
基于车牌时空数据的城市热点交通线路挖掘 ①
2020-08-11 01:42:56张翔宇吕明琪李素玲
高技术通讯 2020年7期
张翔宇 张 强 吕明琪 李素玲**
(*中国科学院计算技术研究所 北京 100190) (**中国科学院大学 北京 100049) (***浙江工业大学计算机学院 杭州 310014) (****北京赛迪时代信息产业股份有限公司 北京 100048) (*****中华全国总工会 北京 100085)
0 引 言
智能交通系统(intelligent transportation system, ITS)是改善城市交通系统运行性能的有效手段。近年来,越来越多的交通传感设备(如交通摄像头、环形线圈、微波检测器等)被部署在城市道路上,这些交通传感设备采集了大量的交通数据,使得智能交通系统逐渐从技术驱动为主演化为数据驱动为主[1]。因此,从交通大数据中挖掘交通运行模式成为了一个热门的研究领域。其中,城市热点交通线路(以下简称为“热点线路”)是一类典型的交通运行模式,指在固定时间段内大量车辆共同行驶的道路路段序列[2, 3]。热点线路可支持许多潜在的应用,如路线规划[4]、交通流预测[5]、拥堵预测[6]、城市规划[7]等。
然而,与单一车辆的行驶模式[8]不同,热点线路考虑的是城市车辆的总体流动规律。由于单一车辆行驶的不确定性,大部分车辆的行驶轨迹只贡献热点线路的一部分,只有极少数车辆的行驶轨迹能完整覆盖一条热点线路。因此,现有轨迹模式挖掘算法要求车辆轨迹完整覆盖行驶模式,则通常只能挖掘出很短的热点线路,对城市交通总体规划的指导意义不大。
针对热点线路挖掘问题,大多现有工作采用细粒度的车辆GPS轨迹数据[7, 9-12]。然而,由于普通车辆的GPS轨迹数据基本无法获得,现有工作均采用浮动车辆(如出租车、公交车)的GPS轨迹数据。由于浮动车辆的占比很小,其产生的轨迹数据对城市道路的时空覆盖非常有限。因此,从浮动车辆轨迹数据中挖掘出的热点线路通常难以反映真实的城市交通状况。另一方面,交通摄像头作为智能交通系统的重要基础设备,由于其非侵入的特性,已经被大量地部署在城市道路上,并被用作车辆行驶轨迹采集的最主流设备[1]。交通摄像头最主要的功能为车牌识别,由于交通摄像头具有空间属性,车牌识别具有时间属性,则一辆车的轨迹可被重构为该车辆按时间顺序经过的交通摄像头的序列[13]。鉴于交通摄像头的高覆盖率,从车牌识别时空数据中挖掘热点线路是更为合理的思路。
然而,基于车牌时空数据的热点线路挖掘比一般的交通模式挖掘更具挑战,原因如下:首先,由于建设成本的原因,交通摄像头通常无法覆盖所有的道路路段。其次,由于技术限制的原因,车牌识别经常存在遗漏和错误等问题。这些不确定性问题导致现有交通模式挖掘方法无法有效挖掘出热点线路,原因在于现有方法大多将车辆轨迹映射到道路网络上,在此基础上进行交通模式挖掘[2, 14-16]。然而,由于交通摄像头的空间稀疏性和识别不确定性,基于车牌时空数据重构得到的车辆轨迹中的连续2个交通摄像头可能间隔多个道路路段,导致难以进行道路匹配。另外,大部分车辆的行驶轨迹只占热点线路的部分。通常情况下,一辆车会在一条热点线路的起点和终点之间驶入和驶出,而大量车辆在该起点和终点之间的轨迹共同构成了这条热点线路。因此,现有交通模式挖掘算法(如聚类算法[17, 18]、序列模式挖掘算法[19, 20])只能挖掘出大量很短的热点线路,对城市交通总体规划的指导意义不大。交通模式挖掘算法通常会产生大量的挖掘结果,而这些结果中很多是相似和冗余的,导致决策人员难以从中发现最有价值的信息。
