
基于深度学习技术的磁共振成像研究进展
2020-08-04 08:57罗伶俐王远军
中国医学物理学杂志 2020年7期
罗伶俐,王远军
上海理工大学医学影像工程研究所,上海200093
前言
磁共振(Magnetic Resonace,MRI)成像是具有高空间分辨率,成像过程无电离辐射的一种无创性诊断工具,在临床医学影像诊断中具有重要作用。但因扫描时间过长,对于需获取瞬间信息的组织器官,会由于器官运动而产生运动伪影,因此动态MR成像的时间分辨率很差[1]。因此,为减少MRI扫描时间而对k空间进行欠采样,但由稀疏数据重建的图像易产生混叠伪影,对此有两种解决方法:一种是平行成像(Parallel Imaging,PI)[2],主要利用多通道接收线圈的灵敏度编码,与全采样条件下成像图像像素之间的映射关系来消除混叠伪影;另一种是基于压缩感知(Compressed Sensing,CS)原理的图像重建算法[3],利用信号在变换域中的稀疏性,通过非线性重建算法来消除伪影。
但随着大数据时代的到来及计算机硬件的飞速发展,近年来人们开始重视深度学习的作用,深度学习在计算机视觉和图像处理等领域均获得了巨大成功。而在医学成像领域也引起了广大学者的重视。近年来许多学者将人工神经网络(Artificial Neural Network,ANN)应用到MR快速成像中。本文着重介绍深度学习在MR成像中的几种不同应用方式,对该成像方法做出回顾性总结,并对其在未来的应用做出展望。
1 深度学习在MR成像中的应用
1.1 基于图像域学习的MR成像方法
基于图像域学习的MR 成像方法主要通过学习伪影图像与去伪影图像之间的映射关系来消除图像中的伪影。其中较为典型的是基于多层感知器(Multilayer Perceptron,MLP)的MR 快速并行成像方法[4‐5],该模型基本结构见图1[6]。Golkov 等[4]设计的MLP 结构中减少了所需的扩散加权图像的数量,以适应扩散MR 成像的q 空间模型。Kim 等[5]则减少MLP 结构所需的相位循环图像的数量,以去除带状伪影。Kwon 等[6]则在PI的基础上将MLP 结构进一步应用到各类数据采样模式下,以评估该模型在不同采样模式下的适用性。
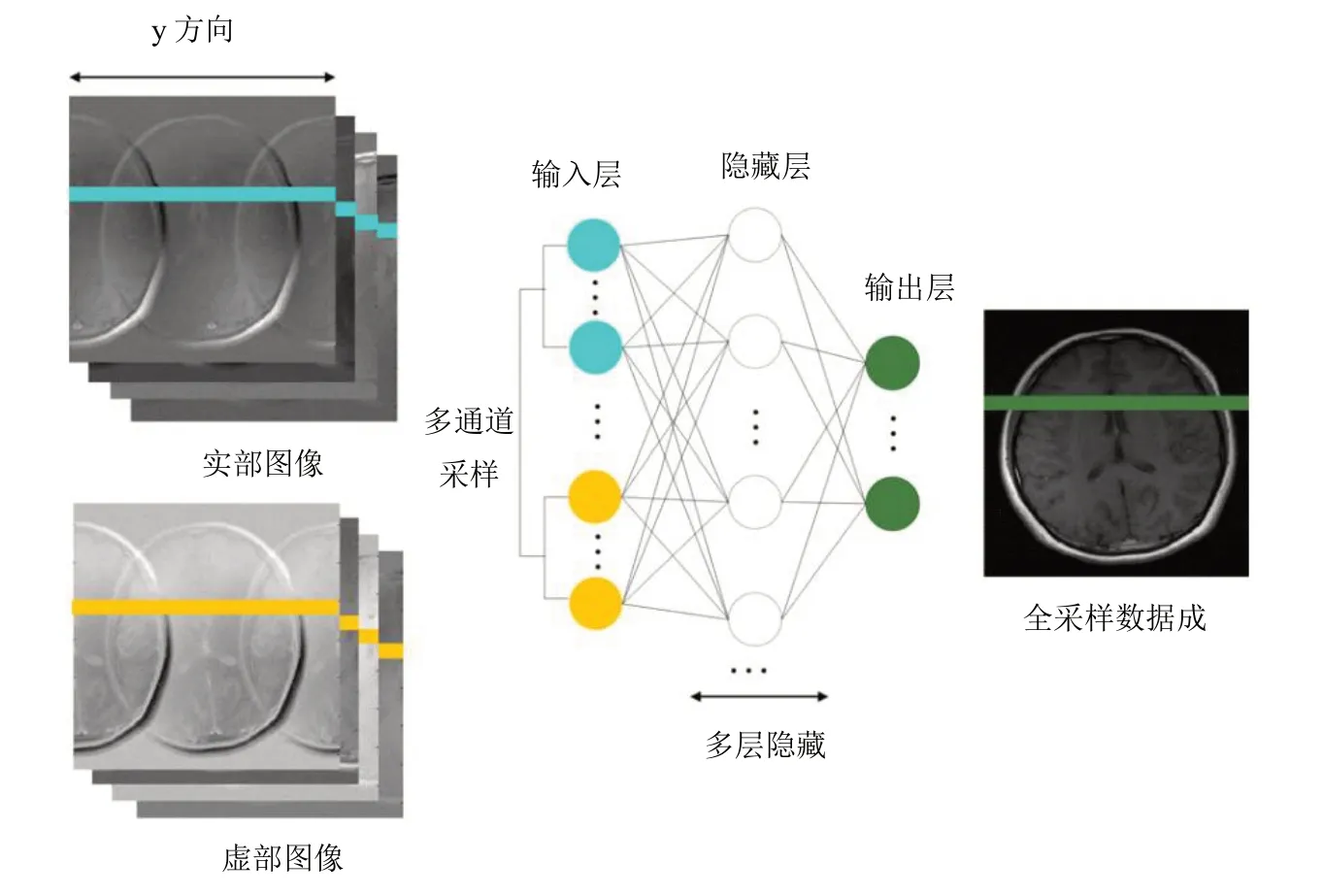
图1 基于MLP结构的MR成像方法Fig.1 Magnetic resonance imaging based on multilayer perceptron structure
MLP应用于MR快速成像呈现了巨大优势:由于训练后的参数模型比手动设定的特征或全局变换能更有效地拟合训练数据,因此可从高度欠采样的k空间数据中恢复图像。此外,不同于传统迭代算法,基于MLP的训练网络无需利用先验信息多次迭代以保真数据,只包括内积运算和最大化运算,因此成像速度很快。 同时在没有自动校正数据(Auto‐Calibration Signal,ACS)的采样模式下,该方法仍能有效消除噪声,快速成像。
