
基于眼睛状态识别的疲劳驾驶检测
2020-08-03 04:15任小洪陈闰雪
科学技术与工程 2020年20期
徐 莲, 任小洪, 陈闰雪
(1.四川轻化工大学自动化与信息工程学院,宜宾 644000;2.人工智能四川省重点实验室,自贡 643000;3.四川轻化工大学计算机学院,宜宾 644000)
据中国统计年鉴数据显示,1995—2014年平均每年有38.2万起交通事故发生,而35%~40%的交通事故都是由疲劳驾驶引起的,及时检测疲劳并作出预警是降低交通事故的有效方法之一。疲劳驾驶检测技术大致可分为行为检测、生理检测和视觉检测3类[1-3],视觉检测具有非入侵性和准确率高等特点,在疲劳检测领域得到广泛应用。
视觉检测主要是通过眼睛状态、头部姿态和面部表情3个方面来确定疲劳程度,其中眼睛包括丰富的信息,不易受外界干扰和人为抑制。闫河等[4]采用194个特征点的人脸主动形状模型,结合harr级联定位眼睛区域,通过光流法跟踪眼睑特征点识别眼睛状态,进而实现驾驶员面部疲劳检测。该方法对光照变化有较好的适应性,但是眼睛状态识别的准确率还有待改善。Wang等[5]提出一种基于Adaboost和等高线圆的眨眼疲劳检测算法,先采用Adaboost算法对人脸与眼睛区域进行检测,用网格方法去除瞳孔区域的像素,然后用最小二乘法对上眼睑轮廓进行拟合,最后根据PERCLOSE判断疲劳。李长勇等[6]对驾驶员人脸进行建模,提取驾驶员的视线、眼部PERCLOSE特征,建立基于贝叶斯置信网络的多信息融合疲劳检测方法。罗元等[7]结合灰度投影与级联卷积神经网络定位眼睛,利用人眼6个特征点识别眼睛开闭度,根据PERCLOSE比值进行疲劳判断。该类方法在正面能够达到较好的检测精度,但易受光照与头部姿态的影响。在实际驾驶环境中,驾驶员会有多种头部姿态,如抬头、低头、偏头等,最常见的头部姿态为左右偏转。当驾驶员左右偏头幅度过大时,会出现部分脸部及眼睛的遮挡。综上所述,减小头部姿态引起的误差和提高疲劳驾驶检测精度是至关重要的。而且疲劳驾驶引发的交通事故反应时间非常短暂,设计一个能够快速检测出驾驶员疲劳的模型具有重要意义。
针对以上问题,设计一种眼睛状态识别网络(Gabor and LBP-convolutional neural networks,GL-CNN),该网络将眼睛图像的gabor特征和LBP特征相结合,通过迁移学习将传统的图像处理技术与深度学习结合起来,能够更有主观意识地学习特征,有效提高模型分类准确率。用单眼检测代替传统的双眼检测,增加驾驶员头部姿态的检测范围,旨在提高疲劳驾驶的智能监控能力。
