
结合CNN和WiFi指纹库的室内定位算法①
2020-07-25 01:47曹建荣武欣莹吕俊杰杨红娟
计算机系统应用 2020年7期
曹建荣,张 旭,武欣莹,吕俊杰,杨红娟
1(山东建筑大学 信息与电气工程学院,济南 250101)
2(山东省智能建筑技术重点实验室,济南 250101)
1 引言
基于WiFi的指纹库室内定位技术是室内定位领域中的重点研究内容之一.指纹库室内定位技术主要包含确定性算法、概率型算法、人工神经网络3个主要研究方向.传统的基于指纹库的室内定位方法主要是指:离线阶段先使用滤波方法(高斯滤波等)再使用均值求出指纹库;在线阶段使用确定性算法(K近邻等)或概率型算法(贝叶斯概率等)进行指纹匹配.随着科技的不断发展,各行各业对室内定位精度的要求越来越高[1].传统的室内定位技术难以突破定位精度的瓶颈,而深度学习在图像和语音处理等方面的成熟应用使一些学者把深度学习引入基于WiFi的室内定位领域中,并做了较多的研究[2,3].Nowicki M等人利用深度神经网络(Deep Neural Network,DNN)有效降低本地化系统成本,证明了堆叠自动编码器可以有效地减少特征空间及实现稳定和精确的分类[4].Yu 等人利用深度卷积神经网络(Deep Convolutional Neural Network,DCNN)和频谱图自动学习无线信道指纹特征,从图像层次表明谱图DCNN模型能够用于指纹识别,其无线信道分类准确率为96.46%[5].Zhang等人首先采用4层深度神经网络,使用堆叠去噪自动编码器(Stacked Denoising Autoencoder,SDA)学习可靠特征,然后用隐马尔可夫模型(Hidden Markov Model,HMM)的精细定位器来平滑基于DNN的粗定位器的初始定位估计[6].众多研究成果表明,基于深度学习的室内定位算法在定位精度上有显著提高.
许多研究者都是通过使用复杂的网络结构和长时间调节网络参数寻求最优匹配结果.这无疑增加了前期离线阶段数据采集、训练调整的难度、在线阶段匹配的时间,同时对硬件也提出了更高要求[7].本文提出了一种基于较少数据,简单计算的匹配算法,即用CNN算法完成初步定位后,再结合传统指纹库进一步确定精度的算法.该方法整体使用的数据量和计算复杂度相对较小,时效性较好,且定位精度进一步提高.
2 算法的基本原理
2.1 算法基本流程
本文提出的算法包括离线指纹库建立和在线定位计算两个阶段.离线阶段时,首先从服务器的数据库中获取AP 接收到的全部信息,并预处理数据;然后基于预处理的RSSI数据训练CNN网络模型,得到符合定位精度的CNN定位模型;最后计算已处理的RSSI数据,完成指纹库的建立.在线阶段时,首先通过CNN定位模型初步预测待测点位置,得到最接近某个参考点的位置信息.然后结合传统指纹路径库中的数据,经过距离比例计算进一步缩小预测范围,最终得到较高精度的待测点坐标.
2.2 原始数据预处理
2.2.1 数据获取
为保证获取的数据更接近实际情况,本文的数据直接从定位系统中实时存储定位信息的数据库中获取.离线阶段,首先获取未处理的UDP报文,完成UDP报文的校验、长度验证和舍弃不完整数据;其次拆分标准UDP报文的关键字.关键字包含4个,分别为上传此UDP报文的AP 物理地址、时间戳、发送UDP报文内容的终端MAC地址及当前时刻的RSSI值;最后存入数据库中以备后用.
2.2.2 CNN模型数据处理
假设在被测区域中存在U个参考点和V个AP,则V个AP在第j个参考点处构成的一个RSSI值向量rj可表示为:
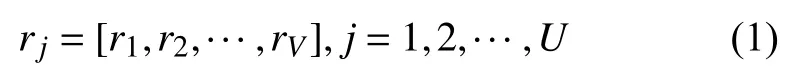
利用已处理的训练样本数据,把在每一个参考点处采集的M个RSSI值向量值整理为如下形式:

其中,j取值为[1,U],且j为整数.r(M,V)表示第V个AP在第j个参考点采集得到的第M个RSSI值.M值的选择取决于获取的数据量,且M值为正整数的平方.V的取值根据被测区域中实际使用AP的数量.
为简化后期计算,此处对上述Rj矩阵做形式和内容两方面变换.首先对Rj矩阵中每一个AP 获取得到的M个数据(即Rj矩阵中的每一列)均变形,变成的矩阵形式.如本文选择V值为3,即变换后会形成3个矩阵,分别为Aj,1、Bj,2、Cj,3√;然后添√加一个新的子矩阵Dj,4,使Rj矩阵大小变为矩阵Dj,4统一填写相同值,这样既可以保证数据形式一致,也不会对数据√内容造√成影响.新的Rj矩阵大小由原来的3×M变为即Rj矩阵的形式为:
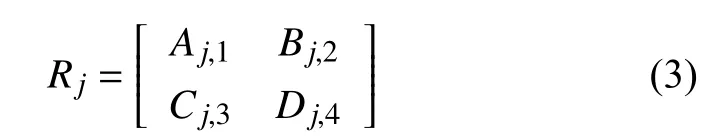
其中,矩阵Aj,1、Bj,2、Cj,3、Dj,4分别为以下形式:

经过上述变换,在某个参考点处来自3个AP的不同RSSI值就可以通过Rj矩阵表示在一张灰度图片上.在权衡数据量能够充分体现RSSI值动态变化和计算耗时两个问题的基础上,本文在训练CNN模型时,选择输入图片像素大小有16×16、28×28、36×36三种.
2.3 卷积神经网络训练
CNN模型一般由卷积层、池化层、全连接层3部分组成.不同的CNN模型通过对上述3部分的结构组合,参数修改等途径解决不同的问题.
从2.2节中可知,所用训练和测试的数据均为一张张二维的、代表着一个个具体待测点的指纹灰度图片,这与使用CNN算法进行字符识别类似,即本文待测点处的位置编号与字符识别中的数字类别类似.因此以字符识别的两层卷积(Convolution)、两层池化(Pooling)、随机失活、两层全连接层(Fully Connected)的CNN模型为基础,通过改变卷积层数量、卷积核大小、激活函数以选择性能最佳CNN模型参数,进一步保证在后续参与定位时,定位精度的提高.图1为所使用的CNN模型的基本结构.
以28×28的图像为例,在第一层卷积层中,首先使用32个5×5的卷积核,2×2的最大池化(步长=1)对图像操作,形成32个14×14的特征图;然后再使用64个5×5卷积核,2×2的最大池化(步长=1)操作,形成7×7×64的特征图;接着变换数据格式,生成1×(7×7×64)的数据用于分类.使用的ReLU、Elu[8]两种激活函数如下所示.
ReLU激活函数:
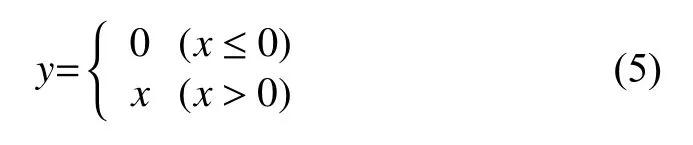
Elu激活函数:

ReLU激活函数是分段线性函数,属于单侧抑制函数.它使神经元具有了稀疏激活性;Elu激活函数存在负值,可以将激活单元的输出均值向0 推近,具有批量归一化的效果,而且减少了计算量.
为了防止训练过拟合和训练出的模型相对简洁,在全连接层后添加Dropout层,并取值为0.5.训练模型使用反向传播算法训练整个网络.训练CNN模型能够找到代表参考的类与位置信息的非线性映射关系[9],即当相邻迭代之间的损失函数下降到阈值以下或者满足迭代次数时,网络达到稳定则保存网络参数,停止训练;否则,从新的训练样本集中选择输入继续训练.通过多次训练后得出效果最好的CNN模型,形成基于卷积神经网络的指纹库模型.
2.4 指纹库数据处理
指纹库形成的基础是能够测出在定位点处具有代表性的RSSI值.现实中同一参考点处的RSSI值不同的原因主要有两个,分别为随时间、空间小范围内动态变化和信道传输错误出现偶然异常值.针对这两个问题,本文提出了基于限幅加权的滤波方法用于确定传统指纹库的指纹.对所有获取得到的数据,做以下3步处理:首先使用 2δ准则对处理的数据做限幅处理,去除因偶然因素引起的极端值;然后使用自然断点分类(Jenks Natural Breaks)[10],得到若干代表性分类和有界终端点集合;最后对这些数据加权,得到某AP在此点最具代表性的RSSI值.
具体步骤如下:
Step 1.计算高斯分布的标准差,筛选出符合 2δ原则的集合Ωn;
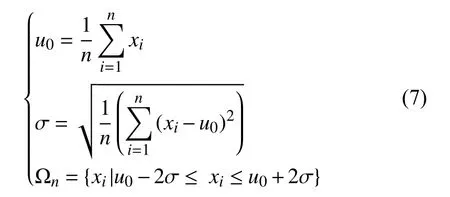
其中,i∈[1,n],且i为整数,xi为原始数据,n、u0、σ分别为原始数据的总量、平均值、标准差.
Step 2.自然断点分类法与K 均值聚类在一维数据聚类分析中意义是一样的.从数据集本身出发,按照类内方差最小,类间方差最大的原则,对数据迭代和移动聚类.其中最主要的是确定聚类数量k值和使用方差拟合优度(Goodness of Variance Fit,GVF)算法判断分类效果好坏.
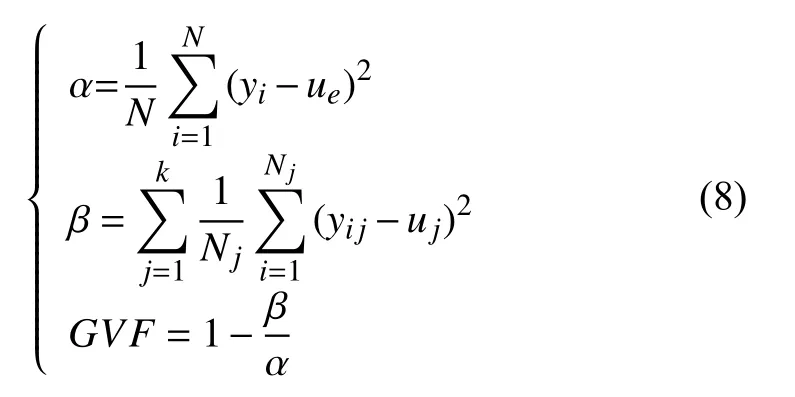
其中,i∈[1,N],j∈[1,k],i、j∈Z;yi、N、ue、α分别表示集合 Ωn中的第i个数据、数据数量、平均值、方差;yij、Nj、uj、β表示把集合 Ωn分成K类后,第j类中的第i个数据、第j类中数据的数量、第j类中数据的平均值、k类方差的和.
GVF 用于判定不同分类的分类效果好坏.在一定范围内,GVF值越大,其分类效果越好,分类结果越具有代表性.一般经验值指出,GVF>0.7 就可以接受分类结果.
通过Step 2,把集合 Ωn划分成了k类小集合{Θ1,Θ2,···,Θn},以及(k+1)个各类的边界点组成的集合{t1,t2,···,tk+1}.
Step 3.对计算出的{Θ1,Θ2,···,Θn}中的各类数据做加权处理,得到此参考点处某一个AP的最终RSSI值.

