
在线学习的主用户仿冒攻击策略
2020-08-14 04:53:32王少尉
国防科技大学学报 2020年4期
盛 响,王少尉
(南京大学 电子科学与工程学院, 江苏 南京 210023)
在认知无线网络[1-2]中,用户被分成主用户和次用户。主用户持有使用授权频段的牌照,可以随时接入该频段,而次用户只能通过频谱感知[3-5]在不影响主用户的情况下机会性地接入该频段。然而,频谱感知技术并不是绝对安全的[6-7]。主用户仿冒攻击是一种针对频谱感知技术的欺骗性干扰,它通过传输伪造的主用户信号来修改频谱环境以阻碍次用户的频谱感知[8]。只有深入研究主用户仿冒攻击策略即在每个时隙如何选定攻击信道,才能进一步确保认知无线网络的安全性。主用户仿冒攻击者(Primary User Emulation Attacker, PUEA)的目的在于阻止次用户接入频谱,这要求能在次用户感知的频谱空隙上传输伪造的主用户信号。然而实际上,主用户仿冒攻击者并没有任何关于频谱环境和次用户行为的先验知识,很可能会攻击那些被主用户占据或未被次用户感知的频段,这严重影响了攻击的有效性。因此,智能的攻击者需要使其攻击策略适应于非平稳的频谱环境和次用户频谱感知策略,其主要难点有以下两个方面:一是攻击者无法判断攻击是否有效,这是因为被攻击的信道永远不会被次用户接入;二是攻击者对非平稳的认知无线网络没有任何先验知识,只能通过观察信道状态来学习。对攻击策略的充分理解可以帮助认知无线网络量化主用户仿冒攻击对次用户吞吐量的影响,这有助于相应的检测和防御策略的评估。此外,智能的主用户仿冒攻击者为其他现有干扰者的策略设计提供了一种新思路,并可以指导认知无线网络中安全机制的设计。这是本文的动机和意义所在。
文献[9]提出了基于部分可观测马尔可夫决策过程的攻击策略。这种攻击策略的部署依赖于攻击者获得攻击结果的能力。也就是说,攻击者需要知道是否有次用户曾感知被攻击的信道。文献[10]提出了三种攻击策略(均匀随机攻击、最大拦截攻击和选择性攻击)来检验次用户防御策略的有效性,其假设次用户算法的参数对攻击者是已知的。次用户算法的参数是其对信道的度量,该值越高的信道被感知的概率越大。文献[11]提出了基于在线学习算法EXP3.G的攻击策略,该策略不依赖于任何关于认知无线网络的先验知识,其考虑的系统模型是平稳的认知无线网络,也就是该网络中频谱环境和次用户频谱感知策略的统计特性是固定的。
本文研究了在非平稳的认知无线网络中的主用户仿冒攻击策略问题,将攻击策略问题归约为在线学习问题,并提出了基于汤普森采样的在线攻击策略。提出的在线攻击策略根据攻击者观察到的频谱环境信息和次用户行为不断更新以最大化攻击效果,可以有效地适应非平稳的认知无线网络。仿真结果表明,相较于现有的攻击策略,提出的在线攻击策略在稳态信道和非稳态信道场景下的两项性能指标(主用户仿冒累积攻击和次用户累积接入)都表现优越。
1 系统模型和问题归约
1.1 系统模型
考虑一个典型的认知无线网络,该网络包括K个授权信道、N个次用户和1个主用户仿冒攻击者。该网络以时隙方式运行,即在一个时隙内授权信道的状态保持不变。
