
基于卷积编解码器和门控循环单元的语音分离算法
2020-08-06 08:29:30陈修凯陆志华
计算机应用 2020年7期
陈修凯,陆志华,周 宇
(宁波大学信息科学与工程学院,浙江宁波 315211)
(*通信作者电子邮箱zhouyu@nbu.edu.cn)
0 引言
语音是人们日常生活中最常用的一种交流方式,在聊天过程中人们感兴趣的目标语音往往会被一些额外的噪声和表面反射的混响所破坏,所以将目标语音和背景干扰区分开来是一个至关重要的问题。尽管人类能够非常容易地进行语音分离,即能够非常容易地获取自己感兴趣的目标语音。但是经过大量的事实证明,构建一个自动系统来匹配人类听觉系统来执行语音分离问题是非常困难的。Cherry 曾写到:“还没有提出一种能够彻底解决‘鸡尾酒会问题’[1]的算法”[2]。在语音信号领域,他的结论到目前为止仍是成立的。
语音分离问题是盲源分离(Blind Source Separation,BSS)问题中的一个重要组成部分。一直以来语音分离问题是被当作信号处理问题来研究,几十年来,随着机器学习和深度学习技术的飞速发展,语音分离问题被当作成监督性的学习问题来研究。将深度学习引入有监督的语音分离中已经成为了当前的主流模式,而且大幅度提升了语音分离的性能[3-5]。
文献[6]通过深度神经网络(Deep Neural Network,DNN)重构被屏蔽的掩码成分提高了语音分离的质量;文献[7]提出一种频谱变化感知损失函数,通过对频谱变化随时间变化较大的T-F 单元分配更高的权重,提高了语音分离的质量;文献[8]提出了一种基于复数信号逼近的长短时记忆(Long Short-Term Memory,LSTM)网络方法,来解决传统DNN 方法不能充分利用语音信号时间信息的问题,从而提高了语音的分离质量。
上述文献中的算法均提高了语音分离的质量,但是它们均存在一定的缺点:这些方法大多数都使用时频(Time-Frequency,T-F)单元的频谱图功能而不是时域波形。但是,频谱图功能具有某些局限性:首先,诸如离散傅里叶变换及其逆运算之类的预处理和后处理运算量很大,并且会在输出信号中造成失真;其次,这些方法通常仅估计幅度,并使用噪声相位来产生增强的语音。研究表明,相位可以提高语音质量[9]。Pascual 等[10]提出了一种基于生成对抗网络(Generative Adversarial Network,GAN)的语音增强算法,在该算法中,他们对混合信号的原始波形进行操作,考虑到了混合信号中的相位信息。Tan 等[11]提出了一种基于LSTM 网络和卷积编解码器(Convolutional Encoder Decoder,CED)相结合的语音增强算法,来解决实时的单声道语音增强。受Pascual 等[10]和Tan等[11]的启发,本文提出了一种基于卷积神经网络的端到端语音分离改进算法,以CED 网络和门控循环单元(Gated Recurrent Unit,GRU)[12]网络相结合,再利用混合语音信号的原始波形作为输入特征。
