
考虑平板车合作运输的船舶分段堆场间调度
2020-08-03 07:17:14李柏鹤蒋祖华陶宁蓉孟令通
上海交通大学学报 2020年7期
李柏鹤, 蒋祖华, 陶宁蓉, 孟令通, 郑 虹
(1. 上海交通大学 机械与动力工程学院, 上海 200240; 2. 上海交通大学 高新船舶与 深海开发装备协同创新中心, 上海 200240; 3. 上海海洋大学 工程学院, 上海 201306)
符号说明
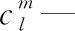
h—工厂或堆场序号,h=1,2,…,k
i—运输任务编号,i=1,2,…,n
j—运输任务编号,j=1,2,…,n
l—平板车编号,l=1,2,…,p
mi—第i个任务分段的质量
Q—无穷大的正数
tE—车场开放时间,即平板车最早可出发时间
tL—车场关闭时间,即平板车最晚回归时间
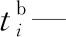
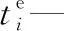
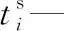
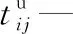
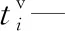
xi—第i个任务是否是超重任务,即一个平板车无法运输,若为1表示是;若为0表示否
yil—第l辆平板车是否执行第i个任务的0-1决策变量
zijl—第l辆平板车上第i,j个任务执行顺序的0-1决策变量,即如果第l辆平板车执行完第i个任务后,接着执行第j个任务,则zijl=1;否则zijl=0
zi0l—第l辆平板车执行其最后1个任务的0-1决策变量
z0il—第l辆平板车执行其第1个任务的0-1决策变量
α—平板车执行所有任务的空载行驶时间权重
β—平板车执行所有任务的等待时间权重
船舶制造是典型的拉式生产方式,船体建造工艺流程以中间产品“分段”作为组织生产的基本作业单元[1].分段在船坞之外的作业场或堆场进行组立装配、预舾装、涂装和舾装等建造工艺,最后到船坞进行总组搭载.船体分段质量较大,一般为200~300 t,个别可达到500 t.因此,分段在作业场地和堆场之间的运输主要依靠重型平板车.
一般来说,船厂中的平板车资源都是有限的.目前,某大型船厂平板车的最大承重能力为425 t,将质量超出现有平板车最大承重能力的单个分段,称之为大型分段.大型分段需要采用多个平板车进行合作运输.实际中,某大型船厂每天要完成约100个分段的运输.研究如何对船厂有限的运输资源进行充分利用、如何运输大型分段、如何提高平板车的利用率以及如何在保证任务准时进行的情况下,降低无效作业的等待时间等问题,具有十分重要的现实应用价值.
国内外船舶分段运输问题的研究相对较少.Joo等[2]以拖期时间和延迟时间的权重和作为目标函数,设计了遗传和启发式进化两种算法对问题进行求解.Wang等[3]以船舶分段运输过程中平板车的空驶时间、拖期时间和延迟时间的总和作为目标函数,提出一种贪心启发式算法对问题进行求解.Salehi等[4]认为运输过程中排放的气体在温室气体排放中占较大的比例,因此提出一个双目标混合整数非线性规划,目标函数为总运输成本和总碳排放量,并提出一种构造式启发式算法用于求解问题.Hu等[5]考虑了多个单类型平板车运输一个大型分段的问题,建立了以最小化完工时间为优化目标的数学模型,为了提高求解方法的计算性能,用贪婪插入算法和遗传算法生成初始解,设计顺序插入法求解模型.张志英等[6]构建了考虑堆场信息、分段进出场次序等因素的最短场路模型并对其进行优化,以最小化临时分段移动量和平板车在堆场中的行驶距离为优化目标,确定分段在堆场中的最优停放位置和进出场路.王冲等[7]为解决船厂平板运输车搬运船舶分段的日程计划问题,建立了利用最少数量的平板车完成分段搬运作业,以及所有分段搬运作业完成时间最小化的两阶段优化模型,提出了基于遗传算法的两种编码方法以实现模型求解.
上述研究均没有考虑当单个分段的质量超出平板车最大承重能力时,应该如何调度多种类型的平板车.而本文的研究目的是解决该运输难点,采用多个平板车合作运输大型分段的策略,且设定有多种承重能力的平板车可供选择.同时,为了保证生产的准时性,引入任务时间窗紧约束作为约束条件,开展具体研究.
1 问题描述
研究的问题可描述为有n个待执行的运输任务和p个运输平板车,每个运输任务包括:任务编号、分段编号、分段质量、运输起点、运输终点、运输时间窗(任务最早可执行时间以及任务最晚的执行时间);每个运输平板车包括:平板车编号、平板车承重能力.每个任务必须由满足其分段承重需求的平板车在时间窗范围内开始从运输起点运送至运输终点.其中对于大型分段,一个平板车由于承重能力限制无法运输,此时就需要多个平板车合作运输.某船厂的道路路口情况、堆场位置以及平板车停放位置如图1所示.其中:虚线为平板车空载行驶的路径;实线为平板车负载行驶的路径.假设平板车L1的任务序列为任务Oi和Oj,任务Oi为将目标分段从平直中心运输到涂装平台;任务Oj为将目标分段从9号平台运输至曲面车间.则平板车的实际执行流程为从平板车的停放位置出发,行驶至平直中心并提取分段,负载行驶至涂装平台后放下分段;然后,空驶运行至9号平台并提取分段,负载行驶至曲面车间后空驶至平板车停放位置,结束运输.