除了以上方法,Wang 等[7]设计的卷积神经网络(Convolutional Neural Networks,CNN)旨在抑制由二维伪随机采样产生的类噪声混叠伪影。Chaudhari等[8]设计了一个20层的CNN,在实现精准生物标记而提高图像信噪比的同时可实现亚毫米级的高分辨率。Schlemper等[9]为更好地评估ANN在成像应用中产生的偏差,引入贝叶斯深度学习,以对ANN能否生成理想图像进行建模。Lee等[10]则将残差学习引入到MR快速成像中。可见目前基于图像学习的MR成像方法有很大的研究进展。但非线性重建算法的通病在于重建图像易产生结构相关伪影。另一方面,此类方法不能处理意外情况下未经训练的数据(例如改变成像视野和输入图像的大小)。因此基于深度学习方法的大部分模型有待进一步提高以应对潜在变化的输入数据。
1.2 基于k空间数据学习的MR成像方法
基于k空间数据学习的成像方法主要通过ANN对欠采样k空间数据进行插值后,再进行成像。目前就传统重建算法而言,k空间数据插值最前沿的方法之一是基于零化滤波的低序汉克尔矩阵方法(Annihilating Filter‐based Low Rank Hankel Matrix Approach,ALOHA)[11‐12]。其基本思想是:若图像域的底层信号是稀疏的,且可被表示为有限更新率(Finite Rate of Innovations,FRI)为s的信号,则由其k空间数据ˆ构建的汉克尔矩阵Hd(ˆ)(d表示该矩阵束大小,d<s)是低秩的。若ˆ中的数据丢失,则可通过带有丢失数据的低秩汉克尔矩阵来恢复数据[13]。
但该方法的计算量太大,且汉克尔矩阵的存储占用了很大的内存空间。为解决这些问题,Han等[14]在此基础上引入了深度学习方法,提出了DeepALOHA 网络:将欠采样k空间数据ˆ作为输入数据,用白化滤波器ˆ将输入数据转变为FRI信号,即,后由CNN 来填补k空间中缺失的数据,再除以原来的权重,即,得到插值后的k空间数据结构ˆ,经傅里叶逆变换后可得到理想图像。同时为应对非线性采样的情况,对输入数据进行了重栅格化的预处理。该模型结构见图2[14]。

图2 DeepALOHA网络模型Fig.2 DeepALOHA network model
该网络经有效训练后,在不同的采样模式下均能进行高效的成像。且相比同条件下基于图像域学习的MR成像方法,基于频域学习的成像方法生成的图像质量更高,与原图的偏差更小。Cha等[15]在此基础上,将深度学习方法进一步引入到MR血管造影并行成像中,采用了能够有效维持图像细节的紧框架U‐net(Tight‐frame U‐net)用于对欠采样k空间数据进行插值校正[16]。该方法在有效提升图像空间分辨率和时间分辨率的同时,大大缩短了成像速度。由此可见,基于k空间数据学习的成像方法相较常见的并行成像技术(如GRAPPA、SENSE 等)提升了计算效率,为MR快速成像提供了一种新的思路。
1.3 保障图像域与对应频域数据一致性的成像方法
