
数据驱动下的个性化自适应学习研究综述
2020-08-07 09:21张丽君梁婉莹
华南师范大学学报(自然科学版) 2020年4期
朱 佳,张丽君,梁婉莹
(1. 华南师范大学计算机学院,广州 510631; 2. 广州市大数据智能教育重点实验室,广州 510631)
移动互联网、智能教育的发展,极大地延伸了传统的学习空间和教育实践,促使教学模式和学习方式发生深刻变革[1]. 在人工智能(AI)、大数据、移动互联网和云计算等新兴技术的支持下,数据驱动下的个性化自适应学习日益成为教育界关注的焦点,并逐渐发展成为以大数据为基础的教育技术新范式[2-3]. 我国《教育信息化“十三五”规划》[4]、《教育信息化2.0行动计划》[5]、《新一代人工智能发展规划》[6]等文件均明确了个性化学习的重要性,指出“关注学习者不同特点和个性差异”“为每个学习者提供适合的教育”“探索在信息化条件下实现差异化教学、个性化学习、精细化管理、智能化服务的典型途径”等内容. 由此可见,关注个性化学习、尊重个体差异、促进学习者个性化发展,是我国未来教育发展的重要内容[7]. 目前有关自适应学习的研究,本质均指向个性化,认为将其作为一种实现个性化学习的具体方法[8],可以为学习者提供个性化服务[9]. 在数字化学习环境中,个性化自适应学习(Personalized Adaptive Learning)通过特定的科学手段挖掘学习者个性特征差异,全程记录和分析学习行为数据,对学习活动、学习过程和学习结果进行价值判断,以此开展个性化的干预和指导[10-11],从而促进知识意义的主动建构和有效学习.
近年来,随着如Knewton、InterBook、ELM-ART、AcroBatiq、Smart Sparrow、英语流利说和猿题库等系统的大规模普及与应用,个性化自适应学习的发展尤为迅速. 对国内外相关研究调研发现,当前个性化自适应学习的研究主要集中在系统模型构建、框架设计和平台开发[12-13]、技术应用研究[14-15]、系统模块组件开发和构建[1,16]以及对研究现状综述分析[17-18]等领域,知识图谱[19-20]及其表示学习[21-22]、知识追踪[23-24]和路径推荐[25-27]等为其研究热点,神经网络[28-29]、深度学习[30-31]和贝叶斯网络[32-33]等技术也被广泛应用. 然而,根据文献梳理,当前系统模块相关组件的关键技术多采用自然语言处理、机器学习和深度学习等方法实现[23,30,34-35],可解释性效果不佳,在某种程度上容易形成“黑箱”问题. 因此,针对教育技术领域中面临的关键问题和现有方法缺陷,本文在对个性化自适应学习框架进行解读的基础上,开展相关组件关键技术研究动态和存在问题的梳理分析,并对近年来解释性较好的技术研究作出介绍. 这些研究和应用经验的借鉴和综合运用,将成为推动学习者个性化发展行之有效的策略.
1 个性化自适应学习框架
当前个性化自适应学习框架主要由领域知识模型、学习者特征模型和教学模型三部分组成[8,36-37],又称为经典的“三角模型”[38]. 其中,领域知识模型包含学习领域的逻辑体系、基本概念和原理、规则定义以及探究方式等,学习者特征模型动态描述学习者的认知状况、学科知识、学习历史、情感状态、学习风格和偏好等方面的个性特征,教学模型决定适合学习者的学习活动和教学策略. 此三角模型正是教学过程“三要素”(教师、学生和教学内容)在计算机辅助教学(Computer Aided Instruction,CAI)中智能化、程序化的实现,相关工作原理(图1)为:教学模型根据领域知识及其推理,对学习者特征模型反映出的知识水平、认知能力、学习风格和偏好等加以诊断和分析,做出适应性决策,动态安排高切合度的学习内容、学习资源及其呈现方式,有针对性地向学习者提供个性化推荐服务;同时,对学习过程进行实时监测和管理,动态获取学习者表现数据,由此不断训练、更新学习者特征模型.
