
并行处理技术在全球海量地理信息数据质量控制中的应用
2020-08-03 13:23:36张俊辉林尚纬万咏涛
测绘通报 2020年7期
周 琦,杜 晓,张俊辉,郑 义,林尚纬,万咏涛
(国家基础地理信息中心,北京 100830)
地理信息数据是国民经济和社会发展各行业统一的空间基础和信息载体,是不可或缺的国家战略性信息资源的重要组成部分,是整合各类经济、政治、社会、军事、文化各类信息的基础,是实现“一带一路”大数据资源体系的空间定位与空间关联支撑框架。
地理信息数据的质量关系到国计民生,直接影响我国对全球资源、态势、突发事件的掌控、监测、评估和应急处置决策,限制我国参与国际事务、实施全球战略的进度和深度。近些年由于我国的国际地位不断提高,海外利益愈发广泛,为满足国家、社会需要,测绘生产中涉及的空间数据范围已由国内逐渐向境外地区蔓延,空间数据的获取手段、方法日趋成熟,数字化生产的效率越来越高,使得面对海量地理信息数据的管理与质量控制问题面临很大的困难。当前数据检查主要以计算机按检查规则自动检查配合人机交互判断为主,质检软件和工具基本为单机运行,而且没有任务管理功能,无法进行质检任务的分配、调度和进度监控,对质检方案的使用也不能进行约束。由于质检人员水平参差不齐,对质量问题的认识不一致,加上专业素养的差别,导致不同人员质检的结果差异很大,质检人员工作态度和责任心的问题也可能使部分检查项漏检或错检[1]。此外,目前已有的质量控制体系适应范围单一,缺乏系统性设计,不便于质量信息的汇总、统计和追溯,更无法满足检查任务对时效性的要求。
针对全球海量地理信息数据成果数据量大、数据类型丰富、质量控制检查项庞杂的特点,本文研究并行处理技术在海量地理信息数据质量控制中的应用,以期实现压缩任务执行时间、节约任务执行成本、实现质量信息的汇总、统计和可追溯的目的。首先介绍现有的高性能并行计算模型/框架以及各自优势对比;然后研究基于MapReduce框架的多源多时相海量数据并行质量控制技术,依托成熟度高的自主研发平台,将分布式并行计算技术、多线程技术应用到地理信息数据质量控制体系中,进一步解决传统计算机数据自动检查时人为操作多、检查计算慢、自动化判断程度低的质量控制难题;最后选取核心矢量要素、DOM成果、DEM成果作为典型数据案例开展对比试验。
1 分布式集群并行计算模型及框架
当前主流的分布式集群并行计算模型及框架[2]有MPI分布式并行计算模型、MapReduce分布式计算模型和Spark分布式内存计算模型。见表1。
