
冷水机组回归模型的分析与评价
2020-08-07 04:37王群
上海节能 2020年7期
王 群
上海碳索能源服务股份有限公司
0 引言
冷水机组是暖通空调系统主要耗能设备,最高可达60%~70%的比例,因此对冷水机组开展节能及故障诊断的工作意义重大。
冷水机组的模型分为黑箱、灰箱模型[1]。黑箱为纯数据驱动模型,随着人工智能发展,黑箱模型在实际工程中的应用越来越广,但其解释性较差。灰箱模型建立了冷水机组的物理模型,通过数据统计的方式确定其中的因子,比较常见的灰箱模型包括SL、BQ、MP、GNU、GNS 及LS 模型,本文采用实际项目数据对该6种灰箱模型进行评价。
1 实验数据
实验数据采用项目数据,数据字段为810-814,602,601,719,739,此外还采用杭州气象数据(字段1078)。原始数据见表1。
2 数据预处理
建立模型需要的数据包括:冷冻水供回水温度T_rchw、T_schw,冷冻水流量F_chw,冷冻机主机功率P,冷却水回水温度T_rcow。采用的项目数据中缺少冷却水数据,因此根据虹桥机场气象数据进行推测。在此处假设冷却水回水温度比湿球温度高3 ℃。除此之外,原始数据的预先处理还包括:
1)去除冷冻水流量、冷冻水供回水温度无数据点,若此行有一个数据无效点,则删除此行;
2)判断冷机单独运行的时间。判断依据为:如果该数据点的有功功率小于10 kW,则判断该时间点冷机没有运行。如果一数据点只有1台有功功率大于10 kW,则认为该时间点该冷机单独工作。经处理后,1~4 号主机单独工作的数据点分别有861、1 932、714、1 862个;
3) 根据时间,将不同字段的数据进行链接,链接后再次去除无数据点。此项处理之后,1~4号冷机的数据点数量分别有120、741、13、162 个,根据结果,选择2号冷机进行试验;
4)冷机的数据包含了一些噪声点,利用filter.py中的zscore_filter 进行数据清洗。在zscore_filter中,根据每一个变量的值计算其zscore,如果其大于阈值,则删除该行数据,经处理后,2 号冷机剩余662个数据点。
由于经过处理之后的数据在时间上没有延续性,因此每一个数据点可以视为独立而与前后数据点无关联。处理后的数据示例见表2。其中温度单位K,流量单位为m3/h,制冷量单位为kW。为进行建模,温度参数单位全部需要转换为K。
数据详情见表3。

表1 原始数据

表2 数据示例

表3 数据详情
3 探究模型及主要内容
探究模型见表4。其中,Tci 为冷却水回水温度,即T_rcow,单位:℃;Two为冷冻水供水温度,即Tschw,单位℃;Twi为冷冻水回水温度,即T_rchw,单位℃;Qe 为制冷量,单位为kW。在6 个模型中,SL、BQ、MP Model 为数据模型(Black Box Model),GNU、GNS、LS Model 为半物理模型(Grey Box Model)。
该报告主要包含了对6 个模型的预测精度、外围预测、数据减少、参数物理意义等方面的探究。
1) 6 个模型性能的基本探究,主要以RMSE(Root-Mean-Squre-Error)和 CV(Coefficient of Variance)为判断依据。两个参数的计算公式分别为:

其中,为预测值,yi为真实值,n为用来测试的数据量。
2) 6 个模型对训练数据点以外的数据预测性能。如:利用8月的数据训练的模型对9月COP的预测精度的研究;
3)训练数据减少对模型性能的影响;
4)GNS、GNU、LS Model中几个参数的物理意义研究。
4 探究结果
4.1 模型性能基本探究
4.1.1 回归方法
在训练模型时,主要的方法是模型线性化之后进行回归。其中SL、BQ、MP、GNS、LS Models 均采用此方法进行回归。
BQ 中 令,GNS、LS 中 令然后线性回归之后进行再计算得到COP。为探究GNS、LS Model的性能,回归时同时探究了是否有常数项时模型的表现。
在线性回归时,分别考虑有常数项和无常数项时模型的表现。
以下为3个灰箱模型回归时的具体参数转化。
(1)GNU Model
GNU Model的公式为:
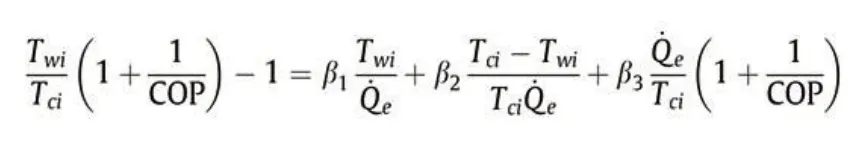
回归对应公式为:
第一次回归,y=β1x1+β2x2+β3x3+C1,

表4 探究模型
(2)GNS Model
GNS Model公式为:

回归对应公式为:

其中,为常数项。
(3)LS Model
LS Model 公式为:

回归对应公式为:

4.1.2 基本性能探究结果
在测试中,随机选取2 号冷机中300 个数据点进行训练(注:300个数据点已足够作为6个模型的训练数据,详见训练数据减少部分结果),其余数据作为测试数据。为研究噪声数据对模型性能的影响,在有噪声影响时(利用未过滤的2号冷机数据进行训练),同样选择300个训练数据进行训练。
为防止在预测时单个噪声点对模型造成较大影响,对于预测结果中COP 小于0,大于10 的结果进行之前,用预测结果的平均值替代。在实际计算过程中,此项仅在MP Model及GNU Model中有重要作用。各个模型的性能在不同数据下的基本表现见表5。
未排除预测精度的随机性,重复100 次试验得到测试的平均值见表6。
根据预测结果:
在没有噪声的情况下,除无常数项的GNS、LS Model外,6个模型在数据量足够的情况下表现差异不大,预测的相对误差CV均在6%~7%之间,其中MP Model 预测精度最高,其次为含常数项的GNS Model;
GNU Model由于训练过程较为复杂,需要对预测结果进行修正,以防止单个反常点对模型精度产生较大的影响;
有噪声数据时,6个模型平均的预测精度均出现了一定程度的下降,但总体还是保持了较好的准确率。在没有进行结果的修正之前,MP Model 的CV高达190%,模型本身对噪声相当敏感,容易出现单个点偏离值异常;

表5 模型基本表现

表6
在没有常数项 C 时,GNS、LS Model 预测结果均不理想,而GNU Model 表现与含常数项相差不大。
6 个模型的预测性能(无噪声训练数据)详见图1。
4.2 模型外围预测性能
探究训练模型对未来数据的预测能力是模型性能探究的重要部分。将2号机数据按月分为三部分,其中包括 175 条 8 月数据点,294 条 9 月数据,198 条 10 月数据。三组数据中 COP 均为 3~6 之间。比较的内容包括:6 个模型利用8 月数据训练对 9 月 和 10 月 进 行 预 测 Aug-> Sept、Aug->Oct、Aug->Sept,Oct,利用9月数据训练对10月进行预测Sept-> Oct,利用8、9 月数据训练对10月进行预测Aug, Sept-> Oct;为了比较各个月的数据量不同对结果的影响,每个月的数据量根据最少数据月(8 月)进行随机去除,并用去除后的数据进行试验,重复试验50 次,最后将结果进行平均。预测结果见表7。

