
基于机器学习的农产品销量区间预测
2020-08-06 15:01赵亚亚张泽人代永富
计算机时代 2020年7期
赵亚亚 张泽人 代永富
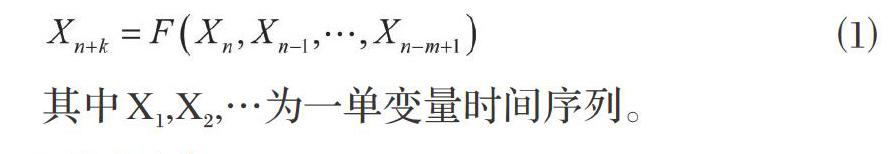

摘要:时值实施乡村振兴战略的关键时期,农村电商发展出现高峰,为加强其供应链体系建设,对农产品进行销量预测。针对影响销量的未知因素和干扰项众多的问题,提出基于K-means聚类的偏二叉树SVM销量区间预测模型。用BP神经网络时间序列对陕西大枣价格进行预测,根据质量、价格、时间三个因素,利用聚类算法对样本划分类别,偏二叉树SVM进行分类,将销量预测在聚类区间内。实验结果表明,该模型有着极高的预测精度,可用于农产品销量预测。
关键词:机器学习;时间序列预测模型;BP神经网络;K均值法聚类;偏二叉树svM
中图分类号:TP181 文献标识码:A 文章编号:1006-8228(2020)07-22-04
0引言
当前是实现乡村振兴战略的关键时期,农村电商是一个有力的破局之道,帮助农村电商预测未来农村产业发展方向,使农民及时调整生产方案,实现精准产销,助力国家全面脱贫。因此,预测各种农产品的销量显得尤为重要。
目前国内对农产品销量预测的研究方法众多,如人工神经网络模型、回归分析、时间序列分析模型和支持向量机模型。这些方法在不同的方面取得了较好的效果,但仍存在局限性。人工神经网络法易造成过拟合态,且可能与实践情况偏离较大,陷入局部最优解。回归分析法其拟合效果與数据量密切相关,对数据不全的农产品预测并不理想。时间序列分析法可能会因为农产品销量因素多而导致其计算结果的可信度较差。支持向量机法对数据量过大的情况,计算机的求解能力将会减弱。
机器学习在预测方面有着强大的能力,比如说皇冠模型(ICM)。本文在此基础上,综合考虑上述的方法的优点和缺点,采用BP神经网络时间序列对价格进行预测,并提出一种基于聚类算法的偏二叉树SVM农产品销量区间预测模型,克服定量估计误差难以控制的缺陷。考虑到传统决策树SVM方法的误差积累问题,本文运用聚类算法,根据划分难易程度,按序分割,进一步优化模型,从而尽可能地利用较少的特征信息对产量精准预测,以减少多种干扰因素对产量预测误差的不确定性,同时将产量预测的准确性控制在可指导生产范围内,对农民的生产量进行科学引导。
1理论与问题分析
1.1关于大枣价格的分析
1.1.1理论基础
基于BP神经网络的时间序列预测:认为时间是决定变化的一个条件,未来与前面m个值之间可以用函数关系进行拟合,以BP神经网络为工具,将前几年数据进行滚动排列作为输入值,后一年作为输出值。以时序分析为方法来拟合一个函数关系式,变量之间应满足:
1.1.2问题分析
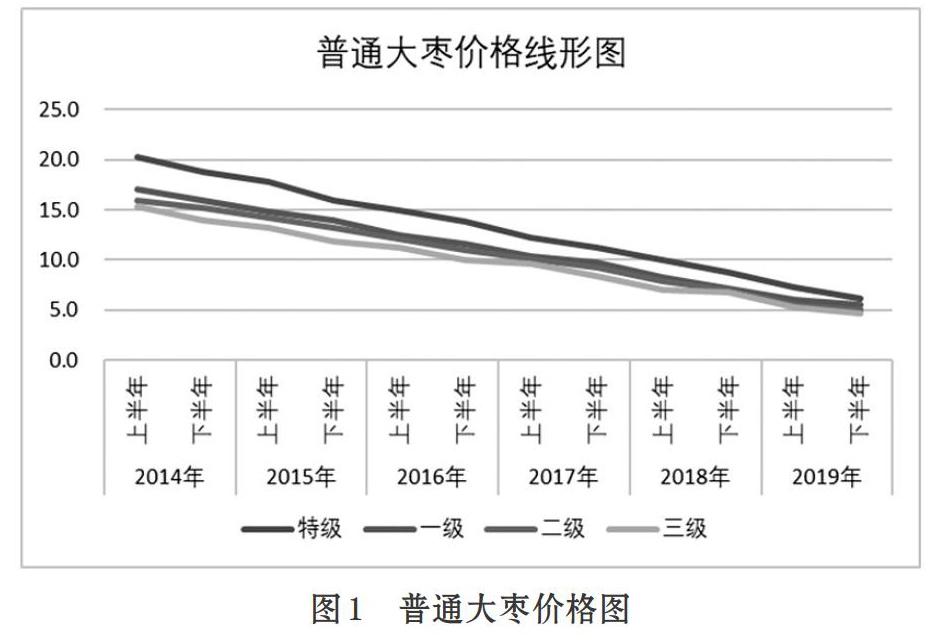
采集2014-2019陕西大枣的价格数据(单位:元/斤),通过数据分析发现价格随时间的变化具有动态性、随机性和复杂性。时间序列分析法可以很好的解决变量于一定区域内随时间动态变化的自相关问题,BP神经网络在处理不确定和非线性的问题上,有着极大优势。所以,通过BP神经网络对该函数关系进行拟合,建立基于BP神经网络的时间序列预测模型。