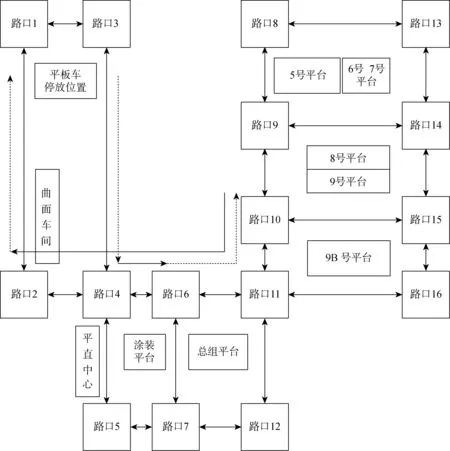
图1 道路及堆场布局图Fig.1 Distribution of roads and yards
对于大型分段,两个平板车之间的合作运输工作原理如图2所示.其中:Ll为运输平板车序号;Bi为船舶分段;Sh为工作场或堆场序号.以平板车L1和L2为例,平板车L1从车场出发,空驶至S1堆场,装载分段B1后负载行驶至S3堆场,卸下分段;空驶至S5,由于分段B3是大型分段,需要L1和L2合作运输,所以等L1和L2均到达S5后,开始运输分段B3至S6.对于合作运输大型分段的平板车而言,若一辆平板车早到,一辆平板车晚到,将会导致早到的平板车只能原地等待,这在生产过程中是极度浪费资源的,且等待时间也会造成生产进程的滞后.因此,从平板车运输任务分段的全过程出发,以平板车执行任务时的空载行驶时间和平板车由于早于时间窗到达产生的等待时间,或者平板车合作运输时产生的等待时间的权重和作为优化目标进行研究,以期达到合作运输效率优化的效果.
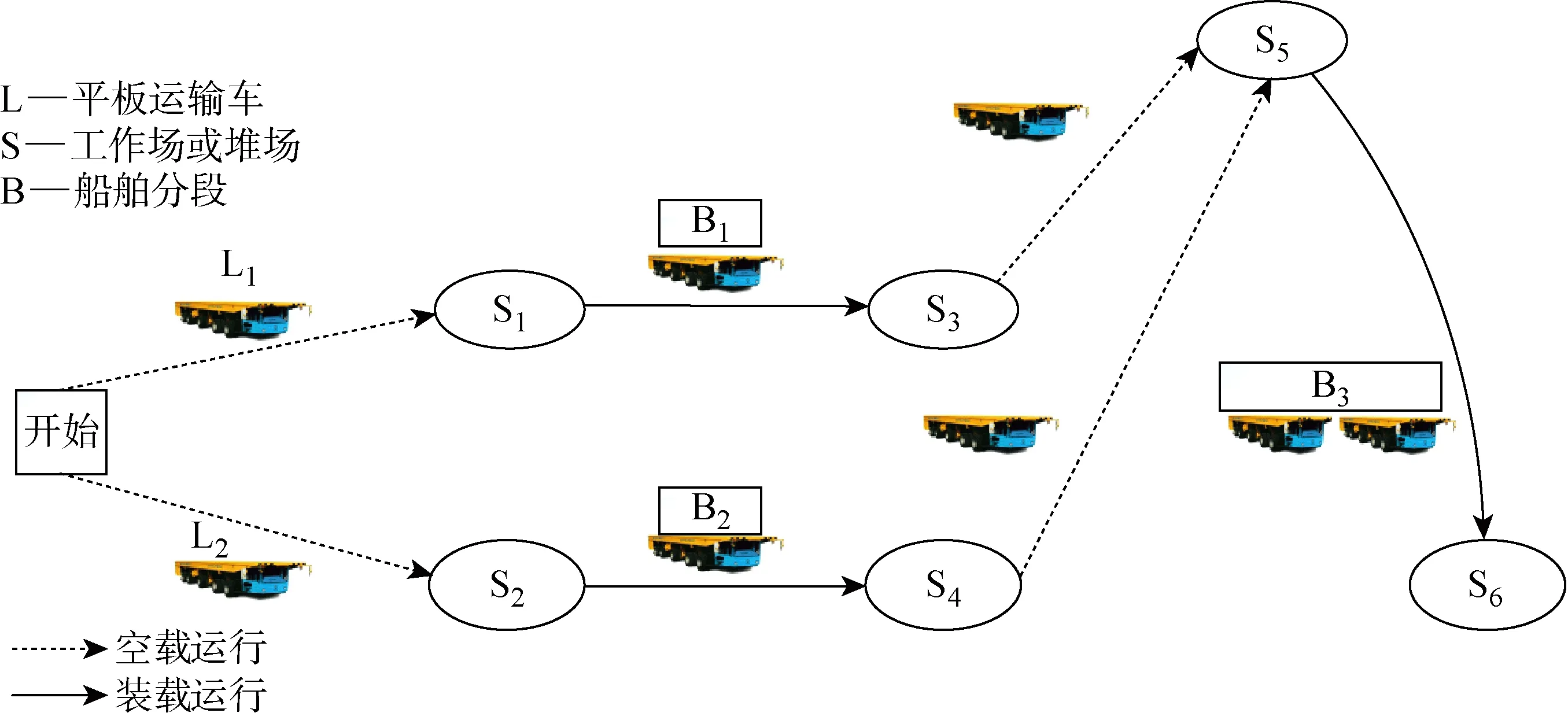
图2 平板车合作运输示意图Fig.2 Diagram of multi-flatcars cooperative transportation
考虑到堆场的实际情况以及便于堆场调度问题的研究,作出如下假设:① 平板车运输分段过程一旦开始执行, 就不可被其他任务打断;② 平板车在同一时刻最多只能运输一个分段;③ 不考虑道路因素 (道路上是否有平板车、道路宽度、道路上可以通行多少平板车)对平板车通行的影响;④ 为了方便说明, 假定大型分段的质量不超过两个平板车的承重能力之和;⑤ 合作运输的平板车可以保持一样的速度.
