
一种基于WSD层级记忆网络建模的文档表示方法
2020-08-07 10:06张柯文朱全银方强强马甲林成洁怡丁行硕
淮阴工学院学报 2020年3期
张柯文,李 翔,朱全银,方强强,马甲林,成洁怡,丁行硕
(淮阴工学院 计算机与软件工程学院,江苏 淮安 223005)
文档层级结构关系建模可以针对文档的词句级联的上下文信息进行文档表示,也是自然语言处理领域研究的基础。在过去的研究中,研究者们通过传统的机器学习方法进行文档建模表示,Wu等[1]通过凸松弛将特征变换与SVM学习相结合,以人工标注对训练数据集进行特征提取和学习构建文档模型,实现文档分类,Chen[2]提出改进TF-IDF用于处理包含大量新闻的新闻分类。Jian[3]提出的BOLS- SVM算法对于在线预测任务特别有用,这类方法在过去取得了显著的成果,然而性能却依赖于复杂的人工规则和特征工程。为解决该问题,研究者们采用深度学习进行文档建模,笱程成等[4]使用循环神经网络(Recurrent Neural Network,RNN)预测社交消息,通过记忆获取到的语义信息,可以捕捉到更广范围的特征信息,这些深度网络模型在训练过程中关注训练目标的特征信息,较传统方法而言取得了更好的效果。Tang 等[5]改进了门控循环神经网络实现文档建模来进行情感分析,通过双层Bi-GRU实现句间内在语义编码可以较好地捕捉句间语义信息。这些方法通常以句子作为输入,通过词向量关注训练目标的特征信息。然而,这种文档分类方法忽视了文档层级结构和上下文的语义关系。
因此,本文提出的文档表示算法主要是根据词句文档组成的层次关系,针对词句级联,从词到句通过Bert模型学习词向量中的语义信息,句到文档引入记忆网络获取句子之间的语义联系,实现文档分类。总体思路是:首先,通过Bert算法基于词向量得到相似句子文本的句嵌入矩阵,以获得词语之间语义信息;然后,将句子映射到句嵌入矩阵空间得到句子的向量化表示;最后,为保留文档内部语义联系,将文档分句后的序列数据输入Bi-LSTM(Bidirectional Long Short Term Memory Network,BiLSTM)模型中,获取每个句子的注意力权重,得到文档的向量化表示。本方法充分考虑到了词句级联的层次关系,增加文档建模内部的语义联系。对于类间数据相似性较高的文档分类更加准确,满足对文档模型高效的分类要求,在实际应用中具有一定的可行性。
1 相关技术
本文通过对文档预处理,以定长的句向量作为输入,引入Bert语言模型实现句子的向量化表示,通过Bi-LSTM获取句向量间的上下文关系,结合注意力机制保留句子之间复杂的语义关系,实现文档的篇章向量表示,进行文档分类。