图1 6个模型的预测-真实值散点图(19:含常数项,20:不含常数项)
表7 中绿色表示模型CV 值小,红色表示CV值大。典型的模型预测-真实值散点图见图2。
对比预测结果:
各个模型对外围数据的预测并不精确,仅8月数据对9月的预测结果较好,而其他项模型的CV值较大,预测结果不理想;
根据各预测结果的平均CV,排除随机性 ,SL Model、BQ Model 和 无 常 数 项 的 LS Model 对未来数据的预测最差,其他5 个模型的性能差异不大,灰箱模型的表现稍好于数据驱动模型;
对所有模型而言,主要误差来源为预测得到的COP 偏小,BQ Model 还存在部分点预测COP偏大;
在此项预测中,GNS Model结果较为稳定,但由于其基础误差较大,参考意义不高。
4.3 训练数据减少对模型的影响
为得到模型在不同的训练数据下的预测表现,随机选取n条数据,对模型进行训练,然后用剩余数据作为测试数据,计算该模型的CV。经过30 次随机之后,对所得的结果进行平均即为该模型在此数据量中的表现。6 个模型的表现见图3,由于GNS Model 在没有常数项时表现过差,在后面的讨论中不再提及。在测试过程中注意训练误差和测试误差的变化,以预防过度拟合。
根据模型在预测时的精度做出的三色图(N 表示无常数项)见图4。图中,从上往下训练数据条数依次增大,绿色表示CV值较小(<6.5%),红色表示CV值较大(>9%)。

表7 模型对未来数据的预测表现

图2 未来数据预测的典型预测-真实散点图

图3 模型在训练数据减少时的CV值(小图为训练误差和测试误差)
结合各图,可以看出:
在数据驱动模型中,SL 模型收敛最快,MP次之,BQ 最慢,在数据量足够时BQ Model 和MP Model 模型预测精度更高,BQ、MP Model 在数据量达到125 条之后数据增加对模型的表现影响不大;
GNS Model 在没有常数项时不能很好拟合数据,无论是训练误差还是预测误差都较大;
相比数据驱动模型,灰箱模型所需要的训练数据更少,在数据较少的情况下,灰箱模型明显有更好的预测精度;
LS Model 在没有常数项时表现精度不高,而加入常数项后表现较好。
GNU N Model 和 GNS Model 在 所 有 模 型中表现最好,其需要的训练数据少,约75 条模型的训练误差和测试误差即相差不多,GNU Model 的参数更有物理意义,GNS Model 则拥有较高的预测精度,其他模型与这两个模型的表现相差较大。

图4 训练数据减少时模型CV三色图(Min:6.5%,Max:9%,Medium:7.5%)
4.4 灰箱模型参数物理意义
在6 个模型中,有GNS、GNU、LS 均为灰箱模型。为将模型应用于故障诊断,此报告包含对模型参数物理意义的探究。
4.4.1 GNU Model
GNU Model的公式为:

回归对应公式:
第一次回归,y=β1x1+β2x2+β3x3+C1,
其中,β1~β3均有各自的物理意义:
β1— ΔS,由于内部不可逆性,冷水机组总内熵产生率,
β2— Qleak,热量损失/增加率来自或进入冷水机组,
β3——R,总换热器热阻。
GNS Model公式为:

回归对应公式为:

β1~β3为该冷机的熵增特性(characterize the entropy generation of a particular chiller)。4.4.3 LS Model

LS Model 公式为:

回归对应公式为:

该模型的参数意义理论上与GNS Model相似,均是冷机的熵增特性。,

4.4.4 结果及讨论
在现有的数据中随机选择足够多的数据进行反复训练,即得到该数据集的参数分布。此报告中选择200~250 条数据,每个数据量随机重复50次,从而得到2 500 次训练的参数。由于GNU Model 无常数项的表现,因此不再考虑加入常数项后的模型,而GNS、LS 模型,则需考虑加入常数项后的模型。
GNU Model
各参数分布图(横轴为参数值,纵轴为频数)
根据理论,β1~β3分别对应熵增ΔS, 热损Qleak,换热器热阻R。某一典型(冷机功率3~4 kW)的回归结果见图5,结合数据来源冷机的功率(Pmean=1961 kW)。统计结果见表8,回归结果见表9。
初步判断,β1、β2、β3的分布范围不大,遵循正态分布,具有物理意义,可以作为故障诊断的依据。但在回归时可能会有比较意外的值出现,因此建议多次随机取数据点训练之后得到参数的平均值。此外,对β2,由于与试验结果的符号不同,因此建议通过实际测量数据进行校对,以确认其符号。