本研究要解决的问题有:① 运输任务的最优序列;② 运输任务对应哪些平板车执行,大型任务由哪些平板车运输;③ 各个任务的开始执行时间和完成时间.时间变量单位均为分钟,以开始工作时间作为0点,其余时间均在此基础上累加.
2 堆场间运输调度模型
2.1 目标函数
建立平板车在堆场间的运输调度模型,优化目标在调度过程中的时间因素.首先,平板车执行任务所消耗的时间是确定的,但平板车执行任务之间的空载行驶时间是不确定的,其会随着平板车上任务序列的改变而改变;其次,平板车早到堆场或工作场时,由于时间窗紧约束的原因,会使平板车产生等待时间;再次,由于考虑的是平板车合作运输的大型分段,合作运输的平板车如果到达堆场或者工作场的时间不同,也会使早到的平板车产生等待时间.而等待时间会产生附加成本,即资源的浪费,进而影响生产进程.因此,模型以平板车执行任务的空载行驶时间与等待时间的权重和作为目标函数,优化运输成本.现有研究文献中,以最小化任务完工时间作为目标函数的也较多,本文模型中由于考虑了时间窗紧约束,严格控制每个任务的执行时间,所以不需要优化任务完工时间.
(1) 平板车完成所有任务的任务间空驶时间:
(2) 平板车从车场出发空驶到其第1个任务起点的时间,以及平板车执行完任务空驶返回车场的时间:
(3) 平板车早于时间窗到达或者由于协同运输而产生的等待时间:
目标函数以上述三者的权重和作为优化目标,使其最小化.
minf=α(f1+f2)+βf3
2.2 约束条件
(1) 非大型分段由1个且只由1个平板车进行运输,大型分段由2个平板车进行运输:
(2) 每个平板车上的第1个任务只有1个:
(3) 每个平板车上的最后1个任务只有1个:
(4) 平板车上执行的相邻2个任务之间的时间存在约束:
(5) 任务时间窗约束:
(6) 车场时间窗约束:
(7) 平板车承重能力与任务分段质量约束:
(8) 对于大型分段任务来说,执行任务的平板车必须都到任务始点地,任务才能开始执行:
(9) 保证平板车上执行完一个任务后接下来的任务要满足在解中的出现次数约束:
(10) 保证平板车上执行的任务要满足在解中的出现次数约束:
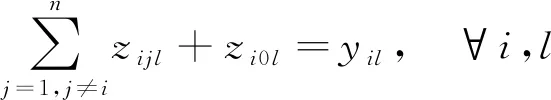
(11) 决策变量的取值范围约束:
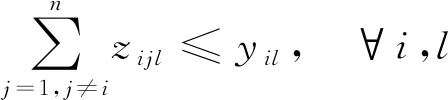
3 基于禁忌搜索的模型求解
船舶分段堆场间的运输调度模型为混合整数线性规划问题.对于小规模问题,可以采用商业求解器,如CPLEX求出最优解.但在实际应用中,需要搬运的分段数量较大,现有求解器很难在有限时间内求出高效解.禁忌搜索算法在组合优化问题中具有较好的效果,广泛应用于旅行商问题以及车辆路径问题.禁忌搜索算法依靠禁忌表的存在,可以在搜索中跳出局部最优,不同的构造邻域方法也增加了邻域空间的多样性,具有较好的求解效果.因此,设计禁忌搜索算法在分钟级别的时间内高效求解模型,具有较高的实际应用价值.
3.1 解的编码方式
模型解的编码与解码方式如图3所示.编码方式为3个一维数组串行,表示平板车运输的分段及其运输顺序.如图3(a)中,第1行表示任务序列编号,第2行和第3行表示任务被执行的平板车编号.若第2行和第3行的平板车编号相同,则表示该任务是由同一个平板车执行的;若第2行和第3行平板车编号不相同, 则表示该任务是由两个平板车合作运输的.解码后的运输方案如图3(b)所示,即平板车1执行第3、6、1、2个任务;平板车2执行第4、6、5个任务;平板车3执行第9、7、10、8个任务.其中任务6为大型任务,由平板车1和平板车2合作运输.同理,如果考虑3个平板车合作运输,则用4个一维数组串行表示平板车运输的分段及运输顺序.