针对上述问题,本文提出了一种从车牌时空数据中有效挖掘热点线路的方法。该方法首先从重构的车辆轨迹数据中挖掘出子模式,并基于一个双向树数据结构拼接这些子模式以形成候选热点线路(该步骤称为热点线路挖掘)。然后采用聚类排序算法从候选热点线路中挑选出代表性热点线路(该步骤称为热点线路压缩)。本文的主要贡献如下。(1) 提出了一种无需道路网络支持的、基于车牌时空数据的热点线路挖掘方法。(2) 提出了一种双向树数据结构,用于拼接短的子模式以形成长的热点线路。(3) 提出了一种聚类排序算法,用于发现代表性热点线路。(4) 基于杭州市真实车牌时空数据进行了实验。
1 相关工作
现有工作主要采用数据挖掘技术从各类交通传感设备数据中挖掘交通模式。例如,Inoue等人[15]和Banaei-Kashani等人[16]从环形线圈产生的交通流数据中挖掘每条道路的交通流模式。Yuan等人[9]从浮动车辆轨迹数据中挖掘行驶模式,并用于最快路径检索服务。Zheng等人[10]从浮动车辆轨迹数据挖掘两类出行模式即热点区域和热点路线,并基于这两类出行模式分析居民出行的时空规律。Janecek等人[21]基于蜂窝网络数据对交通状态进行推断,包括行驶时间和交通拥堵等。
现有基于车牌时空数据挖掘的工作大多集中在交通流估计方面。例如,Castillo等人[13]利用车牌时空数据和道路车流数据对车辆轨迹进行重构,在此基础上构建车辆轨迹矩阵。Mínguez等人[22]对交通摄像头的数量和部署位置进行优化,在此基础上对OD(起点-终点)矩阵进行估计。然而,这些方法粒度较粗,只能对某条道路上或某对起点终点间的交通流进行总体统计,无法估计车辆的细粒度行驶模式,从而无法支持热点线路的挖掘。
现有细粒度行驶模式挖掘方法大多基于细粒度的轨迹数据(如GPS轨迹数据)。例如,Yao等人[17]提出了一个基于深度学习的轨迹聚类算法,首先提取时空不变特征,然后基于seq2seq模型对轨迹数据进行表征,最后在深度表征基础上实现聚类。Cao等人[19]将行驶模式元素定义为频繁路段周围的区域,在此基础上提出了一种基于子串树数据结构的行驶模式挖据算法。然而,聚类算法或序列模式挖掘算法挖掘出的行驶模式通常较短,难以对热点线路进行有效表征,且这些工作挖掘出的基本上都是单一对象的行驶模式。实际上,单一车辆的行驶模式通常只占热点线路的一小部分[2]。例如,城市中可能存在一条从居住区到工作区的热点线路,但通常大部分车辆不会行驶整条热点线路,而是在这条热点线路的中间某处驶入、某处驶出。
与本文工作最相关的是Li等人[2]提出的FlowScan算法。FlowScan算法采用一个密度聚类算法在道路网络中对热点道路路段进行扩展,从而形成热点线路。然而,FlowScan算法采用的是细粒度车辆轨迹数据,不适应车牌时空数据。首先,由于交通摄像头的空间稀疏性和识别不确定性,可能存在部分道路路段未部署交通摄像头,或未能正确识别部分行驶车辆的车牌,导致重构得到的车辆轨迹数据难以准确映射到道路网络中。其次,FlowScan算法会产生大量的热点线路,其中某些是相似和冗余的,导致决策人员难以从中发现最有价值的信息。
2 问题定义
定义1车牌时空数据。交通摄像头可识别过往车辆的车牌并记录时间。因此,车牌时空数据可被定义为一个三元组的集合LD={(Ik,Ck,Tk)},Ik为车辆k的车牌号,Ck为记录Ik的交通摄像头的编号,Tk为Ck记录Ik的时间。其中,Ck代表了空间属性(每个交通摄像头的经纬度位置已知),Tk代表了时间属性。