1.1 文档预处理
数据预处理后数据质量的好坏影响整个自然语言处理系统的性能。中文文本不同于英文文本,在词与词之间没有明显的界限,通常有着不可分割的语义联系。唐明等[6]利用TF-IDF算法计算每篇文档中词的权重,并结合word2vec词向量生成文档向量,最后将其应用于中文文档分类。何炎祥等[7]通过卷积神经网络(Convolutional Neural Networks,CNN)来获取邻近词汇间的关联,注重捕捉局部间的特征。在这类词嵌入文档模型中,通常先对文档进行分词、去停用词等处理,利用结巴分词将文档切分成若干个有意义的词汇,同时过滤掉一些高频却没有意义的噪点。该处理虽然可以去除噪点对文档分类的影响,却忽视了词与词、句与句之间的语义联系,如前后文之间的因果关系等。本文利用文档层级结构的特点,以句子作为基本单元保留词句层级之间的语义关系。
1.2 Bert算法
文档向量化是文档表示的重要方式,将文档表示成机器学习能够处理和表达文档语义的向量。李双印等[8]提出了一种文档建模方法,设计一种能够同时利用单词和标签信息,以及自动利用标签种类信息,对半结构化文档进行有效的建模,实现文档的向量化表示,但这种方法很少考虑单个词对整篇文档的影响力。这种词嵌入的方法实现文档的向量化,忽略了词到句,句到文档的组成特点,不能充分获取文档的语义关系。
2018年 Google[9]发布了基于双向 Transformer 的大规模预训练语言模型(Bi- directional Encoder Representation from Transformers,Bert)可以较好地表示词和句子以理解其潜在的含义和关系,在情感分类、命名实体识别等任务中取得了很好的效果。Bert生成句向量的优点在于它可充分理解句意,并且排除词向量加权引起的误差。Bert模型使用三层嵌入层联合调节上下文对文本训练,很好保留上下文语义联系,其输入如图1所示。

图1 Bert输入表示
对于输入的文本数据将一对文本句标记为句子对。每个句子对被组合为一个序列,序列的第一个词以特殊的标记[CLS]表示,通过特殊标记[SEP]将每个句子分开。然后,将学习的每个句子分别嵌入到句子的每个标记中,构成句向量空间矩阵。通过数据映射得到句子向量,如图2所示。
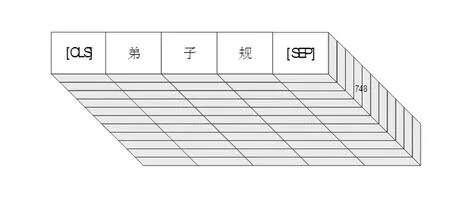
图2 句子向量表示图
1.3 双向长短时记忆网络
双向长短时记忆网络是对于长短时记忆网络LSTM的变体。LSTM是改进后的循环网络,有效解决了梯度爆炸或者梯度消失的问题。通过引入基于门控单元,在神经元中加入输入门、输出门、忘记门以及记忆单元来改善梯度消失的问题,同时也增强了句子序列之间的记忆程度。LSTM设计结构如图3所示。
