
基于启发式社团发现模型的创新态势研判算法
2020-08-03 10:05易成岐童楠楠王建冬
计算机工程与应用 2020年15期
易成岐,郭 鑫 ,2,童楠楠,3,窦 悦,陈 东,王建冬
1.国家信息中心 大数据发展部,北京 100045
2.北京大学 信息管理系,北京 100871
3.中国人民大学 信息资源管理学院,北京 100872
1 引言
当今,世界新一轮科技革命和产业变革正在加速演进,以互联网、大数据、人工智能、物联网等为代表的新一轮信息技术不断突破,深刻影响着全人类生产方式的进步及思维模式的转变。近年来,我国科学技术事业发展也取得了很大成就,科技创新能力显著提升。在此背景下,我国既面临着弯道超车的千载难逢历史机遇,又面临着差距继续被拉大的严峻挑战。因此,全面把握并精准感知特定领域创新态势至关重要,具有重要战略意义和指导作用,从国家层面看,能够有效分析创新领域的战略布局、对比评估创新态势发展差异、科学制定创新体系提升策略等;从企业层面看,能够有效发现并挖掘创新技术的空白点、寻找更适合企业技术创新发展的切入点、形成更有针对性的企业二次创新活力。
专利作为国家自主创新成果的重要载体,是全社会科技创新研究成果和新技术产品研发的重要信息来源,专利数据分析不仅可以了解特定领域的技术水平和研发能力[1],还能对技术创新态势进行全面地研究和评估[2]。因此,如何科学有效地开发利用专利数据并提取出其背后蕴藏的创新态势,是产业界和学术界共同面临的热点问题。
现有的研究成果主要集中在对专利的数量、引用和关联关系开展分析[3],其中以专利数量的统计分析居多,即选取特定领域专利的申请时间分布、地域(例如国别、省份、城市等)分布、技术领域分布等进行统计,并开展横向或纵向对比分析[4-5]。专利引用分析方法主要源于文献计量学,即对专利文献之间的引文关系进行探索,如Li等对专利引文网络进行分析,揭示了研究领域、机构、国家之间的知识创新转移过程[6]。专利关联分析同样关注专利之间的联系,但其不局限于引文关系,还包括学科联系、主题联系以及专利主体间(例如国家、机构、个人等)联系等。例如,商琦等以专利主题联系为切入点,通过文本聚类得到区块链的五类技术主干[7]。胡欣悦等以专利主体联系为切入点,通过社会网络分析方法对华为公司各研发单元的空间分布及国际化合作网络进行分析,发现华为国际化研发网络呈现以深圳和美国为中心的“核心—半边缘”结构[8]。
总体来看,目前对专利数据分析的研究主要集中在专利外部基本属性信息的统计分析,如专利申请时间、所属机构、引用关系等,而基于专利内容层面的研究并不多,且普遍不够深入。
考虑到专利网络作为复杂网络中重要的组成部分,其具有社团结构特性。即专利网络的整体由若干专利团体组成,团体之间的连接相对稀疏但团体内部的连接则相对稠密。因此,本研究拟基于专利文本数据,深入到专利内容层面构建专利网络并引入社团发现模型[9],提出一种基于复杂网络的创新态势研判算法。该算法能够有效结合图网络拓扑中所蕴藏的结构性关系,从专利网络中解析得到多个子团体及各子团体特征,对创新态势分析与研判具有十分重要的意义。
综上,本文的主要贡献及创新点主要包含以下三个方面:
(1)利用发明专利标题和摘要等文本信息,通过测算专利之间的文本相似度,将专利文本数据转换成为无向加权专利网络图。其中,为了缓解专利标题和摘要短文本引发的文本向量稀疏问题,本文引入了非监督的稀疏向量稠密化方法。在融合启发式社团发现模型的基础上,本文提出了一种创新态势研判算法。
(2)为了解决专利网络构建过程中的相似度阈值自动化选择问题,本文通过实验驱动的方法,对比分析了专利网络相似度阈值与专利网络中常用统计指标的变化关系,最终选用平均聚类系数这一指标实现了最优相似度阈值的自动化判定,能够实现专利网络构建过程中的实时迭代自反馈效果。
(3)本文抽取了我国数字中国及大数据领域真实发明专利数据进行了数据实验,验证了方法的有效性并分析了数字中国及大数据领域创新态势,同时对实验结果进行了阐述及解读。
2 基于启发式社团发现模型的创新态势研判过程及算法
2.1 创新态势研判基本思路
基于发明专利题目和摘要等文本数据,结合社团发现模型分析创新态势的基本思路如图1所示,主要分为三个阶段:

图1 利用社团发现模型分析创新态势的基本思路
首先是专利本体阶段,其中,V代表发明专利节点,在此初始阶段各发明专利相对独立,每个发明专利节点包含专利申请号、专利标题、专利摘要、申请日期、公开日期、申请人、发明人等相关基本属性信息。
第二阶段为专利网络构建阶段,利用发明专利标题及其摘要等文本信息,通过测算发明专利之间的文本相似度,可根据专利之间的相似程度构建专利间的相似边E(下文会详述专利网络构建方法及过程),因此,在此阶段可将孤立专利节点构建成为无向加权图G。
第三阶段为创新领域分析研判阶段,在此阶段可利用复杂网络领域的社团发现模型和网络拓扑布局算法对无向加权专利网络图G进行社团结构划分,其中,社团发现模型可以更准确地自动化理解专利网络的组织关系、拓扑结构与动力学特性。
2.2 专利网络自动化构建方法
通过测算发明专利之间的文本相似度,将特定领域的n条发明专利数据构建为一个无向加权图G={V,E,W}(|V|≤n)。其中,如果两个发明专利的文本相似度超过一定阈值(阈值选择策略详见下节),则认为两者存在相似性关系,即两条专利之间存在一条无向边,否则无边。G代表特定领域的发明专利网络图,V代表专利网络图G中的发明专利节点,E代表发明专利节点间的无向边;W代表发明专利之间无向边的权重,权重值为文本相似度,取值归一化至0~1之间。
其中,由于将n条发明专利转换为无向加权图G的时间复杂度为O(n2),为了节省运算时间成本,本文只考虑利用发明专利标题和摘要计算文本相似度,为了缓解短文本造成的文本向量稀疏化问题,本文采用一种非监督的稀疏向量稠密化方法进行相似度测算[10],区别于传统余弦相似度计算方法中将专利标题文本转换为x=(x1,x2,…,xV)T和y=(y1,y2,…,yV)T两个等长的词向量(V代表词表长度),本文首先将每条发明专利标题重写为非等长词向量x={xa1,xa2,…,xanx}和 y={yb1,yb2,…,ybny},其中,ai和bj代表x和y向量中非零权重词语的索引项(1≤ai,bj≤V),xai和ybj代表词汇表中词语的关联权重,另外,假设x和y向量中分别存在nx和ny个非零权重词语,则余弦相似度计算公式可改写为:

其主要思想是,为了计算每个词语之间相似性的平均相似度,可以较大程度地将发明专利标题稀疏向量进行稠密化处理,其中,ϕ(ai,bj)代表非零权重词语ai和bj之间的相似度。关于词语稠密化表示方法,本文采用了浅层神经网络模型word2vec方法[11-12],其中,利用2016年1月至2019年4月期间365.3万条国内部分高新技术领域发明专利标题及摘要文本数据,采用默认参数即窗口大小为5的CBOW(连续词袋)模型进行训练。对于每个词汇,本文统一映射为200维的词向量,考虑到RBF(径向基函数)本质是一种相似度的测量,而且是在原始空间的相似度测量方式,因此本文使用RBF核函数作为后续实验中两个词向量a和b的相似度计算方法:

2.3 专利相似度阈值选择策略
在构建专利网络的过程中,对发明专利相似度阈值δ的选择尤为关键,会直接影响专利网络密集或松散的程度,阈值越小代表符合阈值的专利节点筛选策略越宽松,会导致专利网络拥有更多的节点及边;阈值越大则代表专利节点筛选策略越苛刻,专利网络则会拥有更少的节点及边。但是由于相似度阈值δ并不是一个常数,而是会受到专利领域分布范围、专利数量多少等诸多因素影响,因此,本文拟将专利网络的相似度阈值与专利网络中常用统计指标的变化关系进行对比分析,希望能够找到一种统计指标实现最优相似度阈值δ的自动化判定,从而满足专利网络构建过程中的实时迭代自反馈效果。
在此阶段,本文通过以数据实验为驱动的方法,对比分析了专利网络相似度阈值δ与专利网络平均度、平均路径长度、平均聚类系数、网络密度、介数中心性、紧密中心性、特征向量中心性、同配系数等复杂网络中常用统计指标的变化关系,分析发现专利网络相似度阈值δ与平均聚类系数|C|的变化呈现线性关系,其中,部分专利网络(我国数字中国领域专利、北京市西城区专利、江苏省高新技术领域专利、深圳市高新技术领域专利、浙江省高新技术领域专利)相似度阈值与平均聚集系数对比关系如图2所示。

图2 部分领域专利网络相似度阈值与平均聚集系数对比
因为在复杂网络中,如果节点V0与节点V1相连,节点V1与节点V2相连,那么节点V2有很大概率与V0相连。为了量化该特性,聚集系数也称为聚类系数,表示在复杂网络中与同一节点相连的节点们互相连接的程度[13]。节点Vi的聚集系数Ci可以表示为:

其中,ki表示与节点Vi相连接的节点数量,ei表示节点Vi的ki个相连节点集合V={V1i,V2i,…,Vki}中存在互相连接的边的数量。由式(3)可知,对于有向图,ki个节点存在互相连接边的数量上限为ki(ki-1),而对于类似于专利网络的无向图,ki个节点存在互相连接边的数量上限为ki(ki-1)2。
通常平均聚类系数|C|能够以全局视角量化复杂网络中节点聚集程度[14]。平均聚集系数|C|定义为所有节点的聚集系数的平均值,取值范围在0至1之间,可表示为:

其中,N代表复杂网络中节点的数量,Ci代表节点Vi的聚集系数。
因此,可以在选择相似度阈值过程中实时反馈专利网络的平均聚类系数|C|值,将平均聚类系数|C|接近平滑时的临界点所对应的相似度阈值作为专利网络的最优阈值δ。
2.4 启发式社团发现模型
考虑到Modularity(模块度)是一种衡量社团发现质量的评价方法[15],Modularity会保证基准网络与现有网络有着相同的度分布的前提下,通过对比基准网络与现有网络在相同社团划分后的连接密度来度量社团发现算法的准确程度,具有很强权威性,但由于计算Modularity属于NP-完全问题,因此本文采用一种启发式Modularity计算方法作为社团发现模型[16],具体计算公式为:
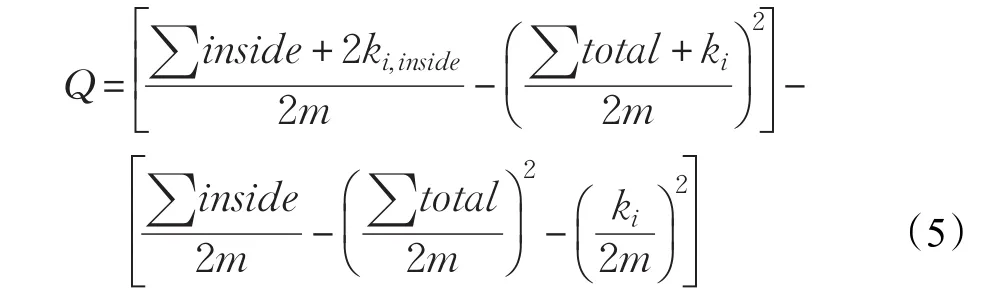
其物理意义是计算专利网络中同一社团内部边的比例与同样度分布下基准网络内部边比例的期望值之差。其中,m代表专利网络中边的数量,∑inside代表社团C中内部边的数量,∑total代表划入社团C中节点的边的数量,ki代表了与节点i相关边的数量,ki,inside代表从节点i连到社团C中节点的数量。
该算法主要思想是首先合并社团,并将每个节点单独看作一个社团,基于Modularity增量最大化标准决定需要被合并的社团。此外,将上一步骤已发现的所有社团看成单独节点,并且构建新的网络,重复运行上述步骤后直到Modularity不再增长,则得到社团发现的近似最优解,专利网络最终形态为G={V,E,C},其中C代表专利节点V所属的特定社团。
2.5 基于启发式社团发现模型的创新态势研判算法
综合上述分析,本文融合了稀疏向量稠密化文本相似度测算方法、专利相似度阈值选择策略和启发式社团发现模型,提出了一种基于专利数据的创新态势研判算法,如算法1所示。
算法1基于启发式社团发现模型的创新态势研判算法
输入:特定领域专利明细数据V={V1,V2,…,Vn}和初始阈值δ=0.1
输出:已形成若干社团的专利网络G={V,E,C}
开始
1.FunctionpatentNetwork(V,δ)do//专利网络构建函数
2. fori:=1tondo
3. forj:=i+1tondo
4. 利用公式(1)和公式(2)计算Vi和Vj文本相似度sim(i,j);
5. ifsim(i,j)>δthen//判断相似度是否大于阈值
6.V←Vi,V←Vj;//将Vi和Vj添加至专利网络
7.E←Eij;//将Vi和Vj之间的边添加至专利网络
8. end if
9. end for
10. end for
11. 利用公式(4)计算当前专利网络的平均聚集系数|C|;
12.ifisSmoothing(|C|)then//判断当前|C|是否已平滑
13. 生成专利网络G={V,E};
14. break;
15. else
16.δ+=0.1;
17.patentNetwork(V,δ);
18.end FunctionpatentNetwork(V,δ)
19. 利用公式(5)对专利网络进行社团发现测算;
20. 输出已形成若干社团的专利网络G={V,E,C}。
3 我国大数据及数字中国领域创新态势分析研判
3.1 大数据及数字中国领域专利网络构建
为了验证上述方法的有效性以及分析研判我国数字中国及大数据领域创新态势,本文从国家发展改革委大数据中心已掌握的专利明细数据中,抽取了公开日期为2016年1月至2019年4月期间国内部分高新技术领域发明专利标题及摘要文本数据作为基础专利数据(共365.3万条)。基于此数据,利用大数据及数字中国领域关键词对专利标题及摘要文本进行字符串精准匹配,并将匹配到的专利数据利用前文所述基于启发式社团发现模型的创新态势研判算法进行专利网络建模。建模后得到我国数字中国领域专利网络共11 622个节点及81 120条边,平均度为13.96。其度分布遵循着较好的幂律分布规律,如图3所示。

图3 我国数字中国领域专利网络度分布
此外,我国大数据领域专利网络共包含4 721个节点及47 521条边,平均度为20.13。如图4所示,由于大数据领域限定范围相对更小,因此其度分布并没有呈现十分明显的幂律分布规律,更接近于伽马分布。

图4 我国大数据领域专利网络度分布
3.2 大数据及数字中国领域创新态势分析
为使我国数字中国及大数据领域创新态势显示效果更直观,本文利用Gephi[17]开源软件对其进行了可视化展示,并对社团发现结果进行了节点着色处理,同时采用度分布结果进行了节点的大小调整,并利用Hu[18]提出的算法对其进行了自动化布局。其中每个社团的标签是利用TF-IDF算法从社团内部专利标题文本中提取具有代表性的关键词所进行的标注,我国数字中国领域创新态势图谱最终可视化效果如图5所示。
从图5可以发现,数字中国领域技术创新初步形成了人工智能与机器人、智能家居、数据存储、控制系统、移动终端、物联网与传感器、计算机、数据处理等8个创新社团,已形成以生产生活数字化为内核,大数据技术为依托,人工智能(AI)、集成电路(IC)和物联网(IOT)等“3I”技术为核心领域的数字中国技术创新格局。