1 门控循环单元和卷积编解码器
1.1 门控循环单元
LSTM 网络是在递归神经网络(Recurrent Neural Networks,RNN)基础之上所做改进的一种网络,在RNN 网络的基础上引入了记忆单元(memory cell)和门机制(gate mechanism)。LSTM 在网络结构上与RNN 相比较,增加了输入门、遗忘门、输出门等结构单元。其结构如图1所示。
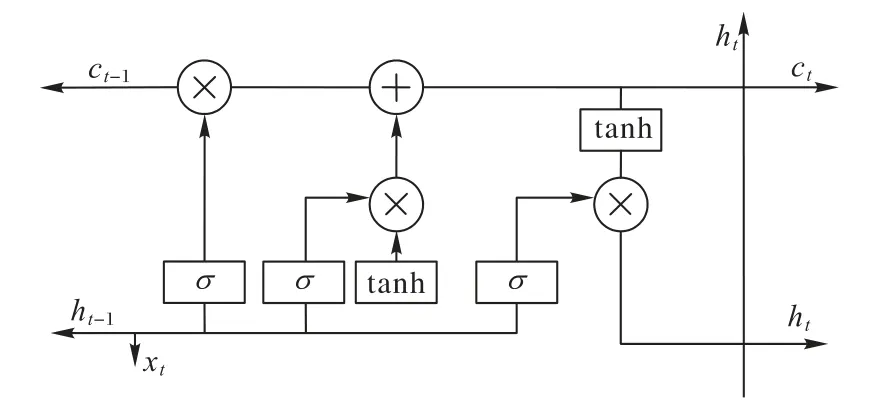
图1 LSTM结构Fig.1 LSTM structure
各个门中的计算公式如下所示:


其中:Wf,Wi,Wa,Wo是各个门的输入权重;Uf,Ui,Ua,Uo是各个门的循环权重;bf,bi,ba,bo是各个门的偏差;Xt是t时刻的输入向量;h是tanh激活函数;δ是sigmoid激活函数。
GRU 网络是在LSTM 基础上改进的一种网络,它既具有LSTM能够保留长期序列信息的能力,同时又能够减少梯度消失。GRU中只有两个门:更新门和重置门。GRU 网络和LSTM 网络相比较,其最大的优势就是结构更简单,计算量更小,训练速度更快。GRU网络结构如图2所示。
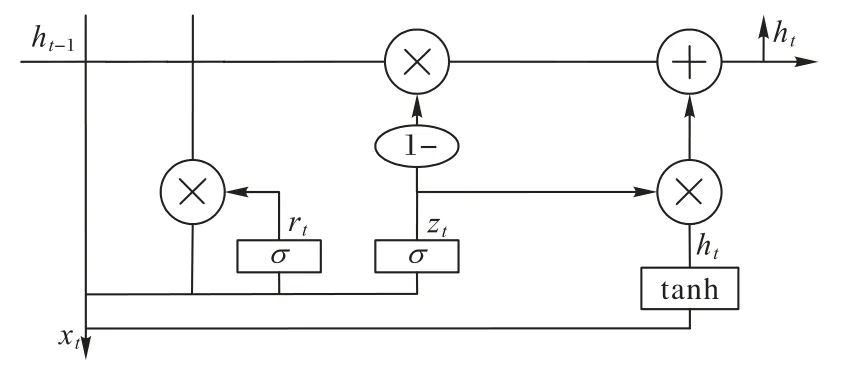
图2 GRU结构Fig.2 GRU structure
在本文中通过如下公式定义t时刻GRU 输出值ht的计算过程:
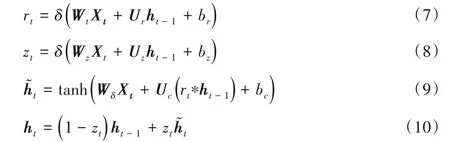
其中,rt表示重置门,zt表示更新门,δ表示sigmoid 激活函数。sigmoid 激活函数可以将数据映射到[0,1]上来确定门控信号。更新门具有两重功能:遗忘功能、记忆功能。它既能够对原来隐藏状态不相关的历史信息选择性遗忘,又可以对候选隐藏状态选择性记忆,保留下与当前时刻依赖性强的长短时信息。
1.2 卷积编解码器
CED 网络是一种非常灵活的网络结构,主要由编码器(encoder)和解码器(decoder)组成,通常使用在网络的预训练、数据降维和特征提取等中。编码器由多个卷积层组成,与之对应的解码器由多个反卷积层组成。在编码阶段,输入信号通过卷积层进行投影和压缩,参数校正线性单元(Parametric Rectified Linear Units,PReLUs)应用在所有的卷积层和反卷积层。编码器和解码器之间通过跳连接,因为输入和输出共享相同的基础结构,即自然语音的结构。通过跳连接来连接编码器和解码器,可以减少传输过程中语音信号信息的丢失,而且使用跳连接可以直接将波形信息传递到解码器中。CED 和传统的卷积神经网络(Convolutional Neural Network,CNN)相比,具有更少的参数。CED 结构如图3所示。
