
钓鱼网站检测研究现状与发展趋势的计量分析
2020-08-03 10:05朱世起努尔布力
计算机工程与应用 2020年15期
朱世起,努尔布力
新疆大学 信息科学与工程学院,乌鲁木齐 830046
1 引言
信息时代互联网用户的爆炸式增长,在给国家注入新的经济增长动力的同时也为恶意黑客带来了新的创收途径。钓鱼网站作为钓鱼攻击最常见的网络媒介,自互联网出现之日起就一直受到恶意黑客的青睐。而钓鱼攻击作为社会工程学攻击的一种,比其他类型的社会工程学攻击具有更高的复杂性与普遍性[1]。在攻击形式上,不同于依赖纯技术手段入侵的黑客攻击,钓鱼攻击往往还利用用户的信任并使用社会工程学通过伪造知名站点的方法去欺骗用户。Jagatic等人[2]指出:有时候一封“友好”的电子邮件会诱使用户在线上透漏更多信息,而这正好迎合了发件者的意图。作为钓鱼攻击的重要一环,钓鱼攻击往往始于一封伪造的电子邮件,通过其中的链接最终将用户导流至套取用户信息的钓鱼网页当中。由PHISHLABS在2018年最新发布的报告[3]中显示:被钓鱼攻击的对象正在由个体上升为组织;通过电子邮件和线上服务进行的钓鱼攻击中,金融机构以21%的占比排在被攻击目标的首位;截止到2017年的年末,以https开头的钓鱼网址数量占比由2016年的1/5上升至 1/3;通过 SaaS(Software-as-a-Service:软件即服务)作为媒介的钓鱼攻击增长速度达到了237%的历史新高。
在2018年第13届APWG(The Anti-Phishing Working Group:反钓鱼攻击工作小组)的电子犯罪研究专题学术会议的论文征集上,给出了网络犯罪经济学、安全相关风险评估、公共政策与法律法规、移动设备的安全性评估等10项有关钓鱼攻击的理论性学术研究研究投稿主题方向。同时,在产业工程性研究方向上给出了攻击方法研究、开源信息获取、网络广告欺诈研究等9项投稿主题方向。可见,尽管目前产业界与学术圈都热衷于寻找应对钓鱼攻击的解决方案,但钓鱼攻击本身并没有得到有效的遏制,且依然造成了巨额的经济损失。而据2018年赛门铁克安全报告[4]指出,通过浏览器传播的挖矿劫持同比去年激增8 500%。整个环节通过网络钓鱼的方式诱导用户点击恶意链接,然后加载挖矿脚本到用户计算机中从而完成劫持。可见,通过钓鱼攻击窃取信息或劫持主机进而牟利的途径,已经从以往的诱导用户输入相关个人登陆信息,继而盗取账户资金、隐私信息或是劫持网页进行无休止的广告弹窗骚扰等,发展到了挖矿劫持等新手段下对个人计算机运算能力的窃取。利用钓鱼攻击进行犯罪的活动范围正在不断扩大。与此同时,诸如SETOOLKIT、WiFiPhisher等开源钓鱼工具的不断涌现,使得进行钓鱼攻击的技术成本和经济成本不断降低。同时也导致尽管有大量的反钓鱼软件,但钓鱼攻击始终无法被真正杜绝。如何运用新的技术手段与思路对不断升级的钓鱼攻击手段进行更有效地识别与遏制,是近几年来一直未能有效解决且受到持续关注的问题。
本文主要采用文献计量分析法,通过统计学、图书馆情报学等方式,旨在解决以下三个问题:
(1)钓鱼网站检测技术关注的热点及核心研究领域是什么?
(2)在钓鱼网站检测技术领域下国际上著名的期刊及研究机构有哪些?
(3)钓鱼网站检测技术在国际上的发展脉络以及未来可能的发展趋势是什么?
