
预测储量升级潜力优选研究与应用
2020-08-04 01:28张凤东刘景亮黄学斌
科学技术与工程 2020年18期
张凤东, 刘景亮, 黄学斌, 石 磊
(中国石油化工股份有限公司石油勘探开发研究院,北京 100083)
预测储量是指在圈闭预探阶段预探井获得了油气流或综合解释有油气层存在时,根据区域地质条件分析和类比,有进一步勘探升级价值的储量[1]。预测储量发现后,对预测储量进行合理评价和升级是石油公司勘探开发过程中的一项重要任务,它直接影响着勘探开发决策部署和储量接替。因此开展预测储量升级潜力研究具有重要的现实意义。
一些学者对储量升级动用及应用聚类分析方法进行了相关研究。秦伟军等[2]以油气预测储量区块为研究对象,提出了油气预测储量区块升级综合评价方法。采用聚类分析方法,不同学者对储层分类、产能预测、融合算法等进行了研究[3-6]。谭锋奇等[7]以克拉玛依砾岩油藏为例,基于聚类分析方法对储层类型进行了精细划分。也有学者从不同角度对储量替代率预测方法等进行了研究[8-13]。
为此,应用聚类分析方法,将有升级潜力的单元从预测储量中快速筛选出来,不仅能为下一步储量升级动用提供控制储量目标,为勘探开发部署提供决策依据,而且能够提高决策效率、节省研究成本。
1 预测储量升级的影响因素分析
预测储量升级主要取决于储量本身的内在要素及当前的认识程度,如油气藏地质条件、品位和储量规模等[2],而油藏圈闭类型、储层类型、储量丰度、埋深、产能、储量规模等因素对储量升级都有较大的影响。从储层物性来看,孔隙性、渗透性及流体饱和度等对能否升级具有直接的影响,而原油地下黏度及地面密度是决定开发难易的重要条件,也影响储量升级的重要因素。还有政策及外部环境等条件,虽然也会影响储量升级,但在此不作为研究对象。
根据储量升级的主要影响因素,运用聚类分析方法对预测储量单元和控制储量单元进行统计、计算、归类,从预测储量中找出和控制储量相似程度高的储量,从而优选出预测储量单元。聚类分析就是将储量单元分组形成多个类或簇,在同一个类中的单元具有较高的相似度,而不同类中的单元差别较大。核心是通过对多个储量单元特征信息的综合分析,从大量数据中寻找隐含的数据分布规律,将数据体中具有相似地质特征、物性特征、产能等特征的储量单元分为同一类,从而达到在预测储量中找出目前可升级储量的目的。
2 储量升级的聚类分析方法
2.1 聚类分析方法
聚类结果是反映原始数据的自然结构特征,以发现原始数据中某些潜在的联系和特征。聚类算法要使类间对象(样本)的相似性尽可能小,类内对象的相似性要尽可能大,同一类对象具有相近的宏观和微观特征,从而实现聚类的有效划分。常用的聚类分析方法有快速聚类法、系统聚类法和二阶聚类法[12]。
2.1.1 快速聚类分析
快速聚类法又称为k-mean聚类法,是一种迭代求解的聚类分析算法,具有分类高效、易于操作、扩充性好等特点。快速聚类对储量单元分类的基本思路:判断每个单元储量与每类储量的相近程度,然后将其合并到最近的类中。聚类中心以及分配给它们的单元就代表一个类。每分配一个新成员,各聚类中心会根据现有的单元被重新计算。重复再分配的过程,直到每类中心包含的单元不再变化。算法过程:①选择n个初始聚类中心;②计算每个单元与这n个中心各自的距离,按照最小距离原则分配到最近聚类;③重新计算,使用每个聚类中的样本单元均值作为新的聚类中心;④重复步骤②和③,直到聚类中心不再变化;⑤结束,得到n个聚类。