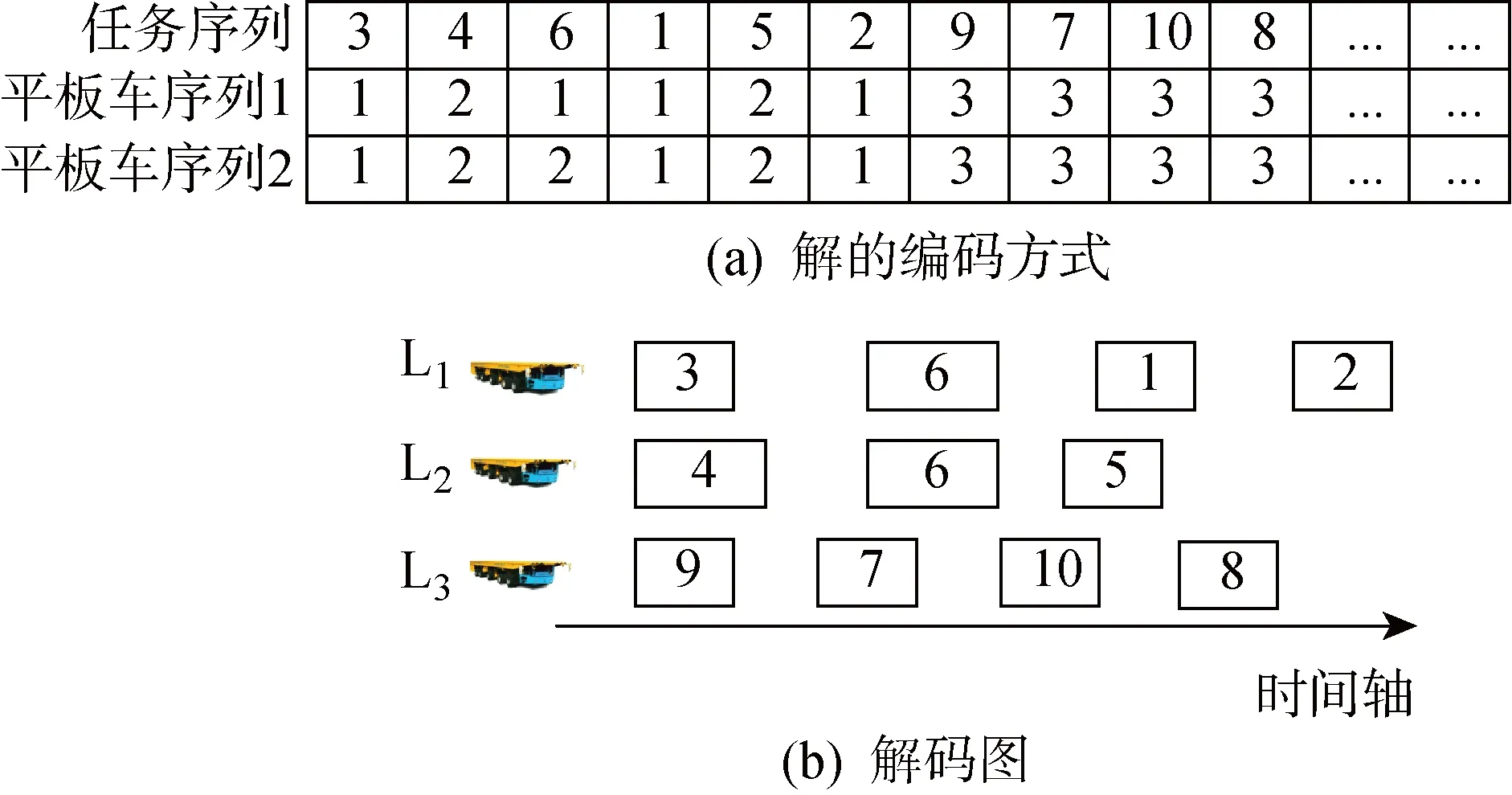
图3 编码与解码图Fig.3 Coding and decoding
3.2 构造初始种群
采用随机构造初始种群的方式,先随机生成任务序列,再根据承重约束为每个任务分配平板车,对于大型任务则随机产生两个符合其承重约束的平板车.由于模型中存在时间窗约束,很可能构造的个体是不可行的,但对于不可行解,在计算适应度时会给予惩罚,所以在迭代中,不可行解会被逐渐取代.
3.3 个体适应度评估
个体代表模型的解,个体适应度函数就是模型需要优化的目标函数,对于所提模型的适应度越低,代表个体越好.个体解码后,可以获得每个车的运输方案、计算平板车从车场出发至执行第1个任务的空载行驶时间,以及执行后续任务的空载行驶时间与执行完所有任务后回到车场的空载行驶时间.在计算平板车等待时间时,首先需要注意大型任务要等到执行大型任务的所有平板车均到达其起始点才可以开始执行.大型分段的时间更新示意图如图4所示.由图4可知,第1辆平板车上任务6的执行时间要后移,因为第2辆平板车还未到达.其次,需要调整每个平板车上第1个任务的开始执行时间,以最小化等待时间.由于任务6是大型任务,任务6的开始时间被延后,导致L1在执行完任务3后存在一段等待时间,此时需要对任务6之前的任务开始执行时间进行调整.将任务3的开始时间延后,此时等待时间就消除了(见图4右框).同理,第3辆平板车也需要对任务9的开始时间进行调整,这样可以减少平板车的等待时间.在算法求解过程中可以出现不可行解,但一定要对其适应度加上一定的惩罚,且根据不可行解的出现情况,动态改变惩罚系数.

图4 大型分段的时间更新示意图Fig.4 Diagram of time update of large-blocks
3.4 邻域结构
如何从当前解出发,构造高效的邻域解是禁忌搜索算法的核心所在.设计5种邻域结构,具体操作过程如下.
(1) M1.让1个任务从1辆平板车迁移到另外1辆平板车.
步骤1在解的任务序列上随机地选择1个任务.
步骤2若该任务是大型任务,则在满足大型任务的承重约束下生成新的平板车赋值给解的第3行序列;若该任务不是大型任务,则在满足任务承重约束下生成新的平板车,并赋值给解的第2行和第3行序列.
M1的具体领域结构图如图5所示.