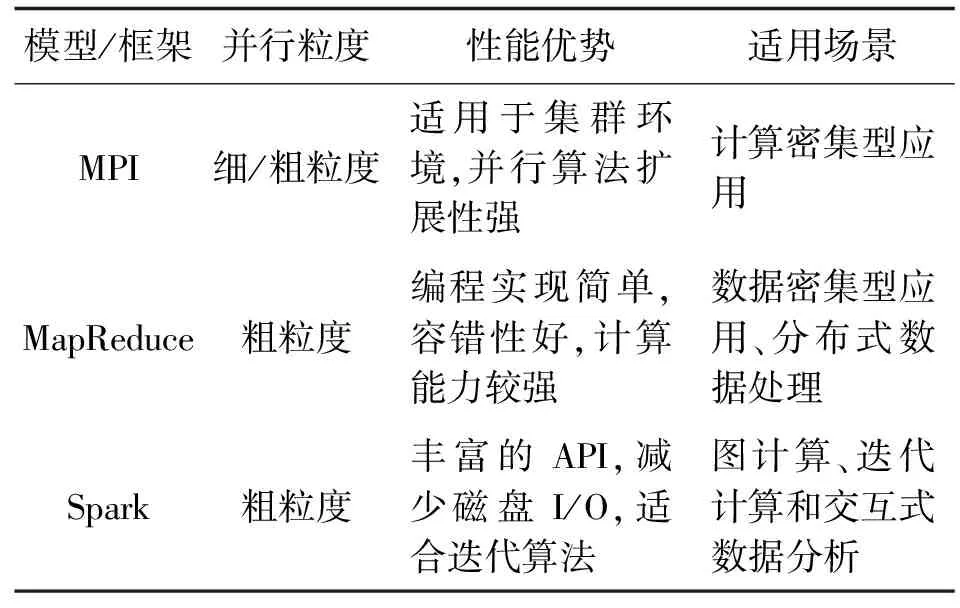
表1 面向分布式集群的并行计算模型
(1)MPI分布式并行计算模型。MPI是一个基于消息传递的并行计算应用程序接口[3],主要应用于分布式集群上,可支持广播和点对点两种通信方式。MPI具有较强的可移植性,可以兼容应用于共享内存、分布式内存处理平台。分布式集群上一般采用的混合编程模型结合了MPI和OpenMP二者的优点,基于OpenMP实现线程级并行,基于MPI实现任务分配和消息传递,最终实现线程和进程两个层次的并行计算[4]。目前大型计算、密集型应用使用的主流并行计算模型便是MPI分布式并行计算模型。
(2)MapReduce分布式并行计算模型。文献[5—7]奠定了当前云计算技术发展的基础,其中MapReduce并行开发模型是面向大规模数据集的并行处理,可以实现计算任务的自动并行和调度,同时隐藏底层实现细节,大大降低编程难度,因此被广泛应用[8-9]。MapReduce模型把计算过程抽象为两个阶段,即Map和Reduce,用户通过实现map(映射)和reduce(规约)两个函数,从而实现分布式计算。
(3)Spark分布式内存计算模型。Spark是一个开源通用并行计算框架[10],支持海量数据集的并行处理。Spark弹性分布式数据集(RDD)作为一个可并行操作、有容错机制的数据集合,提供了统一的分布式共享内存。Spark使用内存计算技术减少磁盘I/O,允许多次循环访问内存数据集,有助于实现迭代算法;另外Spark容错性高,可以确保分布式应用的正确执行。因此Spark在大数据并行处理应用中发挥着日益重要的作用,但也存在对计算机内存消耗过大的问题。
目前,国内外专家学者在基于MapReduce并行框架的地理信息数据处理方面开展了大量研究,但研究相对集中于各种算法的并行化改造方面[11-13],对并行处理架构下的地理信息数据质量控制研究相对较少。基于此,本文依托自主构建的矢量数据和栅格数据质检规则库,构建了基于MapReduce框架的地理信息数据质量控制体系,以期全面提升地理信息数据质量控制的效率。
2 基于并行处理技术的海量地理信息数据质量控制
地理信息数据质量控制包括空间参考检查、位置精度检查、属性精度检查、完整性检查、逻辑一致性检查、表征质量检查及附件质量检查等内容。为实现对海量地理信息数据质量控制效率的快速提升,本文引入基于MapReduce分布式计算的并行访问机制,利用CPU进行计算任务的管理,协同利用GPU与CPU共同参与运算,首先采用基于多计算节点的多任务并行检查策略,在集群环境中由一个周期执行一个操作的算法结构,改造为一个周期可同时执行多个操作的并行算法;然后使用基于多线程的多任务并行检查策略,在单计算节点上将计算任务分解成同一个进程的多个线程来执行,实现多个检查任务在多计算节点间和单计算节点多核上的并行计算,提高海量地理信息数据的质检效率。