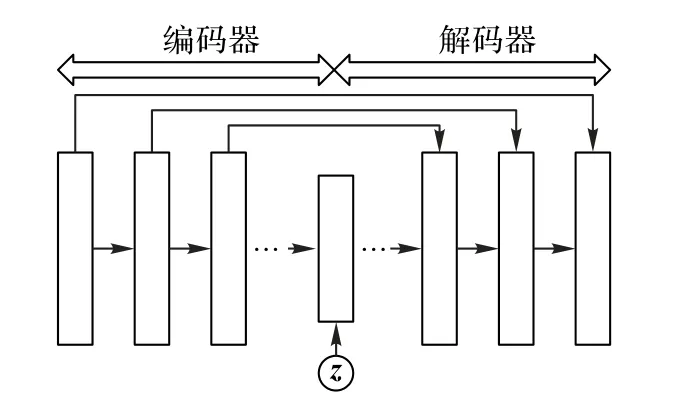
图3 CED结构Fig.3 CED structure
其中z是服从正态分布的噪声向量[13]。
2 本文提出的改进算法
2.1 问题描述
在单通道语音分离问题中,混合的语音信号时域表达式可以表示为:

其中:xi(t)表示第i个说话人的时域信号,x(t)表示混合后的时域信号,n(t)表示噪声信号。在不考虑噪声的情况下,混合信号的时域表达式可以简化为:

本文仅研究两个说话人的情况,即i=1,2。此时混合信号的时域表达式可以表示为:

2.2 网络结构
本文提出的卷积神经网络是以CED 和GRU 相结合的网络结构,是根据文献[11]改编而来的一种网络结构,其结构如图4所示。
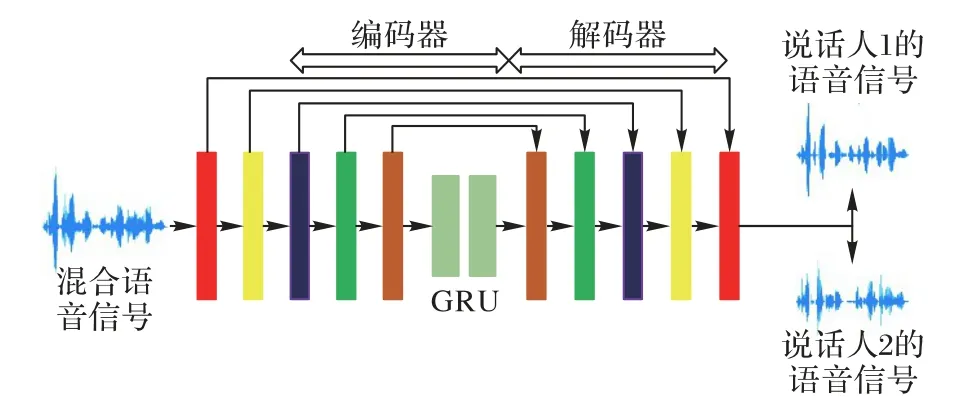
图4 基于CED-GRU的语音分离结构Fig.4 Speech separation structure based on CED-GRU
本文使用混合信号的波形点作为输入特征。输入信号通过编码器被编码到一个较高维的潜在空间中,然后由两个对称的GRU 层对潜在的特征向量的序列进行建模。随后,解码器将GRU层的输出序列转换回原始的输入形状。
卷积层的目的和作用是捕获和学习输入的特征,而CNN层数越多,特征的学习效果越好,但是参数学习将会变得更加困难。因此,本文模型在编码阶段使用了11 层卷积层,在解码阶段使用了11 层反卷积层,其性能比单层CNN 模型好得多。其中卷积层和反卷积层的具体结构如下:16 384×1、8 192×16、4 096×32、2 048×32、1 024×64、512×64、256×128、128×128、64×256、32×256、16×512;GRU 的结构为:8×1 024、8×1 024。
在本文提出的网络中,将指数线性单元激活函数(Exponential Linear Unit,ELU)应用于除输出层以外的所有卷积层和反卷积层。与整流线性单元(Rectified Linear Unit,ReLU)相比,已经证明ELU 收敛更快、泛化更好。在输出层使用softplus 激活函数。此外,在每次卷积或反卷积之后和激活之前都采用批归一化处理。编码器和解码器中,内核数需保持一致:在编码器中内核数逐渐增加,而解码器中内核数逐渐减少。
在本文中提出的算法模型其训练次数为100,优化算法使用的是Adam 优化算法,批大小设置为200,学习率设置为0.0002。
2.3 损失函数
