
基于K-means算法的专利数据分析
2020-07-27 12:10薛淑晖王丽吴海涛
现代信息科技 2020年5期
薛淑晖 王丽 吴海涛

摘 要:专利信息作为目前国际知识产权中科技含量最高的存在,是国家和企业获取竞争优势最全面的技术情报来源。使用专利数据网的数据信息作为测试数据,采用K-means算法,针对专利文本数据进行聚类分析,旨在找出隐含在专利数据信息中不容易被直观发现或直接统计得出的数据情报信息。通过深入挖掘专利信息,提高专利信息利用率,使之转换为具有实际价值的情报信息,有效解决了对专利信息利用不足的问题。
关键词:聚类分析;K-means;专利数据;数据挖掘
中图分类号:TP391.1;TP312 文献标识码:A 文章编号:2096-4706(2020)05-0085-03
Patent Data Analysis Based on K-means Algorithm
XUE Shuhui,WANG Li,WU Haitao
(Nanjing Institute of Technology,Nanjing 211167,China)
Abstract:Patent information is the most comprehensive source of technical information for countries and enterprises to obtain competitive advantages. In this paper,the data information of the patent data network is used as the test data,and K-means algorithm is adopted to conduct clustering analysis on the patent text data. The aim is to find out the data intelligence information which is hidden in the patent data information and not easy to be found directly. Through deep mining of patent information,improving the utilization rate of patent information,transforming it into information with practical value,the problem of insufficient utilization of patent information is effectively solved.
Keywords:cluster analysis;K-means;patent data;date mining
0 引 言
数字信息网络的飞速发展正逐步改变着信息服务的传统模式,科研、教育、文献等数字情报服务正处于高速发展的变革阶段,这预示着数据科学和计算科学的情报分析和知识服务时代已经来临。尤其近年来,随着大量科研实验内容及其成果数字化的实现,以专利信息和科研论文为主题的文献情报发展迅速。知识产权的重要性愈发显著,已成为一个国家或企业在同行业竞争中获取优先优势占据有利地位的主要手段。专利信息,作为目前国际众所周知的知识产权中科技含量最高的存在,是国家和企业获取竞争优势的最全面的技术情报来源。但是面对浩如烟海的专利信息,如何从中充分发现并利用其价值是目前进行专利数據分析挖掘的重中之重。
当今我国目前的数据研究和数据分析都处于快速发展阶段,针对专利数据的统计分析和引文分析较为成熟,但对专利信息的深入研究分析尚有明显不足之处,而聚类分析和关联分析的存在,恰恰可以弥补这部分的缺陷。聚类分析可以帮助我们分析隐含在海量专利数据中的、不容易被直接统计得出的信息,适合通过比对专利数据的共同之处研究专利研究的趋势和重点,从而抓住发展的趋势[1]。为了对专利信息进行更深层次的挖掘利用,本文基于江苏省大学生创新训练项目“基于Python的专利数据分析系统的设计与实现”中文本聚类分析的K-means算法,从专利的名称入手,基于Python语言对医药专利数据进行专利文本聚类分析。