分布式并行计算框架技术的思想是,在同一个集群环境中同时部署硬盘存储文件系统和内存存储文件系统,通过发挥各自的优势实现数据的安全性、持久化存储与高效计算。其中,计算节点之间以“主-从”式结构进行组织,主节点以实时热备的方式防止出现单点故障。主节点负责调配其他从节点,还负责处理上层应用数据请求;从节点之间不进行通信,但可以通过主节点的调配控制让从节点间的数据实现互备。如图1所示。

图1 分布式并行计算框架技术
2.1 基于多计算节点的多任务并行检查
多计算节点间的并行质量检查通过Torque并行作业调度[14]实现。首先用户提交的检查任务在资源管理模块中排队等待,直到任务需要的CPU类型、数量内存大小等资源满足条件才能执行。然后对多任务并行操作进行调度时,Torque根据事先定义的集群调度策略决定等待队列中的检查任务要在哪些计算节点上执行,在满足不同用户需求和最大化整合分布式集群资源利用率之间达到动态平衡。
Torque支持多任务批处理、多种作业调度策略,实现对多任务批处理的初始化和调度执行的控制,其独立调度模块允许系统管理员定义资源和每个任务可使用的数量,实时监控排队任务、运行任务和系统资源使用状况。Torque由4部分组成,分别是PBS用户命令、PBS服务(pbs_server)、PBS执行(pbs_mom)和PBS调度(pbs_sched)。如图2所示。
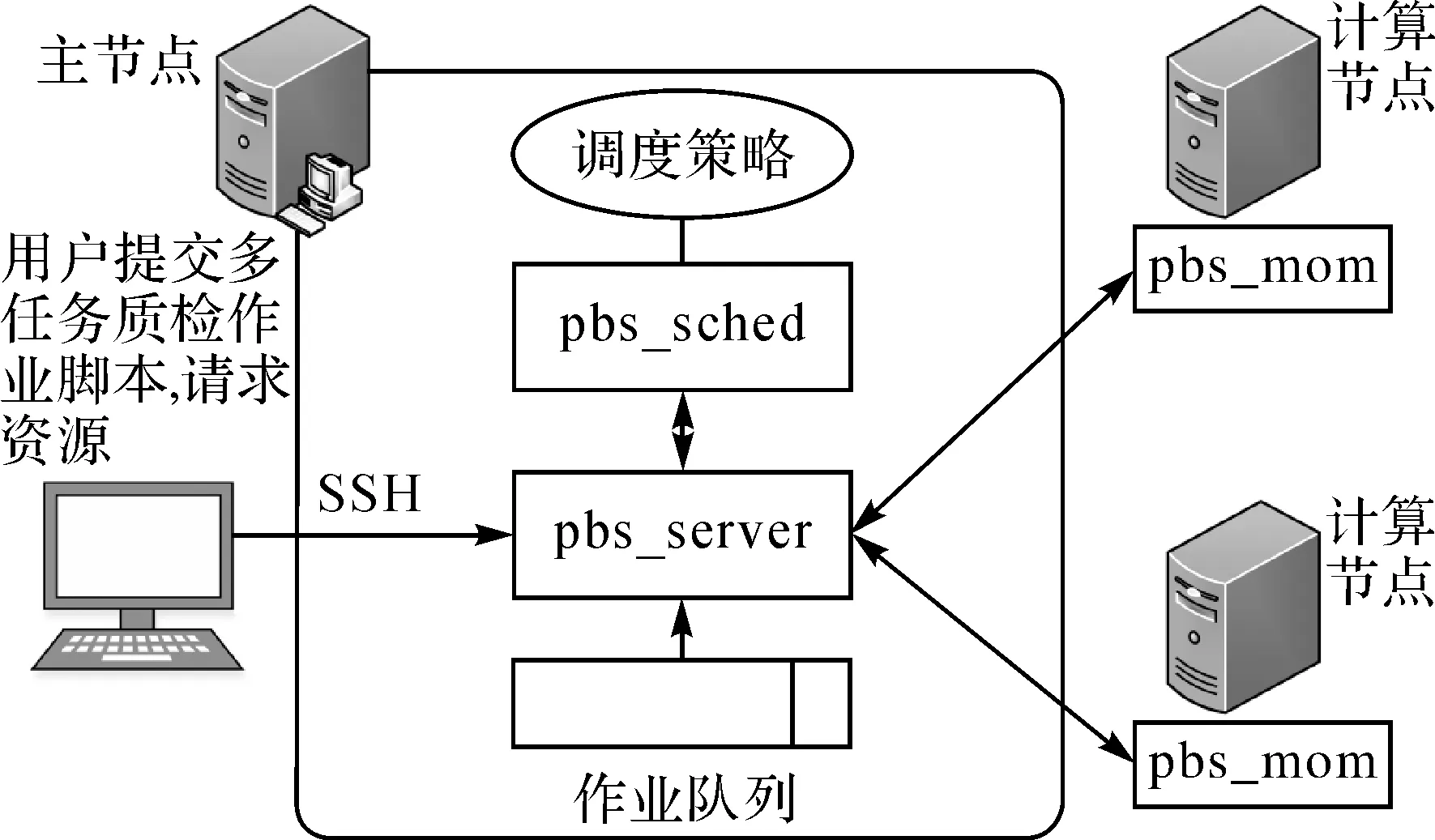
图2 Torque并行作业调度架构
(1)PBS用户命令主要用于用户递交、查询、队列管理和删除多任务批处理质检任务。
(2)PBS服务用于接收、产生、调整、保护、启动用户的多任务批处理质检任务。
(3)PBS执行用户执行节点上的守护程序,将服务器上的用户任务复制到节点上驱动任务。
近年来高校大规模扩招,只注重学生的数量,招收学生分数入学分比较低,却轻视了质量,而这些学生自身惰性比较大,自学能力差,很依赖老师,从而影响了教学质量,大学教育从精英化教育变成了大众化教育,会计专业作为一直以来的热门专业,招进大量学生,但质量却良莠不齐,缺乏个性化教育。
(4)PBS调度用于多任务批处理质检任务运行的排队调度控制。
2.2 基于多线程的多任务并行检查