2 数据来源与研究方法
2.1 数据来源
为确保论文内容的质量与所调研结果的前瞻性,本文通过文献计量工具进行分析的数据来源于包含相关SCI、CPCI-S与BKCI-S等数据库的Web of Science核心数据合集。使用到的检索关键词如表1所示。

表1 文献检索策略表
考虑到Web of Science的主题检索会检索文章的标题、摘要以及关键字。同时考虑到英文中同一意义的单词在表达时可能存在词性的不同。例如,在表达“评估”意义时,有的文章使用其名词形式“evaluation”,而有的文章则使用动词形式“evaluate”。为避免因词性书写方式不同而导致的查找遗漏,本文在高级搜索中通过使用通配符以及精确匹配符,将表1中的主题词凝练成如下搜索语句:
TS=((phishing OR“fishing attacks”OR“fishing attack”)AND(detect*OR classifi*OR evaluat*OR recogni*OR countermeasure*) AND(algo*OR method*OR mean*OR way*OR tech*OR approach*OR scheme*OR software*OR solution*OR tool*OR model*OR system*))
Web of Science核心数据合集中,被收录的与钓鱼网站检测相关的文献,年代最早起始于2005年。2005年之前虽在其他数据库(例如知网)中有少量钓鱼网站检测文献,因其未收录在Web of Science核心数据合集中,默认为这些文献在国际上影响力较低,故在下文中不予统计。因截止到本文成稿之时,2019年尚未过半无法对2019年全年的文献进行分析。故去除个别2019年的文献,最终从Web of Science核心数据合集得到2005—2018年文献765篇。
2.2 研究方法
借鉴Garfield博士在1955年提出的将文献作为检索字段从而追踪论文创意发展脉络的思想[5]。借助表2所示的工具,从施引文献(Cited References)、被引文献(Related Records)、引用次数(Times Cited)入手,分别解决计量调查的深度、广度以及关注度的问题,完成文献计量的关联图谱可视化分析。通过可视化分析的结果,指引寻找并阅读一定量的代表性文献,总结出较为成熟且应用较为普遍的识别方法,探索在检测钓鱼网站问题上的新方向以及可能的突破点。

表2 文献计量工具表
为了弥补仅仅通过计量工具无法准确地提取论文中所用检测技术的问题。本文采用将邻域内高被引文献人工阅读的方式,将具体的检测方法进行归纳汇总。通过参考计量工具得出的结果,选取具有代表性的文章,将文章中的检测技术与工具得出的热点方向进行对比分析,最终都得出结论。研究方法流程如图1所示。

图 1 研究方法流程图
3 钓鱼网站检测技术的计量分析
共现分析法[7-8]将不同信息载体中的共现信息量化,继而基于不同信息载体中概念特征的相关度得到最终结果。通过共现分析,结合时间脉络分析研究领域的发展过程,可以在一定程度上达到预测研究领域发展趋势的目的。
3.1 基于共词分析的词频数指标计量分析