2.1.2 系统聚类分析
系统聚类是聚类分析中常规方法。在系统聚类的过程中,首先判断不同样本之间的相似程度,每次将具有最小欧式距离的两个类合并,合并后再重新计算类与类之间的距离,再次进行合并,直至所有样本都归为一类为止,得到系统最终聚类结果,同时可绘出聚类过程谱系图。
2.1.3 二阶聚类分析
二阶聚类又称两步聚类,主要用来揭示数据内在的自然分组[12]。二阶聚类整个聚类过程分为前后两大步骤来完成,第一步对所有单元进行距离考察,构建聚类特征树,同一个树节点内的记录相似度高,相似度低的则会生成新的节点;第二步,在分类树的基础上,用凝聚法对节点进行分类,每一个聚类使用Bayesian信息准则(BIC)或Akaike信息准则(AIC)进行判断,得出最终的聚类结果。
2.2 聚类分析流程
预测储量升级潜力优选的聚类分析就是以储量单元本身的特性为基础,对比与控制储量的相似性或相异性,并根据这种相似或相异程度将其划分为不同的类。聚类结果要满足合理性及进一步研究的可操作性,既反映同类间性质的相似性,又把和控制储量对象差别大的单元划出去,利于从预测储量中筛选出可升级单元。为此,利用聚类分析方法对预测储量的优选升级可遵循以下流程。
(1)确定所要考察的预测和控制储量单元。
(2)检查整理数据,补齐缺失值,消除异常点,保证数据的完整性、系统性和合理性。
(3)确定性能评估方案,聚类的内部度量标准以及实际评价中对分类精度的要求和深入研究的可操作性。
(4)选择聚类范围,如同一盆地。也可根据需要选择聚类范围,比如细分沉积相,在同一构造沉积相中计算,例如控制储量、预测储量沉积相都选择滩坝砂。
(5)对数据集进行挖掘。
(6)得出计算结果,对聚类结果进行分析。
3 实例计算
3.1 计算变量的选取
首先选取聚类变量。由于参与聚类的变量决定聚类的结果,因此筛选有效的聚类变量非常重要。从影响聚类的多种因素中抽取相关性强的变量进行类比,以对所有样本数据进行有效分类,进而从中优选出目标单元。
把选择的456个预测储量单元和946个控制储量单元放在一个系统中作为数据源,运用SPSS统计分析软件,对系统中的样品集数据进行快速聚类。选择计算单元名称作为标注个案,把地质储量、有效厚度、油气藏埋深等15项数值型参数作为计算变量,使用k-mean聚类法对大系统中的数据进行迭代计算,直至所有类中心收敛。计算结果如表1所示,方差分析F检验值及显著性表明各参数对聚类分析的显著影响程度。
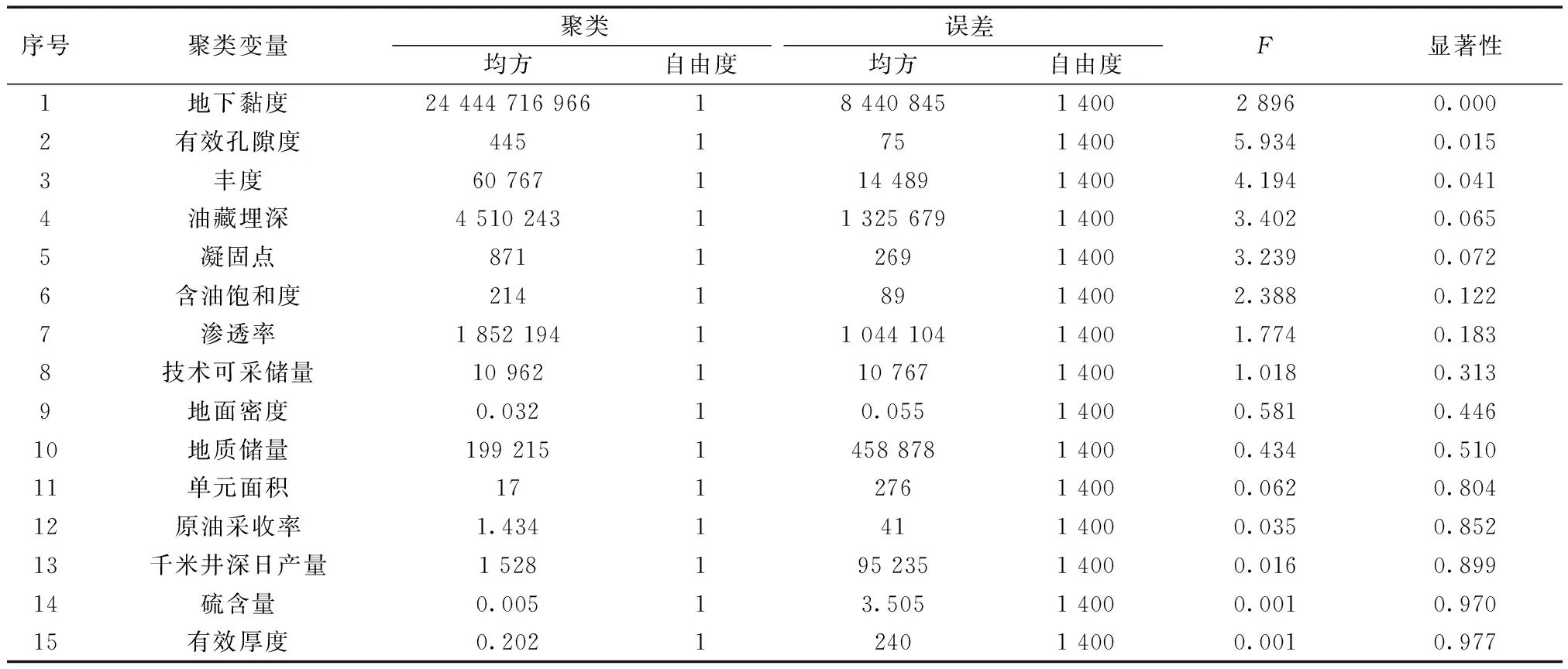
表1 聚类变量筛选方差分析Table 1 Analysis of variance of cluster variable selection
依照聚类均方应大于误差均方的原则,根据F检验值和显著性大小聚类计算结果,确定储量单元聚类的主控因素主要为:地下黏度、有效孔隙度、丰度、油藏埋深、凝固点、含油饱和度、渗透率、技术可采储量、地面密度、地质储量,其次为单元面积、采收率,而千米井深日产量、硫含量和储层有效厚度的F最小,类间处理的不同带来的差异小于类内个体差异所带来的差异,故在聚类分析时去除该3类变量,保留其余12项变量参与聚类分析。