基于图像域学习的MR 成像方法更倾向于图像去噪,未能充分利用到频域数据,因此导致网络生成的图像无法与原始频域数据联系起来。为保证频域数据与图像域数据的联系,Schlemper 等[17]将数据一致层(Data Consistency Layer,DCL)引入到了基于级联网络(Cascaded Network)学习的MR 成像方法中。此类方法在利用ANN 提升图像质量后,将图像域中改善后的信息回馈给原始的k空间数据,后再进行最终图像。
1.3.1 数据一致层对于训练参数为θ的神经网络fc,输入值为带伪影图像xu,输出值为期望图像xt,其关系可表示为xt=fc(xu|θ)。两幅图像对应的频域数据可表示为:yt=Fxt,yu=Fxu,F 表示傅里叶变换,对k空间数据的修正如下:
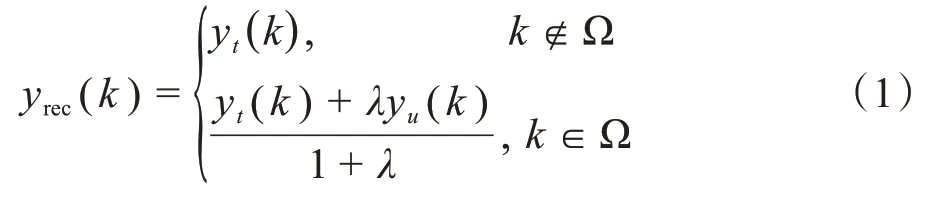
其中,Ω 为采样掩膜,在无噪声环境下(即λ→∞),用原始k空间中的数据表示yrec中已采样的数据,即将不属于采样掩膜Ω 下的频域数据填补进k空间。之后可对作傅里叶逆变换后可重建图像。
1.3.2 DCL的应用Schlemper 等[17]参考字典学习(Dictionary Learning, DL)的成像模型结构[14],提出了一种级联网络结构,即交替地连接CNN与DCL,结构见图3[18]。相比基于CS 理论的MR 成像算法中较前沿的字典学习方法(DLMRI),CNN 中的大部分参数可通过训练进行调节,自由度大于DL 中的参数,因此可在提高计算效率的同时学习到更精准的数据转换方式,从而进一步提高图像精度。
在此基础上,Schlemper等[19]将基于CNN和DCL的级联网络进一步应用到MR动态成像中,并取得了不错的快速成像结果。Knoll等[20]对该级联网络中的DCL 层进一步修改,并用U‐Nets 替代了CNN 以消除由CNN 带来的图像伪影,该方法被用于距扫描的CT稀疏角度成像算法中,保障了图像数据与频域数据的紧密联系,且更好地保存了图像整体结构。Dedmari 等[21]则引入了DenseNet,结合DCL 进行快速MR成像,结果显示该方法在无需大量训练的情况下,对不同欠采样率的情况呈现了很好的鲁棒性。可见DCL 有效保障了不同数据之间转换关系,预防了因单独处理图像域数据而造成数据转换关系脱节的情况,进一步提升了重建图像的质量。
1.4 基于流形逼近的自动转换MR成像方法
MR成像问题主要在于解决频域数据和时域数据之间的转换问题。通常对于线性采样的MRI而言,实现数据域转换的常见方法是傅里叶变换。而对于非线性采样的MRI成像而言,单凭傅里叶变换进行成像是远远不够的,由于多重因素决定了重建图像的精度,需利用迭代算法结合先验信息进行图像重建,但误差依旧很大。若找到频域数据与图像域数据之间精准的映射关系能大大简化MR图像重建过程。为此,一种基于深度学习的端对端成像方法应运而生。Zhu等[22]提出了一种基于流形逼近的自动转换(Automated Transform by Manifold Approximation,AUTOMAP)成像方法,该方法无需其他先验信息,主要通过监督学习的方式,在进行大量训练的基础上学习频域数据与图像域数据间的映射关系。