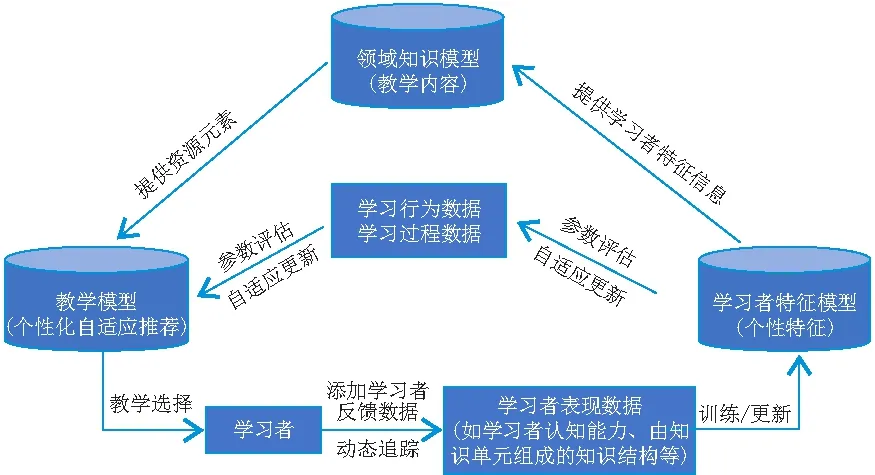
图1 个性化自适应学习基本框架
1.1 领域知识模型
根据关联主义学习理论,知识是一个由相互联系的事实、概念、命题和规则等要素构成的网络,而学习就是为了增加对这个网络的认知和理解,从而促进有基础、有意义的创造,更好地开展个体建构[39-40]. 领域知识模型对应用领域的组成元素及其结构进行描述,表示内部各组成元素及其之间的相互关系[41],一般由语义网、领域本体、层次结构和知识图谱等技术构建,其核心作用在于支持知识的获取、组织和推理等. 在大数据视角下,CHAPLOT和KOEDINGER[42]提出使用教育知识图谱来引导一个过程中多个单元间的先决条件关系,其他学者[28,34,43]也通过引入神经网络、机器学习和深度学习等技术对教育知识图谱构建过程中的关键环节(如实体识别、关系提取和知识表示等)进行深入研究. 在知识表示学习领域,当前绝大多数工作均聚焦于通用知识图谱方面,如:BORDES等[44]将“关系”解释为低维向量空间上头部和尾部实体间的转换操作,JI等[45]提出了一种使用2个向量来表示实体和关系的TransD细粒度模型,XU等[22]提出了一种用于学习实体结构和文本信息联合表示的深层体系结构,KAZEMI和POOLE[46]提出了一种基于张量分解方法的双线性模型来解决头尾实体关联性问题等. 然而,以上技术大多仅停留在表层学习概念间的链接关系,缺乏对实体重要性以及不同类型实体间的关系研究,同时对海量多元异构媒体资源的跨图谱表示学习也存在鲁棒性不足问题,与实际的应用需求仍有较大差距.
1.2 学习者特征模型
学习者特征模型是个性化自适应学习的核心和基础,反映个体自身及其行为所受强化关系上的个体差异,预示不同的学习行为表现[11]. 每个学习者的个性特征各不相同且动态变化,因此需借助AI技术对学习者行为序列进行动态检测和建模,预测其对知识的掌握程度及学习趋势,相关方法主要有知识追踪、覆盖模型和贝叶斯网络等. 如:CORBETT和ANDERSON[32]提出了一种贝叶斯知识追踪(Bayesian Knowledge Tracing,BKT)模型,该模型从结构上来说是一个隐马尔可夫模型(Hidden Markov Model,HMM),将学习者的知识状态表示为一个二元组{掌握该知识点,未掌握该知识点},并根据当前知识状态来预测隐变量的概率分布;PIECH等[23]提出一个深度知识追踪(Deep Knowledge Tracing,DKT)模型,通过循环神经网络(Recurrent Neural Network,RNN)对学习者的知识状态进行建模后,利用长短期记忆网络(Long Short-Term Memory,LSTM)追踪学习者随时间变化的知识熟练程度,相关效果被证明优于BKT模型;YEUNG等[24]在原始DKT模型的损失函数中引入与重建波动相对应的正则项和正则约束,增强了跨时间补偿预测性能的一致性. 根据以上研究可知:基于深度学习的知识追踪模型已被证明在无需人工特征的情况下优于传统的知识追踪模型,但也存在未考虑到学习者知识状态将受知识难度和遗忘规律[47-48]影响的问题,且相关参数和表示一直被指出不可解释.
