
基于Camstyle改进的行人重识别算法
2020-08-03 10:05张师林
计算机工程与应用 2020年15期
张师林,曹 旭
北方工业大学 城市道路交通智能控制技术北京市重点实验室,北京 100144
1 引言
行人重识别是广域视频监控中的一项重要任务,其目的是跨摄像头识别出同一个人,在交通、公共安全和视频监控方面发挥着重要作用。如果当前有一个需要查询的人,行人重识别任务需要从部署在不同位置的多个摄像头收集的数据中排列出最可能的目标。行人重识别难点在于人体姿势、照明和视野的不同所引起的行人姿态和外观的变化,摄像头的差异性是也一个重要的因素,它对行人重识别的准确性有很大的影响。本文是基于Camstyle[1]实现的,利用传统方法,如kissme[2]、xqda[3]等很难去解决以上问题。近年来,深度学习方法[4-8]得到了很好的效果,文献[4]提出了预训练卷积神经网络模型在行人数据库上进行微调的方法,从而得到高维的深层行人特征。以上方法都利用深度学习得到特征,将行人重识别作为一项排名任务。
有限数量的样本和不同摄像头存在的差异使深度学习的方法没有更好体现其优势。根据文献[9]总结,在数据集Market-1501[10]中每个人的样本数量平均只有17.2张图片,数据集CUHK03[11]样本数量为9.6张图片,数据集DukeMTMC[12]样本数量为23.5张图片,这将导致深度学习方法出现过拟合现象。为了克服这些问题,在CycleGAN[13]启发下,提出了摄像头风格学习的方法。在一组摄像头收集的图像样本中,每个摄像头收集的图像样本都可以通过CycleGAN网络转换成其他摄像头风格的图像。在Market-1501中,数据集的收集是由6个不同位置的摄像头完成的,1个摄像头拍摄的图像通过CycleGAN网络可以被转换为其他5个摄像头的风格,转换后的图像使用其原图像的标签,真实的图像和转换风格后的图像组合成新的训练集。如图1所示,引入摄像机风格转换图像,深度学习模型可以学习更多的特征,得到更丰富的行人信息,本文方法应用triplet loss做度量学习获取有区分力的特征,两者结合可以增加类内样本的多样性,使类内更凝聚,增大类间距,并提高模型的泛化能力。

图1 Market-1501数据集风格转换后分类结果
全局特征学习是从图像样本上提取代表全身的特征信息,并得到最显著的外观线索以此来表示人的身份信息。但是,在多变的环境中,一些重要的细节信息往往被忽略,这可能会影响识别的准确性。为了解决这一问题,本文提出了多粒度损失来增强摄像头风格学习得到的特征信息,以此方法可以将全局信息和局部信息在不同的粒度上相结合,得到更多的细节信息,对全局信息补充,并一定程度上降低行人样本不对齐对识别准确度的影响。训练样本由粗粒度到细粒度划分如图2所示,不同粒度的分区使信息内容有多样性,通过多粒度特征和全局特征相结合,可以得到更有区分力的行人特征。