认知无线网络中主用户的行为(数据传输或空闲)决定了授权信道的主用户使用状态。本文只考虑信道的主用户使用状态,而不指定主用户的行为模式。记K个信道为K={1,2,…,K},主用户使用状态共计有2K个可能。在时隙t的主用户使用状态表示为Dt=[dt(1),…,dt(K)],其中dt(i)∈{0,1}(当信道i被主用户占据时等于0,当信道i处于空闲状态时等于1)。值得注意的是,信道主用户使用状态的统计特性不是固定的,而是时变的甚至是任意的。
记认知无线网络中N个次用户的集合为N={1,2,…,N}。在每个时隙,每个次用户依次进行频谱感知和数据传输。在时隙t的频谱感知阶段,次用户j受限于其有限的采样率只能感知一个信道qt,j。在数据传输阶段,如果该信道处于空闲状态,次用户j接入该信道并传输数据,否则次用户j保持静默。考虑多个次用户的情形,可以利用现有的控制信道来避免因两个次用户感知同一个信道而产生的碰撞,这样的话就可以将N个次用户看作1个可以同时感知和接入N个信道的次用户。记该次用户群感知的信道为Qt={qt,1,…,qt,N}。
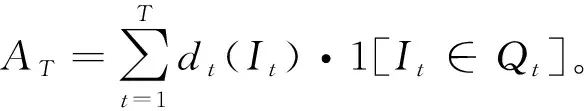

图1 主用户仿冒攻击者的帧结构Fig.1 Time slot structure of PUEA
1.2 问题归约
攻击者的目标是最大化AT。为此,在每个时隙,攻击者不仅需要攻击最可能被次用户接入的信道It,还需要观察能给之后决策带来最大帮助的信道Jt。这是一个典型的多臂赌博机问题[12],一种特殊的在线学习问题[13],它可以被描述为:在一系列实验中,赌徒通过在每个回合选择K个摇臂中的一个来最大化总奖赏,每个摇臂都服从赌徒不知道的奖赏分布,该分布的特性只能通过过去的奖赏得到部分反映。具体来说,在时隙t,定义信道k∈K的奖赏rt(k)为攻击者攻击该信道的成功次数dt(It)·1[It∈Qt]。该问题的攻击策略可以表示为φ={φ(t)}t≥1,其中φ(t):K→(It,Jt)只依赖于过去t-1个时隙观察到的信道状态信息{Om(n)}t>m≥1,n∈Jt。攻击者的最优攻击策略φ*可表示为:
(1)
上述优化问题是很难解决的,一方面信道奖赏分布的统计特性只能通过观察结果部分反映,另一方面信道奖赏分布的统计特性不是固定的。
2 在线攻击策略
汤普森采样[14-15]是一种旨在解决多臂赌博机问题的启发式算法。该算法的核心思想是在每个回合根据每个摇臂是最优摇臂的后验概率随机选择信道,其中后验概率按照贝叶斯规则根据观察结果进行更新。提出的在线攻击策略分为两个阶段——攻击和观察。
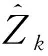
(2)
式中,θ1,k的值在0到1之间且服从贝塔分布。θ1,k的分布B(S1,k,F1,k)可以表示为:
(3)
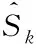

=(1-θ1,k)·θ2,k
(4)
攻击者根据每个信道是最优的概率随机选择一个信道攻击。值得注意的是,不需要将上述概率精确计算出:在每一轮对θ1,k和θ2,k进行一次抽样,然后选择有着最大奖赏期望的信道就足够了。记θ1,k和θ2,k的抽样值为θ1,k(t)和θ2,k(t),有着最大奖赏期望的信道也就是