3.2 聚类计算结果分析
再选取2017年渤海湾盆地稀油油藏366个保有控制储量单元、118个新增预测储量单元,共484个单元作为样本分析的数据源,采用快速聚类法对各储量单元进行计算,根据距离和相似性逐次分解、合并,经多次集群至所有类中心收敛,把所有单元分类到不同的类中得出最终聚类结果。
如表2所示,聚类计算把20个预测储量单元和175个控制储量单元归为一类, 表明该20个预测储量单元和控制储量单元具有较高的相似性,这为下一步升级动用提供了明确的优选目标。在选出的这20个预测储量单元其中,经实际验证,截至2018年底已有永斜558、利943、桩海111(5)等9个单元升级为控制储量单元,升级率已达45%。可见通过聚类分析优选潜力预测储量单元具有较高的准确度。表2为选出的11个预测储量单元及9个证实已升级为控制储量的预测储量单元。
聚类结果方差分析如表3所示。从表3可以看出,各变量聚类均方差都远大于误差均方差,且显著性水平均远小于0.05,说明拒绝12个变量使各类之间无差异的假设,表明参与聚类分析的12个变量能很好地区分各类,类之间的差异足够大,能够较好地把具有相同特征的单元归于一类,同时把不同类的单元分开。
通过系统聚类,能够表明聚类的整个过程及各类之间的距离。冰柱图代表了不同类的聚集过程,把所有单元的聚类过程直观地表现出来。从冰柱图可以看出,选出的桩海111(5)、桩海111(4)、桩海111(3)、桩海111(2)等目标单元,在聚类过程中经不同次的聚类计算,最终归为同一类。图1为一部分单元的聚类过程。
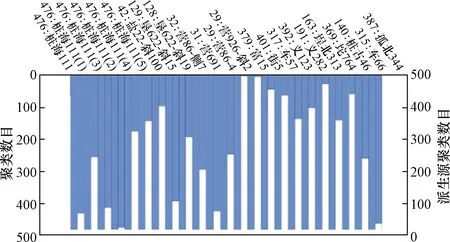
图1 系统聚类分析冰柱图Fig.1 System cluster analysis icicle diagram
4 结论
(1)影响预测储量升级的主要因素是储量本身的内在品质及认识程度。计算表明影响储量单元聚类的主控因素为:黏度、有效孔隙度、丰度、油藏埋深、凝固点、含油饱和度、渗透率等要素。
(2)聚类分析根据储量本身属性定量确定各储量单元之间的亲疏程度并进行归类。应用该分析技术,不仅能对可升级预测储量进行早期识别,加快储量升级动用节奏,为勘探开发部署提供决策依据,而且能够节省研究人员时间和精力,降低研究成本、提高决策效率。
(3)利用聚类分析方法选出的预测储量,作为具有优先升级潜力的单元,还需结合圈闭构造、储层连续性及评价井试采等认识确定当前预测储量能否升级为控制储量。
猜你喜欢
家庭影院技术(2021年9期)2021-11-05
资源导刊(2021年10期)2021-11-05
矿产勘查(2020年4期)2020-12-28
矿产勘查(2020年2期)2020-12-28
石油与天然气地质(2020年4期)2020-08-14
金桥(2020年12期)2020-04-13
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
现代计算机(2016年17期)2016-02-28
小学科学(2015年8期)2015-09-06