图2 多粒度分割
本文方法的贡献主要有两方面。首先,提出了摄像头风格学习,它不仅消除了摄像机的风格差异,减少了CNN过拟合的影响,还增加了训练样本的多样性,提高了模型的泛化能力。其次,将多粒度特征和全局特征结合起来,得到更多的细节信息,对全局信息进行补充,并提高识别准确度。实验结果表明,该方法具有良好的性能。在Market-1501数据集上,Rank1的准确率为96.1%,mAP的准确率为93.8%,获得了当前已发表最高准确度。
2 相关研究工作
随着深度学习的不断发展,很多深度学习的方法在行人重识别领域被提出,如文献[14-18],文献[14]提出了一种基于特征融合的行人重识别方法,融合后的特征对行人图像具有更好的表述能力。文献[16]提出超分辨率特征映射的方法,可以使低清的probe图像得到高清特征。训练分类模型是一种有效的方法,可以充分利用行人的标签,如文献[19-25],文献[19]提出了IDE方法,将行人重识别问题作为图像分类问题,并使用了ImageNet[26]预训练模型。文献[27]随机擦除输入训练样本图像中的矩形区域,可防止模型过拟合,使模型更具鲁棒性。文献[28]从其他数据集中随机选择伪积极样本作为附加训练样本,结合局部特征得到一个更有区分力的行人特征,并提出RPP方法,对局部特征重修正调整。
2.1 生成对抗网络
获取数据困难和容易出现过拟合是行人重识别的重要问题,针对这些问题,人们提出了几种基于生成对抗网络的数据增强方法和正则化方法。文献[9]提出LSRO方法,将GAN网络生成的无标签虚假图像与真实有标签的原训练集结合作为新的训练集,以实现半监督学习。文献[29]使用GAN网络实现跨数据集的背景迁移。姿态多变性是行人重识别的难点之一,为了克服这个问题,文献[10]使用GAN网络生成了8个姿势的图像样本,用来代表所有摄像头视角的行人姿势。文献[30]使用条件GANs学习从输入到输出图像的映射。文献[31]提出了新的GAN网络SPGAN,它可以将生成的图像结合行人重识别loss来解决区域偏差问题。文献[32]提出了一个新的数据集SyRI,通过更改HDR等参数,可以生成100多个环境中的行人样本数据。文献[33]提出区域转换网络,在保留原始样本身份的同时,结合多类GAN损失来生成不可见区域的图像样本。Camstyle与本文的工作更为相似,但本文的方法与之不同,Camstyle主要考虑生成样本的质量,本文使用triplet loss结合风格转换样本来提高行人重识别的性能。
2.2 行人对齐
人脸对齐已经被深入研究,文献[34]提出了一种无监督方法,根据其他图像的分布来对齐脸部,然后用卷积RBM表述符对该方法做进一步提升。在行人重识别中,对行人进行检测时会引入过多的背景信息,还可能出现图像部分缺失的情况,所以,行人对齐是实现更高识别精度的必要方法。早期已经有几个工作提出了行人对齐的方法,如身体各部位对应匹配[2,11],相比与早期的行人对齐工作,文献[25]通过深度学习的方法得到用于仿射变换的6维向量,网络可以自动对输入图像进行矫正,行人对齐和行人识别有一个好的相互作用,行人识别准确度越高,行人对齐效果也会越好,而当行人对齐好的时候,行人识别也会得到好的准确度,此方法相比之前的方法也获得了更高的准确度。以上工作都对输入样本的形态进行了改变,行人图像样本在对齐的过程中会出现一定的扭曲,这样会对识别准确度造成一定影响。与上述工作不同,本文是从另一角度解决行人对齐问题。在文献[35]的启发下,设计了多粒度损失来解决行人对齐问题。
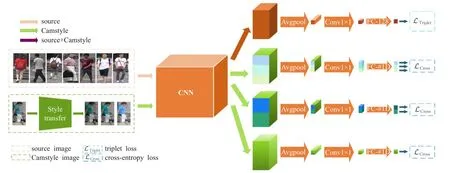
图3 网络结构图
3 方法实现
本章将分别介绍网络结构和方法的实现过程,总体框架如图3所示。图中分为4分支,第一分支使用triplet loss,其他分支使用cross-entropy loss。
3.1 网络结构
使用resnet-50[36]作为主网络,并使用文献[1]中的训练策略,该策略使用Imagenet[26]为预训练模型。对resnet-50做了一些改变:(1)全局平均池化层之前的结构与resnet-50模型相同保持不变,只将最后一个卷积层的卷积步幅改为1,不同于Imagenet的多物种分类,行人重识别可以归属为细粒度的类内识别,卷积步幅为1可以得到更多的细节特征,更好地表述不同人的信息。(2)删除了全局平均池化层并改为对应不同分支的池化层,(3)在主网络后添加了一个1×1卷积层和一个全连接层。卷积层用来减少特征维度,卷积后,通道数从2 048变为256,然后接BN层[37]并使用ReLU激活,BN层用于参数归一化,并缓解过拟合。全连接层有两种,一种的输出维度是128,用于triplet loss度量学习,命名为“FC-128”,另一种的输出维度等于训练集中行人身份的数量,用于cross-entropy loss分类,命名为“FC-#ID”。
在图3中,包含4个分支。第一个分支的输入为原训练集样本和由原训练样本风格转换后的样本。在训练过程中,将原训练集样本和风格转换后样本归为同一身份标签。其他分支与第一分支的不同处包括有:(1)它们含有不同的粒度。第一个分支使用全局特征,而第二个分支和第三个分支分使用局部特征,最后一个分支没有分割,但使用了不同的损失函数。(2)全连接层由“FC-#ID”代替“FC-128”。(3)使用cross-entropy loss代替triplet loss。所以,网络有两个损失函数:用于分类的cross-entropy loss和用于相似性度量学习的triplet loss。对于有标签的训练集样本,IDE[19]是有效的训练方法,可以利用cross-entropy loss将训练过程转化为一个分类问题,cross-entropy loss可以表示为:

ns表示每一批次送入网络训练的样本数量,pi(y)是输入样本类别属于y的概率值。
对于相似性度量学习,采用了文献[38]中的triplet loss,triplet loss可以设置margin,margin可以控制正负样本的距离,使类内距离趋小,类间距离趋大,当行人图像特征归一化后,可以通过设置阈值来更好地判断行人身份是否属于同一个ID,结合CycleGAN生成的数据,训练样本增多可以使triplet loss不易出现过拟合现象,提高训练后模型的泛化性,公式可以表示为:

X表示为在一批次中训练时输入的图像,xa是一个锚点,xa和xp属于同一类别,它们形成了一个积极的训练对,xa和xn属于不同的类别,它们形成了一个消极的训练对,m是一个距离参数,它可以拉近同类别之间的距离并限制不同类别之间的距离,d(⋅)表示两个图像样本在特征映射空间的欧式距离。设置m为0.3,并将全连接层FC-128的输出特征作为嵌入特征用来计算triplet loss。
3.2 摄像头风格学习
由不同摄像头造成的图像风格变化是影响行人重识别准确性的重要因素。在训练集中,同一身份行人的样本数量很少,但包含了很多的图像风格,这样训练后的模型不会对行人图像产生一个好的特征表述,为解决这个问题,采用摄像头风格学习方法。真实图像和摄像头风格学习生成的图像示例如图4所示,训练集被增强为原图像和风格转换图像的组合,生成的虚假图像填补了真实数据点之间的空白,并在特征空间中扩展了类边界,增强后的数据集可以使生成的嵌入特征对类别的分布有一个更好的表述。

图4 风格转换
本文方法中,通过摄像头j(j∈1,2,…,C)收集真实图像样本xs,j,C是所用数据集中使用摄像头的数量,{xs*,i|i∈1,2,…,C⋂i≠j},在训练过程中将xs,j和生成的假图像设置为同一类别。为简单起见,省略了摄像头的下标,使用真实图像样本联合生成的假图像样本来计算triplet loss,损失函数可以表示为:

ns是一个训练批次中真实图像样本的数量,ns*是生成的图像样本的数量。在实验中,如果数据集是被C个摄像头收集的,那么对于每一个真实图像样本都会生成C-1个假图像样本。

λ为损失函数LT所占的权重,triplet loss是必不可少的,它可以使模型获得更有区分力的特征,如果没有triplet loss,训练后得到的结果会受到很大的影响。
如图5所示,图中用softmax表示cross-entropy loss,如果只使用cross-entropy loss,会出现类内距离大于类间距离的现象,影响识别准确度,通过结合triplet loss,可以使类内距离更紧凑,增加类间距离,提高识别准确度。

图5 加入triplet loss对分类效果的影响
3.3 多粒度损失
在行人重识别中,用于训练的图像样本是通过摄像头拍摄的,场景比较复杂,全局特征得到的是一个整体性的图像表述,这样去区分图像的前景和背景就比较困难,特别是当有遮挡,光线剧烈变化等情况发生时,全局特征可能就被破坏了,以上分析可知,只考虑全局特征可能会忽视掉重要的细节特征。在3.2节的基础上,将多粒度特征与全局特征相结合,不同的分区数量,代表图像信息的多样性,随着分区数量的增加,局部特征能够更集中地去表现所在分区的特征信息,从而过滤其他区域的信息,这样可以学习到更多重要的细节信息,并且通过不同粒度的结合又不会丢失局部信息与整体信息的联系。如图3所示,模型的网络结构以resnet-50为主干,替换其全局平均池化层后接分支网络,四分支共享主干的网络参数,所以增加多粒度后模型计算的复杂度不会提升很多,第一个分支损失函数可以表示为LT,其他分支可以分别表示为,Cross-entropy loss函数可以表示为:


上面的损失函数包含有7个损失,LCross为第二、第三、第四分支所有损失函数的集合,它包含了6个损失,具体表示形式为公式(5),λ是损失函数LT的权重,改变λ值对识别准确度有较大的影响,图6显示了使用不同λ值对重识别准确度的影响,这里设置λ为0.1。LT为第一分支的损失函数,用于样本间的度量学习,可以得到更有区分力的特征,具体表现形式为公式(3)。多粒度损失结合摄像头风格学习能更好地表述图像的细节,降低相机差异的影响。
3.4 均衡采样策略
行人重识别数据集由不同人的图像组成,每个人都有不同数量的图像样本。通常情况下,每批次训练并没有对每个ID的样本数量进行限制,训练数据是从全部训练集中随机选取的,这样就会使输入的训练数据对于每个ID不平等,拥有更多图像样本的ID训练的次数就越多,图像样本越少的ID训练得越少。
这样训练出来的模型会对拥有更多图像样本的ID提供更多的信息,但是每个人都应具有同样的重要性,应该受到平等的对待,所以,引入了均衡采样策略。对于每一批次的训练样本,随机选择P个不同的人,对选择的每一个人随机抽取K个训练样本,这样每一批次的训练图像样本个数为P×K,在所有ID都被取样之后,认为完成了一个epoch。这种均衡采样策略与文献[38]中提出的策略相似,但在本文中是使用它来消除类之间的不平衡。这样,对于有更多图像的人,只是忽略了图像多出的部分,以后的采样也能抽取到未被采样的样本,而对于图像较少的人,可以多次使用相同的图像,这种方法保证在训练过程中每一批次每个ID都有相同数量的训练样本。

图6 λ对准确度的影响
3.5 性能分析
本文通过CycleGAN生成可用于训练的摄像头风格转换图像,增加了训练数据的多样性,结合triplet loss使类内样本更紧凑,增加类间距离,减少类内距离大于类间距离的情况,起到了聚类的作用,多粒度特征可以对全局特征做一个补充,学习全局特征可以获得行人图像比较粗糙的信息,对一些细节信息不会有好的表述,多粒度特征可以对行人图像样本局部区域进行更精细的表述,不同分区的分支所获取的特征结合全局特征形成更有区分力的行人特征,从而提高识别准确度。
4 实验分析
本文主要在 Market-1501[10]和 DukeMTMC-reID[12]数据集中验证了提出的方法,这两个数据集都是大型数据集并对每张图像样本提供了摄像头的标签。
4.1 行人重识别数据集
Market-1501是一个大型的行人重识别数据集,是由校园中的6个不同位置摄像头收集的图像样本组成。它包含了32 668图像样本,这些样本属于1 501个ID。数据集分为两个部分,训练集和测试集,训练集包含12 936个图像样本,它们属于751个ID,测试集包含19 732个图像样本,它们属于750个ID。这些图像由DMP[39]方式获取,所以会有很多的图像并不对齐。训练集中每个ID平均有17.2张图像。测试集中选取3 368个样本作为查询图像,它们分属750个ID,在实验中使用单查询方式评估结果。
DukeMTMC-reID是新发布的多目标多摄像头行人跟踪数据集的一个子集。原始数据集包含8个不同摄像头拍摄的85 min高分辨率视频。本数据集是从视频中剪切行人图像获取的,每120帧剪切一次行人图像样本。数据集由36 411个行人图像样本组成,这些样本属于1 404个ID。与Market-1501数据集的划分类似,数据集包含来自702个ID的16 522个训练图像样本,来自其他702个ID的2 228个查询图像样本和17 661个待匹配的图像库样本。
4.2 实验参数设置
所有实验是在Pytorch框架实现的,硬件基础为GeForce GTX TITAN GPU。
4.2.1 摄像头风格转换模型
对于数据集Market-1501,它是由6个摄像头收集的数据样本,所以需要训练15个CycleGAN模型。对于DukeMTMC-reID,它由8个摄像头收集的数据样本,所以需要训练28个CycleGAN模型。在训练时,输入图像的像素设置为256×256,并且使用随机翻转和随机擦除来进行数据增强。使用Adam[40]优化器进行参数更新,需要训练50个epoch,前30个epoch,辨别器和生成器分别设置学习率为lr=0.000 1和lr=0.000 2,在剩下的20个epoch中学习率线性衰减到零。
4.2.2 行人重识别模型
输入图像大小调整为256×128像素。使用随机剪切、随机翻转和随机擦除做数据增强。将Dropout rate设置为0.5,使用SGD优化器,并将momentum设置为0.9,权重衰减因子设置为5E−4,并将Nesterov设置为true。训练时初始学习率设置为0.06,在训练100个epoch和150个epoch后分别衰减为6E−3和6E−4,在完成200个epoch后停止训练。每一个训练批次分别取64个真实图像样本和32个生成的图像样本,随机选择P个不同的人,对选择的每一个人随机抽取K个训练样本,本文K设置为4,所以对于真实图像和生成图像P分别为16和8,使用真实图像训练分类模型计算crossentropy loss,使用真实图像和生成图像相结合计算triplet loss。在测试中,使用欧式距离去计算查询图像和图像库样本的相似性。
添加多粒度损失,需要在以上基础做适当修改,输入图像的大小调整为384×192像素。训练初始学习率设为0.1,经过50和100个epoch的后学习率分别衰减为3E−2和3E−3,完成150个epoch后停止训练。每一个训练批次分别取32个真实图像样本和16个生成的图像样本。如图3所示,在测试中,将所有分支的输出特征连接在一起作为最终特征,最后进行距离对比排序。
4.3 性能评估
Triplet loss的权重λ是一个重要的参数。如图6所示,当设置λ为0.1时Rank-1和mAP达到了最佳结果所以这里设置λ为0.1。
在表1和表2中将提出的方法分别在Market-1501和DukeMTMC-reID数据集上与已发布的方法进行了比较。与现有技术相比,本文的方法取得了很好的效果。在Market-1501测试中,Rank-1为95.3%,mAP为86.1%,超过PCB+RPP方法分别为1.5%、4.5%。在DukeMTMC-reID上,Rank-1为88.1%,mAP为76.4%,Rank-1超过DNN_CRF方法3.2%,mAP超过PSE+ECN方法0.7%。在Market-1501数据集上使用re-ranking方法后,Rank-1的准确率为96.1%,mAP的准确率为93.8%。
从表1和表2的结果可以看出,单使用摄像头风格学习(CSL)方法,训练后就可以得到更有区分度的特征,在所测试的两个数据集中,结果都好于原Camstyle方法,并且提升很明显。此方法可以获得更多的训练数据,并增加类间距离,减少单使用cross-entropy loss所出现的类内间距大于类间间距的情况,实际效果如图5所示。
在结合多粒度损失(MGL)后,准确度在单使用CSL的基础上又有了可观的提升,在数据集Market-1501上,Rank-1和mAP分别提升了2.1%和7%,在数据集Duke MTMC-re ID上,Rank-1和mAP分别提升了6.6%和14.3%,多粒度损失可以对行人的细节特征做更好的表述,通过不同的粗细粒度,可以增加局部与全局不同维度的关联性,使模型的泛化性进一步增强,从而有效提升重识别的准确度。
在图7中,可以看到在Market-1501数据集上4个查询图像的检索结果,绿色框代表正确为同一身份,红色框代表错误为不同身份,可以看出本文方法能够有效地检索出与查询图像同一身份的人。