1 疲劳检测流程
基于眼态识别的疲劳检测流程如图1所示。首先将采集的视频图像通过MTCNN(multi-task convolutional neural networks)检测出驾驶员的人脸,并对左右眼睛的位置进行定位,然后经过眼睛筛选机制获取待检测的左眼或右眼图像,将眼睛图片的Gabor 特征与LBP特征结合到CNN中构造GL-CNN模型,再用训练好的眼睛状态分类模型GL-CNN来判断待检测眼睛的睁闭状态,最后通过PERCLOSE等准则判断驾驶员疲劳或清醒的状态。

图1 基于眼态识别的疲劳检测流程Fig.1 Fatigue detection process based on eye state recognition
1.1 眼睛定位
人脸检测和眼睛定位是眼睛状态识别的关键部分。近年来深度学习[8-9]在图像处理中取得了惊人的成就,在疲劳驾驶检测中也有涉及。卷积神经网络(convolutional neural networks,CNN)的多层结构能够自动学习特征,并且可以学到多个层次的特征。在复杂的实际驾驶环境中,单个CNN模型已经不能满足人脸关键点定位的要求,现参考Zhang等[10]的MTCNN训练好的模型,网络结构如图2所示,主要由PNet、RNet、ONet三层网络网络构成,网络结构由简单到复杂。
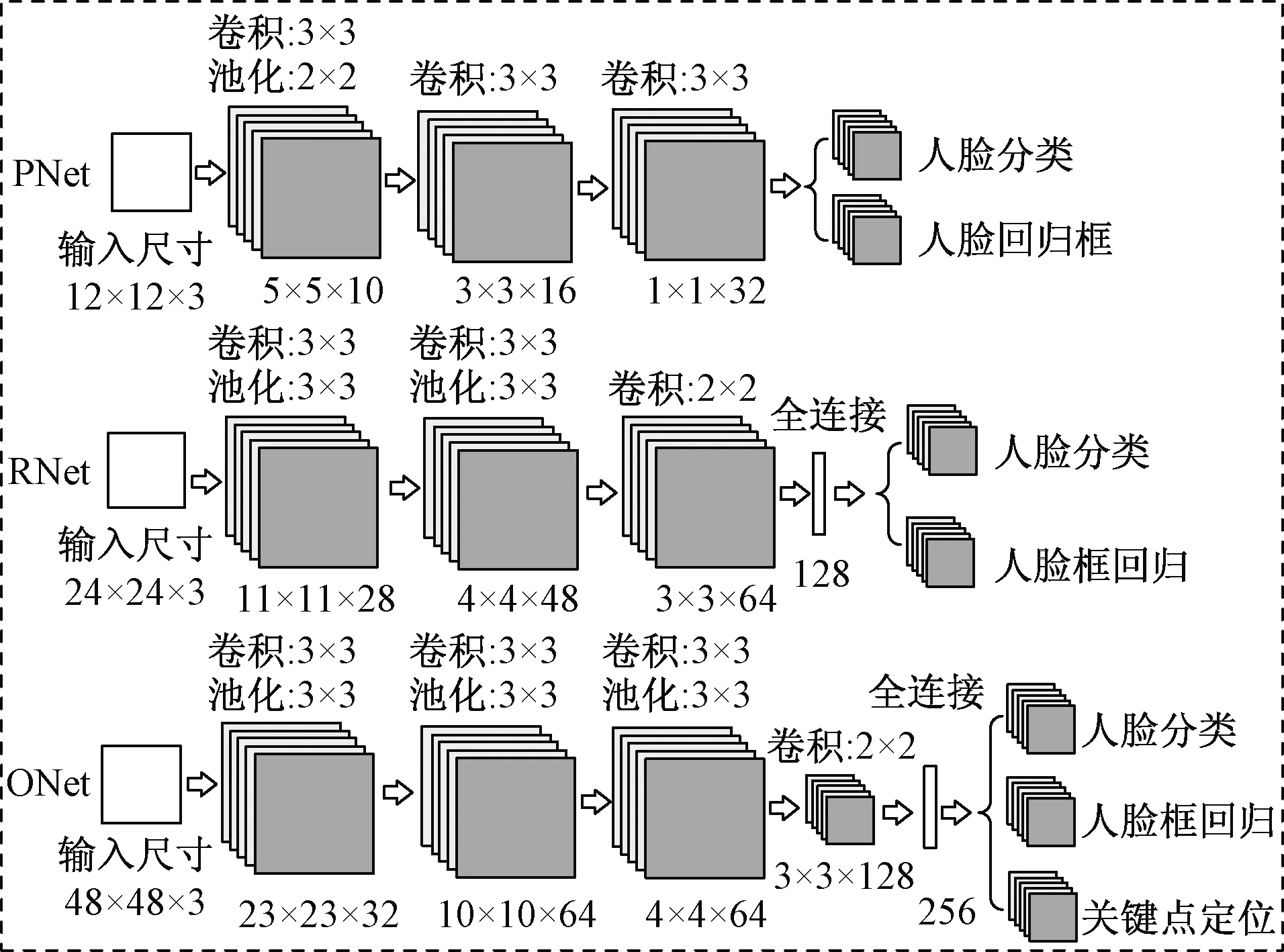
图2 MTCNN网络结构Fig.2 The network structure of MTCNN
PNet采用全卷积网络训练得到人脸候选框和回归框向量,然后对人脸候选框进行校准,用非极大值抑制(nonmaximum suppression,NMS)去除掉高度重合的候选框。
RNet将PNet预测的候选窗作为输入,滤除大量效果较差的候选框,然后对候选框进行校准和NMS进一步优化预测结果。
ONet通过更多的监督来识别面部的区域,最终输出人脸框和5个特征点(左右眼睛瞳孔、鼻尖、左右嘴角)坐标。
由于只需要定位人脸与眼睛,人脸检测与眼睛定位如式(1)所示。
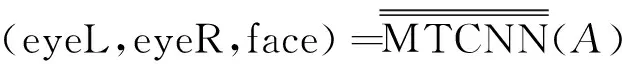
1.2 基于迁移学习的眼睛分类模型GL-CNN
1.2.1 眼睛筛选机制