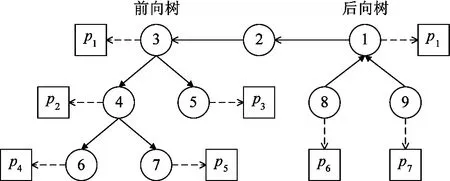
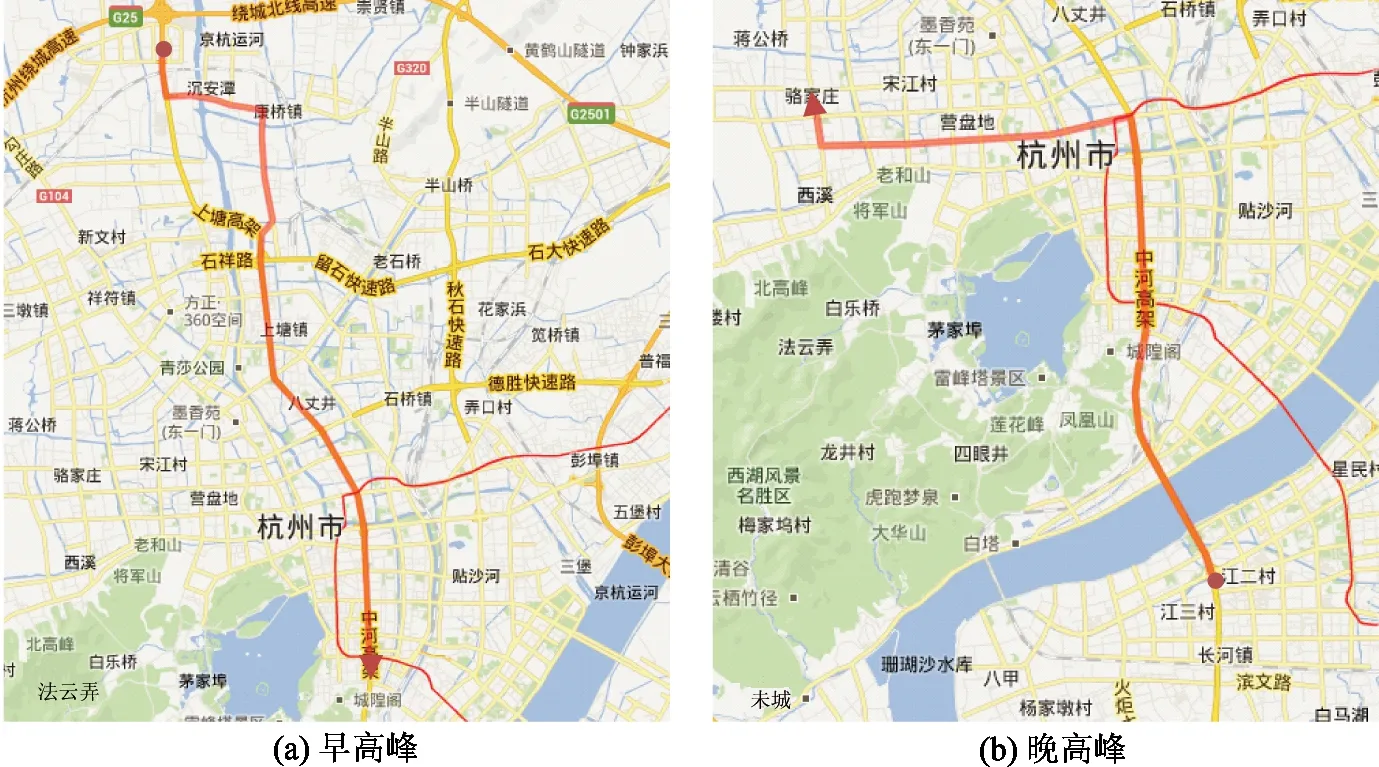
定义2车辆轨迹。对车牌时空数据进行交叉检索和重构可得到每辆车的轨迹。一辆车的轨迹可被定义为一个序列VT= 定义3热点线路。一条热点线路被定义为一个序列R= 由于单一车辆行驶的不确定性,现有基于轨迹模式挖掘算法的热点线路挖掘方法通常只能挖掘出很短的热点线路。如图1(a)所示,若要求每个行驶模式至少有4条轨迹支持,则现有轨迹模式挖掘算法只能挖掘出R1、R2和R3这3条较短的热点线路。针对此问题,弱化现有轨迹模式挖掘算法的限制,将热点线路定义为一个道路路段的序列,该序列的指定长度的任意子序列均共享大量共同车流。如图1(b)所示, 图1 热点线路挖掘问题 由于交通摄像头的空间稀疏性和识别不确定性,重构得到的车辆轨迹无法准确映射到道路网络。因此,本文提出了一种无需道路网络的从车牌时空数据中挖掘热点线路的方法,该方法分为子模式挖掘和子模式拼接2个步骤。 子模式挖掘工作流程如下,给定时间段[Ts,Te],采用子串模式挖掘算法从车辆轨迹数据中挖掘出长度为K的子串模式。子串和子序列是最具代表性的2类模式,而子串模式与子序列模式的不同在于,子串模式要求模式中连续的元素在原始序列中也是连续的,而子序列模式只要求模式中连续的元素在原始序列中顺序一致(可以不连续)。之所以使用子串模式,是考虑到车辆在空间中的运动必须是连续的[19]。采用N-Gram算法挖掘子串模式:采用一个哈希表存储每个子串模式和其对应的支持度(即该子串模式出现的次数)。对每条车辆轨迹VT,算法读入连续的K个元素<(C1,T1),…,(CK,TK)>。如果T1≥Ts且TK≤Te(即轨迹发生在指定时间段内),则将 实际操作中,核心参数K和minSup的设置非常重要。一方面,参数K设置的过大会导致难以发现足量的子模式,而设置的过小则对热点线路的要求过低(容易导致产生过多无意义的热点线路)。另一方面,参数minSup的设置需要考虑实际的交通流量。在交通流量较大的区域中,minSup也应设置的较大。然而,由于不同区域的实际交通流量差异较大,导致minSup的绝对数值难以统一设置。因此,通过设置一个(0, 1)的相对数值来估算minSup的绝对数值,方法如下:首先,提取所有长度为2的子模式并计算它们的支持度。然后,绘制所有长度为2的子模式支持度的CDF(累积分布函数)曲线。最后,设置一个minSup的相对数值rMinSup(0 iCDF(p)=inf{x∈R:p≤CDF(x)} (1) 子模式拼接工作流程如下。提出了一种将短的子模式拼接成长的热点线路的算法。算法流程如算法1所示,其主要工作为基于前向拼接和后向拼接概念构造一棵双向树。首先,基于一个种子子模式(第3行),算法调用递归函数不断将其他子模式拼接到种子子模式上(第6行),形成一棵双向树(包括一棵前向树和一棵后向树)。然后,拼接各前向树分支和各后向树分支,得到候选热点线路(第7~9行)。 定义4前向拼接和后向拼接。给定一个长度为K的子模式P0,另一个长度为K的子模式P1若满足:P1的长度为K-1的前缀可与P0的长度为K-1的后缀完全匹配,则P1可与P0前向拼接。另一个长度为K的子模式P2若满足:P2的长度为K-1的后缀可与P0的长度为K-1的前缀完全匹配,则P2可与P0后向拼接。 算法1子模式拼接算法输入:长度为K的子模式集合PS输出:候选热点线路集合RS1.