共词分析法[9]旨在通过统计词语在同一组文献中同时出现的次数,从而间接地概述研究领域的研究热点,属于共现分析法中的一种。词频指代所分析文档中词语出现的次数。使用carrot2工具通过Lingo聚类算法结合TF-IDF词频分析对文献数据的标题、摘要以及关键词进行聚类后做高频短语提取,得到图2。

图2 词频统计发泡图
图2 中的气泡大小与气泡内短语在不同论文中出现的数量成正比。出现频率越高的短语分布越靠四周、同时气泡体积越大,出现频率越低的短语分布越靠近几何中心。通过高频短语可以看出:与钓鱼网站检测技术相关的关键词中,“钓鱼邮件”“钓鱼网站”和“英特网用户”在论文中被提及最多。除此之外“移动设备”“浏览器”和相关的“数据集”也被反复提及。反映出国际上对网络钓鱼的相关检测研究正逐渐从以往的钓鱼行为主导者(邮件、网站)、受害者(英特网用户)转向研究网络钓鱼的媒介(浏览器、移动终端)。“数据集”词频的上升,正面说明了大数据方法正在越来越多的运用到网络钓鱼的检测中来,从侧面解释了“机器学习”词频最高的原因。研究方法相关的短语中,“机器学习”“神经网络”及“视觉相似性”占比靠前,此三者都需要大数据作为支撑,说明以大数据作为基础进行后续工作已经成为一种趋势。在特征相关短语上,“数字证书”“钓鱼URL”与“DNS”三大常规特征排名靠前,说明即使机器学习相关方法的使用普及迅速,但很有可能在创新趋势上是以使用常规特征结合机器学习的方式为主。在剩余高频短语中,“分类算法”“模型提出”“垃圾邮件过滤器”等短语反应了多数论文的最终产出。而“社会工程学”作为网络钓鱼的非技术手段理论支撑,在对网络钓鱼的流程解释上广泛使用,故在摘要中以高频出现。

图3 共现关键词聚类时间轴图
3.2 基于关键词与补充关键词的共现趋势分析
关键词[10]往往能够迅速准确地反映文章的主题内容和重点。Web of Science核心数据库中通过使用聚类算法给每篇文章新增了通过聚类得到的补充关键词(keywords plus)。为了得到钓鱼网站检测技术的发展趋势,追踪每一年在钓鱼网站检测方面所关注重点的不同 。本文借助CiteSpace软件生成关键词及补充关键词的共现网络,人工筛选去除掉诸如:安全(security)、攻击(attack)以及数据集(data set)等几乎任何网络安全领域都会出现的无参考价值关键词,并利用时间轴视图通过关键词及相关领域术语的演变,间接地将发展趋势的演变展示出来最终得到共现关键词聚类时间轴图。
图3中“十字”形节点的大小与此关键词共被引的程度成正比。与关键词节点相连连线的颜色对应关键词出现的年份。

表3 关键词排名表
3.2.1 关键词排名分析
在排名前10的关键词中,随着年代的变化,具有影响力的关键词从最基础的领域类名词(钓鱼攻击、垃圾邮件)不断地向方法性的名词(数据挖掘、机器学习)进行演化,最终演化为钓鱼攻击有可能存在新的被攻击平台(智能手机),如表3。而在2018年的最新论文中,提取出的关键词和主题词更是变更为:手机钓鱼(mobile phishing)、信号检测理论(signal detection theory)以及随机森林(random forest)等。可见,在钓鱼网站检测技术方向上,国际上的主流研究方向正在向如何使用人工智能的方法解决新型移动设备上的钓鱼问题进行转变。结合社会工程学通过手机、智能手表等新型移动设备进行钓鱼欺诈目前正在变得日益严重且亟待解决。