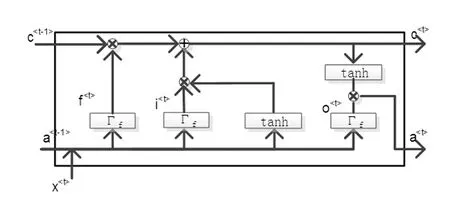
图3 LSTM网络单元结构图
神经元核心思想是通过采样前一时刻的上下文信息产生下一时刻的输出信息。假设t时刻的记忆内容c
α
(1)
该时刻的输出信息由LSTM循环单元的三个门控单元控制,分别是更新门、遗忘门和输出门。
Γu=δ(wu[α
(2)
Γf=δ(wf[α
(3)
Γo=δ(wo[α
(4)
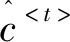
(5)
其中,wc和bc为记忆信息的权重矩阵和偏置项。因此,通过求解式(5),进而通过式(6)实现LSTM更新的记忆内容c
(6)
然而,LSTM对于序列数据只能从前往后传递序列信息,而对于基于上下文的文档表示序列,忽略了后文对语义之间的影响。Chen 等[10]使用大型语料训练Bi-LSTM模型,使用时,固定Bi-LSTM参数,获取Bi-LSTM的输出,经映射并加权相加后得到上下文信息,明显改善了NLP的技术发展水平。因此使用双向长短时记忆网络可较好地捕获文档句子前后之间的语义信息,其结构如图4所示。
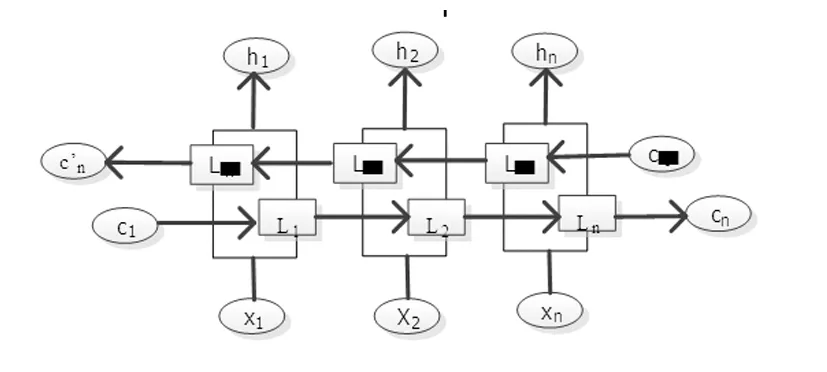
图4 BiLSTM结构图
最后输出结果为隐藏层单向和反向输出的拼接结果。其拼接公式如式(7)~(9)所示:
(7)
(8)
ht=Lt+L't
(9)
其中,Lt和L't分别为t时刻LSTM前向语义输出和后向语义输出,前向与后向的语义信息合并后得到包含序列上下文信息的t时刻隐藏层的语义输出ht。
1.4 注意力机制
注意力机制在自然语言处理的序列模型中取得了很大的成就。Zhao 等[11]引入注意机制进行神经机器翻译,Yang 等[12]提出了一个词典增强的LSTM 与注意力机制的目标依赖情感分类模型。在BiLSTM神经网络中结合Attention机制,在不同时刻计算输出特征向量的权重,突出句子的重要特征,从而增加文档表示之间的语义联系,使整个模型获得更好的效果,结构如图5所示。
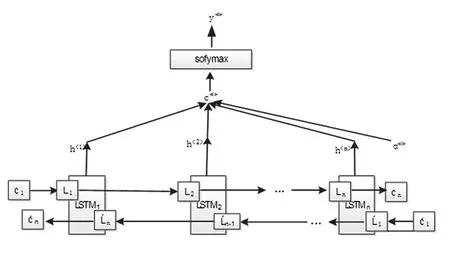
图5 BiLSTM+Attention结构
通过计算每时刻隐藏层的输出,在整个文本中向量表示的匹配得分占总体得分的比重,计算如式(10)~(12)所示,得到隐藏层输出的权重矩阵,从而获得文档句子之间的重要信息。
score(hi)=vTtanh(w1h1+b1)
(10)
(11)
(12)