在实际驾驶环境中,驾驶员的头部姿态是多样化的,当某只眼睛由于偏转被遮挡时很难实现同时正确检测双眼的状态,一旦某只眼睛出现错检,就判断为错检,对实验结果的干扰很大。针对这种情况,提出一种眼睛筛选机制。当头部大幅度偏转、倾斜时,检测未被遮挡的单只眼睛图片,而当双眼均未被遮挡时,同样检测单只眼睛。具体如图3所示,图3中fw和fh分别表示MTCNN检测出人脸框的宽和高,d表示MTCNN定位双眼瞳孔连线的中点到人脸右边框的垂直距离,当d大于fw/2时,检测图片右眼(实际驾驶员的左眼),否则检测图片左眼(实际驾驶员的右眼)。
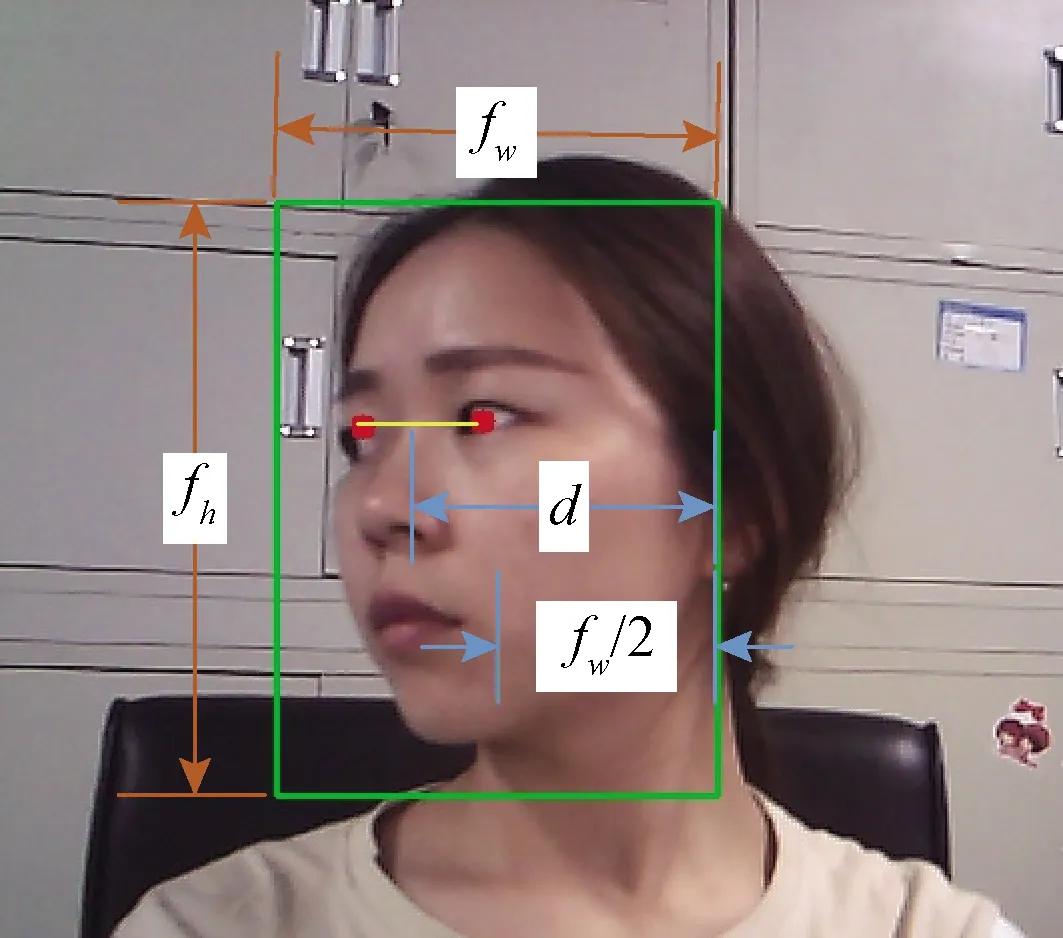
图3 眼睛筛选机制示意图Fig.3 Schematic diagram of the eye screening mechanism
对于检测到的人脸大小不一,采用一种自适应的方法进行眼睛图片切割。根据MTCNN检测出来的眼睛位置分布和人脸大小来剪裁眼睛,即
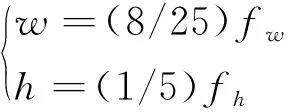
式(2)中:w和h分别表示剪切后眼睛的宽和高。
1.2.2 迁移学习
迁移学习有域(Domain)和任务(Task)两个概念[11],域D={X,P(X)}是由特征空间X与边缘概率分布P(X)(X∈{x1,x2,…,xn})两部分组成,任务T={Y,H(·)}是由标签空间Y和目标预测函数H(·)两部分组成。定义源域为DS,源任务为TS,目标域为DT,目标任务为TT,对于给定的DT、DS、TS、TT,迁移学习是指当DS≠DT或TS≠TT时,用DS和TS的相关信息提高TT中目标预测函数H(·)的学习效率。
根据源域、目标域和任务之间的不同情况,将迁移学习分为归纳迁移学习、传递迁移学习和无监督迁移学习3类。现采用传递迁移学习,将眼睛的Gabor特征、LBP特征数据集作为源域,原眼睛图片作为目标域,当对原眼睛图片分类训练时,将特征图像训练获得的模型参数作为模型初始参数。
局部二值模式(LBP)是用来描述图像局部纹理特征,具有旋转不变性和灰度不变性等优点。Gabor滤波器可以提取图像不同方向上的纹理信息,对光照、姿态具有一定的鲁棒性。Gabor特征图与LBP特征图如图4所示,原图经过局部二值化得到眼睛的LBP特征图,Gabor滤波器从原图提取0°、45°和90° 3个方向上的特征图,然后将3个特征图像映射合成一个新的3通道图像,最后经过灰度化得到Gabor特征图。
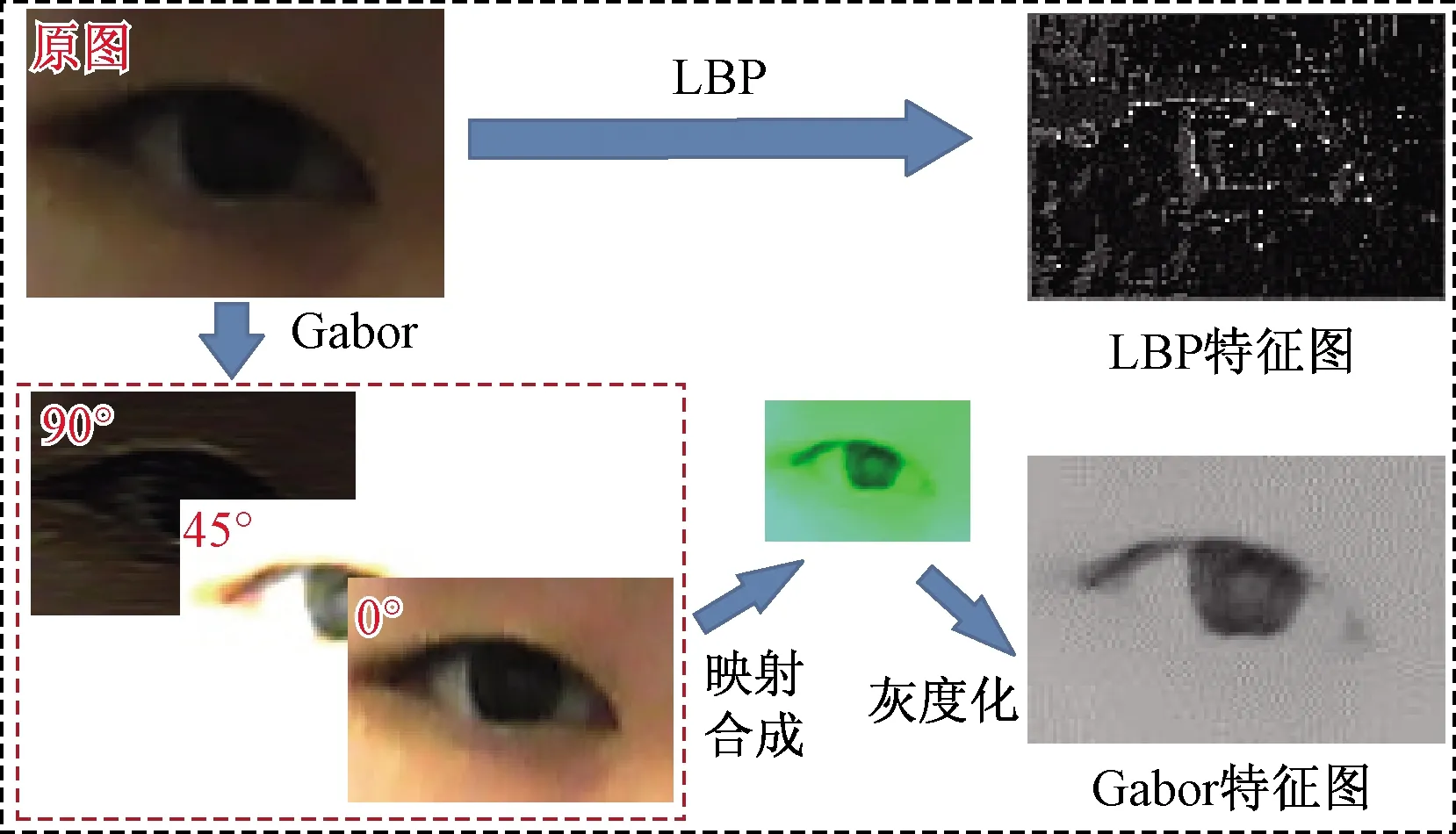
图4 Gabor特征图与LBP特征图Fig.4 Gabor feature map and LBP feature map