3.2.2 冷门及热点方向趋势分析
由图3作为趋势分析的基础,结合由Carrot2得到的词频聚类结果。将聚类结果尽可能细分,将首次发文时间作为横轴将跟进研究的相关方向总发文量作为纵轴,将该方向下自首发文年份起的发文均值作为气泡半径,背景的蓝色基调代表冷门、黄色基调代表热点。即越是新出现的方向越接近热点,越是发文量大的方向越接近热点,图的左下方至右上方研究逐渐偏热且背景色由冷色转为暖色,从而做出冷门及热点趋势气泡图(如图4~6所示)确定冷热趋势,以求更加清晰地反映研究中的冷门方向与热点方向。
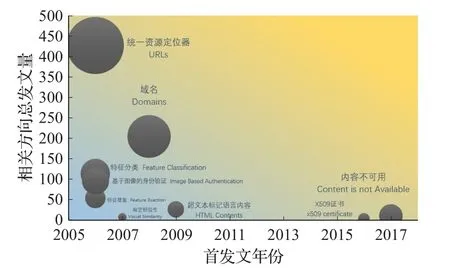
图4 内容研究冷门及热点趋势图

图5 检测方法研究冷门及热点趋势图
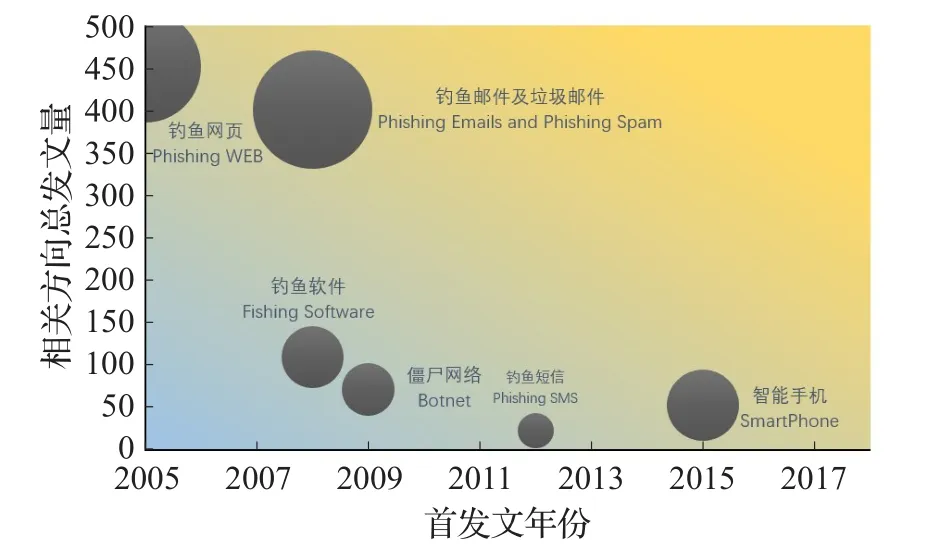
图6 钓鱼媒介研究冷门及热点趋势图
从内容特征(图4)、方法研究(图5)以及钓鱼媒介(图6)三个大方向入手,分别对每个大方向下的小方向做冷门与热点趋势分析。
在内容研究有关的方向上,基于URLs的检测虽然距离提出已经过去较长时间,但依然具有一定的热度。而机器学习方法的提出,一定程度上使得基于URLs、域名已经文本的检测有了回暖的趋势。与此同时,由于网页上图片数量多、难获取且难以让计算机分辨图片内容等因素的影响,基于视觉相似性的检测并没有因机器学习的出现有太大改观。可以预想,如果钓鱼网页图形图像特征数据集得以构建,通过机器学习的方法将视觉相似性作为检测依据将会是不错的冷门方向。最后,近几年越来越多的研究者开始关注证书对鉴别网站合法性的作用。同时,钓鱼网站的诸如加入混淆文本等种种隐匿手段导致的爬虫爬到的数据不可用,也为研究者提供了新的思路,或许被混淆了的不可用数据正是钓鱼网站的另一大特征。这也解释了为何在Lingo聚类算法下会得到“Content is not Available”这样的关键词。
在检测方法上,机器学习的爆发成为了有史以来的最大热点。在机器学习的子分支中,SVM逐渐降温,而主动学习技术往往会使用SVM算法作为基准分类器,从而继SVM开始降温后,主动学习技术逐渐走红有望成为新一轮的热点。同时,近年来利用决策树和随机森林进行钓鱼网站检测有爆发的趋势。潜在语义分析(LSA)作为一个该方向研究方法昙花一现的冷门,有望在将来的研究中作为钓鱼网站溯源的重要手段。
邮件作为工作中交流的重要手段一直是诱导用户进入钓鱼网站的重要入口,近年来以钓鱼媒介为出发点的钓鱼检测研究持续升温。尤其是智能手机出现后,钓鱼链接的散播途径新增了APP内的即时通信散播。由于不同的APP对其用户所发送消息的检测敏感程度不同,所以针对智能手机钓鱼的防范研究是近几年来的新热点。同时,如何甄别通过智能手机APP散播恶意链接的恶意用户也是近几年如何防范智能手机钓鱼大方向下的新的研究方向。
3.3 国家合作共现网络图谱分析