其中,score(hi)为包含语义信息的hi输入到单层感知机中获得单篇文档隐藏层的输出,文档内各句子注意力权重矩阵ai由式(11)计算得到,通过权重矩阵ai与文本特征向量hi进行加权和,得到包含文档各句子重要性信息的向量ci。
2 WSD层级网络文档表示模型
文中分类方法采用了多种现有算法相结合的联合建模策略,对篇章级文档词句级联关系进行层级建模并进行分类。本设计的联合建模策略是基于Bert语言模型和深度神经网络进行的,其中,通过Bert建模实现句向量表示,利用双向长短时记忆网络和Attention机制保留句子之间复杂的语言关系。因此,考虑到算法的复杂度以及获取文档词句之间的语义联系,利用Bert算法和双向长短时记忆网络,合理分配算法比重进行语义建模,实现文档分类,其基于WSD层级记忆文档表示的分类机制如图6所示。算法流程包括四个部分,数据预处理,文档向量化,神经网络建模和分类训练与评估。
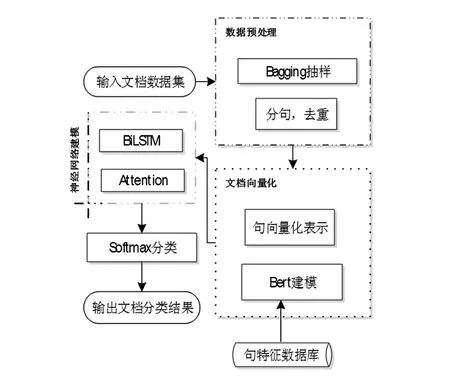
图6 WSD层级网络文档分类模型流程图
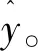
(13)
其中,w2和b2为向量化文档ci的权重矩阵和偏置项。具体步骤如表1所示:
文档表示为:Text={s1,s2,s3…sn}
数据集表示为:
D={Text1,Text2,Text3…Textm}

表1 基于WSD层级网络文档分类模型算法步骤
这种联合建模策略有效的利用了各类算法的优势进行文档层级结构建模,有效获取文档词句之间的上下文语义联系。通过Bert算法和双向长短时记忆网络结合注意力机制实现文档的向量化建模,对样本训练分类,有效加强了对分类样本词句内部的含义和语义关系的特征表示,提高了分类模型的准确率。因此,是一种较为理想的文档分类方法。
3 实验结果和分析
3.1 数据集
本实验采用THUCNEWS和CHEM&ENGNEWS两个数据集。
THUCNEWS是清华大学根据新浪新闻RSS订阅频道2005-2011年间的历史数据筛选过滤生成,包含74万篇新闻文档。其中,选取65 000条数据进行分类验证,将其以0.64,0.16,0.2的比例分为训练集,验证集和测试集。
CHEM&ENGNEWS是来自11个不同化工网站的新闻资讯,包含22万篇新闻文档,大小约为2GB,根据网站的来源分类成十个类别,包括Coal,Corportate,Social,Plastic,Industry,Mineral,Technology,ChemicalEquipment,Petrochemical和NatureG-as。在采样过程中与基于Bagging的集成学习方法结合,生成十个平衡数据集,64%的样本置于训练集中,剩下的抽取16%和20%分为验证集和测试集,从而降低方差防止过拟合,增强算法的鲁棒性。
