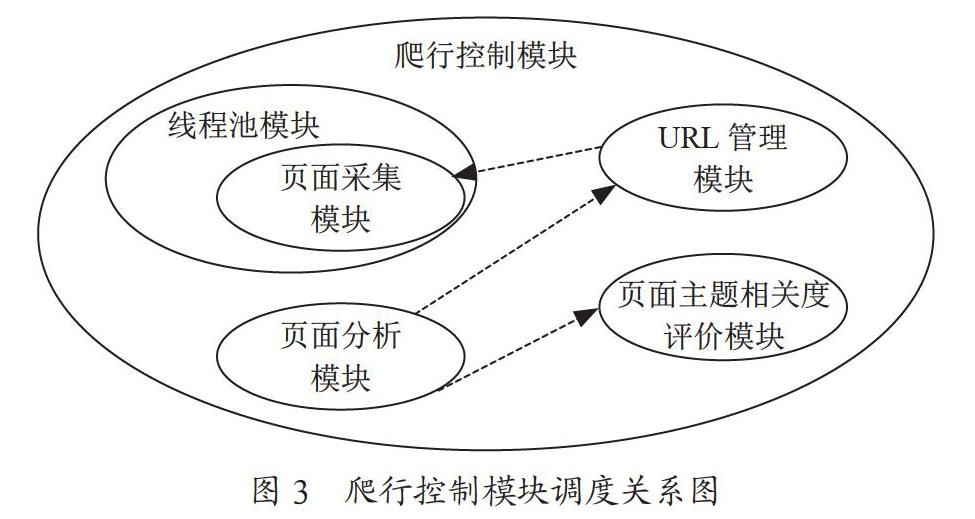
(1)爬行控制模块。该模块是整个系统的核心,协调调度其他模块的运行。通过该模块可以调用线程池模块,将多线程应用于网页爬取,通过URL管理模块解析URL,找出满足相关度要求的链接并将其加入待爬取的队列中,抛弃无法满足相关度要求的链接。图3显示了该模块与其他模块之间的调度关系。
(2)页面采集模块。页面采集模块的主要任务是在爬取队列中下载相关网页,即通过HTTP协议将服务器端与URL对应的页面下载。其原理是首先在主程序设置一个初始的URL地址,获取其页面所包含的所有链接地址,建立待爬取队列。判断该队列在非空的情况下哪些URL已被爬取,同时下载未被爬取的URL页面,忽略已抓取的页面,直到队列清空。
(3)URL管理模块。URL管理模块的任务是初始化待抓取队列,并对页面内容进行去重处理。如果URL未被抓取就调用相关函数进行下载,如果已被抓取则略过。循环执行上述步骤直到待抓取队列为空。URL管理模块的另一个功能就是给URL队列进行排序,保证相关度高的URL能够优先被抓取。
(4)页面分析模块。该模块主要任务是设置分析规则,对下载的页面的源码按照规则进行解析,实现网页文本内容的提取。
(5)页面主题相关度评价模块。该模块的主要任务是网页的主题相关度计算。需要预先设置主题关键字及其边界,再導入页面分析模块提取出来的文本内容,匹配相应算法计算文本内容的相似度,然后把文本内容符合主题要求的页面写到系统数据库中,不符合的则丢弃。
(6)线程池模块。该模块是本文重点研究的对象,其主要任务是管理多线程,提高爬取性能。
3 系统的多线程管理
3.1 多线程网络爬虫
网络爬虫如果仅仅使用一个线程,那么需要花费很多时间等待DNS服务器的响应,另外发送到服务器端的请求以及接收从服务器端返回的网页数据都需要耗费大量时间,但是等待的过程CPU却总是空闲,严重浪费了系统资源。单线程网络爬虫已经被多线程模式所取代,以提升CPU利用效率,减少等待时间。
利用多线程一次可以爬取多个网页,为避免多线程网络爬虫系统占用过多服务器资源,需要使用礼貌策略,所谓礼貌策略就是让服务器的多数时间用于处理实际用户的请求,而爬虫工作会在处理请求的间隙执行。执行多个爬取任务通常需要在各个任务间相互协调和通信。所以多线程的程序复杂度要远远比单线程高。
多线程技术的使用提升了爬虫效率,但是系统资源也将因频繁地创建和销毁线程对象而消耗。因此为解决这个问题,使用线程池技术,即线程池中存在可随时被唤醒的线程以降低创建线程时的资源消耗,可以改善因多线程的频繁创建而引发的系统效率降低的问题。
3.2 线程池的原理
线程池是根据任务需求创建或销毁线程对象的,线程池通常会创建一批线程,这批线程为空闲等待状态。当一个请求进入系统,线程池马上调度一个空闲状态的线程进行处理。但是如果长时间没有任务请求,线程池内的线程一直空闲等待,线程池中设定的策略会主动把这些没有被调用的线程销毁,从而达到降低系统资源开销的目的。反之如果线程池中的线程一直处于运行状态,那么线程池又会创建更多线程等待处理新任务。线程池工作模式如图4所示。
线程池对提高效率作用很大,使用线程池的优点如下:
(1)线程池技术可以根据实际情况实时调整线程的数量,使效率大大提高,在实际使用线程池的过程中要注意:需要综合考虑来设置合适的线程数量,线程数并不是越多越好;需要考虑多线程并发可能导致的各种错误,避免死锁的产生。
(2)线程池中的每个线程都可以复用,将创建和销毁线程时导致的对系统资源过多的占用影响降至最低。
基于以上分析,所以在做相关主题爬虫设计的时候,为提高爬虫的性能和系统资源使用率,尽量要考虑使用线程池来管理多线程。
3.3 爬虫多线程工作流程
爬虫多线程工作流程如图5所示。多线程爬虫的工作流程如下:
(1)将线程数初始设定为0;
(2)在配置文件中确定线程数量的最大值。然后程序判断线程数是否达到该值。若达到则线程被线程池收回,结束该流程。否则继续下一步;
(3)线程从待抓取的URL队列中取出一个URL地址,作为页面下载入口。如果待抓取队列为空,该线程就终止,否则线程计数器就加1;
(4)系统发送HTTP异步请求,当前线程继续执行爬取任务,然后返回第2步判断线程数,是否继续获取新的URL下载。同时分配新线程,等待HTTP响应;
(5)线程接收到响应数据后,对页面数据进行分析处理,把新的URL放入待抓取队列中,线程数减1,一个爬取任务完成。
4 基于Java的爬虫系统的多线程设计
4.1 Java多线程爬虫框架——Crawler4j