眼睛的Gabor特征、LBP特征图与原图有一定的相似性,但是比原图更凸显边缘轮廓。将Gabor特征融合图与LBP算子结合不仅能够保留图像纹理变化表征能力,还能有效降低特征冗余。
1.2.3 眼睛分类模型GL-CNN
眼睛状态识别方法主要有基于特征分析[12]和模式分类[13]两类方法,这两类方法各有所长,但是在实际环境中,光照变化和图像分辨率低的情况下不能达到理想的效果。为此通过迁移学习将Gabor特征与LBP特征加入到CNN网络中构造GL-CNN网络。GL-CNN网络结构如图5所示,先将gabor特征图和LBP特征图加入到CNN中进行预训练,再训练与预训练采用相同的CNN网络结构,将预训练好的模型参数作为再训练过程的初始参数,然后对原始图片进行再训练,最后判断眼睛的状态open(睁眼)或close(闭眼)。
CNN网络结构如图5虚线框内所示,该网络层包含2个卷积层、2个池化层、2个全连接层。在每个卷积层后都采用relu激活函数,分别在第二层卷积层和第一个全连接层后面接比例为0.25和0.5的Dropout层防止过拟合。经过两个全连接层之后,通过一个softmax层完成最后的分类,softmax函数为
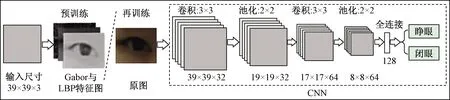
图5 GL-CNN网络结构Fig.5 The network structure of GL-CNN
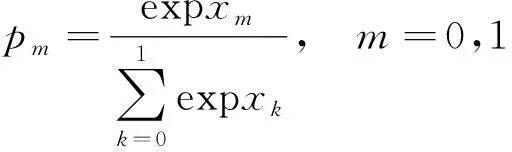
式(3)中:Pm表示分类为m的概率,m为0表示睁眼,m为1表示闭眼;xm为全连接层的输出。全连接层计算公式为
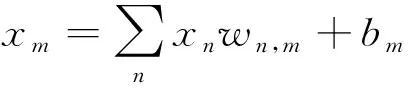
式(4)中:xn表示上一层输出;wn,m和bm分别表示全连接的权重和偏置。CNN采用二值交叉熵损失函数,公式为
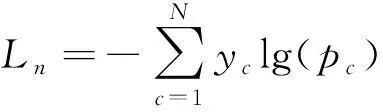
式(5)中:Ln表示第n个样本的交叉熵;N表示分类数量;yc∈(0,1)表示眼睛样本的标签,0表示睁眼,1表示闭眼;Pc表示样本预测为c的概率。
2 实验结果与分析
采集数据、训数和测试都是基于Python3.6和Tensorflow 1.2.1平台上实现的,采用普通摄像头(640×480),显卡型号为Tesla T4,显存为15 G。MTCNN对于偏转一定角度的人脸有较高的准确率,且鲁棒性好,为眼睛状态识别奠定了基础。
2.1 眼睛数据采集
默认眼睛只有开闭两种状态,定义一个标准:如果虹膜和眼白部分可见定义为睁眼,否则定义为闭眼。不同的眼睛状态如图6所示,如图6(c)所示,眼睛实际上是睁开的,但是虹膜看不见,将这种近似闭眼的情况定义为闭眼。