1.3 教学模型
教学模型根据知识间蕴含的前驱和后继关系,综合考虑学习者当前知识状态、认知能力、学习风格及偏好等特征,有针对性地推送个性化的学习路径和学习资源,其构建方法主要有基于内容的推荐、基于协同过滤的推荐以及混合推荐等. 在早期学习推荐系统中,基于内容的推荐技术被广泛使用[49-50],但这些方法存在采用人工标记耗时且仅适用于小规模数据方面的问题. 后来,有关学者应用协同过滤技术[25,51]或混合过滤的方式[52-55]提供相关的自适应信息,如应用本体技术、语义和上下文关系等改善了这一情况,但也发现混合过滤并不能轻易通过改变结构而改善结果[56]. 如:陈敏等[57]以“学习元”平台为例,提出泛在学习的内容个性化推荐模型;TANG等[58]通过应用RNN,实现下一步学习推荐可高达60%的预测准确度. 以上提到的绝大多数推荐方法,只是在现有学习数据支持下针对学习者的知识背景和学习条件而开展的推荐,其可解释性效果不佳.
2 数据驱动下的个性化自适应学习
在大数据时代,越来越多的学习行为能够被追踪和记录,教育从“用经验说话”向“用数据驱动决策、管理与创新”的方向发展[59]. 数据驱动下的个性化自适应学习通过大数据分析学习过程和学习行为,能够精准识别学习者的个性特征、动态监控学习过程、实时预测学习趋势和有效评价学习结果,给予学习者个性化的干预和自适应的指导[60]. 因此,如何对海量教育数据的概念特征进行自动提取并建立关系、如何追踪学习者在学习过程中不断变化的个性特征、如何精准确定学习者每一步要学习的知识单元等,均是当前教育实践中亟需解决的科学难题. 鉴于此,针对经典“三角模型”建立一个可解释的个性化自适应学习技术框架,需着重对教育知识图谱的构建与表示学习、知识追踪和个性化学习路径推荐等核心技术难点(图2)进行研究,以解决教育数据中的概念边界检测、教育知识图谱表示学习的实体间语义信息传播、深度知识追踪的数据稀疏化和不可解释、个性化学习路径推荐融合课程序列等问题.
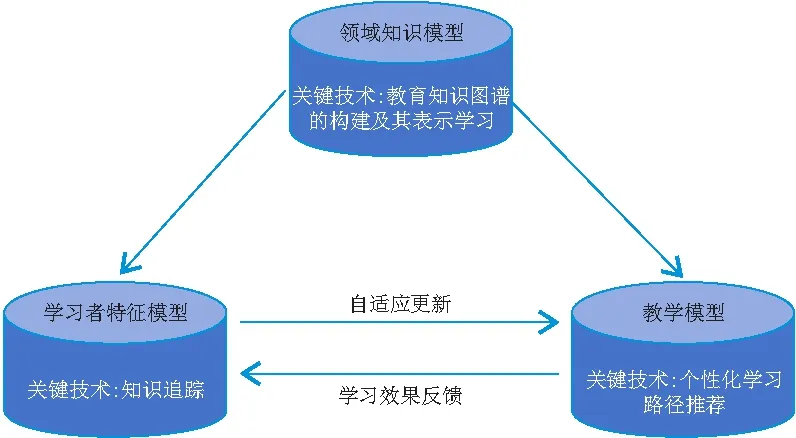
图2 个性化自适应学习框架的相关组件及对应关键技术
2.1 教育知识图谱的精准构建与表示学习方法
知识图谱(Knowledge Graph,KG)作为诊断学习者对知识和技能真实掌握状况的底层依托,知识元抽取在本质上来看属于序列标记问题,因此,可将教育数据的概念提取视为词语序列标记问题. 考虑到教育数据的顺序性及其内部词语的依赖性,HUANG等[61]在融合双向长短期记忆网络(Bidirectional LSTM,BiLSTM)和条件随机场算法(Conditional Random Fields,CRF)的基础上提出了BiLSTM-CRF(Bidirectional LSTM-CRF)模型,该模型精准度高且对词向量的依赖性较低. 李振和周东岱[20]深入分析了基于深度学习的知识元抽取,指出:BiLSTM-CRF模型是当前序列标注问题解决领域中较为成熟的应用,该模型结合了BiLSTM和CRF的特点[62],具有序列建模能力强、特征抽取自动化的优点;MA和HOVF[63]将卷积神经网络(Convolutional Neural Networks,CNN)融入BiLSTM-CRF模型,提出了一种“端到端”的BiLSTM-CNN-CRF模型,该模型通过采用CNN模型进行文本字向量特征学习,识别效果得到显著提升. 此外,LI等[64]专注命名实体边界检测,提出了AT-BDRY(Adversarial Transfer for Named Entity Boundary Detection)模型,通过无监督的传输学习方法来减少源域和目标域之间数据分布中的差异,无需任何手工特征或任何先前语言知识便能从文本中检测出实体边界. 