图7中的圆圈节点大小反应发文总量的大小。最外圈紫色圆环的厚度标识中心度的大小,即论文的学术影响力大小,外圈的紫色圆环部分越厚则节点的重要性程度越高。大红色部分标识突发性表征节点,如果研究的内容在短时间内变化频率较高则相应的年轮圆圈变为大红色 。除以上部分之外,年轮圆环部分的颜色对应图片顶部时间轴的颜色,圆圈颜色深浅与环状厚度的不同分别代表不同年代发文量的不同。

图7 国家合作共现网络图
从钓鱼网站检测领域的宏观角度来看,美国、印度和中国占据发文量的前3名,其中美国在总发文量(160篇),中心性指数(0.53)与首次发文年限(2005年)上均占据第一,说明美国在钓鱼网站检测这一领域内与其他国家相比具备更高的理论基础与科研实力。发文量排名前5的国家中,美国(2005)和中国(2006)都在2010年之前提出了钓鱼网站检测的概念,对于该领域有着较早的起步。相比美国和中国,印度虽然发文量第二,但于2011年才发表相关领域的第一篇文章起步较晚。在中心性上,美国(0.53)、英国(0.44)和法国(0.20)占据前3,中国虽然发文总量上超过英国和法国,但中心度指数只有0.12位居第四,可见在论文的影响力方面,我国和世界发达国家相比还具有一定的差距。
3.4 被引期刊排名分析
为对比被引期刊对相关领域的影响力与期刊本身在国际上认可度的关系。使用CiteSpace的被引期刊网络计算出的中心度,作为衡量期刊对相关领域影响力的度量指标;使用评价结果总体与JCR期刊评价标准存在较高的一致性[11],但可以免费使用的Cite Score期刊评价标准,作为期刊在国际上认可度的度量指标;最终提取出文献数量排名前10的被引期刊如表4所示。
在相关发文量排在前10的期刊中:研究方向上,基本都以“工程技术-计算机:软件工程”为主,即钓鱼网站检测方面相比理论研究学者以偏向工程性的研究更多。而在理论研究与工程实践中,以理论研究为主的文章往往具有更高的科技前瞻性与研究深度。所以在中心度上,以理论方法为主的《COMMUN ACM》虽然文献数量相较第一名的《LECT NOTES COMPUT SC》仅达到后者的一半,但中心度却明显高于其他同文献量级刊物。Cite Score的相关性上,因为Cite Score值所反映的是刊物的整体水平而非某领域下研究分支的水平,故中科院SCI期刊分区标准上被评为一区期刊的IEEE COMMUNSURV TUT其中心度(0.08)远远低于小众期刊LECT NOTES COMPUT SC的中心度得分(0.23)。可见,钓鱼网站检测技术的整体研究水平在世界顶尖刊物上还缺乏其他研究领域所达到的深度。尽管目前的研究成果已经趋于成熟,但是尚未有一种方法至少能够在理论上达到根治网络钓鱼的目的。

表4 TOP 10被引期刊排名表
3.5 国内外主要研究机构及代表作者分析
国家科研实力的进步离不开研究机构的贡献,而研究机构中实验室带头人的实力往往可以从侧面体现出机构在这一领域下的研究实力。利用3.3节得到的国家中心度作为各国在钓鱼网站监测技术上的科研实力参考,提取中心度排名前10的国家,并统计寻找其国家内此领域下发文最多的研究机构与机构高产作者,如表5所示。

表5 中心度Top 10国家下其主要研究机构及高产作者排名表