表1 Market-1501对比实验结果%

表2 DukeMTMC-reID对比实验结果%

图7 相似性度量排序后可视化结果
5 结论
本文方法对行人重识别主要有两方面贡献。首先,提出摄像头风格学习获得有区分力的行人特征,其次,多粒度损失与摄像头风格学习相结合可以更好地表述图像的细节信息,减少过拟合的影响,并且进一步提高精度。在Market-1501和DukeMTMC-reID进行实验获得很好的结果,超过现有已公开的方法。本方法在初始获取数据过程中需要根据摄像头的数量C训练对应的个CycleGAN模型,需要耗费很多时间,占用计算资源,在多粒度分割时采用硬性的平均分割,并没有考虑分割比例对准确度是否会有影响,接下来会对以下方面做进一步探索:(1)使用StarGAN代替CycleGAN,通过StarGAN实现一区域对多区域的图像转换,从而减少生成训练数据所需要的时间,节约计算成本。(2)增加粒度的多样性,并调整分割比例,测试不同分割比例,不同粒度对识别准确度的影响。
猜你喜欢
粉末冶金技术(2021年3期)2021-07-28
意林(2021年5期)2021-04-18
扬子江(2019年1期)2019-03-08
建筑科技(2018年6期)2018-08-30
小天使·一年级语数英综合(2017年6期)2017-06-07
汽车与安全(2016年5期)2016-12-01
中国交通信息化(2016年5期)2016-06-06
浙江大学学报(工学版)(2016年11期)2016-06-05
应用海洋学学报(2015年3期)2015-11-22