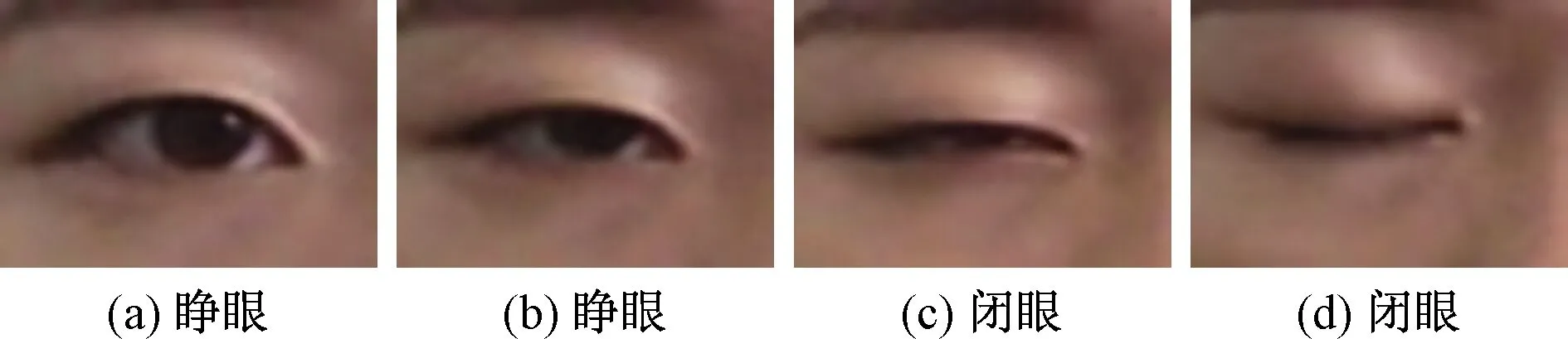
图6 不同状态的眼睛示例Fig.6 Examples of eyes in different states
眼睛状态分类网络GL-CNN训练和测试数据为自主采集,综合考虑到实际驾驶环境的复杂性,采集的眼睛图像包括戴眼镜、不戴眼镜、正面、侧面和光照不均匀等多种情况。对数据集进行筛选(不区分左右眼),选择可用于训练或测试的睁闭眼图片共12 000张。
2.2 眼睛分类模型GL-CNN实验对比
GL-CNN采用随机梯度下降法(stochastic gradient descent,SGD)和动量(momentum)的优化器进行训练,为了能更好地评估模型的性能和避免过拟合,采用十折交叉验证原则划分数据集,训练集与验证集比例为7∶3。GL-CNN再训练损失函数如图7 所示,再训练的初始损失率约0.1,在经过1 000次迭代损失函数曲线基本收敛于0.05,在自采集数据集测试准确率为98.2%。
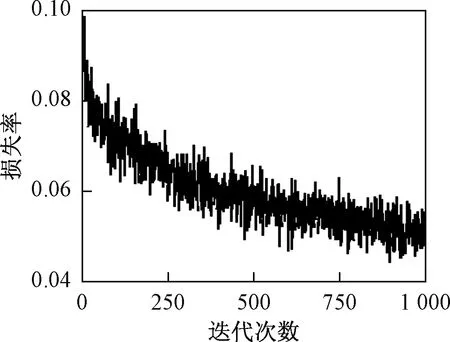
图7 GL-CNN再训练损失函数曲线Fig.7 Retraining loss function curve of GL-CNN
通过迁移学习将Gabor滤波器加入CNN调制称为G-CNN(Gabor-convolutional neural networks ),同理将LBP特征加入CNN调制称为L-CNN(LBP-convolutional neural networks ),基于CNN的不同算法对比如表1所示。相对于经典C-NN算法,分别加入Gabor特征和LBP特征提升了分类准确率,而将Gabor特征和LBP特征相结合加入CNN人工调制,比单独加入一种特征图的准确率高。将传统的图像处理技术与深度学习结合起来,不仅能扩展数据集,而且能有效提高模型分类准确率。不同算法在自采集数据测试集上的分类准确率及算法速率如表2所示,本文算法分类准确率最高且速率最快。

表1 基于CNN的不同算法分类对比Table 1 Comparison of classification of different algorithms based on CNN