为融合实体的文本和结构信息,KIPF和WELLING[65]提出一种图卷积网络(Graph Convolutional Networks,GCN)的半监督学习模型,该模型通过谱图卷积的局部一阶近似确定卷积网络结构的选择、学习隐藏层表示、编码局部图形结构和节点特征,可直接用于图结构数据处理. 此外,SCHLICHTKRULL等[66]引入关系图卷积神经网络(Relational Graph Convolutional Networks,R-GCN)构建知识图谱,对链接预测和实体分类的2个实验均验证了R-GCN模型作为实体分类的独立模型的有效性. 领域知识建模是构建个性化自适应学习系统的关键,然而,当前的研究主要依赖可编码、可量化的显性知识进行建模,忽略了隐性知识的应用. 因此,如何利用教育知识图谱对学习者学习过程中的隐性知识进行表示和建模,如何有效实现隐性知识和显性知识间的转化,将成为未来教育知识图谱研究和发展的重点和难点.
2.2 基于深度学习的知识追踪
知识追踪基于学习者的行为序列进行建模,能够预测学习者对知识的掌握程度,是个性化自适应学习系统构建的核心和基础. 近年来,基于RNN模型的知识追踪方法因具备捕获人类学习的复杂表示能力、其效果优于其他所有传统方法而被广泛应用,但同时也不可避免地存在输入序列重构、预测结果波动和处理稀疏数据时无法泛化等问题. 这些问题虽可以采用在损失函数中引入正则项并对输出结果进行正则约束等方法进行优化[24],但在效果提升方面却不显著且缺乏足够的可解释性[67]. 为此,NAKAGAWA等[68]提出一种基于图神经网络(Graph Neural Networks,GNN)的知识追踪方法,该方法将知识结构转化为图形,从而间接将知识追踪任务重构成GNN模型中时间序列节点级分类问题. 从数据结构的角度来看,知识结构可以以图形G=(V,E,A)形式进行组织,将有关数据图形结构性质的先验知识整合到模型中,提高知识追踪的性能和可解释性[69]. 相关实验表明:文献[68]提出的知识追踪方法可以改善对学习者成绩的预测效果,在无需增加其他信息的情况下更具解释性. 近年来,通过深度学习处理图结构数据的GNN方法研究备受关注,各种泛化框架和重要操作陆续问世,并在相关研究领域也都取得了成功结果[70-71].
另一方面,知识追踪也可以看作为对学习者参与学习活动时知识概念(Knowledge Concepts,KCs)掌握程度进行建模的一项任务. PANDEY和KARYPIS[72]认为:在知识概念的学习中,学习者在各项学习活动中所掌握的技能彼此关联,且取决于与该学习活动相关联的过去学习表现;为有效解决数据稀疏时无法泛化的问题,提出一种基于自我注意(Self-Attention)的知识追踪模型,该模型能够在不使用任何RNN模型的情况下模拟学习者的互动历史,并通过学习者历史互动中的学习行为表现来进行推理和预测,相关实验表明该模型比基于RNN模型的方法快一个数量级. 此外,GONZLEZ-BRENES等[73]研究表明:通过知识追踪和其他建模方法的组合应用,可有效提升模型的预测精度. 如:CAI等[74]采用知识追踪和回归分析模型相结合的方法研究学习者整体学习趋势,预测未来学习趋势和表现;KHAJAH等[75]结合知识追踪和项目反应理论(Item Response Theory,IRT)模型来预测学习者的知识掌握,获得了显著成效.
总的来说,训练知识追踪的目标是利用学习者的历史学习数据去预测其未来学习表现,DKT模型在优化学习效率、发现不同知识点间内在联系、动态反映学习者连续知识水平变化等方面表现出强大优势,但也存在模型无法重构、学习者对知识点掌握程度不连续问题,未来需进一步对各种相关的DKT+模型进行探索和研究.