将PS复制到TS2.while TS不为空do3.从TS中找出支持度最大的子模式P4.将P从TS中删除5.构建2个树节点fn(对应P.CK)和bn(对应P.C1)6.运行函数ForwardExpand(fn)和BackwardExpand(bn)7.for以bn为根节点的后向树的每个分支bbdo8.for以fn为根节点的前向树的每个分支fbdo9.将bb的反转, 算法1续 下面给出一个实例对子模式拼接算法进行进一步说明。给定7个长度为3的子模式P1= <1, 2, 3>,P2= <2, 3, 4>,P3= <2, 3, 5>,P4= <3, 4, 6>,P5= <3, 4, 7>,P6= <8, 1, 2>和P7= <9, 1, 2>,其中P1的支持度最大,则构造的双向树如图2所示(其中,树节点用圆形代表,而正方形代表的是树节点对应的子模式)。从该双向树中,通过拼接前向树分支和后向树分支,可以提取出6个候选热点线路,即R1= <8, 1, 2, 3, 5>,R2= <9, 1, 2, 3, 5>,R3= <8, 1, 2, 3, 4, 6>,R4= <8, 1, 2, 3, 4, 7>,R5= <9, 1, 2, 3, 4, 6>和R6= <9, 1, 2, 3, 4, 7>。 图2 子模式拼接实例 热点线路挖掘步骤会产生大量候选热点线路,其中存在大量相似和冗余,导致决策人员难以从中发现最有价值的信息。以图2为例,仅7个子模式就会产生6个候选热点线路,而真实交通数据中通常可挖掘出海量的子模式,导致产生的候选热点线路过多。此外,从图2中产生的候选热点线路中可发现,许多候选热点线路非常相似(如R1和R2,R3和R4,R5和R6)。针对此问题,提出了一个聚类排序算法,用于对候选热点线路进行压缩,主要包括聚类和排序2个步骤:首先,聚类步骤对所有候选热点线路进行聚类。然后,排序步骤从每个聚类中挑选出最具代表性的候选热点线路。 在聚类步骤中,基于最长公共子序列算法定义候选热点线路间的相似度,候选热点线路Ri和Rj的相似度计算方法如式(2)所示。 S(Ri,Rj)=max{S(Ri→Rj),S(Rj→Ri)} (2) (3) 其中,LCSS(Ri,Rj)为Ri和Rj的最长公共子序列。式(2)中使用了S(Ri→Rj)和S(Rj→Ri)的最大值作为Ri和Rj的相似度,其目的是为了更有利于较长的候选热点线路。这种情况下,较长的候选热点线路更容易与其他的候选热点线路产生高相似度,使得较长的候选热点线路倾向于将较短的相似候选热点线路吸收进同一聚类,并更容易被挑选为聚类中的代表性候选热点线路。 在此基础上,采用Affinity Propagation聚类算法[23]对所有候选热点线路进行聚类处理。Affinity Propagation聚类算法的优势在于不需要预先设定聚类的数量,这符合热点线路数量通常未知的现实情况。 在排序步骤中,从每个聚类中挑选出最具代表性的候选热点线路。为此,给定一个聚类,计算其中每个候选热点线路的权值,而热点线路权值由表征度权值和重要度权值2部分构成。 其中,表征度权值用于指示一个候选热点线路代表其他候选热点线路的能力,而候选热点线路Rj代表候选热点线路Ri的能力可由S(Ri→Rj)判断,即Ri和Rj的最长公共子序列能较多覆盖Ri。因此,基于式(4)对候选热点线路Rk的在聚类RC中的表征度权值进行量化。 (4) 另一方面,重要度权值用于指示一个候选热点线路是否经过城市的重要区域。综合考虑以下假设对候选热点线路的重要度权值进行量化。