由于是通过解码器端输出估计的纯净语音信号的波形,因此本文直接使用尺度不变信噪比(Scale-Invariant Signal-to-Noise Ratio,SI-SNR)[14-15]来设计损失函数。SI-SNR 也是用于语音分离质量评价的一项重要指标。SI⁃SNR的表达式:
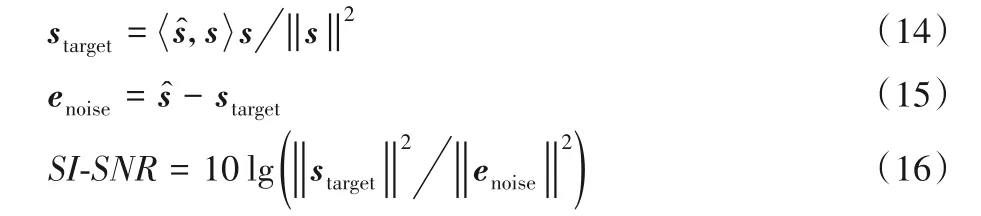
其中:是估计出的目标信号,s是纯净的目标信号。为了保证尺度的不变性,通常情况下都要对和s做均值为0 的归一化处理。通常情况下,SI⁃SNR的值越大,表示语音分离的质量越好。但是由于训练过程中使用梯度下降算法来训练模型,所以实际的损失函数定义为。
3 实验和结果分析
3.1 实验数据集
通过使用TIMIT 数据集[16]来对本文提出的系统进行评估,以解决两个说话人的语音分离问题,本文比较男性和男性、男性和女性、女性和女性说话人之间的语音分离效果。
TIMIT 数据集中共有630 位说话人,其中男性共有438人,女性共有192人,每位说话人共说10句话。训练数据集中男性有326 人,女性有136 人;测试数据中男性有112 人,女性有56人。本文所使用的训练数据集是从TIMIT的训练数据集中随机挑选出男性40 人,女性20 人,然后对两个不同说话人的句子进行混合;本文所使用的测试数据集是从TIMIT 的测试数据集中随机挑选出男性20 人,女性10 人,然后对两个不同说话人的句子进行混合。训练集数据和测试集数据是在信噪比在-5 dB和5 dB之间均匀选择进行混合而生成的。
3.2 评价指标
多说话人的语音分离目标是提高语音信号的语音质量或者提高语音信号的清晰度,这需要通过相应的语音质量评价来说明语音分离质量的优劣。
常用的用于客观质量评价和清晰度评价的指标有如下几种。
1)语音质量的感知评价(Perceptual Evaluation of Speech Quality,PESQ)[17]:PESQ 是最广泛用于评估语音质量的客观度量之一。PESQ 版本P.862.1/2 产生的数字范围为1~4.5,随着得分的升高,表示语音分离的质量越好。
2)短时目标可懂度(Short-Time Objective Intelligibility,STOI)[18]:STOI 是用于评估语音清晰度的最广泛使用的目标度量。STOI 表示语音可理解性的听力测试结果,通常用0~1的数字来评价语音分离的质量,其中1 表示语音完全可理解,0表示语音完全不理解。
3)BSS_Eval 工具箱[19]:BSS_Eval 工具箱中包括“源失真比”(Source to Distortion Ratio,SDR),SDR 表示语音分离系统的失真程度;“源干扰比”(Signal to Interference Ratio,SIR),是比较非目标声源噪声与目标声音的分离程度;“源伪像比”(Signal to Artifact Ratio,SAR),是指在语音分离过程中引入的人工误差程度。通常情况下,这三者的值越高,就表示语音分离的质量越好:
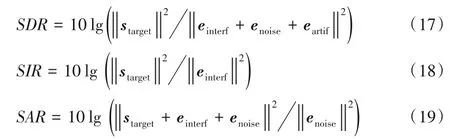
3.3 实验结果分析
为了验证本文算法的优劣性,使用当前最具有代表性的几种语音分离算法与本文算法做对比,包括基于排列不变训练(Permutation Invariant Training,PIT)的多说话人语音分离算法[20]、基于深度聚类(Deep Clustering,DC)的单通道多说话人语音分离算法[21]、基于深度吸引网络(Deep Attractor Network,DAN)的多说话人语音分离算法[22]和文献[14]中提出的语音分离算法。
其中PIT 算法、DC 算法和DAN 算法都是以短时傅里叶变换(Short-Time Fourier Transform,STFT)后的频谱作为输入特征,文献[14]中的算法是以原始波形作为输入特征。
使用不同算法的PESQ 值对比如表1 所示。使用不同算法的STOI值对比如表2所示。
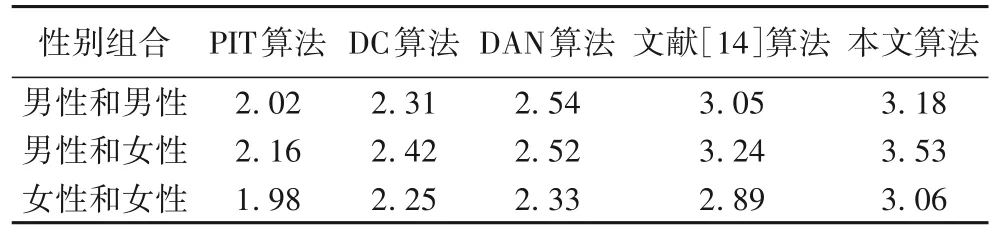
表1 不同算法的PESQ平均值Tab.1 Average PESQ of different algorithms
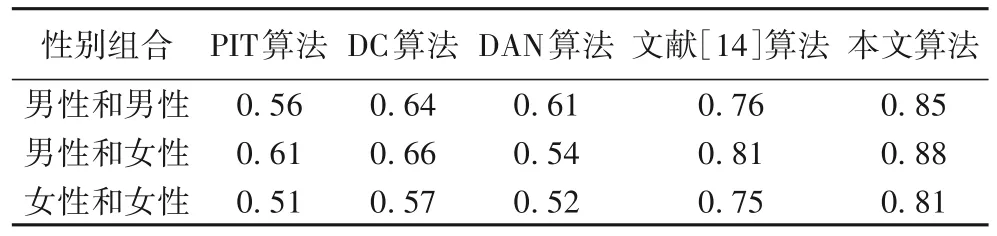
表2 不同算法的STOI平均值Tab.2 Average STOI of different algorithms
使用不同算法的SDR、SAR、SIR 平均值对比如图5~7所示。
通过表1、表2、图5、图6、图7中的数据可以发现,本文算法的PESQ值、STOI值SDR平均值、SAR平均值和SIR平均值,均优于PIT 算法、DC 算法、DAN 算法和文献[14]算法的各项评价指标。
其中本文算法与PIT 算法相比,男性和男性的PESQ 值提高了1.16 个百分点,STOI 值提高了0.29 个百分点;男性和女性的PESQ 值提高了1.37 个百分点,STOI 值提高了0.27 个百分点;女性和女性的PESQ值提高了1.08个百分点,STOI值提高了0.3 个百分点。本文算法与DC 算法相比,男性和男性的PESQ 值提高了0.87 个百分点,STOI值提高了0.21 个百分点;男性和女性的PESQ值提高了1.11个百分点,STOI值提高了0.22 个百分点;女性和女性的PESQ 值提高了0.81 个百分点,STOI 值提高了0.24 个百分点。