ZJU(Zhejiang University dataset)[14]是浙江大学采集的眨眼视频集,共获取有效图片8 681帧,本文的眼睛状态识别算法在ZJU上的测试准确率为97.51%。文献[15]提出一种新的特征描述子,主方向梯度多尺度直方图,将MultiHPOG、LTP、Gabor与SVM结合起来检测眼睛状态,该方法准确率较高,但耗时较长。对比文献[15]在ZJU数据集上的性能检测如表3所示,本文的眼睛状态识别算法准确率比文献[15]更高,而且大大缩短了检测时间。
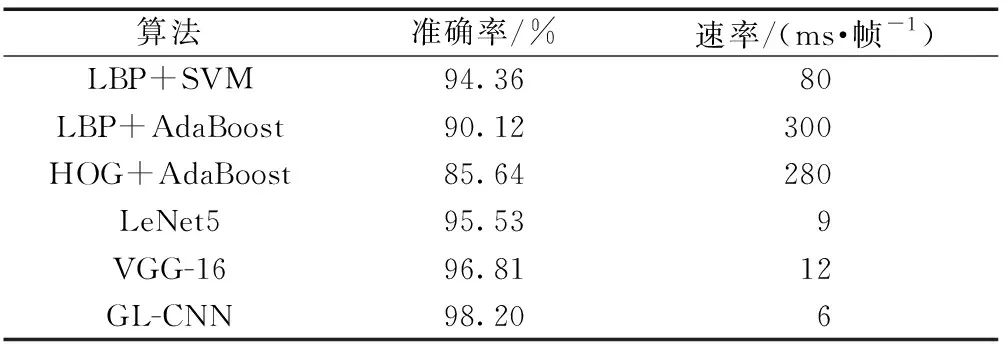
表2 不同算法在自采集数据集的分类对比Table 2 Comparison of classification of different algorithms in self-acquired datasets

表3 与文献[15]在ZJU上眼睛状态识别性能对比Table 3 Comparison of eye state recognition performance with ZJU in[15]
2.3 基于眼睛筛选机制的实验对比
以驾驶员的正前方为中心轴,头部向各个方向偏转较小范围内,双眼检测能达到较好的检测效果。图8给出了部分具有代表性的5种头部状态实验图,当驾驶员疲劳时会精神恍惚,头部会偏转或者出现频繁点头现象,这样采集到的人脸大面积被遮挡,从而造成眼睛状态的错检。
由图8可知,头部偏转极端时,被遮挡的眼睛出现错检,但没有被遮挡的眼睛检测正确。因此提出一种眼睛筛选机制,用未被遮挡的单只眼睛替代双眼检测。这里测试了450张人脸图像,分别在转动角(pitch)方向-30°~30°、滚动角(roll)方向-30°~30°、平动角(yaw)方向-75°~75°范围内偏转,考虑到驾驶员白天头部左右偏转比较频繁,重点检测平动角方向上的效果,视频流检测部分结果如图9所示。

图8 双眼检测结果示例Fig.8 Example of binocular test results

图9 基于眼睛筛选机制的单眼检测结果示例Fig.9 Example of monocular detection results based on eye screening mechanism
由图8、图9可知,单眼检测比双眼检测适应的头部姿态更多,单眼检测在不同的平动角范围内检测结果如表4所示。本文算法对于头部左右大幅度偏转情况下具有较高的准确率,而且能适应一定范围内的光照变化,不同光照情况下检测结果示例如图10所示。
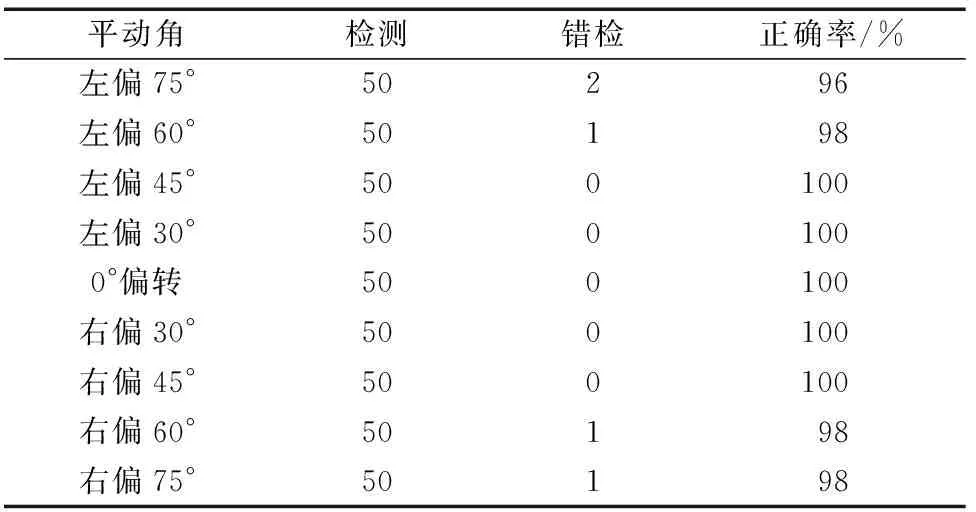
