
面向各类攻击的差分隐私保护模型
2020-08-11 16:07黄晓黄喻先
网络安全技术与应用 2020年8期
◆黄晓 黄喻先
(1.中国移动通信集团江苏有限公司 江苏 210012;2.南京邮电大学 江苏 210023)
1 引言
约翰●奈斯比在《大趋势》中提到:“人们正被数据淹没,却又饥渴于知识。”数据库技术的成熟使得数据量以指数规模增长,同时,高带宽、低延时、高稳定的5G技术使得海量数据得以高速传输和集中处理。它们的延伸价值将体现在通信领域的下一个金矿——数据挖掘之中。因此,无论是传统的零售业还是新兴的电子商业,人们都迫切地希望对数据去粗取精,揭示其中的潜在价值。
然而,数据集中通常包含着许多个人的隐私信息。例如,电商企业收集的客户交易数据集中包含着个人的消费习惯,这些信息会随着数据的共享和挖掘而泄露。因此,如何在使用数据的同时保护用户的敏感信息成了当前信息安全领域亟待解决的问题。
为了应对各类攻击,提出了三种隐私保护的方向:数据失真[1]、数据加密[2]和限制发布[3]。数据失真是在数据中添加噪声,使敏感数据失真但同时保持其余数据不变的方法。这是以牺牲数据的准确性和真实性为代价,从而达到保护隐私的目的。数据加密通过将数据挖掘算法与加密算法结合起来,保证了数据的机密性,但面对海量数据时加密算法计算开销极大。限制发布技术则是对原始数据的选择性发布。当前这类技术的研究集中于数据匿名化,比如隐藏数据中的某些标识符属性(例如姓名、ID号等),使得敏感信息泄露被控制在一个极小的范围内。但是,由于新型的网络攻击手段层出不穷,传统的限制发布技术已无法满足隐私保护的需要。
因此,鉴于传统隐私保护方法的不足,研究人员试图寻求一种有效的并且可以被证明的隐私保护模型,能够抵御当下各种形式的攻击。差分隐私[4](Differential Privacy,DP)的提出使得这种设想逐渐成了可能。
2 数据集公开时面临的隐私攻击
2.1 数据集的基本概念
数据集[5]可以理解为包含若干个记录的数据文件,每条记录均描述了一个实体的多方面属性。根据特征的不同,我们可以将属性分为以下四类:
(1)个体标识符:例如姓名、身份证号等可以唯一标识一个个体的属性。
(2)准标识符:与外部信息链接从而可标识个体身份的属性(单个准标识符不能定位个体,但是多个准标识符链接后可用来潜在的识别某个体),如图1所示,在学生学籍信息数据集和学生体检信息数据集中,班级、性别、出生日期都不能直接确定学生身份,而它们的链接组合可以基本确定某个学生身份。
(3)敏感属性:数据挖掘时需要被保护的隐私信息,例如是否患病,薪资等信息。
(4)非敏感属性:可以公开的属性,又称为一般属性。
2.2 链接攻击
知己知彼,百战不殆。只有深入理解攻击者的攻击手段,我们才能提供更有效的隐私保护。链接攻击[6]是目前攻击者常用的隐私攻击手段,曾给美国在线公司带来了巨大的亏损。

图1学生学籍信息数据集和体检信息数据集的链接
美国在线(American Online AOL)是一家著名的因特网服务提供商。2006年,为了支持学术研究,AOL公开了近三个月,总共2000万条的匿名搜索记录。在这些数据中,AOL使用匿名ID来替代用户的真实姓名。然而,纽约时报发现用户的查询记录中包含着一些可以揭示他们真实身份的潜在信息,将这些潜在信息与其他可获得的数据相结合,就能找到部分用户的真实身份。例如,某位用户的搜索记录中包含着“孕期的注意事项”、“A医院的预约方式”、“B地一周内的天气情况”。那么我们就可以基本确定该用户是一位生活在B地,最近去过A医院的孕妇。倘若再结合A医院的病人数据集,并逐一排查,就能确定该用户的真实身份。最终由于这次隐私泄露,AOL被起诉,高层集体离职,赔偿了500多万美元。