3.2 实验过程
3.2.1实验设计
基于LSTM模型,对两种数据集进行新闻文档分类。为验证所提出WSD层级记忆网络建模算法对文档分类的可行性及优势,通过不同预训练算法包括TF-IDF、Word2vec等语言模型,对不同LSTM的变体进行大量对比实验。
3.2.2实验参数
针对新闻文档数据,对实验算法参数进行了合理设置,对比实验中Word2vec和TF-IDF算法中采用结巴分词[14],每篇文档文本基于词向量表示,其中词向量设置为200维的连续值,词量大小参数值为6000;本算法使用句向量表示文档,每篇文档固定长度设为30,最大句子长度为100,即长度超过100的句子基于特定目标词进行切割,长度不足100的以0向量填充句子的输入矩阵。在训练时对验证集准确率进行监控,当训练步数超过1000步没有改变时则停止训练,从而提高学习效率,以避免过拟合问题。
3.2.3评价指标
通过精确率P、召回率R和F1_score来评价分类模型效果[15]。准确率为被识别为该分类的正确分类记录数与被识别为该分类的记录数之比;召回率为被识别为该分类的正确分类记录数与测试集中该分类的记录总数之比,召回率是覆盖面的度量,衡量了分类器对正例的识别能力;F1_score就是精确值和召回率的调和均值,其公式为:
(14)
该评价指标适用于对来自相同源的不同数据集运行不同方法的情况,以及在相同数据上获得竞争结果的标准情况。
3.3 实验结果及比较
在THUCNEWS数据集中进行分类实验,实验分别通过TF-IDF,Word2vec以及本文所采用的Bert模型进行语言预处理,同时分别与传统机器学习算法SVM、传统LSTM以及基于注意力机制的BiLSTM算法结合,对实验结果进行分析,见表2。由于该数据集的分类较为精准,类间数据界限分明且数据量相对平衡,基于机器学习SVM算法上达到95.2%,在传统LSTM算法上准确率为94.8%,基于word2vec-LSTM算法准确率达96.53%,基于本文提出的组合算法准确率达95.07%。
在CHEM&ENGNEWS数据集进行实验,分别使用三种语言模型进行语言预处理,在LSTM及其变体进行实验比较,本算法和BiLSTM两种方法的训练loss曲线和accuracy曲线如图7所示,训练损失率在10%~15%,准确率在90%以上。进一步验证了该组合算法的准确性和稳定性,在类间数据相似度高且类间数据分布不平衡的数据集上同样取得了很好的效果。在此轮实验的验证基础上对10 998篇文档进行分类预测分析,如表4所示,完全正确分类的新闻文档数为10 550篇,错误数为448篇,准确率为95%,损失率为18%,实验分类准确率较高证明本算法在实际应用中的可行性,能够达到一定的分类精度。