图5 我国数字中国领域创新态势图谱
通过计算平均最短路径来量化社团间的融合程度(平均最短路径越数值越小则代表社团间融合度越高),进一步分析显示,在应用方面的核心领域(智能家居、控制系统、移动终端)与几大支撑部分(人工智能与机器人、物联网与传感器、计算机与智能硬件、数据存储与数据处理)的融合度均有不同。融合度测算对比结果如图6所示。

图6 三大核心领域与其他应用领域的融合度对比
可以发现,三大核心领域与人工智能、数据处理、计算机、物联网等领域的平均最短路径长度分别为5.31、5.81、6.01和6.29。其中,与人工智能领域的平均最短路径长度最小,说明领域间的融合度最高;而与物联网领域的平均最短路径数值最大,则表示领域间融合度最低,这表明现阶段与核心领域数字产业化融合较好的领域是人工智能领域,该领域为数字经济产业落地注入了强劲的动力。
此外,我国大数据领域创新态势图谱如图7所示,我国大数据领域创新呈现出以技术型专利为中心,逐步向应用型专利扩散态势。其中,技术型专利涵盖了大数据全生命周期的重要链条,呈现存储、安全、检索、计算、分析“五足鼎立”之势。同时,大数据分析方法创新正逐渐向人工智能方法延伸。另外,从图7可知我国目前大数据采集领域专利仍比较匮乏,表明数据资源虽为大数据领域的重要基石,但目前大数据领域公开的采集方法仍相对较少。

图7 我国大数据领域创新态势图谱
4 结束语
本文基于发明专利文本明细数据,通过非监督的稀疏向量稠密化方法测算专利之间的文本相似度,并将其构建成为无向加权图,引入社团发现模型提出一种基于启发式社团发现模型的创新态势研判算法。为解决文本相似度计算过程中阈值选择问题,本文对比分析了专利网络相似度阈值与复杂网络中常用统计指标的变化关系,最终选用平均聚类系数这一指标实现了最优相似度阈值的自动化判定,从而实现专利网络构建过程中的实时迭代自反馈效果。基于上述算法对我国数字中国及大数据领域创新态势分析发现,我国数字中国领域创新初步形成了机器人、智能家居、数据存储、控制系统、移动终端、物联网、数据处理等8个创新社团,并形成了以“3I”技术为核心领域的数字中国创新格局,应用层面的智能家居、控制系统、移动终端三大核心领域与人工智能领域的融合度最高(平均最短路径长度5.31),而与物联网领域融合度最低(平均最短路径长度6.29)。此外,我国大数据领域技术型专利涵盖了大数据全生命周期的重要链条,并呈现出以技术型专利为中心,逐步向应用型专利扩散态势。
未来工作中,一方面可以基于专利网络的时序演化特性研究基于时序变化的创新态势预测方法,另一方面,由于当前算法的时间复杂度仍相对较高,面对大规模发明专利数据时的处理时间仍然较长,可以进一步研究该算法的时间复杂度压缩方法。
猜你喜欢
阅读(中年级)(2022年9期)2022-10-08
汽车与安全(2020年1期)2020-05-14
中国外汇(2019年19期)2019-11-26
制造技术与机床(2019年9期)2019-09-10
中国化肥信息(2019年5期)2019-06-25
成都信息工程大学学报(2019年5期)2019-05-21
西南交通大学学报(2018年6期)2018-12-18
军事文摘(2017年16期)2018-01-19
中学生(2016年13期)2016-12-01
探测与控制学报(2015年4期)2015-12-15