=argmaxk[(1-θ1,k(t))·θ2,k]
(5)
P(θ1,k,θ2,k|Ot(k))∝P(Ot(k)|θ1,k,θ2,k)P(θ1,k,θ2,k)
(6)
其中,
(7)
将θ1,k和θ2,k的分布代入上述贝叶斯规则,可得到在观察到Ot(k)后的参数更新规则为:
(8)
考虑实际网络中主用户占用行为和次用户感知行为的非平稳性,引入遗忘因子来减少过去观察的影响以适应时变的环境。在上述贝叶斯更新后,再根据遗忘因子γ更新所有信道的参数,即
(S1,k,F1,k,S2,k,F2,k)←γ(S1,k,F1,k,S2,k,F2,k)+
(9)
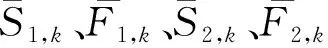

算法1 在线攻击策略
3 仿真结果与分析
本节给出了提出的在线攻击策略在稳态信道和非稳态信道场景下的仿真结果。与文献[11,16]中的设置相同,假定每个信道的主用户使用状态服从独立的两状态马尔可夫链,信道k的转移概率矩阵可表示为:
(10)
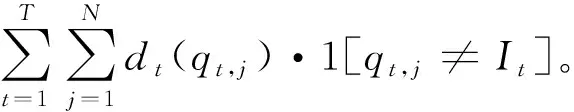
图2比较了在稳态信道场景下攻击策略的性能,具体仿真参数为:K=10,N=1,λ=1,T=2000,γ=0.99。可以看出:在线攻击策略的主用户仿冒累积攻击为376,比PROLA和RA分别高了35%和119%;相应的次用户累积接入为1105,比PROLA、RA和无攻击者分别少了8%、28%和36%。性能提升的原因有两方面:①考虑并有效处理了次用户行为的非平稳性带来的挑战;② 提出的算法能够更有效而快速地利用观察信息改进攻击策略。值得注意的是,主用户仿冒累积攻击的增加量和次用户累积接入的减少量是密切相关但又不完全相同的。以在线攻击策略为例,相较于无攻击的情况,主用户仿冒累积攻击增加了376,而次用户累积接入减少了609,这是因为每一次成功的主用户仿冒攻击对次用户的影响包括直接的阻止次用户接入和间接的破坏次用户对主用户行为规律的学习。
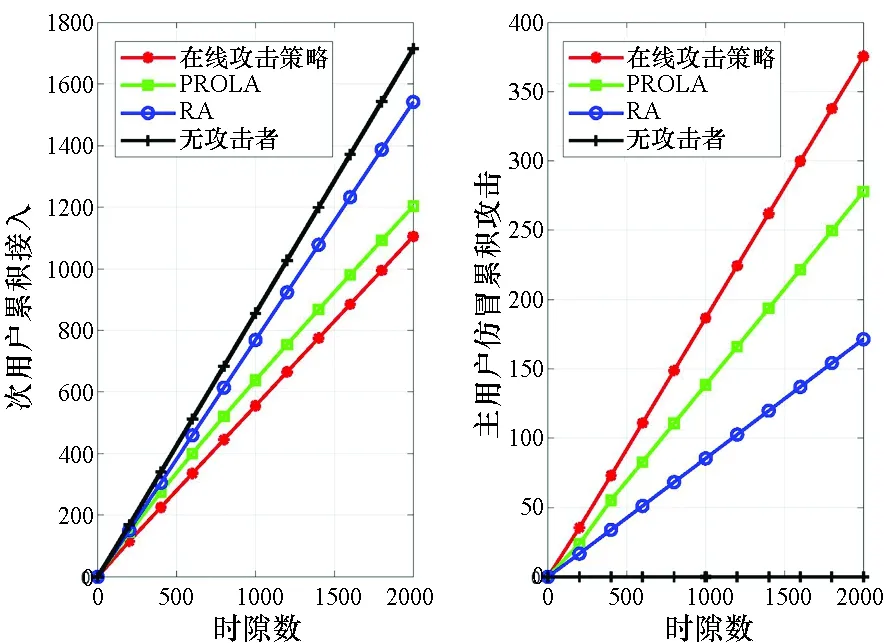
图2 稳态信道场景下攻击策略性能Fig.2 Performance of tested strategies in stationarychannel scenario
图3比较了在非稳态信道场景下攻击策略的性能,具体仿真参数为:K=10,N=1,λ=1,T=2000,γ=0.99,ΔT=100,PΔ∈[0,1]。随着PΔ的增加,主用户使用状态的非平稳性不断增加,极大影响了次用户和攻击者的性能。随着PΔ从0到1,三种攻击策略的主用户仿冒累积攻击都有着不同程度的下降。其中PROLA的主用户仿冒累积攻击下降了40%,而在线攻击策略的主用户仿冒累积攻击只下降了8%,与此同时两者之间的差距也从35%增加到了98%。这是因为引入的遗忘因子γ可以很好地处理认知无线网络中的非平稳性。值得注意的是,次用户累积接入并没有随着PΔ的增加而产生一致的变化,这是因为次用户在无攻击情况下的累积接入随着PΔ的增加而减少。在线攻击策略的次用户累积接入随着PΔ的增加甚至有小幅增加的原因在于:主用户仿冒攻击的间接影响本质上是为次用户学习的环境添加非平稳性,其影响随着环境本身非平稳性的增加而减弱。