表4 对比平动角(-75°~75°)范围内检测结果Table 4 Compare test results in the range of yaw (-75°~75°)

图10 不同光照检测结果示例Fig.10 Example of different lighting detection results

图11 本文算法在YawDD数据集测试图片示例Fig.11 Example of the algorithm in the YawDD dataset test image
采用YawDD(yawning detection dataset)[16]来测试单眼检测与双眼检测准确率,YawDD是在驾驶环境中拍摄的视频数据。男女各占一半,其中20人不戴眼镜,10人带眼镜,共获取20 005帧图片,检测结果如表5所示,单眼检测比双眼检测准确率更高,单眼检测方法在YawDD数据集上准确率达91.28%,比双眼检测方法高出3.37个百分比,由于有色眼镜框对眼睛区域有不同程度的遮挡,对眼睛状态检测增加了难度,戴眼镜的检测准确率较不戴眼镜准确率低,本文算法在YawDD数据集上部分检测图片如图11所示。
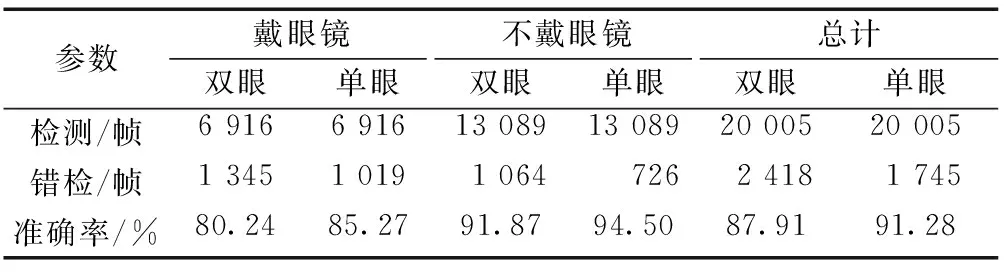
表5 单眼检测与双眼检测眼态识别结果对比Table 5 Comparison between monocular detection and binocular detection
由此可见,基于眼睛筛选机制的单眼检测方法,可以在不扩展数据集的情况下,提高眼睛状态的识别精度,检测更多种头部姿态下的眼睛状态。
2.4 疲劳驾驶检测
当驾驶员疲劳时面部会出现疲劳特征,如长时间持续闭眼、缓慢眨眼等现象,为此通过获取驾驶员眼睛的状态信息判断驾驶员的疲劳程度。PERCLOSE 表示一段时间内眼睛闭合帧数占该段时间总帧数的占比率,即
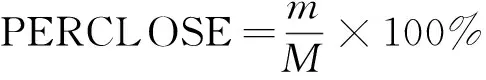
式(6)中:m表示闭眼帧数;M表示该段时间内检测眼睛总帧数,当PERCLOSE大于某个阈值时,判定驾驶员为疲劳状态。采集了20名志愿者的模拟驾驶的过程,每个人录10个视频,每个视频30 s,共100次疲劳状态,100次清醒状态。经过检测得知,其中清醒状态PERCLOSE范围为0~0.3,疲劳状态的PERCLOSE范围为0.2~1.0,由此可见当PERCLOSE 在0.2~0.3范围内是介于清醒与疲劳的过度状态,为此针对不同阈值PERCLOSE做了对比测试,测试结果如表6所示。当PERCLOSE取值为0.25时,总体错检个数最少,检测的准确率最高,可达到97.5%。