一个系统程序代表了一个进程,进程占用CPU资源运行。一个进程可以包含多个线程,线程是资源调度的基本单位,执行一段程序的实质就是在多个线程之间进行切换,程序的不同部分由不同的线程执行。因此当线程池中某个线程在等待HTTP做出响应时,其他线程就进入CPU执行,避免资源的浪费。
Java语言对多线程提供了很好的支持,Java的开源性决定了在众多领域都有不同的Java开源框架。Crawler4j是一个开源的Java网络爬虫框架,提供一个用于抓取Web页面的简单接口,可以利用这个接口实现一个多线程的Web爬虫。使用这个框架,可以非常简单地在Crawler4j所提供的接口基础上进行扩展,从而实现爬虫功能。同时这个开源框架还提供了线程实时监控功能,以便查看线程的运行情况和数据爬取情况。因此使用Crawler4j框架接口实现多线程的、可自定义网页抽取规则和解析规则的主题网络爬虫系统。
Crawler4j框架包含有三大组件,分别是Frontier、Fetcher、Parser。Frontier组件是该框架的核心,包含URL处理队列接口,提供链接处理及其后续工作;Fetcher组件提供了获取URL指定页面内容的接口;Parser组件提供了种子提取的接口并将其放入URL队列中。Crawler4j框架还提供了CrawlerController线程控制器实现爬虫线程的控制,当然还包含其他一些组件。
在实际开发过程中,只需要对Crawler4j框架中的页面解析方式和URL的访问规则进行修改,使其能够按照用户的配置进行网页抓取。系统采用多线程控制Crawler4j的线程控制器,能够通过用户的配置信息,创建不同的爬虫任务。系统为用户提供任务控制接口,用户可以通过界面控制爬虫任务的运行情况。
主题爬虫系统支持多任务同时爬取,在爬行控制模块中设置任务控制器,管理爬取任务队列,每个任务都可以自行设定配置参数和种子链接,按配置参数由CrawlerController控制器进行调度来爬取相关数据。Crawler4j框架主要由三个类实现多线程管理,分别是任务管理类(TaskController)、活动任务类(AliveTask)、活动任务队列类(AliveTaskQueue)。
4.2 爬虫线程的工作流程设计
当线程接收到URL待爬取队列中的链接地址后,通过DNS解析链接地址,获取页面信息,然后利用框架的HTMLParser類对页面信息进行解析,提取出页面文本内容、链接信息等,然后通过页面分析模块和相关度评价模块进行处理,判断分析后的文本内容是否与主题相关,若页面内容与用户设定主题相关,则过滤该页面中的URL,将有效的URL加入队列,继续抓取下一条URL,同时将当前页面交由另外的文本处理线程对当前文本进行后续处理,生成文本内容摘要,结合内容特征向量和摘要特征向量生成内容语义信息和摘要语义信息,将语义信息和网页信息保存至数据库中,同时建立该页面的全文索引。
5 结 论
本文详细介绍了基于主题的多线程网络爬虫系统中的主要功能模块,并详细介绍了系统的多线程管理方式、原理和工作流程,并通过对Java开源框架——Crawler4j的介绍和使用,实现了爬虫线程的工作流程的设计。
参考文献:
[1] 葛玲.基于查询扩展的主题爬虫研究 [D].北京:北京工业大学,2009.
[2] 孙青云,王俊峰,赵宗渠,等.一种基于模拟登录的微博数据采集方案 [J].计算机技术与发展,2014,24(3):6-10.
[3] 陈睿嘉,康志忠,张卫涛.基于网络爬虫的导航深度服务信息自动采集 [J].测绘工程,2015,24(1):17-24.
[4] 段兵营.捜索引擎中网络爬虫的研究与实现 [D].西安:西安电子科技大学,2014.
[5] 王洪威.主题网络爬虫的分析与设计 [D].北京:北京邮电大学,2013.
[6] 陈千.主题网络爬虫关键技术的研究与应用 [D].北京:北京理工大学,2015.
[7] 柴嘉斌,李广华,李长春.主题爬虫搜索策略的研究 [J].科技信息,2011(12):234-235.
[8] 张晓雷.面向Web挖掘的主题网络爬虫的研究与实现 [D].西安:西安电子科技大学,2012.
作者简介:宋婷婷(1980—),女,汉族,福建福州人,讲师,硕士,研究方向:网络爬虫。
猜你喜欢
中国新通信(2016年21期)2017-01-06
戏剧之家(2016年20期)2016-11-09
电影文学(2016年16期)2016-10-22
课程教育研究·学法教法研究(2016年21期)2016-10-20
考试周刊(2016年79期)2016-10-13
电脑知识与技术(2016年20期)2016-08-19
电脑知识与技术(2016年17期)2016-07-23
中国市场(2016年23期)2016-07-05
电脑知识与技术(2016年7期)2016-05-19
电影文学(2016年9期)2016-05-17