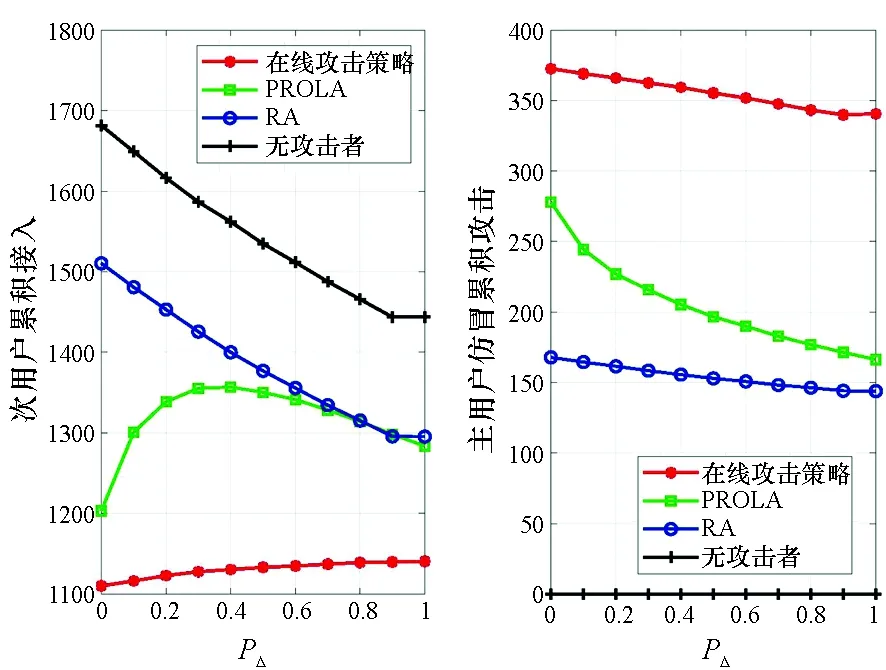
图3 非稳态信道场景下攻击策略性能Fig.3 Performance of tested strategies in non-stationary channel scenario
图4比较了不同λ下的在线攻击策略性能,具体仿真参数为:K=40,N=4,λ∈[1,37],T=2000,γ=0.99,ΔT=100,PΔ=0.5。随着λ从1到37,在线攻击策略的主用户仿冒累计攻击在稳态和非稳态信道场景下分别提升了30%和90%。这是因为攻击者在每个时隙观察到的信道状态信息随着λ的增加而增加,也就是说攻击者的学习能力随着λ的增加而增加。相较于稳态信道场景,λ的增加对非稳态信道场景的影响更大。这是因为非稳态信道场景更为复杂,攻击者学习起来也更困难。值得注意的是,λ的增加会提高对攻击者计算能力的要求,因此需要在性能和代价间权衡。在刚开始的阶段,通过少量增加λ(如从1到4),主用户仿冒累积攻击显著提高;当λ足够大时(如从10到13),主用户仿冒累积攻击的增加量就几乎可忽略不计了。本次仿真中,当λ为10时,攻击者的表现已经接近最优。
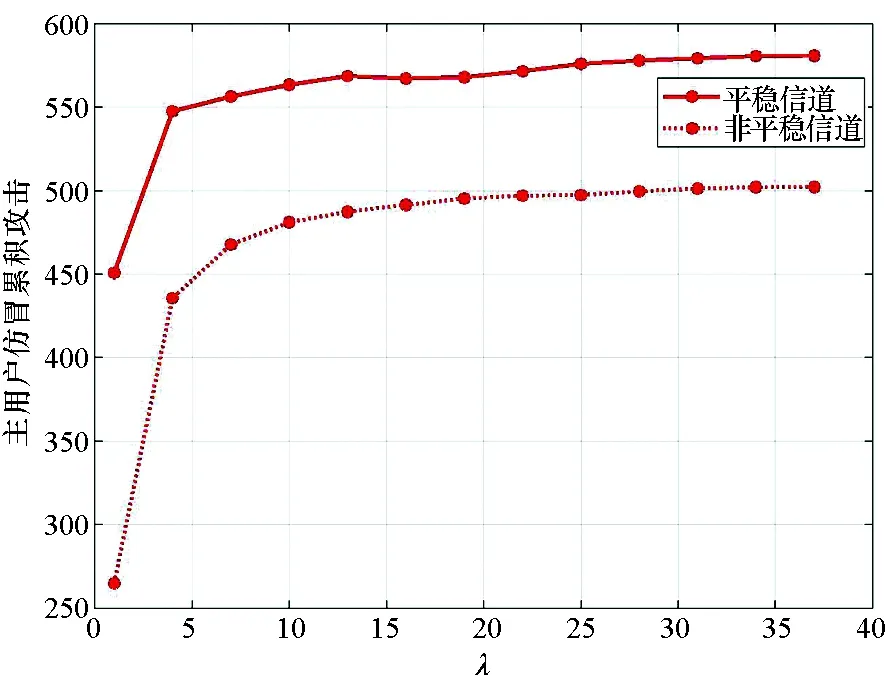
图4 不同λ下的在线攻击策略性能Fig.4 Performance of online attacking strategy under different λ
4 结论
以认知无线网络中的主用户仿冒攻击策略问题为例,通过在线学习将攻击者的观察和策略更新相结合以实现更有效地攻击,这为无线网络中干扰机如何通过与环境交互实现干扰决策优化提供了一种思路。具体来说,将主用户仿冒攻击策略问题建模为在线学习问题,并提出了基于汤普森采样的在线攻击策略。该攻击策略可以有效利用观察信息实现在利用高奖赏信道和探索奖赏未知信道之间的权衡。仿真结果表明,与现有攻击策略相比,在线攻击策略在稳态信道和非稳态信道场景下都表现优越,能够有效适应非平稳的认知无线网络,并在少量的观察信道下就达到接近最优的性能。
猜你喜欢
自动化学报(2021年8期)2021-09-28 07:20:18
铁道通信信号(2020年12期)2020-03-29 06:22:16
铁道通信信号(2018年9期)2018-11-10 03:26:46
爱你(2018年16期)2018-06-21 03:28:44
舰船电子对抗(2016年3期)2016-12-13 05:15:55
信息安全研究(2016年4期)2016-12-01 06:07:04
广西大学学报(自然科学版)(2016年5期)2016-11-12 06:28:54
指挥与控制学报(2015年4期)2015-11-01 10:09:34
移动通信(2015年17期)2015-08-24 08:13:12
计算机工程(2014年10期)2014-06-07 05:53:21