文献[17]采用动感模拟驾驶仪和ASL眼动仪等设备提取眼部特征参数,建立了基于SVM的疲劳检测模型。文献[18]提出一种利用驾驶员眼睛的时空特征检测疲劳的方法,先采用深度级联多任务框架提取眼睛区域,然后通过深度卷积层学习眼睛的空间特征,再通过LSTM单元分析相邻帧间的关系,最后对眼睛疲劳状态做序列级预测。不同算法疲劳检测如表7所示,与文献[17]相比,本文算法准确率更高。对比于文献[18],本文算法的精度和召回率更高,检测速度更快。
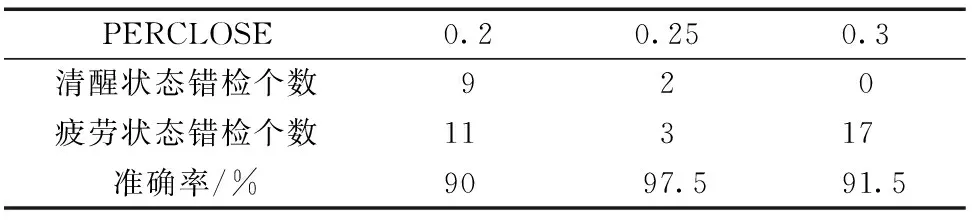
表6 不同PERCLOS值的疲劳测试准确率对比Table 6 Accuracy comparison of fatigue test with different PERCLOS values

表7 与文献[17-18]的疲劳检测性能比较Table 7 Comparison with fatigue testing performance in[17-18]
一般情况下,驾驶员的眨眼频率为15~30次/min,对于400×300的图像,本文提出的方法在CPU上运行每分钟可以检测视频图像700帧左右,平均每次眨眼0.25~0.3 s,本文算法在CPU上运行每张图片检测只需要0.096 s。所以,本文算法可以满足驾驶员的实时疲劳状态的判断。
3 结论
提出一种眼部状态的疲劳驾驶状态识别方法,传统的基于特征提取的疲劳检测方法简单有效,基于神经网络的疲劳检测方法准确率高、鲁棒性强。通过将传统的特征提取方法与深度学习结合起来,不仅可以学习到更多的特征,而且还可以提高眼睛状态识别率,可以实时输出驾驶员的疲劳状态。实验结果表明,本文算法在实际驾驶环境中对于驾驶员多姿态疲劳检测有较高的准确率,而且能够适应一定的光照变化。本文算法在白天具有较好的检测效果,在后续工作中,尝试用红外图像检测晚上的疲劳状态。
猜你喜欢
汽车实用技术(2022年14期)2022-07-30
汽车实用技术(2022年7期)2022-04-20
汽车实用技术(2022年4期)2022-03-07
少儿美术·书法版(2021年9期)2021-10-20
汽车零部件(2021年9期)2021-09-29
小学生必读(低年级版)(2021年5期)2021-08-14
军事文摘(2020年22期)2021-01-04
活力(2019年22期)2019-03-16
动漫星空(2018年9期)2018-10-26
奇闻怪事(2014年5期)2014-05-13