图5
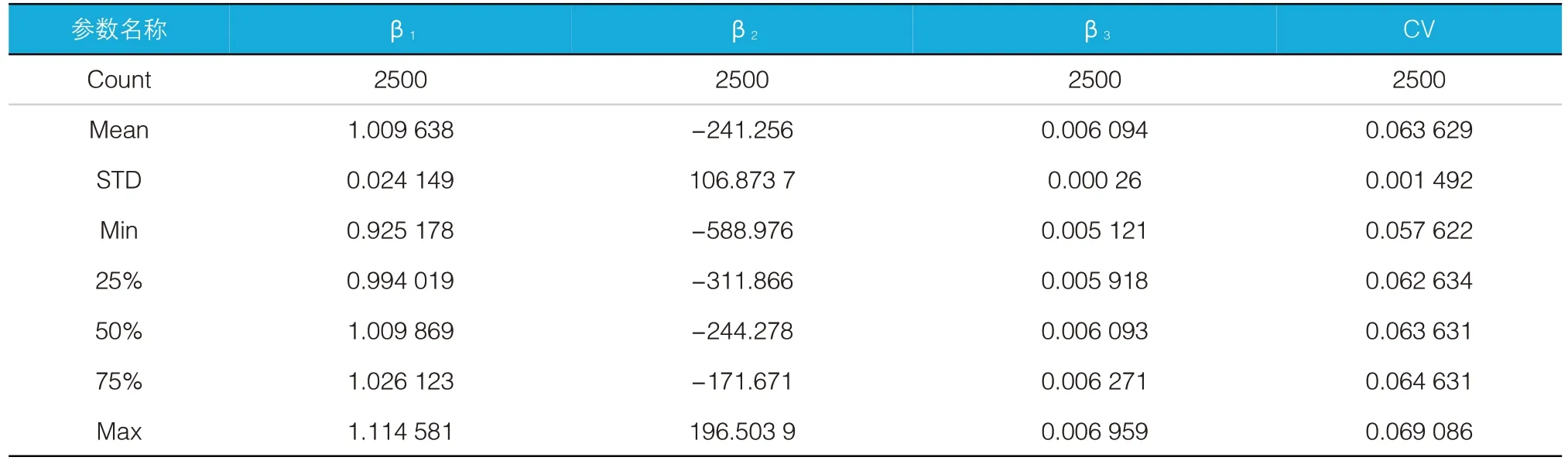
表8 统计结果

表9 典型的GNU Model回归结果
含常数项时各参数分布见图6(横轴为参数值,纵轴为频数)。
不含常数项时各参数分布图见图7(横轴为参数值,纵轴为频数)。
根据J.M.Gordon等人的试验,典型的结果见表9,其中A0~A2对应β1~β3,同时与没有常数项的回归结果对比发现,实际得到的参数分布和实验数据差别较大,因此物理意义有待确认。
LS Model
含常数项时各参数分布图(横轴为参数值,纵轴为频数)见图9。
·GNS Model

图6 含常数项时各参数分布

图7 不含常数项时各参数分布

表10 统计结果(N 表示无常数项)