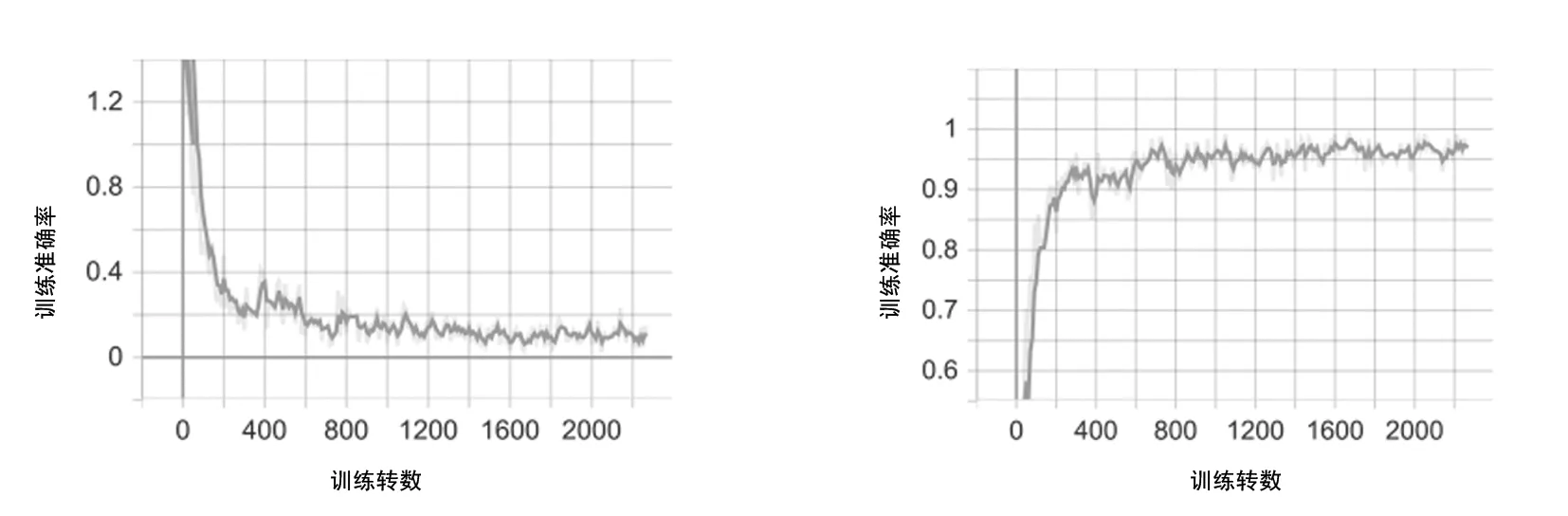
(a)WSD层级记忆网络算法训练loss曲线图 (b)WSD层级记忆网络算法训练accuracy曲线图
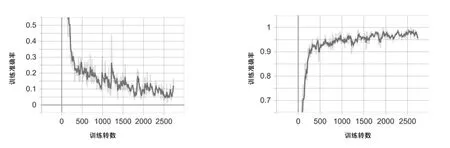
(c)BiLSTM训练训练loss曲线图 (d)BiLSTM训练accuracy曲线图图7 训练集日志
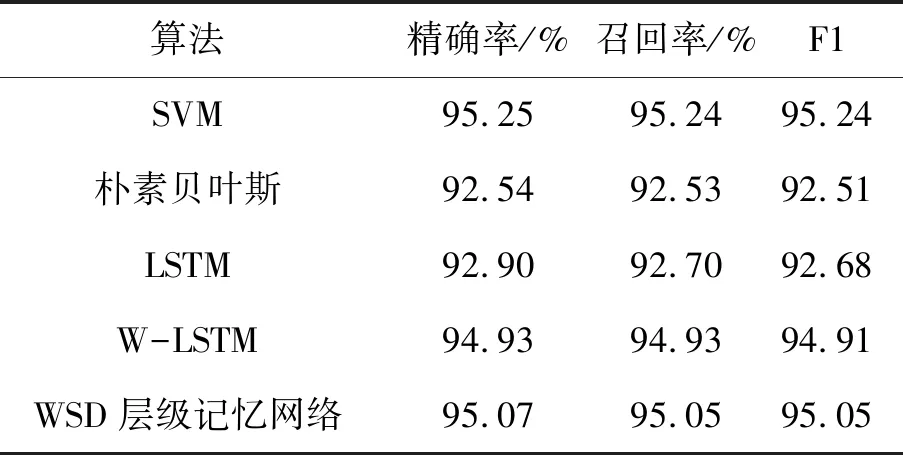
表2 THUCNEWS数据集实验比较
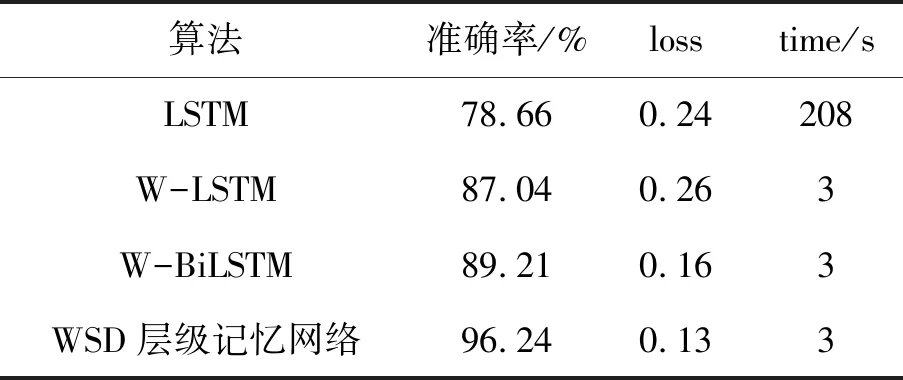
表3 CHEM&ENGNEWS数据集实验比较

表4 10 998篇CHEM&ENGNEWS文档分类实验结果
3.4 实验总结
通过两轮实验结果比较,对65 000篇分类较为精准的THUCNEWS文档数据集进行文档建模表示进行分类,基于WSD层级记忆网络文档建模表示的分类算法达到95.07%,比较其他四种分类较高的算法,分类准确率都达到了90%以上,证明了本算法在分类准确的同时,还保证了算法的稳定性;对于类间相似度较高的CHEM&ENGNEWS文档数据集实验中,本算法的分类准确率达到了96.24%,较其他4种参比方法提高7.06%~18.31%。表明本方法对于类间文本特征相似度很高的数据集具有很好的分类效果,在实际应用中具有一定的可行性。
4 结语
本文提出一种基于WSD层级记忆网络算法进行文档建模分类的方法,通过记忆网络学习获取上下文语义关系,克服了文档数据集类间相似性高及类间数据不平衡的问题。通过实验验证本算法在实际应用中的可行性,并能够达到一定的准确分类效果。本算法还存在问题需要进一步探讨,在句向量表示时基于Bert模型只能表示固定长度的句子,对于长句子损失较多,下一步工作将研究如何增强模型的鲁棒性,以使用不同长度的文档进行分类。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
客联(2022年3期)2022-05-31
中国典型病例大全(2022年13期)2022-05-10
中国新闻周刊(2021年26期)2021-07-27
航天工业管理(2020年9期)2020-12-28
军事运筹与系统工程(2020年1期)2020-09-11
开放教育研究(2020年2期)2020-03-31
廉政瞭望(2019年5期)2019-06-10
电脑爱好者(2017年7期)2017-05-06
长江学术(2016年4期)2016-03-11
