
基于多层分类器的恶意网页检测技术研究
2020-08-07 14:42张士坤
现代计算机 2020年18期
张士坤
(广东工业大学计算机学院,广州510006)
0 引言
根据中国反钓鱼联盟组织的报告[1]指出,2019 年7月国内检测出448046 个恶意网站,对社会和经济造成重大损失。随着移动互联网的兴起和繁荣,恶意网页攻击日益多样化和复杂化,使得恶意网页的检测更为困难。如何高效识别恶意网页已经成为亟待解决的问题之一。
为了应对这些挑战,机器学习方法在恶意网页检测中得到了广泛应用,包括朴素贝叶斯、决策树、随机森林、支持向量机等算法。在这些方法中,特征提取和分类器的构建是很关键的因素。人工特征提取需要耗费大量时间和精力。近年来,深度学习方法在图像识别、语音识别等领域得到广泛应用。深度学习方法使用神经网络模型,自动学习样本特征,在处理大量数据集情况下表现良好。恶意网页检测领域也能使用深度学习方法,目前该应用已经取得不错的效果。
1 相关工作
针对恶意网页的识别,国内外学者提出很多检测方法,主要分为以下5 类:
基于黑名单的检测方法。黑名单是一份恶意网页列表,包含恶意网页的URL、IP 地址等信息。通常是由具有公信力的网站发布,例如谷歌公司开发和维护的Google Safe Browsing API[2]。文献[3]通过网站域名匹配以及Google 搜索结果,来确定待测网页是否为恶意的。黑名单技术虽然实现简单、使用方便,但由于检测效果依赖于黑名单的规模,存在漏报率高的缺点。
基于启发式规则的检测方法。该方法是根据恶意网页的相似性规则来判断网页是否为恶意的,虽然在检测速度上具有较大优势,但仅使用基于规则匹配的检测方法,无法应对新类型的钓鱼网页[4]。
基于交互式主机行为的检测方法。访问恶意网页时,可能会出现恶意软件安装或恶意脚本执行等情况,这时可以使用蜜罐技术检测网页。蜜罐技术本质上是一种对攻击方进行欺骗的技术,通过布置一些作为诱饵的主机、网络服务或者信息,诱使攻击方对它们实施攻击,从而可以对攻击行为进行捕获和分析[5]。
基于机器学习的检测方法。机器学习方法通过选择恶意网页的特征,来生成训练数据,构造分类器进行检测。文献[6]提出基于SVM 的轻量级恶意网页检测方法,作者仅提取了6 个URL 特征,包括URL 长度、数字的数目、是否包含IP 地址。由于提取的网页特征少,模型检测速度快。该方法的缺点之一是实验数据量小,泛化能力较弱。文献[7]提出一种从URL 字符串中提取词汇特征的方法,并使用自适应正则化来检测恶意网页。该方法能较少训练数据的噪音,并提高检测准确率。文献[8]首先从URL 地址入手,提取URL特征并采用改进贝叶斯算法进行检测,对贝叶斯方法无法确定的可疑网页,再提取该网页的页面特征,使用不平衡SVM 进行检测。该方法所需的检测时间少且能达到较高的识别准确率。文献[9]首先过滤掉高度相似的恶意网页和没有登录表单的网页,然后从URL 词汇表、HTML DOM、WHOIS 信息和搜索引擎信息中提取15 个高度差异化的特征,使用机器学习方法检测。文献[10]提出一种可扩展的恶意网页检测方法,作者从URL 和HTML 中提取了212 个特征,同时使用Gradient Boosting 来检测恶意网页。
基于深度学习的检测方法。深度学习方法使用神经网络模型,自动学习样本特征,在处理大量数据集情况下表现良好。文献[11]使用了循环神经网络中的LSTM 对URL 进行检测,使用两百万条URL 的数据集训练模型,准确率能达到98.7%。相比随机森林模型,LSTM 准确率高出5%。
2 模型架构设计
本文对网页不同层次特征,采用不同的算法模型,综合两个模型的输出得到最终的检测结果。本文设计的检测模型有两个层级:CNN-GRU 检测模型和随机森林检测模型。对URL 原始字符串,利用CNN 处理局部关联性数据和特征提取的优势,以及GRU 神经网络捕获数据时序性和长程依赖性的优势,构建CNN 和GRU 混合模型,该模型能自动提取URL 字符串的特征。随机森林检测模型提取了16 个网页特征,包括URL 字符串特征,DNS 信息、网页HTML 等特征。该模型采用随机森林算法进行网页检测。
2.1 CNN-GRU检测模型
由于训练数据为URL 字符串,而神经网络模型的输入必须为数值,所以需要把字符型数据转换成数值数据。如果数据集中URL 长度差异过大,将不利于神经网络快速收敛,因此需要统一所有样本的URL 长度。假设选定的URL 长度为L,所有样本需要进行字符串截取和字符填充。长度大于或等于L 的字符串,只截取该URL 的前L 位,长度小于L 的字符串,从末尾开始填充到L 位,填充字符选择特殊字符,L 的实验值为200。
实验采用one hot 编码,把字符串数据转换成矩阵。通过遍历数据集生成字符映射表,表中每个字符都是唯一的,字符表的长度为96。单个字符用向量c→表示,→|c|=96。c→中只有一位是1,其余位都是0。一条URL 可以映射成尺寸为200×96 的矩阵U。用向量[0,1]标记正常网页,向量[1,0]标记恶意网页。
经one hot 编码后的矩阵包含大量0,会导致稀疏编码和发散性,该问题可以通过词嵌入降维解决。词嵌入降维的作用是通过线性变换,把稀疏矩阵转换成密集矩阵。G 为U 经过Embedding 层降维生成的密集矩阵,其尺寸为200×64。
如图2 所示,卷积层对G 进行卷积运算,抽取局部关联特征。具体地说,卷积层设置多个卷积核Q,每个卷积核Q 对具有窗口大小k 的字符嵌入向量进行卷积以产生新特征[12]。例如一个新特征ci通过下式生成:

其中σ( )x是表示卷积层的非线性激活函数的ReLU 激活函数,Wf是卷积核的权重矩阵,bf是偏差。卷积层对应一个池化层,使用最大池化方法,将同一个卷积核生成的特征集中最大的数值保留[13]。将最大池化层连接到GRU 神经网络,GRU 作为LSTM 的变种,在保持了LSTM 效果的同时又精简了结构,避免了梯度消失和梯度爆炸的问题[14],最后使用Softmax 作为模型的预测函数。
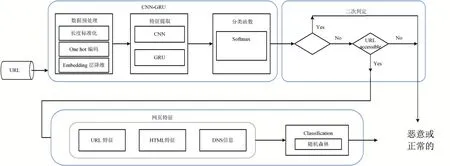
图1 多层次检测模型架构图

图2 CNN-GRU检测模型结构图
为了抑制过度拟合,本模型应用了dropout 策略。在深度神经网络中,dropout 是一种防止过拟合的有效策略,它能够在训练过程中以一定的概率丢弃网络中的每个神经网络单元,实验设置丢包率为0.25。
训练模型的关键是确定目标损失函数。本模型使用交叉熵损失函数,其形式为:

损失函数的优化方法是在模型迭代过程中不断调整神经网络中的权值。实验采用优化策略是Adam 算法,该算法能提供解决稀疏梯度和噪声问题的优化方案。
2.2 随机森林检测模型
随机森林算法是集成的机器学习方法,可用于控制过度拟合。此外,凭借其森林结构,各个决策树的不稳定性可能会消失。因此对网页特征,本实验采用随机森林算法来检测。该分类器首先提取网页特征,生成训练集。然后随机选择若干训练子集,对训练子集构造决策树。最后获取决策树的输出,并求取输出的平均值,得到网页的检测结果。
如表1 所示,文章提取了网页的16 个特征,包括URL 字符串特征、DNS 信息、网页HTML 特征。

表1
2.3 阈值的设置
如图1 所示,阈值α决定网页是否进行第二级检测。如公式所示,若CNN-GRU 输出的正常网页概率p1 与恶意网页概率p2 中最大值和最小值比值小于α,则需要提取网页URL 特征、网页HTML 特征、DNS 信息进行第二级检测;否则则由CNN-GRU 输出结果直接进行判定。α初始化为1,然后输出多级检测模型的识别准确率,α进行加1 操作,直到输出最优识别准确率并收敛。

3 实验分析
3.1 评价指标
本文采用准确率(A)、查准率(P)、查全率(R)和F1值评价模型的性能。其中准确率是最重要的评价指标。查准率表示预测为正的样例中实际为正的比例,查全率表示正样本中被预测正确的比例,F1 值是查全率和查准率的调和平均值。

上述公式中,TP 表示被预测为正样本,实际上也
是正样本的总数,FP 表示被预测为正样本,实际上是负样本的总数,TN 表示被预测为负样本,实际上也是负样本的总数,FN 表示被预测为负样本,实际上是正样本的总数。
3.2 实验环境及数据集来源
本实验采用的编程语言为Python 3.6,CPU 为Intel Core i7 7700k@4.2Hz,RAM 为16G。数据集包含36400 个正常网页和37175 个恶意网页。设置batch为64,epoch 为20。实验过程中采用5 折交叉验证,保证检测模型的稳定性。
如表2 所示,与CNN、LSTM、CNN-LSTM 检测模型相比,CNN-GRU 模型在准确率、查全率、查准率、F1 值上效果比前者要好。从图3 看出,CNN-GRU 神经网络训练过程中,最早收敛,具有更好的稳定性。通过图4对比得出,本文设计的多层次检测模型在准确率等指标上表现更佳。如图5 所示,当α取值为215 时,多层次检测模型识别准确率收敛,且明显优于CNN-GRU模型和RF 模型。

表2

图3 神经网络训练图

图4 CNN-GRU、RF、多层次检测模型对比图

图5 阈值α变化图
4 结语
本文研究了卷积神经网络、循环神经网络、随机森林算法在恶意网页检测上的应用和效果,设计了结合神经网络和随机森林算法的多层次检测模型,并和单层次检测模型进行对比。实验证明,在准确率、F1 值等指标上,多层次检测模型有更好的效果。恶意网页种类较多,未来可以研究恶意网页的多分类问题,有助于进行针对性防御。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
魅力中国(2018年5期)2018-07-30
中学科技(2016年7期)2017-05-16