在研究机构上,中国的中科院大学以15篇的发文量远超世界其他各国发文量排名第一的机构。说明中国大学论文的发表在国际上处于一定的领先地位。但与此同时注意到,中国整体的中心度较低即文章在国际上的影响力较弱。根据之前的分析,在钓鱼网站检测相关领域的期刊以工程技术为主。故可大致看出,中国在工程技术方面已经具备一定的实力,在创新程度上与国外相比还存在一定的差距,后期应加大理论方面的研究为接下来的理论创新提供一定的基础。
4 研究热点和趋势分析
钓鱼网站自出现之日起到今天,数量一直呈现上升趋势。钓鱼的手段和对象随着时间的推进不断发展,反钓鱼的手段也在不断更新。但无论如何演变,目前新方法的本质为将基础方法的组合或机器学习实现,现将代表性方法与结合此方法的代表性文章整理如表6所示。
结合3.2节的时间轴图,以关键词过滤后Web of Science核心数据库收录的论文作为统计数据(此过滤条件下收录的论文伊始年份为2005年,故表7中尚未起始时间段为2005年)对本领域的研究热点以及发展趋势归纳如表7所示。
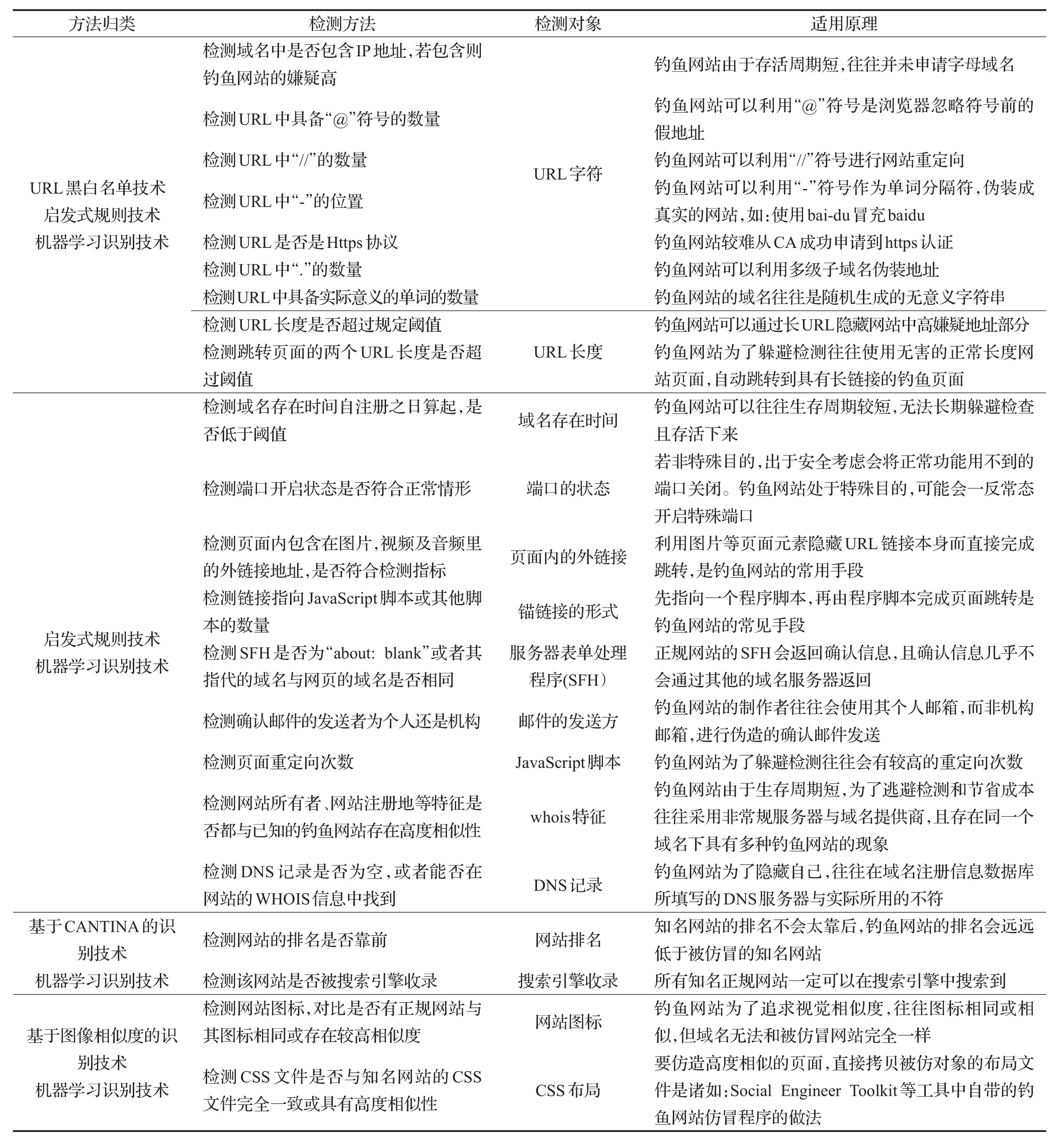
表6 钓鱼网站基础检测方法汇总表
在整个钓鱼网站检测技术发展的第一阶段(方法探索阶段),即是要解决如何选取合适的特征并通过何种技术手段进行特征值的提取问题,换句话说即是特征数据集的构建问题。而在钓鱼网站检查的第二阶段(方法完善阶段),如何通过特征数据高效且准确的得出判定结果成为了新一轮的研究目标。在这一阶段,各种算法的尝试与组合是检测技术研究的主流方向。着重解决在给定特征指标不变的前提下,如何提高检测算法准确性与高效性的问题。随着人工智能技术的兴起,钓鱼网站开始利用人工智能技术对网站的钓鱼特征进行智能化的伪装,传统的高效特征逐渐丧失其优势,而另一些冷门特征逐渐有了检测价值。可见,在钓鱼网站检测技术的第三阶段(方法人工智能化阶段),如何通过人工智能技术与同样开始使用人工智能技术的钓鱼网站进行特征挖掘与特征隐藏之间的博弈将成为新的问题。

表7 钓鱼网站检测方法及研究热点发展脉络表
5 结论
钓鱼网站的检测本质上是对网站进行特征提取后,对所提取特征所做的检测,而非钓鱼网站本身。所以在钓鱼网站监测技术的研究上,研究热点以及趋势的发展脉络以钓鱼网站的特征的选取与获得作为整个研究方向的导向标。在此回答文章伊始所提出的三个问题。
(1)钓鱼网站检测技术关注的热点及核心研究领域:
技术实力的基础决定了钓鱼网站的特征选取,而整个技术的关注点则伴随着特征数据的发展而不断更新。在初期的方法探索阶段,由于特征数据的匮乏,所以核心关注点在特征发现、特征提取、检测技术等一系列围绕特征数据的收集以及定性与定量的处理上。核心研究特征数据的选取与处理问题。而在方法完善阶段,由于特征数据的获取与处理已经趋于成熟,人们开始将关注点移至僵尸网络、数据挖掘、社会工程学等钓鱼网络的危害途径及目的意图上来。核心研究如何提高钓鱼网站检测的准确率同时降低所耗费时间的问题。最后,随着人工智能热度的不断升温,无论是钓鱼网站的制作者还是钓鱼网站检测的白帽安全人员,都开始将人工智能技术融入网站的攻防技术中来。为了应对越来越成熟的检测手段,对钓鱼特征的隐藏从最初的单纯利用社会工程学的手段混淆嫌疑URL,发展到对网站脚本的恶意代码伪装、注册信息造假以及CSS文件内容的降重等。