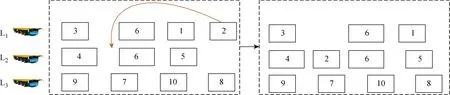
图5 M1的邻域结构Fig.5 Neighborhood structure of M1
(2) M2.让1辆平板车上的2个任务的执行顺序发生改变.
步骤1在解的平板车序列中随机选择1个平板车.
步骤2在该平板车上选择2个任务, 交换其位置及平板车号.
M2的具体领域结构图如图6所示.
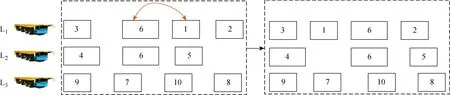
图6 M2的邻域结构Fig.6 Neighborhood structure of M2
(3) M3.让两个车之间交换任务片段,这样更有利于保护时间窗的约束[8].
步骤1在解的平板车序列中选择2个平板车.
步骤2选择平板车上除了开始和末尾的1个任务序列片段,即2个连续的任务,与另外1个平板车上的任务序列片段进行交换.
步骤3检查新的解是否满足大型任务的承重约束,若不满足,则返回步骤 1;若满足则结束.
M3的具体领域结构图如图7所示.

图7 M3的邻域结构Fig.7 Neighborhood structure of M3
(4) M4.让1辆车的上1个任务迁移到该车上的另1个任务的前面,以增加任务序列的多样性.
步骤1在解的平板车序列中选择1辆平板车.
步骤2选择平板车上的1个任务,再选择另外1个任务.
步骤3将选择的第1个任务迁移到选择的第2个任务位置前.
M4的具体邻域结构图如图8所示.

图8 M4的邻域结构Fig.8 Neighborhood structure of M4
(5) M5.让1辆车的上1个任务迁移到该车上的另1个任务之后,以增加任务序列的多样性.
步骤1在解的平板车序列中选择1辆平板车.
步骤2选择平板车上的1个任务,再选择另1个任务.
步骤3将选择的第1个任务迁移到选择的第2个任务位置后.
M5的具体邻域结构图如图9所示.
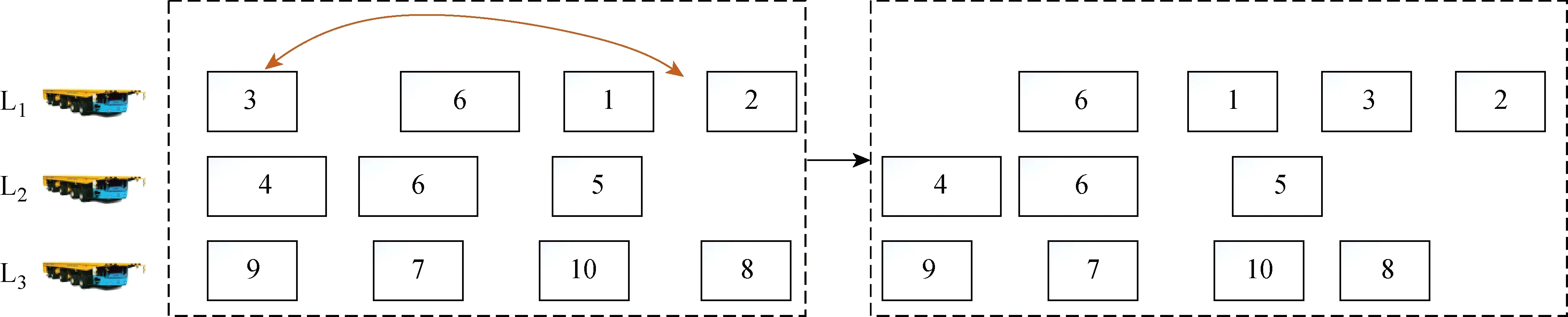
图9 M5的邻域结构Fig.9 Neighborhood structure of M5
3.5 惩罚系数的更新
由于模型的约束较多,很难一直在可行解空间搜索模型的解,且对于上述5种邻域构造方法均不保证时间窗约束的成立,所以对于不满足时间窗约束的个体,在计算个体适应度时需加上额外的惩罚.文献[9]通过研究证明,动态系数的方式效果更好,即如果本次迭代中最好的解不是可行解,则惩罚系数应变大,以减少不可行解的存在;如果本次迭代中最好的解是可行解,则惩罚系数应变小,以增大不可行解的存在.
3.6 禁忌表及特赦规则
由于上述设定的5种邻域结构是不同的,所以针对每个邻域结构分别建立禁忌表,以防止每种策略产生重复的邻域解.特赦规则为如果由禁忌表中的操作产生的解优于当前最优解,则触发特赦规则.对于第1种邻域结构,用(i,l1,l2)表示任务i由Ll1车迁移到Ll2车,则用(i,l2,l1)作为禁忌元素加入到禁忌表中以防止最优解的操作重复出现;同理,第2种邻域结构用(i,j,l)表示车Ll上任务i和任务j交换,则禁忌元素为(j,i,l)和(i,j,l);第3种邻域结构用(i1,j1,l1;i2,j2,l2)表示Ll1车上(i1,j1)任务片段与Ll2车上(i2,j2)任务片段交换,则禁忌元素为(i1,j1,l2;i2,j2,l1);第4种邻域结构用(i,j,l)表示Ll车上任务i迁移到任务j前面;第5种邻域结构用(i,j,l)表示Ll车上任务i迁移到任务j后面.禁忌长度与邻域空间有关,一般为10lgn.