1.2关于大枣销量的分析
1.2.1理论基础
偏二叉树SVM模型:对传统DT-SVM模型优化。越上层节点的分类器的分类性能对整个分类模型的可推广性影响越大。基于此,在生成二叉树过程中,优先分割出易分离的类别。同时,各内节点由一个类与其余类构造分割超平面,生成的二叉树成为偏二叉树。
1.2.2问题分析
传统预测模型大多是通过建立数学模型定量预测。结合生活实际情况,影响陕西大枣销量的因素有很多,如天气、品牌与包装、市场建设等等。若直接对其销量采用定量预测,效果会差强人意。为减少误差,选取大枣近六年每半个月销量数据进行区间预测。
把销量分为若干个区间,去预测未来销量所在区间,将问题转化为多分类问题。而一般的决策树结构涵盖着误差积累的缺点;SVM多分类问题的传统方法one-against-one、one-against-rest可能产生不可分区域导致分类错误。对此,采取一种基于聚类算法的偏二叉树SVM来解决问题。
2模型建立与求解
2.1价格预测模型
2.1.1模型建立
Step 1数据预处理
将不同品质大枣价格(元/斤)随时间变化的数据整合起来,对样本数据进行归一化:
其中,x和x分别为归一化处理前后值;Xmin和Xmax分别为原数据最小值和最大值。
Step 2网络构建和训练
输入输出层设计:通过多次试验发现输入层为五个神经元效果最好,即依次将连续五年的大枣同一品质的数据作为网络的实际输入,其后一年作为网络的期望输出,按此方式滚动排列得到32组样本。
隐层设计:初步拟定四个神经元数,利用试凑法的思想,从而得到一个网络结构5-8-1,如图2。
网络训练:选取purelin为输出函数,tansig为隐层函数。使用MATLAB神经网络工具箱,随机选取70%的数据样本,15%验证样本,15%测试样本,运用trainglm函数和L-M算法训练网络。
2.1.2模型求解
(1)求解网络
通过MATLAB2018的神经网络工具箱对上述构建的模型进行训练,确定相关参数的选取后,经过9次迭代,训练完成。
(2)模型检验
基于traimlm训练构神经网络误差分布,如图3所示。
由图可见,实际输出在期望输出附近比较集中,测试样本误差控制在0.05以内。结合实际情况,即误差控制在0.1元以内。说明训练好的神经网络预测模型精度较高,可靠性较强。用该模型对2020年上半年大枣价格进行预测,如表1。
2.2销量预测模型
2.2.1模型建立
(1)数据预处理
使用机器学习原型聚类里的k均值算法将采集的2014年到2019年的陕西普通大枣半月销量数据进行聚类,得到销售量可能位于的k个区间。以大枣的三个属性为:品质、价格和年份为自变量,对这三个特征向量数据归一化处理在[-1,1]之间,极大减少价格的取值优势。
(2)建立偏二叉树SVM模型
定义:两类的距离等于它们最近的两个样本的欧氏距离,即:
其中dp,q。为不同类sp和sq的距离。