(1) 如果一个候选热点线路包含的交通摄像头更重要,则该候选热点线路更重要。(2) 如果一个交通摄像头被包含在更重要的候选热点线路中,则该交通摄像头更重要。(3) 一个交通摄像头的重要度可由其检测到的交通流量进行量化。 上述假设中,假设(1)和假设(2)表明候选热点线路和交通摄像头间存在互增强关系。这与网页排序算法HITS中定义的hub页和authority页间的关系类似,而HITS算法正是利用这种互增强关系计算网页的重要度权值。因此,将交通摄像头看成hub页,将候选热点线路看成authority页,然后基于HITS算法的思想计算候选热点线路的重要度权值。给定n个交通摄像头和m个候选热点线路,构建一个m×n的矩阵MRC(其中MRC[i,j]指示第i条候选热点线路是否包含第j个交通摄像头)。假定PC和PR分别代表hub分数向量和authority分数向量,则可采用幂迭代算法计算最终的PC和PR。为将假设(3)反映在算法里,在每轮幂迭代中,authority分数(代表候选热点线路的分数)会按照交通摄像头检测到的交通流量成比例地传播到hub分数(代表交通摄像头的分数)中,即交通摄像头检测到的交通流量作为分数传播的一个因子。算法2展示了基于幂迭代的候选热点线路重要度权值计算算法,其中VT为一个n维的列向量(VT[k]代表第k个交通摄像头历史上在指定时间段内检测到的平均交通流量)。 图3给出了一个候选热点线路权值计算的实例。给定3条候选热点线路(R1,R2和R3)和4个交通摄像头(C1,C2,C3和C4),假定R1,R2和R3属于同一聚类,则R1,R2和R3的表征度权值分别为0.833,0.5和0.583。而当执行候选热点线路重要度权值计算算法后,R1,R2和R3的重要度权值分别为0.363,0.248和0.389。因此,R1具有最高的表征度权值(由于R1与其他候选热点线路的交叠部分最多),而R3具有最高的重要度权值(由于R3经过最重要的交通摄像头C4)。 算法2候选热点线路重要度权值计算算法输入:关联矩阵MRC,交通流量向量VT输出:所有候选热点线路的重要度权值1. 初始化P(0)C=[1,1,…,1︸n]T,P(0)R=[1,1,…,1︸m]T2. while算法未收敛do3. P(t+1)C=MTRC·P(t)R·VT, P(t+1)R=MRC·P(t+1)C// 第t轮迭代4. 将P(t+1)R归一化5. 将最终PR输出为重要度权值向量 图3 一个候选热点线路权值计算的实例 得到聚类中每个候选热点线路的表征度权值rs和重要度权值is后,可对2个权值进行加权求和得到候选热点线路权值ws(如式(5)所示),然后从每个聚类中挑选出权值最高的候选热点线路作为最终的热点线路,而这些最终的热点线路可按照其包含的车流量进行倒排排序。 ws=α×rs+(1-α)×is (5) 采用杭州市的真实车牌时空数据集进行实验,该数据集包含了部署在杭州市区的821个交通摄像头,数据集时间跨度为2012年6月1日至2012年7月4日,以及2018年11月5日至2018年12月1日。实验仅考虑工作日(总共44 d)。最终数据集包含了195 579 733个车牌识别记录,数据集中每天平均车牌识别记录数为4 444 993(标准差为457 313),每天平均检测到的车辆数为724 636(标准差为73 096)。 基于对该数据集的统计分析,发现交通摄像头存在较高的空间稀疏性和识别不确定性。如图4所示,当缩小地图后,可以发现有很多道路未部署交通摄像头。