在多核系统中,并行计算包括基于多进程计算与基于多线程计算两种方式。基于多进程的并行计算是将一个计算任务拆解为多个独立的计算进程执行,进程间的调度在操作系统内核进行;基于线程的并行计算是将计算任务分解成同一个进程的多个线程来执行,线程间的调度由操作系统内核进行。通常多核系统中基于多线程的编程比基于多进程的编程具有更大优势,因此本文利用多线程技术搭建并行检查框架,实现不同区域、不同数据类型的多任务批处理并行检查。每个检查任务完全独立,互不干扰,在提高检查效率的同时,有效杜绝因某个任务执行失败而导致的全盘停滞现象。
基于多线程的多任务并行检查模型由质检任务调度模块、质检任务线程模块、线程控制模块、质检结果输出模块4部分组成[15]。如图3所示。

图3 基于多线程的多任务并行检查模型
(1)质检任务调度模块负责获取质检任务的处理请求,并将接收到的处理请求加入质检任务等待队列,对质检任务等待队列实时监控,发现处理请求后依据先进先出的原则选择任务执行,并依据任务调度策略为该任务分配质检任务进程。主要包括质检任务等待缓冲区和调度控制单元两个工作单元。
(2)质检任务线程模块负责创建质检任务线程及其线程索引表,按照预设的线程容量创建相应数量的质检线程,同时为每个质检线程开辟与之对应的任务等待队列,线程执行过程中实时监控该等待队列,获取相关任务参数完成数据计算以及数据显示等操作。主要包括线程索引表和工作线程两个工作单元。
(3)线程控制模块主要负责在系统运行过程中实时监控工作线程中的多线程,并通过计算当前系统负载,利用容量调节单元对线程中线程数量进行相应的增减,使计算资源达到最优的负载均衡,同时对状态异常的线程进行回收。该模块主要包括容量调节单元、线程监控单元和线程干预单元3个工作单元。
(4)质检结果输出部分为质检任务计算结果提供输出接口,系统通过该接口获取质检任务执行数据并提交前端应用进行展现。
3 试验与分析
为了验证并行处理技术在海量地理信息数据质量控制中的应用效果,本文选取核心矢量要素、DSM产品、DOM产品3种成果数据作为试验数据进行试验与分析。
3.1 试验数据
综合考虑地理信息资源数据分布的典型性、位置分布的广域性等因素,按照“典型多样、急需优先、面积合理”的原则,选取韩国、蒙古2个国家,合计约1079 GB的地理信息数据开展规模化质量控制检查,进一步验证基于并行处理技术的质量控制体系的可行性和普适性(见表2)。
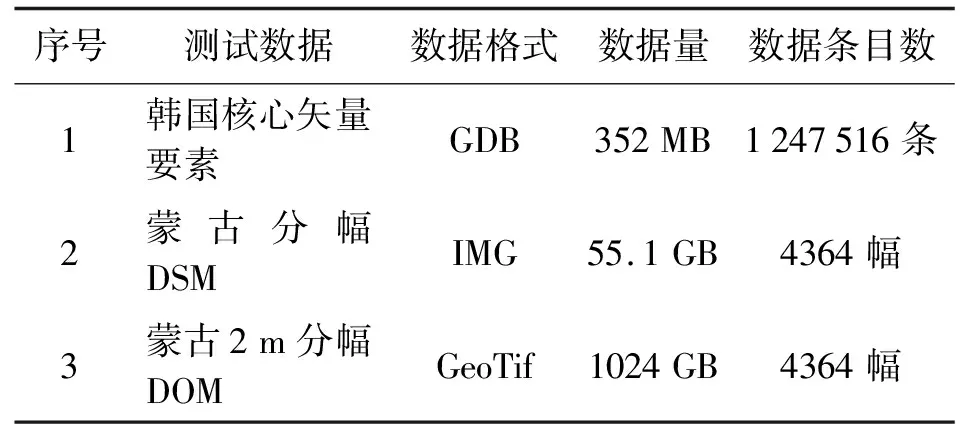
表2 试验数据
3.2 试验环境