本文算法与DAN 算法相比,男性和男性的PESQ值提高了0.64个百分点,STOI值提高了0.24 个百分点;男性和女性的PESQ 值提高了1.01 个百分点,STOI值提高了0.34个百分点;女性和女性的PESQ值提高了0.73 个百分点,STOI 值提高了0.29 个百分点。本文算法与文献[14]算法相比,男性和男性的PESQ 值提高了0.13 个百分点,STOI值提高了0.09个百分点;男性和女性的PESQ值提高了0.29 个百分点,STOI 值提高了0.07 个百分点;女性和女性的PESQ 值提高了0.17 个百分点,STOI 值提高了0.06 个百分点。
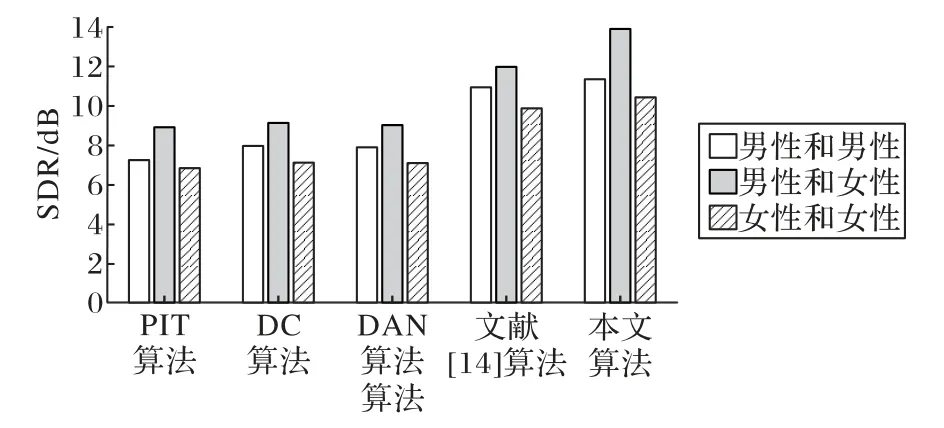
图5 不同算法的SDR平均值Fig.5 Average SDR of different algorithms
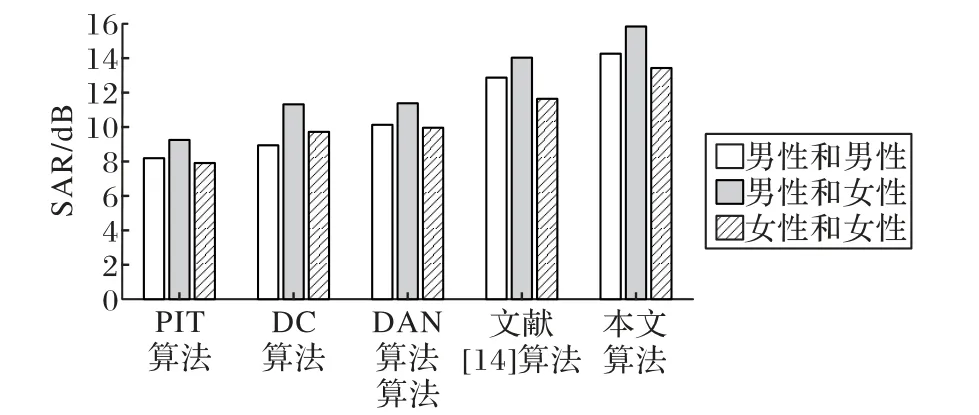
图6 不同算法的SAR平均值Fig.6 Average SAR of different algorithms
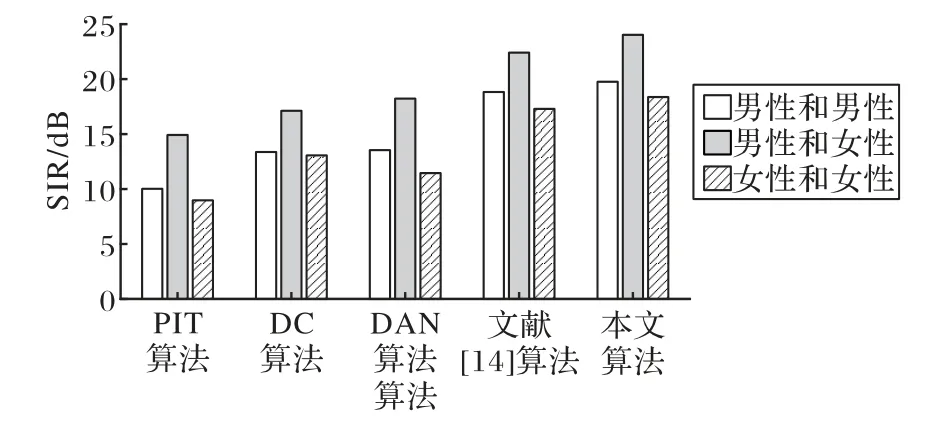
图7 不同算法的SIR平均值Fig.7 Average SIR of different algorithms
4 结语
本文主要介绍了一种卷积神经网络端到端的语音分离改进方法。为了能够充分利用混合语音信号中相位和幅值的信息,以混合信号的原始波形作为输入特征。除此之外,本文提出的模型是基于卷积编解码器网络结构和门控循环单元网络结构相结合的一种网络结构。实验结果表明,本文提出的语音分离算法的各项评价指标均明显优于PIT 算法、DC 算法、DAN算法和文献[14]中算法,这证明了本文算法的有效性。
目前本文中只是考虑了两个说话人的语音分离情况,在未来的工作中,将会考虑到多个说话人的语音分离情况,并且进一步提升语音分离的质量。
猜你喜欢
小学生必读(低年级版)(2021年10期)2022-01-18 15:10:46
小学生必读(低年级版)(2021年11期)2021-03-09 06:14:46
小学生必读(低年级版)(2021年12期)2021-03-04 07:18:44
家庭影院技术(2019年8期)2019-12-04 14:43:19
阅读(快乐英语高年级)(2019年5期)2019-09-10 07:22:44
电子制作(2019年14期)2019-08-20 05:43:38
电子制作(2019年9期)2019-05-30 09:42:10
小说界(2018年5期)2018-11-26 12:43:42
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:53
管理现代化(2016年3期)2016-02-06 02:04:41