此外,该数据集中存在23 365 567条车牌识别记录是错误的(大概占总车牌识别记录数的12%)。再次,交通摄像头还有可能未检测到经过的车辆。 图4 交通摄像头的空间稀疏性 本文提出的方法包括2个核心参数为K和minSup,这2个核心参数的设置直接影响方法的性能。其中,参数K必须大于等于3,这是由于长度小于3的子模式无法被拼接(由于交通摄像头基本都部署在道路路口,因此2个交通摄像头构成一条道路路段,而长度为2的子模式只包含一条道路路段)。另一方面,参数minSup的设置需要考虑实际的交通流量。 在以下实验中,将时间段设置为08:00-09:00(即早高峰)。图5显示了调整参数K和rMinSup后方法性能的变化,这里方法性能的考查指标包括挖掘出的热点线路的平均长度、平均车流量、最小车流量和数量。其中,将一条热点线路包含的车流量计算为其包含的长度为2的子模式的平均支持度。通常情况下,希望挖掘出的热点线路的平均长度更长、车流量更大。如图5(a)和图5(b)所示,增大K和rMinSup后,热点线路平均长度显著缩短,而平均车流量少量增加。这说明K和rMinSup应该设置的小一些。然而,将K和rMinSup设置的过小会引发以下问题:挖掘出的热点线路包含的车流量过小(如图5(c)所示)或挖掘出的热点线路数量爆炸性增加(如图5(d)所示)。因此,将这2个参数设置如下:K=3,rMinSup=0.955(对应的minSup绝对数值为172)。 图5 参数K和rMinSup对方法性能的影响 将本文提出的方法(称为OurMining)与以下方法进行比较评测。 (1) CloSpan。基于CloSpan算法[24]挖掘子模式,并基于第4节提出的方法对子模式进行压缩得到最终的热点线路。 (2) FlowScan。基于FlowScan算法[2]挖掘候选热点线路,并基于第4节提出的方法对候选热点线路进行压缩得到最终的热点线路。FlowScan采用一个密度聚类算法在道路网络中将道路路段扩展到其邻接道路路段以形成热点线路。道路路段r的邻接道路路段集RS满足:r与RS中任一道路路段间的最短道路网络距离小于Eps。然而,基于车牌时空数据重构得到的车辆轨迹无法进行道路匹配。因此,将邻接道路路段概念修改为邻接交通摄像头概念,即交通摄像头c的邻接交通摄像头集合CS满足:c与CS中任一交通摄像头的直线距离小于dEps。在此基础上,采用FlowScan算法将交通摄像头扩展到其邻接交通摄像头以形成热点线路。 (3) DirectMining。基于第3节提出的方法挖掘候选热点线路,不对候选热点线路进行压缩,而仅基于包含的车流量对候选热点线路进行简单倒排排序。 设置α= 0.5,并将热点线路的平均长度和最大长度、top-N热点线路的城市车流覆盖率作为评价指标。其中,top-N热点线路的城市车流覆盖率为排序最靠前的N个热点线路所包含的车流量(在本文中,即排序最靠前的N个热点线路所包含的长度为2的子模式的支持度总和)占城市总车流量(在本文中,即所有长度为2的子模式的支持度总和)的比例。参数设置如下:K= 3(针对OurMining和DirectMining),rMinSup=0.955(针对OurMining,CloSpan,FlowScan和DirectMining),dEps=1 000~5 000 m(针对FlowScan,对应FlowScan_1000~FlowScan_5000)。此外,为保证子模式元素的空间连续性,将CloSpan算法中模式元素的最大间隔限制为3。 