
基于深度学习的动漫影评特征挖掘与应用
2020-08-04 11:23张煦渤张莉
数码世界 2020年7期
关键词:深度学习
张煦渤 张莉

摘要:随着互联网的发展和近年来中国电影的崛起,中国用户越来越习惯于在豆瓣、猫眼一类的影评论坛或平台上发布自己的观影感受,并对电影进行打分。这些评论中隐藏着大量的用户偏好等信息。而若想对这些隐含信息进行获取,需要对影评特征进行进一步分析。基于此,本文通过Python对猫眼网站中“动漫电影”分类下面的影评及其得分等数据进行爬取,并将所得文本数据进行整理,通过jieba分词和word2vec等方法对影评特征进行分析;之后,根据影评的主体内容,侧重于其情感特征进行挖掘,将清洗过后的结构化数据带入基于RNN的深度学习模型中,以用户评分作为其影评情感特征的体现;然后,通过随机游走对模型进行优化,再进行模型效用对比,得到动漫影评情感特征的预测模型,并对其应用场景予以分析。
关键词:深度学习 动漫影评 特征挖掘
1 引言
随着我国经济的不断发展和人们生活水平的日益提高,电影作为一种娱乐消费品,已成为国人生活中不可或缺的一部分,观众在养成观影习惯的同时,越来越热衷于将自己的观影感受和想法分享到互联网上,国内的豆瓣、猫眼等影评汇总平台也由此越来越受人们的关注。而在众多电影分类中,动漫电影作为电影行业中的一个重要成员,从其诞生以来,许多动漫角色深入人心,其影评中亦包含着大量潜在信息,包括电影的口碑、用户的的观影偏好等等。若想对这部分潜在信息进行获取,就不得不对其影评的特征进行针对性的分析。
2 基于RNN深度学习的动漫影评特征分析
2.1 数据获取及预处理
本文以猫眼移动端网页版影评为数据源,选取其动漫电影分类中所有可见平均得分的电影影评为实验对象,同时考虑了影评评论时间的筛选。
首先在Chrome开发者模式下可以通过对网络请求的查询获取猫眼数据的API,其接口结构为:
在具体抓取某一部电影的影评时,只需将其中的movieId替换对对应的电影编号即可。同时,还需注意影评列表的开始时间等参数。
将获取的json文件进行解析,即可得到对应影评的用户ID、打分、地理位置、评论内容等有效信息。之后,将解析后的无效信息予以剔除,共计63条,有效信息214424条。
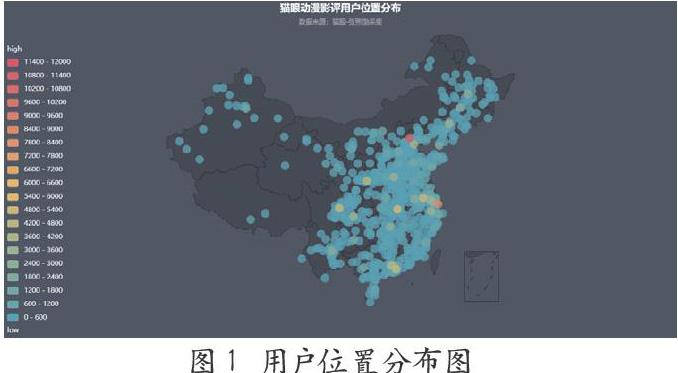
将评论按照用户地域进行分组,通过pyecharts可视化后可得到样本数据用户地域分布如下图。
从图中不难看出,样本用户主要分布于东南沿海一带和华北地区,其次是东北地区,少量位于西北内陆。这主要是因为东南沿海和华北一些地区经济相对发达,城市人口基数庞大,极多的荧幕数量和座位、极高密度的排片场次,让观众便捷观影,活跃的观众评论也多,自然也就成为票房的主要贡献者。
我们整理了样本数据中影评数量排名前20的城市,分别为北京、上海、武汉、南京、成都、深圳、西安、广州、天津、重庆、郑州、杭州、沈阳、无锡、合肥、昆明、哈尔滨、常州、长沙、苏州。这些城市都是经济相对发达的城市,从某种角度来讲,这也侧面反映了城市的购买力和城市GDP,说明其消费水平较高,也印证了用户分布图中所得出的结论。
2.2 word2vec提取词向量
为了在深度学习模型中更好的表示影评的文本数据,需将影评文本进行词向量化表示,基于此本文选择python中的gensim模块训练词向量。由于所抓取的猫眼影评数据为中文影评,所以需要一个符合中文语料库的word2vec模型,以完成对影评数据的词向量获取。因此,为了更好地描述影评词语特征,本文直接选取猫眼影评作为训练数据,采用Skip-Gram模型进行训练。训练参数如下表所示,训练维度为64,迭代次数为5次。
在对抓取的影评数据进行表情符号剔除和去停用词等操作之后,将其输入word2vec进行训练,得到模型测试结果如下表,由于训练数据为影评数据,语料库有限,所以在词语的相似度上有一定的误差,但就总体影评效果来看,符合影评总体语言风格。