1 文本聚类分析
聚类就是根据不同的类型特征,将数据划分为相应的数据类。目的是减小同类型数据之间的距离,增加不同类型数据间的距离[2]。聚类算法又称为群分析,是数据挖掘领域的重要算法之一。
在选择以何种聚类算法来实现聚类分析时,需要从数据类型、聚类目的以及实际应用三个方面来考虑。对专利数据信息进行聚类分析,主要是对专利信息中的标题名称和摘要中的文本内容进行分析。在所有文本聚类算法中,K-means聚类算法是比较传统和基础的聚类算法。我们可以根据自己的需求决定聚成几类,其中每个类别都用该类中所有数据的平均值来表示,这个平均值被称为聚类中心。这种算法虽然不能用于类别属性的数据,但对数值属性的数据来讲,能够较好地发挥聚类方法在几何学和数学统计学上的研究价值[3]。
整体来说,文本聚类分析一般按照以下几个步骤进行:
(1)数据预处理。对专利数据进行文本聚类分析之前要先进行专利字段提取、分词、去停用词、提取关键字、预处理等计算。
(2)停用词处理。对抓取到的专利数据文档利用jieba分词库进行去停用词处理。
(3)数字建模与文本聚类。将经过初步数据处理得到的专利文本关键词进行数字建模处理,数据分析结果采用矩阵表示。数字建模处理所建立的VSM模型中的VSM的维度由专利数据进行预处理后得到的关键词数目表示,向量的大小用来表示关键词的权重。文本聚类算法采用TF-IDF权值计算法,所得词频TF表示特征关键词在VSM数据模型中出现的频率。
(4)分析处理。最后采用K-means算法对创建成功的VSM模型中的向量进行聚类分析处理[2]。
1.1 数据采集及预处理
使用Python数据抓取技术编写数据爬虫脚本,对专利网的数据进行抓取。抓取成功后对采集到的专利数据进行初步筛选、清洗[3]。由于专利文本信息过于庞大,在这里我们采取医药数据的动物医药分支进行处理研究,摘取关于动物医药的专利标题及摘要进行文本聚类验证。由于Python语言的简便性,以及其在科学计算、数据可视化领域拥有丰富的工具包,我们采用Python语言对专利数据进行分析处理。
1.2 停用词处理
在聚类分析开始之前对提取出的专利文本数据进行预处理可以提高聚类分析的效率,使分析出的结果更有意义。预处理的质量会严重影响聚类分析的结果。经过预处理,文本最终会以一种结构化的形式展现出来。文本预处理主要包括以下几个方面:
1.2.1 分词
分词,就是把一个句子按照词语表达的含义进行分割。对于英语文本来说,由于每一个英文单词之间都使用空格分开,所以分词很容易实现。但对于中文文本来说,汉字的组词非常灵活,词语和词语之间的分割标志并不鲜明,这就增加了中文分词的困难性。
1.2.2 词性标注
清华大学和山西大学是主要研究汉语词性标注的机构。他们处理的基本思路是人工标注数万字的语言材料,通过统计带词性标记的词语出现的频率,做成统计表并提取词类共现频度矩阵,建立词类自动标注的概率计算模型[4]。对文本分词后进行词性标注可以从语法上检验分词是否正确,从而进一步优化分词的结果。
1.2.3 停用词过滤
停用词是指一些在文本中出现的频率很高但是对文本内容所要表达的含义没有任何贡献的词,并且在计算相似度的过程中会引入不必要的误差。所以,把这些停用词从文本中过滤出去非常有必要。这一过程就称之为停用词过滤。
停用词过滤首先要建立出一个包含文本中所有停用词的列表。通过查询每一个词条,判断该词条是否包含在停用词列表中,如果包含就将其从词条中删除。这一过程可以提高文本聚类的效率和聚类分析的精确度。
文本挖掘和文本聚类的基础就是文本预处理,只有做好预处理工作,才能保证文本挖掘的可靠性和实用性。
1.3 利用TF-IDF算法计算其权值
使用TF-IDF算法计算权值过程中,主要对预处理过后的文本数据进行权重的分配,这一过程主要利用逆向文档频率和词频来分配权重。文本数据的关键词的权重值和文本中的频率成正比,和文集中包括这一关键词的文档总和成反比[5]。TF-IDF的应用综合考虑了关键词在单个文本中和多个文本中出现的次数的情况,使分析结果更具有可靠性。词频算法如下:
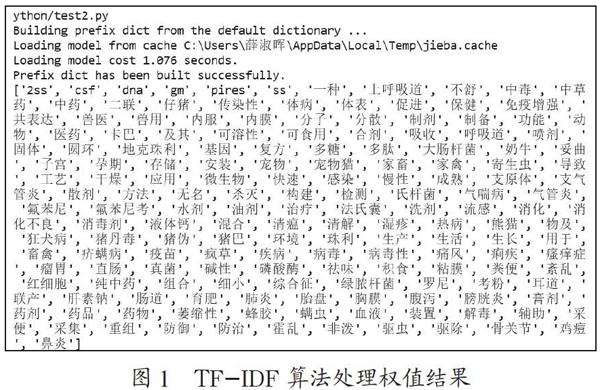
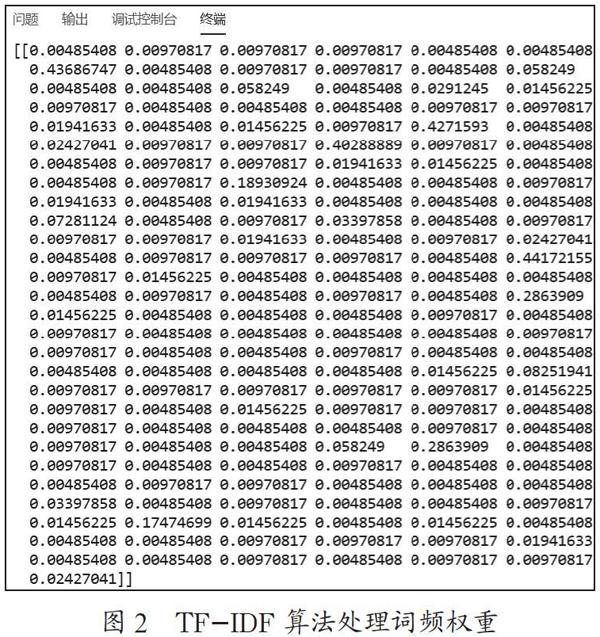
式(1)中,tfij表示特征词ti在数据集dj的词频,N是专利文献总数,Ni表示其中出现特征词的数量。专利文献标题经TF-IDF权值处理后如图1所示,其各项词频权重如图2所示。权值和权重为一一对应关系。
1.3 使用K-means算法聚类分析
K-means算法,又称K均值算法,是于1955年提出的一种新型划分式聚类算法。聚类算法发展多年过程中,K-means算法一直未被淘汰,是聚类算法的经典算法之一。顾名思义,其是通过多次反复迭代求数据间的均值来实现大量数据的文本聚类分析。其算法的核心是:通过随机选择的方式选择多个数据点,再把这些选中的数据点用作K-means算法分析过程中的初始类簇中心,再将其他未选中的数据点依次分配给最近的类簇中心,这就形成了一个个的初始类簇。接着,计算每个随机组成的初始类簇内所有点的均值,并把计算所得的簇内均值当作一个个新的类簇中心点,重新分配其余数据点到离自身最近的类簇中心點;然后,重复迭代这一分配求均值过程,直到每个类簇的中心都不再产生变化[6]。聚类分析结果如图3所示,对应图1、图2的词频和词重,可以根据数字的大小明确地观察出各关键词之间的聚类关系,数字越小,代表对应的关键词与其他词的相关性越小。反之,则证明与之对应的关键词在整个数据集中相对较为重要。关键词和其分析结果能帮助我们从宏观上大致确定专利研究的主题和各主题的重要性。
1.4 数据分析及方法的总结
本文进行专利数据文本聚类所采用的K-means算法,其无监督式的自主搜寻方法,在聚类过程中,打破了我们固有的思维模式,避免了仅凭专利知识对专利数据进行分类从而导致的思想局限和误区,能更好地摆脱个人思想带来的主观局限性[7]。但对文本特征值进行权值计算的方法却有很大的局限性:其只适用于维度低的文本,否则会影响聚类的准确性。
2 结 论
本文基于Python语言,采用网络爬虫技术获取到专利数据,然后通过K-means算法对数据进行了聚类分析。通过对专利数据的聚类分析可以清楚直观地发现当前专利网上现有专利的研究方向及偏重点,在很大程度上提高了用户对专利数据把控的准确度,在研究中具有重大意义。
参考文献:
[1] 齐丽花,张妮妮,秦晓梅.基于K-means的专利文本聚类分析 [J].电脑知识与技术,2018,14(22):206-207+214.
[2] 吴启明,易云飞.文本聚类综述 [J].河池学院学报,2008(2):86-91.
[3] 徐丹丹. 专利文本聚类分析及可视化研究 [D].南京:南京理工大学,2009.
[4] 王彬宇,刘文芬,胡学先,等.基于余弦距离选取初始簇中心的文本聚类研究 [J].计算机工程与应用,2018,54(10):11-18.
[5] 霍纬纲,程震,程文莉.面向不等长多维时间序列的聚类改进算法 [J].计算机应用,2017,37(12):3477-3481.
[6] 叶梦竹.基于专利和论文互引的科学—技术关联研究 [D].武汉:华中师范大学,2017.
[7] SALTON G,BUCKLEY C. Term-weighting approaches in automatic text retrieval [J].Information Processing & Management,1988,24(5):513-523.
作者简介:薛淑晖(1997-),女,汉族,山东德州人,本科在读,研究方向:数据分析。
猜你喜欢
西部交通科技(2021年9期)2021-01-11
速读·下旬(2016年8期)2017-05-09
电子技术与软件工程(2016年24期)2017-02-23
大经贸(2016年9期)2016-11-16
中国市场(2016年33期)2016-10-18
科技视界(2016年20期)2016-09-29
哈尔滨理工大学学报(2016年2期)2016-09-12
企业导报(2016年9期)2016-05-26
计算机教育(2006年9期)2006-09-22