实现AUTOMAP 的深度神经网络主体结构见图4[22],主要由全连接层,卷积层和反卷积层构成。其中全连接层用于估计频域数据与图像域数据之间的流形映射关系,卷积层用于提取图像中的高级信息,反卷积层则用于将提取到的特征进行可视化,输出最终图像。同时流形学习的引入更有效率地处理高维空间中的数据分布:将输入数据x在进行训练之前映射到流形X上,该网络在学习输入流形X与输出流形Y之间的映射关系后,将输出流形Y映射到欧氏空间中以显示图像y。
基于AUTOMAP 的MR 成像方法相较传统的迭代重建算法,能更有效地去除图像伪影,且对噪声更鲁棒。Knoll等[23]将该方法引用到了生成式对抗网络中以消除MR心脏成像中的运动伪影,结果表明该网络的表现远远优于传统的图像重建去噪方法。但由于网络中的多层全连接层导致待训练参数量很大,从而占用了大量内存。为解决这个问题,Oh 等[24]尝试用循环神经网络(RNN)来替代AUTOMAP 深度网络中的全连接层以大大减少待训练的参数量,同时RNN 能在不使系统过载的情况下,将前序信息反映到下一时间步的输出结果中,加强了深度神经网络中前后序信息的紧密联系,也保证了图像重建精度。
AUTOMAP的提出为MR成像的不同数据域转换问题提供了新的思路:即无需相关数据域转换的知识,就可将任意编码环境下的数据(如用于CT成像的欠采样投影,用于MR成像的欠采样k空间数据等)进行转换以重建图像。因此该方法可被广泛应用于各类医学设备的成像算法中(如CT、超声成像、PET等)。
2 总结与展望
本文简要介绍了4 种基于深度学习的MR 快速成像方法,这4 种方法大体上可分为两类:一类是利用ANN对频域数据或图像域数据进行数据校正或去噪去伪影的操作,即ANN 的输入输出数据均为同一数据域上的数据,后经傅里叶变换实现MR 快速成像;另一类则是摒弃了常用的傅里叶变换,通过流形学习的方式学习频域数据与图像域数据之间的精准映射关系,即AUTOMAP。
以上方法的共同点均在于:相比传统图像重建算法,基于深度学习的成像方法进一步提升了图像重建精度及重建效率。但对于同一类情况下的数据分布,ANN 训练周期较长,且不善于处理未经训练的意外数据,如改变采样方式或视野大小等参数情况。目前虽然基于深度学习的成像方法取得了很大进展,但要走向实际的临床应用中,仍面临着很多问题。随着计算机的硬件发展及算法性能的优化,基于深度学习成像方法是未来磁共振,乃至各类医学影像设备快速重建算法的重要发展趋势。
猜你喜欢
吉林大学学报(理学版)(2022年2期)2022-05-30
中国医疗设备(2022年3期)2022-04-01
中西医结合心血管病杂志(电子版)(2020年24期)2020-12-19
中西医结合心血管病电子杂志(2020年24期)2020-10-20
炎黄地理(2019年1期)2019-09-10
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
科技风(2018年1期)2018-05-14
科技传播(2011年8期)2011-08-15
滨州医学院学报(2010年1期)2010-03-30