通过AOL的例子,我们不难发现,倘若在发布数据之前仅仅删除或匿名用户的身份属性(即个体标识符),并不能保护用户的个人隐私。攻击者可能将该数据集与其他公共数据信息联系起来,确定个体的身份。这被称作数据挖掘中的链接攻击。
3 差分隐私理论的研究背景
3.1 传统隐私保护理论的缺陷
K-anonymity[7](k-匿名化)是由Samarati和L.Sweeney于1998年提出的一种数据匿名化方法,它在隐私保护领域有着深远的影响。K-anonymity的基本思想是对数据集里某些准标识符进行泛化处理,使得所有记录被划分到若干个等价类(Equivalence Group)中,每个等价类中的记录要大于等于K条。例如,学生A的成绩为98分,学生B的成绩为96分,为了实现成绩这一准标识符的泛化,我们可以将具体成绩修改为成绩区间,即学生A、B都处于[95,100]这一等价类中,从而实现记录的隐藏。
但是,后续的研究发现,K-anonymity等传统隐私保护模型存在两个主要缺陷。其一,这些模型的可靠性受制于攻击者所掌握的背景知识(攻击者可获得的外部信息),而背景知识的大小很难被充分定义。其二,传统的隐私保护模型无法严格地证明其隐私保护水平。所以,当隐私保护模型中的部分参数改变后,我们难以对其隐私保护水平进行定量评估。
3.2 差分隐私理论的提出
差分隐私[8]一词最初是由Dwork在2006年提出的。Dwork通过严格的数学证明对隐私保护进行新的定义。在此定义下,单条记录的变化对于数据集的整体计算结果是不敏感的,即添加或删除一条记录时隐私泄漏的风险被控制在非常小的范围内。
差分隐私能够解决传统隐私保护模型的两个不足。首先,差分隐私保护是以攻击者的最大背景知识为前提的。最大背景知识是攻击者可以获得的目标个体的所有相关信息。而事实上,攻击者所掌握的外部信息总是远小于最大背景知识的。
其次,差分隐私有着坚实的数学基础。其中涉及的参数,例如隐私预算、全局敏感度等都是可量化的。因此,我们可以通过这些参数进行隐私水平的比较。
如今,通过不断地发展,差分隐私理论的研究越来越成熟,广泛应用于数据发布、数据挖掘、人工智能、机器学习等领域。
4 差分隐私保护模型
4.1 基本定义
差分隐私保护[9]就是要确保任何一个记录无论在不在数据集中,对查询结果几乎没有影响。也就是说,如果有两个只相差一条记录的数据集,分别对它们进行相同的查询操作,那么查询结果相同的概率为100%。
定义1(邻近数据集)设数据集D和D'具有相同的属性结构且,数据集对称差DΔD'=1,即这两个“数据集”只相差一条记录,则称“数据集”D和D'为邻近数据集。
定义2(差分隐私)给定邻近数据集D和D',设:存在随机算法A,Range(A)为A所有可能的输出结果,若算法A在数据集D和D'上任意输出结果O(O∈Range(A))满足下列不等式:
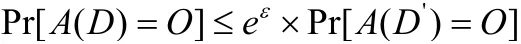
则称算法A满足 -ε差分隐私。其中Pr[·]为事件发生的概率,参数ε为隐私预算。ε越小,可添加的噪声越大,隐私保护的水平越高,但数据集的可用性会降低,因此ε的取值要综合考虑数据的安全性与可用性。
4.2 实现机制
差分隐私保护有两种常用的实现机制[10]:Laplace机制和指数机制。Laplace机制常用于输出结果为数值型的数据集的保护,而指数机制适用于非数值型的数据集的保护。
Laplace机制主要是通过向查询结果中添加服从Laplace分布的随机噪声。噪声的大小由查询函数的全局敏感度Δf和隐私预算ε共同决定。当添加Laplace噪声后,用户查询得到的结果将不再是一个固定值而是一个不确定的随机数,这个随机数的概率密度函数服从Laplace分布。