本文所有的试验均在如表3硬件配置的电脑上运行。

表3 硬件环境
3.3 批量自动检查
使用并行处理改造后的地理信息数据质量控制软件对韩国区域的核心矢量要素、蒙古区域的分幅DSM、分幅DOM及相应的元数据文件进行批量自动化检查,并与改造前的质检效率进行对比分析。
核心矢量要素质检效率随着线程数的增加而产生的变化趋势如图4所示。随着线程数量的不断增加,核心矢量要素质检的效率不断提升,当线程数达到某个阈值(10)后,线程数的增加对核心矢量要素质检效率几乎不再产生影响。

图4 多线程并行方法对核心矢量要素质检效率影响
核心矢量要素、分幅DSM、分幅DOM自动检查项及检查效率见表4。
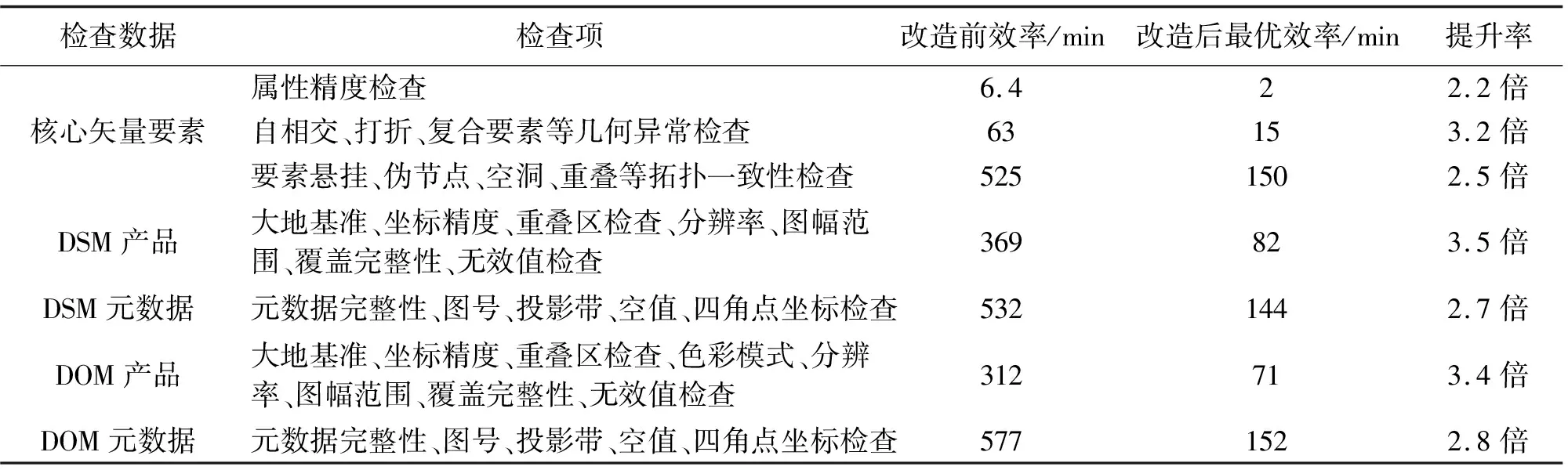
表4 并行改造前后的自动检查效率
从试验结果可以看出,得益于分布式并行计算技术、多线程技术的运用,本文实现了不同区域、不同数据类型的多个质量控制任务的并行开展。相对于传统技术方法,核心矢量要素、DSM产品、DOM产品质量检查的效率提高了2~3倍,从而使地理信息资源的及时质量控制得到保障。
4 结 论
针对多源多时相海量地理信息数据的质量控制要求,本文依托成熟度高的自主研发平台,构建了基于MapReduce框架的多源多时相海量数据并行质量控制体系,将分布式并行计算技术、多线程技术应用到地理信息数据质量控制体系中,打破了传统质量检查软件老旧单一的计算模式,实现了不同区域、不同数据类型的多个质量控制任务的并行开展,使检查效率提高了2~3倍。同时有效杜绝了因某个任务执行失败而导致的全盘停滞现象,保证了对全球海量地理信息数据高效及时的质量控制。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31 08:58:18
当代陕西(2019年14期)2019-08-26 09:42:00
中国生物医学工程学报(2019年6期)2019-07-16 07:52:40
环球市场(2017年36期)2017-03-09 15:48:21
中学数学杂志(初中版)(2016年5期)2016-11-01 09:00:33
自动化学报(2016年3期)2016-08-23 12:02:56
电测与仪表(2016年5期)2016-04-22 01:13:46
计算机工程(2014年6期)2014-02-28 01:26:17
测绘科学与工程(2014年2期)2014-02-27 07:05:49
吉林建筑大学学报(2012年3期)2012-08-15 00:54:52