表11 某试验结果
不含常数项时各参数分布图(横轴为参数值,纵轴为频数)见图10,统计结果见表10。
根据结果,发现在加入常数项后各参数的分布发生了巨大变化,因此认为在加入常数项后,LS Model参数不再具有的物理意义。
5 结论
经过华为数据的试验,所探究的6 个模型在冷机COP 预测上均能达到较高的精度。各个模型的特点总结见表11。
从故障诊断的角度看,GNU Model 和GNS Model 两种模型具有较好的前景。GNS Model 的参数虽然物理意义待确认,但仍可以作为换热器工作状况的一项指标,且其要求的训练参数较少,很快模型即可稳定;GNU Model 的参数可以用来诊断制冷剂在循环中的流动情况、机组换热器的工作情况等。但是,具体的诊断过程需要有相应的数据才能进行更好的研究。相比之下,GNU 模型的性能更为优秀,其各个参数物理意义较为明确,各参数基本遵循正态分布,对训练数据的要求较少,可以作为故障诊断的冷机模型。

图8 含常数项时各参数分布图

图9 不含常数项时各参数分布图
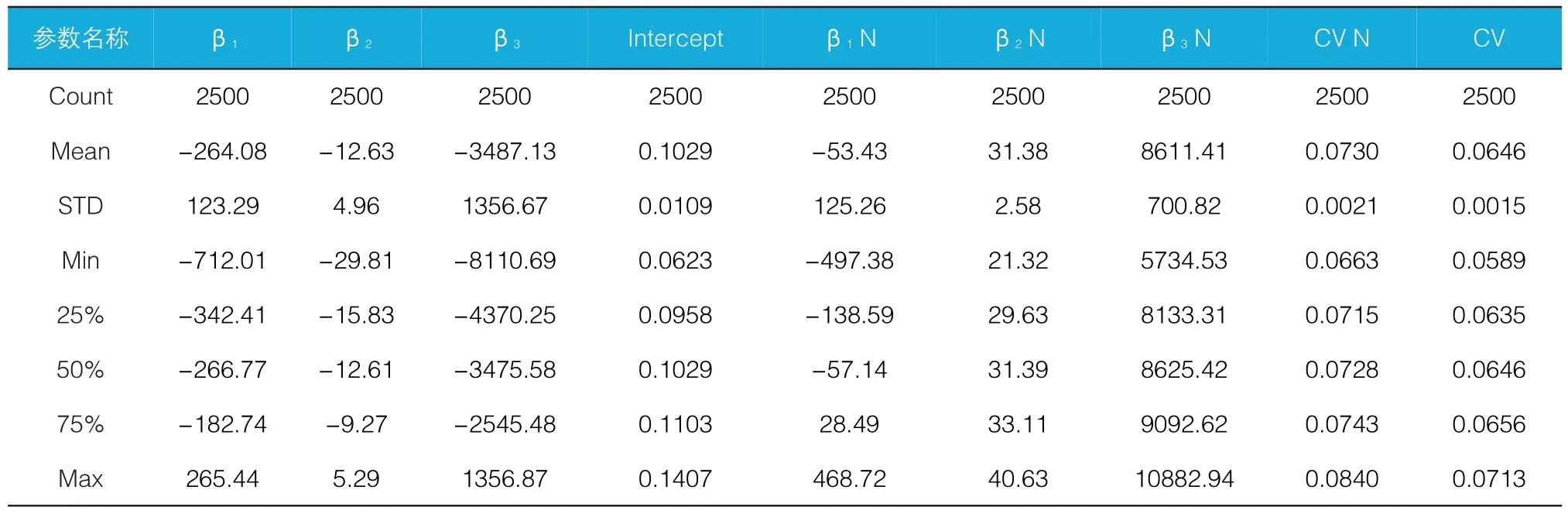
表12 统计结果(N 表示无常数项)

表13 模型探究总结
猜你喜欢
黄河之声(2022年10期)2022-09-27
绿色建筑(2022年4期)2022-08-19
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
世界有色金属(2020年2期)2020-12-09
卷宗(2018年14期)2018-06-29
新高考·高一物理(2016年3期)2016-05-18
建筑工程技术与设计(2014年32期)2014-10-21
有色金属设计(2014年4期)2014-03-11