以此类距离,利用聚类分析的方法,让与其他类距离最远的类最先划分出来,此时构造的最优超平面具有较好的推广性。然后在剩余的类中重复该操作,直至不能劃分为止。这时,就生成了一个偏二叉树。以下为算法流程。
⑤对每个节点使用传统二值SVM训练算法最优超平面。将第n1类样本作为正样本集,其余样本作为负样本集,构造根节点处的SVM子分类器。类似地训练其余节点,直到生成所有的二值子分类器,得到完整的基于二叉树多类别SVM分类模型,然后用于大枣产量预测。
⑥算法结束。
(3)SVM训练
为了增加高维空间的计算能力,同时减少最优参数集搜索空间,我们使用高斯核函数函数进行训练,即:考虑到模型的性能与常数(c,y)有关,用crossvali-dation的想法选取c和y在{2-5,2-1,…,25}内精度最高下的c和y,若有多种组和精度达到最高,则选取c最小的一组,防止惩罚系数过高导致的过学习态。KKT停止条件的容许误差设为0.001。对所有SVM子分类器依次进行训练,形成分类器。
2.2.2模型求解
(1)销量聚类
使用SPSS软件确定最佳聚类数,依据试凑法的思想,结合生活经验,首先选取15个聚类数,然后依次更改聚类数,具体分析每次的聚类效果。最终确定最佳聚类数为10个,如表2。再利用MATLAB软件导出每组聚类成员,并且将其特征向量数据归一化处理。
(2)模型求解及检验
数据集规模为576个样本,选取70%的样本,按照模型思路,采用聚类算法生成决策树模型。余下30%的样本进行测试,得到大枣的测试精度为98.53%,这说明该算法的分类精度极高。使用该模型对2020年平均半月销售量进行预测。如表3。
3结束语
价格的时间序列模型,通过BP神经网络来实现,算法收敛速度快,学习效率高,并且可以实现复杂的非线性映射,效果较好。
利用偏二叉树SVM多分类方法的销量区间预测是一种模糊预测,预测的是一个销量区间,更准确且符合生活实际。运用机器学习的多分类方法,将原型聚类、支持向量机和决策树三者有效结合。既解决了传统的线性不可分问题,又解决了决策树SVM的误差累计问题,从而建立可信度极高的预测模型。事实上,可以再结合传统的定值预测模型,结果会更加精准。
模型利于推广到其他农产品的销量预测上,且随着数据量的加大,模型预测精确性会进一步提高。本文的模型只建立于主要影响因素价格和年份上,其他次要因素和不可抗力因素或者一般化或者忽略。在外界环境发生较大变化时,模型可靠性降低,其实际应用能力也将会减弱,需重新训练模型。
猜你喜欢
电子技术与软件工程(2016年22期)2016-12-26
现代经济信息(2016年27期)2016-12-16
时代金融(2016年27期)2016-11-25
价值工程(2016年30期)2016-11-24
科教导刊(2016年26期)2016-11-15
数字技术与应用(2016年9期)2016-11-09
软件导刊(2016年9期)2016-11-07
科学与财富(2016年28期)2016-10-14
科技视界(2016年20期)2016-09-29
科教导刊·电子版(2016年10期)2016-06-02