2.3 个性化学习路径推荐
与常规的推荐系统类似,个性化自适应学习路径推荐除了需解决常见的数据过大和冷启动问题外,还需考虑系统中其他模块的输出问题. 个性化学习路径推荐是一个详细的推荐过程,如果仅使用学习者数据,难度是非常大的. 为了提供更加准确多样和可解释的推荐,WANG等[76]在基于KG与用户——项目图(User-Item Graph)的混合结构中提出一种知识图注意力网络(Knowledge Graph Attention Network,KGAT)方法,在GNN模型框架下以“端到端”的方式实现知识图的高阶关系建模;该模型采用递归方式传播来自节点邻居的嵌入并引入Attention机制区分邻居嵌入的重要性,相关实验证明了其在理解高级关系重要性方面的可解释性.
学习路径由不同的节点组成,每个节点代表一个知识点,每个课程均包含着或多或少的知识点. NABIZADEH等[26]提出一条融合课程知识关系的学习路径推荐模型,该模型从课程序列图中选择所要学习的知识点后,组合知识关系和深度优先算法对所选知识点的课程序列进行深度搜索,估算学习时间及得分,再根据学习目标、认知状态和先验知识等要素推荐一系列满足学习者有限时间限制的学习路径;相关实验证明:该模型可在最大程度上提高学习者分数的同时满足时间限制,但仍存在学习者和学习对象冷启动问题.
冷启动问题在推荐系统中最为普遍,如果没有学习者的学习行为数据,那么后续的神经网络模型便无法正常运行. 为有效解决该问题,PLIAKOS等[77]提出一种将IRT和机器学习相结合的混合方法,该方法将IRT与基于学习者辅助信息的分类树、回归树相集成,并对学习者能力评估和项目反应进行预测;实验结果表明:IRT与随机森林相结合可提供误差最低和响应最高的预测准确性,有效减轻学习环境中冷启动问题的影响. ZHOU等[27]提出一种基于LSTM模型融合知识关系的全路径学习推荐模型:先基于个性特征相似度对学习者集合进行聚类并训练LSTM模型,预测学习路径及其表现,再从路径预测结果中选择个性化的学习路径进行推荐,从而有效解决没有学习行为数据的学习者路径推荐问题;学习路径中每个节点都具有关于学习者个体特征、学习内容和学习资源等多维数据,与文本数据的特征相似,学习路径数据同样具有序列结构,实验证明该模型对各种数据集都有较好的权衡. 知识关系来源于知识追踪,由于知识追踪模型具备可解释性,因此,该推荐模型具备了一定的可解释性.
教育是一个复杂的系统工程,个性化学习路径推荐的进一步丰富和发展需回归教育本质. 从教育的角度出发,将学习路径的个性化推荐研究与教育全过程相结合,在教育教学理论的指导下开展推荐模型的构建和系统的研发,真正为学习者提供更具个性化的学习服务,将成为未来个性化自适应学习研究的重中之重.
3 结束语
本文在分析国内外个性化自适应学习研究的基础上,从数据驱动的视角出发,对其框架进行解读和对相关组件技术进行分析,并对近年来可促进解释性提升的有关技术研究作出介绍. 虽然个性化自适应学习在人工智能教育中具有广阔的应用和发展前景,但其在基本科学问题、重点体系框架、关键核心技术和重要应用示范等方面仍然处于不断探索阶段. 尤其是在具体应用场景上,主要还是集中于在线教育方面,而在线下实体教育中尚缺乏实际应用,其主要原因在于线下数据采集的困难性以及不同实体教学结构的差异性上. 因此,个性化自适应学习的未来发展应从知识图谱及其表示学习、知识追踪、个性化学习路径推荐等方面,深入研究多场景数据驱动下个性化自适应学习的基础理论和框架体系、核心技术和平台构建,积极推进落地应用示范,通过实际反馈切实推动其在教育领域的创新发展.
猜你喜欢
军事文摘(2022年24期)2022-12-30
北京航空航天大学学报(2022年8期)2022-08-31
成都信息工程大学学报(2021年3期)2021-11-22
少先队活动(2020年12期)2021-01-14
学生天地(2020年15期)2020-08-25
文苑(2020年4期)2020-05-30
意林·少年版(2020年2期)2020-02-18
湘潮(上半月)(2019年3期)2019-05-22
汽车与新动力(2016年6期)2017-01-04
领导科学论坛(2016年9期)2016-06-05