4 数值试验
4.1 实例验证
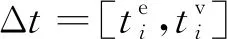
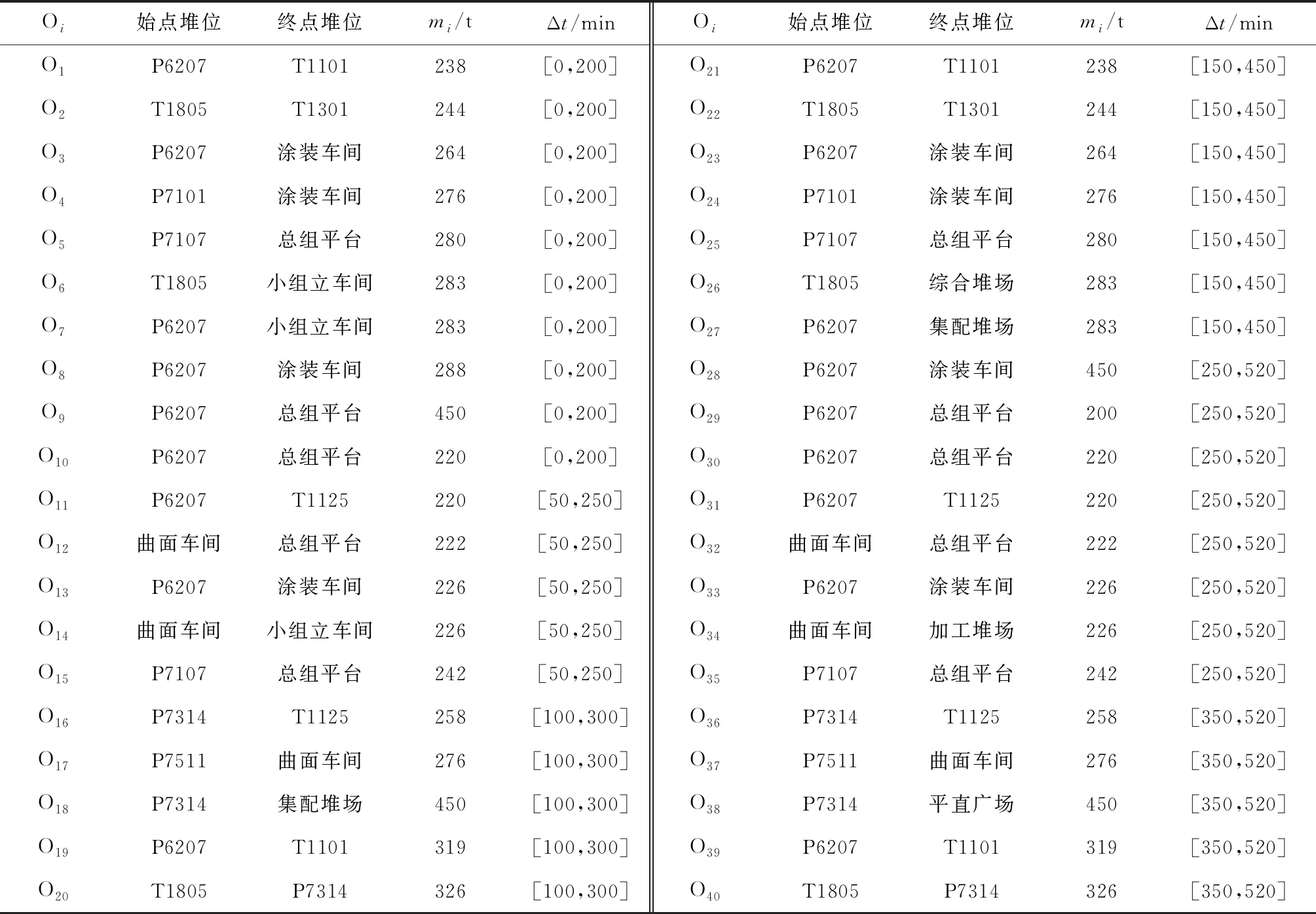
表1 运输任务和时间窗信息表Tab.1 List of transportation tasks and time windows

表2 平板车信息Tab.2 Flatcar informations
获得的调度结果如表3所示.由表3可知,平板车与执行任务之间满足承重约束;任务开始执行时间满足时间窗约束;第9、18、28、38号任务为大型任务,由两辆平板车协同运输.实例结果验证了所提算法的有效性.然而,调度结果中出现了承重能力为425、380 t的平板车运输质量为200 t分段的情况,这主要是由于调度结果是从整个调度周期的总目标函数考虑而导致的.如果质量为200 t的分段都由承重能力为250 t或270 t的平板车运输,很有可能造成250、270 t的平板车之后的运输任务不满足时间窗约束或者运输成本较高,所以算法在求解时舍弃了成本较高的解.