指数机制的关键在于打分函数的设计,根据打分函数对查询结果进行打分。设算法A的输入为原始数据集D,r∈Range是所有可能输出的结果,q为打分函数,q(D,r)表示得到的分数,用来评估输出值r的优劣程度,Δq为函数q(D,r)的敏感度。若算法A以正比于的概率从Range中选择并输出r,则算法A提供-ε差分隐私保护。
4.3 组合性质
倘若要解决一个复杂的隐私保护问题,并且为了保证多次调用后隐私预算仍有效控制在ε之内,我们常常要多次调用差分隐私保护模型。此时,我们可以用差分隐私保护的组合性质[11],合理地将预算分配到整个算法的各个步骤。
4.3.1 串行组合性质
设有n个随机算法A1,A2,…,An,它们的隐私预算分别为ε1,ε2,… ,εn,那么对于同一数据集D,它们的组合算法提供差分隐私保护。所以,如果对一个数据集调用多次差分隐私保护时,隐私预算为所有隐私预算的总和。
4.3.2 并行组合性质
设有n个随机算法A1,A2,…,An,它们的隐私预算分别为ε1,ε2,… ,εn,分别应用于不相交的数据集D1,D2,… ,Dn,它们的组合算法A(A1(D),A2(D),… ,An(D))提供maxεi-差分隐私保护。所以,如果对多个不相交数据集调用差分隐私保护时,隐私预算为其中的最大值。

图2差分隐私的组合性质
5 差分隐私的应用
(1)差分隐私在GPS轨迹数据上的应用
通过分析用户的汽车轨迹数据,我们可以获取到许多有价值的信息。例如,我们可以在轨迹热区点修建一些加油站和充电桩,既便利了用户,又能推动相关产业的发展。但是,GPS轨迹数据中包含着用户的位置信息,倘若不加以处理就将数据发布,攻击者可以轻易获取某个个体的行程路线,这会带来极大的安全隐患。因此,我们可以在GPS轨迹数据中加入符合Lapalce分布的随机噪声,使得处理后的数据满足差分隐私保护的要求,极大地提高了用户的位置隐私安全。
(2)差分隐私在网络浏览记录上的应用
随着互联网的普及,网络浏览记录成了人们最为重要的隐私区域之一。如果不加以保护,黑客可以通过对网络踪迹的数据挖掘,肆意地侵犯个体的生活隐私。早期的网络浏览记录的净化方法是匿名化处理,但是2.2节中AOL的例子告诉我们简单的匿名化处理不足以维护我们的信息安全,所以我们将差分隐私应用到了其中。数据发布者在数据公开之前可以根据敏感度在数据中加入噪声,使得单独删除每一条网络浏览记录对整体的统计结果不会产生影响,从而实现了差分隐私保护。
(3)差分隐私在电子购物中的应用
在线支付的成熟促使电子购物在人们生活中所占的比重越来越大。各个电子购物平台可以通过对用户购物记录的数据挖掘,做到商品的精准推荐,以此来扩大购买需求。对于消费者来说,商品推荐能够让他们在最短的时间内找到需要的商品。所以,对消费记录的数据挖掘是一个双赢的过程。但是,我们务必要重视购物记录的隐私保护,否则会适得其反。因此,我们可以对推荐系统的输入进行干扰,向其中加入高斯噪声,使其满足差分隐私保护的标准,然后实施常规的推荐算法。
6 总结与展望
差分隐私是一种高效且可以被证明的隐私保护模型,它考虑了攻击者最大的背景知识,以坚实的数学理论为支撑,通过参数量化隐私保护水平,弥补了传统隐私保护模型的缺陷,有着广阔的前景。本文从原理性质和实际应用的角度对差分隐私保护进行了叙述,希望能够为信息安全领域的学者提供参考价值。
猜你喜欢
数学杂志(2022年5期)2022-12-02
计算机应用(2022年8期)2022-08-24
湘潭大学自然科学学报(2022年2期)2022-07-28
现代电子技术(2022年11期)2022-06-14
新世纪智能(数学备考)(2021年5期)2021-07-28
台湾农业探索(2020年4期)2020-10-29
计算机系统应用(2020年8期)2020-03-22
台湾农业探索(2019年5期)2019-09-10
爱你·心灵读本(2018年6期)2018-09-10
爱你(2018年16期)2018-06-21