实验结果如图6所示,可以发现以下现象。第1,CloSpan仅能挖掘出很短的热点线路,这是由于序列模式挖掘算法要求支持某个序列模式的车辆轨迹必须完全覆盖这个序列模式,而通常一辆车的轨迹只能覆盖热点线路的一部分。第2,DirectMining能够挖掘出最长的热点线路,但其top-N热点线路的城市车流覆盖率较低(即使N较大时)。这是由于当不进行热点线路压缩时,大量热点线路存在高度的重叠,特别是排序靠前的热点线路(由于这些热点线路基本上都集中在城市最繁忙的一、两条线路上),因此增大N也无法提升top-N热点线路的城市车流覆盖率。第3,当dEps设置的较低时,FlowScan的性能较差,且FlowScan的top-N热点线路的城市车流覆盖率低于OurMining,特别是N较大时。对实验结果进行分析后发现,FlowScan可发现高质量的热点线路,但其召回率较低,这主要是由于邻接交通摄像头的不确定性造成的。首先,基于直线距离定义邻接关系不合理(原始FlowScan是基于道路网络距离定义道路路段的邻接关系)。例如,同样是部署在一条道路路段两端的交通摄像头,当该道路路段是一条城市高速路时,其直线距离会很大,导致算法认为其不存在邻接关系。其次,FlowScan的密度聚类算法不适应车牌时空数据。FlowScan的密度聚类算法挑选初始种子道路路段的方式为该道路路段包含至少minSup起始车流量或minSup终止车流量,而后者在车牌时空数据中无法考查。综上,OurMining可发现质量更高的热点线路(长度更长,且更少的实例就能覆盖更多的城市车流)。 图6 不同方法的性能比较 图7展示了2条挖掘出的热点线路(图7(a)展示了从早高峰时间段中挖掘出的排名第1的热点线路,而图7(b)展示了从晚高峰时间段中挖掘出的排名第1的热点线路)。图中热点线路由一个折线代表(其中,圆点代表起点,箭头代表终点),2个交通摄像头之间的折线为其在道路网络中的最短路径。由图7可以看出,杭州市早高峰最繁忙的热点线路为由城市北部去往城市中心,而晚高峰最繁忙的热点线路为由滨江区穿越城市中心高架路去往城市西部居住区。 图7 热点线路可视化 本文提出了一种从车牌时空数据中挖掘热点线路的方法。该方法首先挖掘和拼接子模式以形成候选热点线路,然后对候选热点线路进行聚类和排序以得到代表性热点线路。基于杭州市真实车牌时空数据的实验结果表明:与现有方法相比,本文提出的方法可以发现更有价值的热点线路(长度更长,且较少的实例就能覆盖较多的城市车流)。3 热点线路挖掘



4 热点线路压缩


5 实 验
5.1 数据集

5.2 调参实验


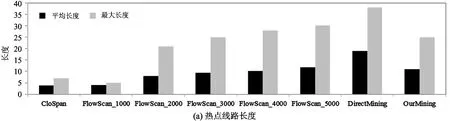
5.3 方法评测

6 结 论
猜你喜欢
中国交通信息化(2022年9期)2022-10-28 06:14:40加油站服务指南(2022年6期)2022-07-28 06:07:02成都信息工程大学学报(2022年3期)2022-07-21 09:35:04汽车工程师(2021年12期)2022-01-18 06:02:43沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46车迷(2019年10期)2019-06-24 05:43:28快乐语文(2018年7期)2018-05-25 02:32:00自动化学报(2017年7期)2017-04-18 13:41:02汽车维修与保养(2015年8期)2015-04-17 03:32:59