同时,模型还生成了对应的词向量表和对应的字典。在词向量表中每一个词语都是通过一个64维的行向量所表示的,而词向量字典是后文中将影评分词数据转化为RNN模型可输入数据的基础。
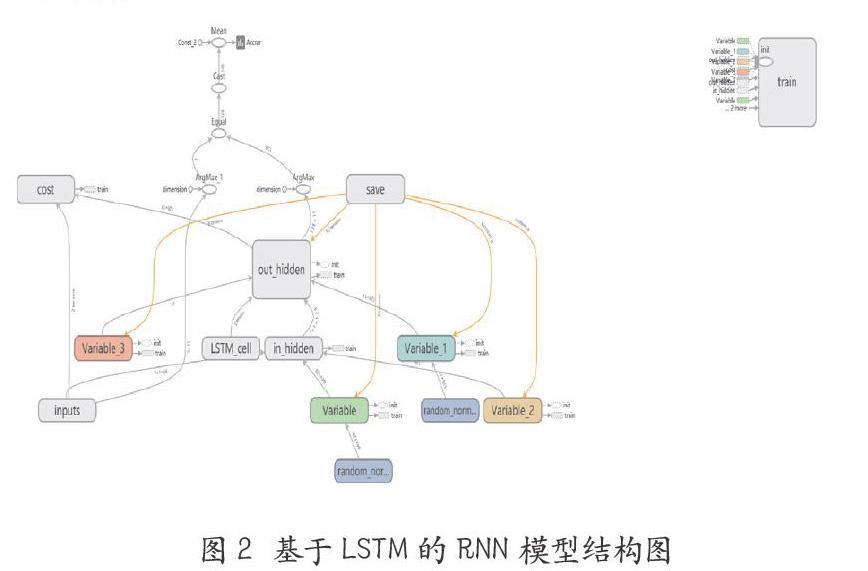
2.3 基于LSTM的RNN模型搭建
通过tensorboard生成的模型结构如下图所示,其中模型整体包括输入层、隐层和输出层,而在隐层中又包含了内部隐层和LSTM细胞状态层。隐层中神经元个数为128,而LSTM细胞状态中又含有四个子层。
其中,模型的关键运算过程位于LSTM_cell模块中,其中包括了细胞状态、RNN的内部神经元结构,以及激活函数等。
2.4 实验结果及分析
在构建好RNN模型后,将清洗过的数据带入模型。模型以用户打分为预测变量,从0到10共分为十一个等级,输入变量为用户评论分词转化而来的向量矩阵,由此在经过多次迭代训练后可以得到模型预测的准确率与成本函数。我们可以得出,随着迭代次数的不断增加,模型预测的平均成本逐渐减少,准确率不断上升,约在12000次后准确率趋于稳定状态,最终预测准确率可达93.75%,说明模型对于影评的用户评分有着很好的预测效果。
而从模型的准确率曲线图来看,模型在训练的迭代前期准确率提升幅度较快,后期趋于平缓,最后逐渐稳定在90%以上水平。
2.5 基于随机游走的改进RNN影评分析模型
由于随机游走词向量多用于做半监督分类模型,所以本节分别选取每种评分的500条数据作为标注数据,共计5500条标注數据,其余数据视为未标注数据。以标注数据为随机游走图中的已知点,对未标注的数据进行随机游走,之后将数据带入RNN模型中进行训练,模型运行结果如下表。
由上表可以看出,模型的平均成本函数以及准确率的变化趋势与上节中RNN模型是一致的;而在准确率上,在迭代前期准确率略低于随机游走改进前RNN模型,而在趋于稳定状态,相比于原模型,预测准确度约提高0.5%。
从上图来看,经过随机游走优化的RNN模型在稳定状态略有提高,虽然随机游走算法对于模型的预测准确率提高不显著,这可能是由于原模型准确率已经很高,导致其提高水平不够显著造成的,但总体来讲,本文实验结果说明,随机游走模型对应预测准确率的提高是有意义的。
3 结论
本文基于深度学习模型,通过对猫眼动漫影评进行数据抓取,完成了对动漫影评的自然语言处理处理和用户评分预测。首先通过分析猫眼影评API,利用python中的requests等库对影评数据进行爬取,再通过jieba模块对评论进行分词得到影评的语料库,之后利用gensim中的word2vec模块得到影评词向量矩阵,在将影评数据转换为嵌入式矩阵后,完成了对数据的预处理工作。接下来搭建基于LSTM的RNN深度学习模型,并将影评词向量矩阵和用户评分带入模型,完成迭代训练,最后得到评分预测模型。
参考文献
[1]伍宏伟.基于隐马尔可夫模型的交通流预测研究[D].兰州交通大学,2019.
[2]郑啸,王义真,袁志祥,秦锋.基于卷积记忆神经网络的微博短文本情感分析[J].电子测量与仪器学报,2018,32(03):195-200.
[3]刘娜.文本自动摘要和信息抽取方法及其应用研究[D].大连海事大学,2012.
猜你喜欢
中国教育技术装备(2016年19期)2016-12-27
中国远程教育(2016年11期)2016-12-27
现代商贸工业(2016年25期)2016-12-26
江苏教育·中学教学版(2016年11期)2016-12-21
江苏教育·中学教学版(2016年11期)2016-12-21
现代情报(2016年10期)2016-12-15
考试周刊(2016年94期)2016-12-12
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
软件导刊(2016年9期)2016-11-07