表3 调度结果Tab.3 Scheduling results
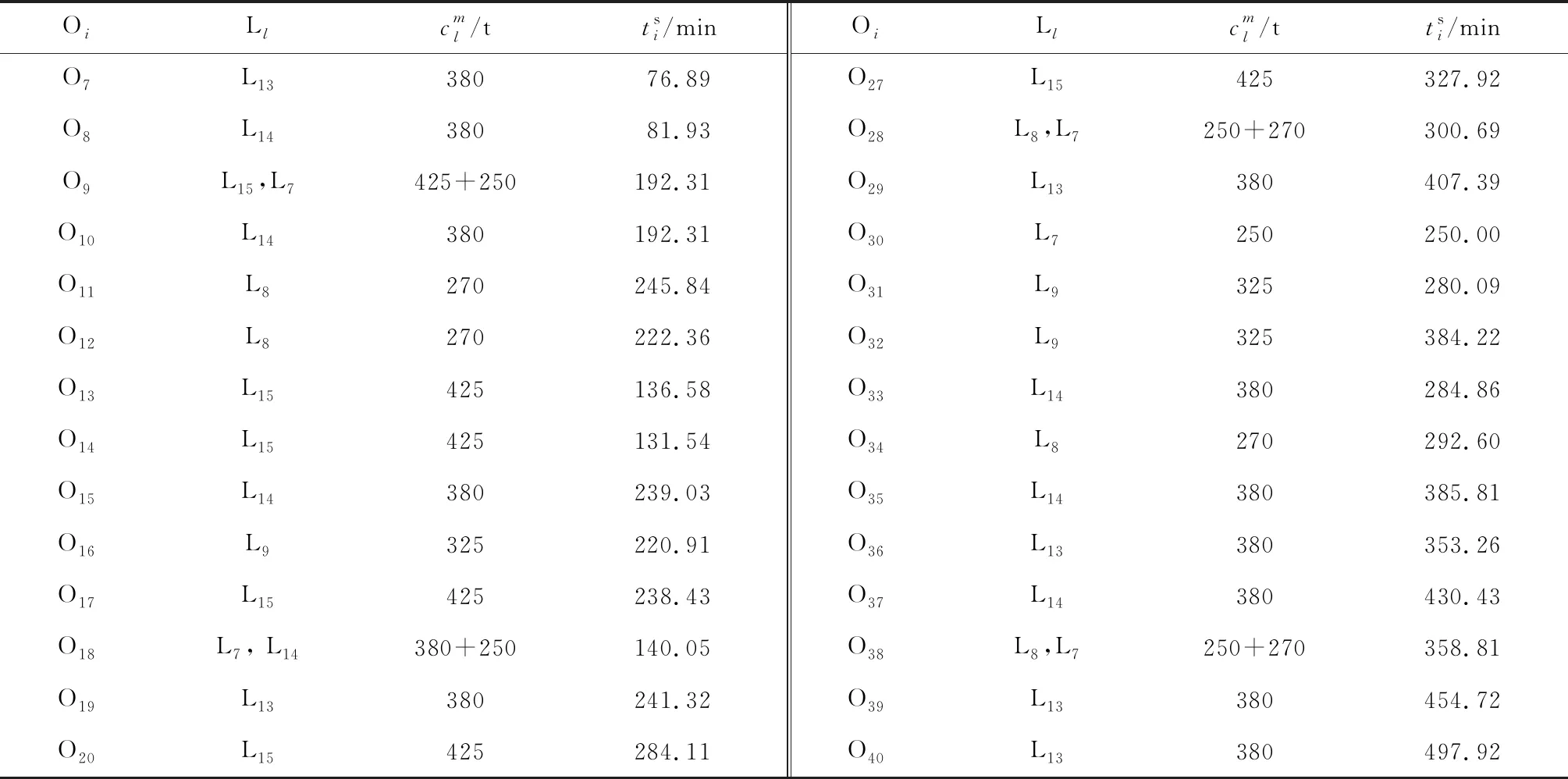
(续表)
4.2 数值实验分析
4.2.1实验条件 为了验证所提禁忌搜索算法求解模型的性能,以多组船厂的实际数据进行实验.任务数量分别为6、8、10、12、20、30、40、50;大型任务数分别为1、1、1、1、2、3、4、5;平板车数量为2、3、4、5、6、7、8.以任务执行时间、各任务之间的行驶时间作为输入量.时间窗根据实际背景进行调整.选用IBM ILOG CPLEX优化求解器求解模型,禁忌搜索基于Java语言编写.考虑到实际应用及便于对比等因素,设定CPLEX求解器的求解时间为 3 600 s.
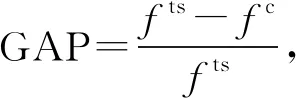
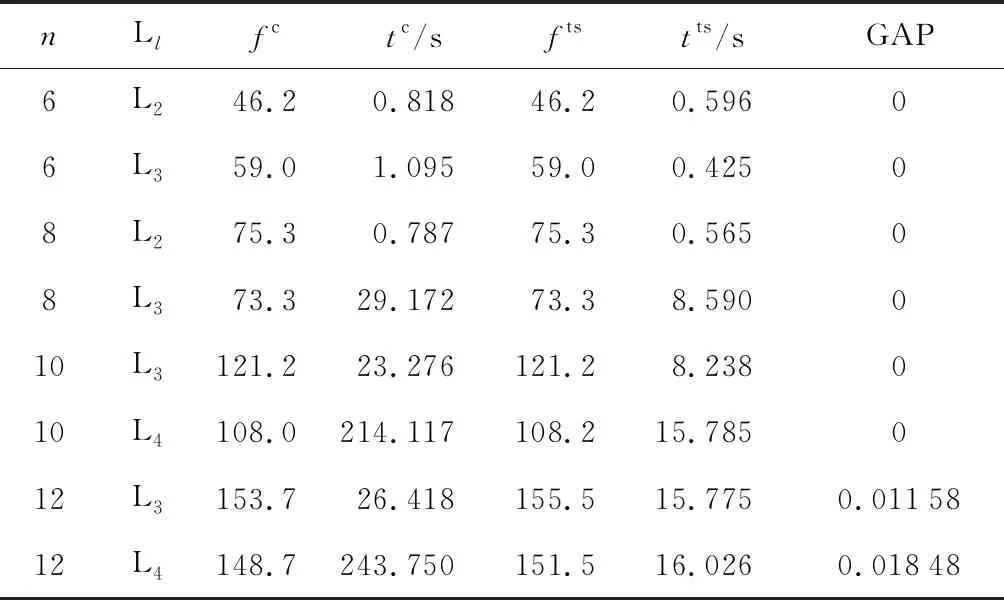
表4 小规模任务的CPLEX与禁忌搜索求解对比
由表4可知,随着任务数和平板车数量的增加,CPLEX的求解时间急剧增加.禁忌搜索算法在任务数为6、8、10时能够求出最优解,在未求出最优解的测试用例上求出近最优解,GAP小于0.02,同时求解时间并没有急剧增加,证明禁忌搜索算法是有效且可行的.由表5可知,当任务数为20、平板车数为4时,CPLEX已经在 3 600 s内无法求出最优解.针对较大规模的任务数和平板车数时,禁忌搜索算法均可以在80s内求得结果,且在任务数为30、40、50时求得的结果明显优于CPLEX.其他任务数和平板车数上GAP均小于0.04,验证了禁忌搜索算法在实际应用中具有较好的效果.