隐藏手段从过去的单一特征造假向如今的多元特征造假发展。为了攫取更高额度的利润,钓鱼的对象也从以往的个人扩展到金融组织。钓鱼的媒介从过去的电子邮件和PC端网页发展到大量通过智能手机终端,包括但不限于手机网页、文字短信、社交APP等。关注的热点偏向了机器学习、大数据、潜在语义分析等如何利用人工智能技术进行相关的检测上来。核心研究如何通过人工智能的方法使得对钓鱼网站的检测从单纯的特征比对,到检测系统对特征的自主学习以至于特征理解上来。
(2)在钓鱼网站检测技术领域下国际上著名的期刊及研究机构:
国际上,钓鱼网站检测技术相关方向的投稿主要以投向工程类期刊为主,可见在这一领域的研究中相比纯学术性质的研究,钓鱼网站的检测更偏向于工程实践性质的研究。普通刊物以《LECT NOTES COMPUT SC》为主,高水平期刊以ACM和IEEE下的子刊为主,期刊详表见3.4节的表4。
(3)钓鱼网站检测技术在国际上的发展脉络以及未来可能的发展趋势:
钓鱼网站检测技术主要经历了3大发展阶段,具体如第4章的表7所示。在检测初期往往以较为容易提取及区分的URL作为特征判别的主流方向,而定性的依据则主要以不同字符的定量特征为主。在方法的完善阶段,当社会工程学的内容加入之后,人们开始探索钓鱼网站服务器的所在地域与网站成本之间的关系、网站存在时长与网站良恶性质之间的关系等一大批从社会工程学角度出发挖掘的特征。此时朴素贝叶斯、支持向量机以及逻辑回归三大分类器[17]模型几乎成了钓鱼网站做二分类时的分类模型标配。近年来,随着人工智能热度的不断升高,无论是钓鱼网站的制作者还是钓鱼网站检测的白帽安全人员,都开始将人工智能技术融入网站的攻防技术中来。为了应对越来越成熟的检测手段,对钓鱼特征的隐藏从最初的单纯利用社会工程学的手段混淆嫌疑URL,发展到对网站脚本的恶意代码伪装、注册信息造假以及CSS文件内容的降重等。隐藏手段从过去的单一特征造假向如今的多元特征造假发展。为了攫取更高额度的利润,钓鱼的对象也从以往的个人扩展到金融组织。钓鱼的媒介从过去的电子邮件和PC端网页发展到大量通过智能手机终端,包括但不限于手机网页、文字短信、社交APP等。由此引出的以人工智能手段为基础的:钓鱼页面视觉上与合法页面的差异性挖掘,钓鱼URL与URL特征检测方向的生成式对抗网络构建,以及在新的移动终端出现的钓鱼网站智能检测等利用人工智能整合基础检测方法的方式都将可能成为今后一段时间内的新发展趋势。
猜你喜欢
军事运筹与系统工程(2022年1期)2022-11-15
质量安全与检验检测(2022年2期)2022-11-13
中学生数理化·中考版(2022年9期)2022-10-25
中国现代医药杂志(2020年10期)2020-01-08
当代陕西(2019年10期)2019-06-03
数学小灵通·3-4年级(2017年9期)2017-10-13
小学生导刊(低年级)(2016年8期)2016-09-24
小学科学(2015年6期)2015-07-01
小学科学(2015年6期)2015-07-01
小学科学(2015年5期)2015-06-08