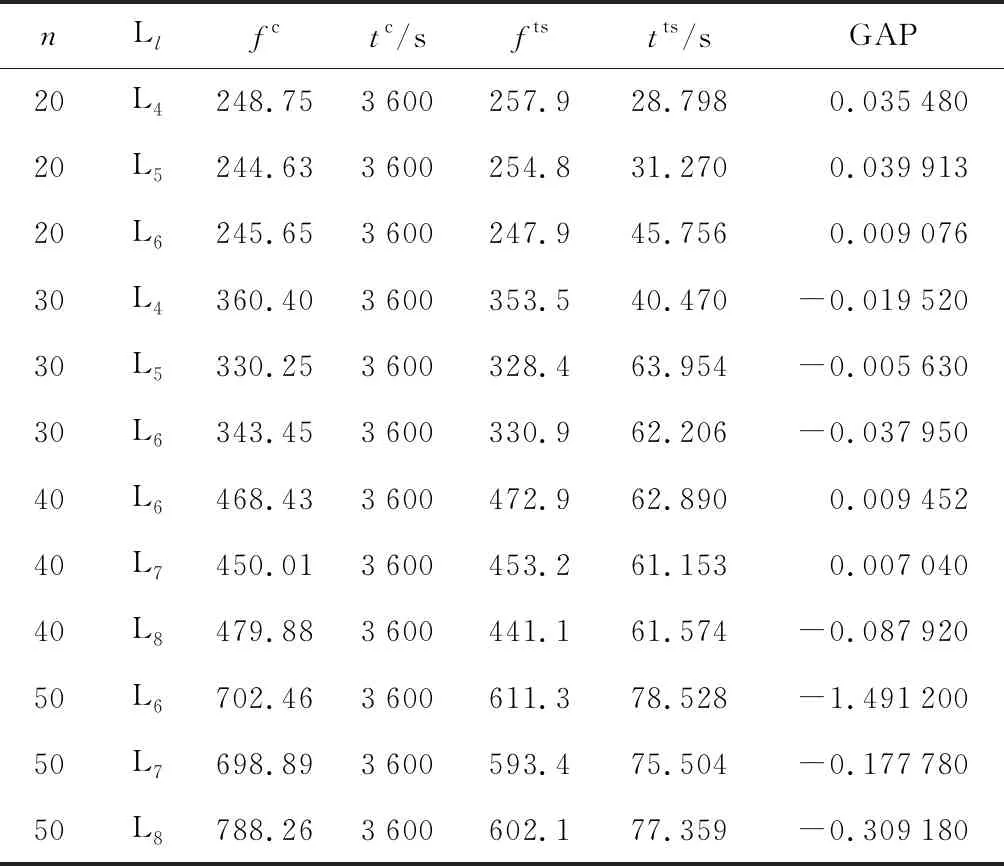
表5 中等规模任务的CPLEX与禁忌搜索求解对比
由于模型目标函数考虑了等待时间,所以需要考虑所有任务的开始执行时间,但是禁忌搜索算法却不能遍历所有任务的开始时间,只能根据时间窗和任务序列的时间连贯性进行微调整,这就导致了大规模任务时禁忌搜索求解结果与最优解在等待时间上会有一定的差距.
5 结语
考虑平板车合作运输的船舶分段堆场间的运输调度模型,通过平板车合作运输解决大型分段的运输难点,提出通过调整任务的开始时间以减小平板车的等待时间.从数值结果可以看出,所提算法在规模较大的情况下依然可以快速求得质量较高的解,验证了所设计的禁忌搜索算法具有较好的效果,可用于实际生产.但如何提高大规模问题解的精度、如何使算法求解稳定、如何设计策略优化平板车的等待时间等问题仍需进一步的研究.
猜你喜欢
智能建筑电气技术(2022年2期)2022-02-06 02:30:50
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19 08:38:42
机械工程师(2020年3期)2020-03-27 06:32:22
运筹与管理(2019年1期)2019-02-15 09:26:42
设备管理与维修(2018年7期)2018-03-28 12:32:45
电测与仪表(2015年15期)2015-04-12 00:43:48
河北科技大学学报(2015年5期)2015-03-11 16:16:37
集装箱化(2014年12期)2015-01-06 18:31:36
集装箱化(2014年10期)2014-10-31 18:28:10
中央民族大学学报(自然科学版)(2014年1期)2014-06-11 01:28:38