其中,j∈[1,k],j∈Z.R(u,v)为第U考点的第V个AP最终值,wj为第j据的权值,函数F()为概率分布函数,用于计算各类出现的概率.
通过以上3个步骤计算每一个参考点所有AP值序列,最终得到指纹库 Ψ.

为防止因信道重叠导致RSSI值在传输过程中出现误差和保证RSSI值动态变化的完整性[11],V值一般取为3.
限幅加权的滤波方法最终目的是在保留了指纹自身的特征后,最大限度地去除异常数据.根据实际处理大量数据后,无效数据约占中数据的5%,使用 2δ准则,能够直接去除来自异常情况、小概率出现的无效数据.通过使用GVF算法和类内数据加权计算出最具代表性的指纹点的RSSI值.以上3个步骤,能够从参与定位的开始就保证了数据的有效性.通过使用限幅加权的滤波方法能够保证参与整体定位的数据的有效性和提高最终的定位精度,能够有效减少或避免在线定位时结果畸变.
2.5 在线定位
在线阶段定位共有4个步骤,主要完成CNN模型的结果与传统指纹库指纹的结合计算.4个步骤如下:
Step 1.预处理获取的实时数据,然后使用CNN模型预测得到位置序号对应坐标点C(Xc,Yc).3个AP在某一时刻获取的数据经过2.4节中的Step1 初步去除异常数据后,得到包含实时数据矩阵H.
Step 2.实时矩阵H中的每一组数据均与指纹库Ψ中的所有指纹做欧式距离计算,以最小欧式距离值对应的指纹为此组数据的接近指纹,最终形成接近指纹库 Ψ′.
Step 3.统计出接近指纹库 Ψ′同接近指纹数量排三位的接近指纹,找到对应的坐标点集合 Γ((Xa,Ya)、(Xb,Yb)、(Xd,Yd)).计算出其各坐标点到C(Xc,Yc)的距离la、lb、ld及距离之和ls.
Step 4.计算出待测点的最终预测位置(Xf,Yf),计算公式如下:
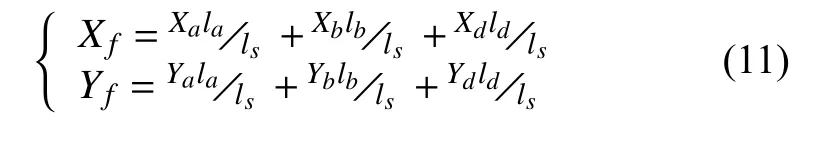
3 实验结果分析
3.1 实验设置
根据被测面积大小和AP的个数合理划分参考点的位置.本实验选取面积为14.4 m×8.6 m的实验教室,以28个2 m×2 m的网格顶点,作为训练CNN模型的指纹库参考点;以112个1 m×1 m的网格顶点作为传统指纹库参考点.被测区域示意图如图2(小圆点、大圆点分别为1 m×1 m和2 m×2 m的网格参考点)所示.在选取参考点时,CNN模型指纹库的参考点位置和传统指纹库的参考点位置应完全不重合.
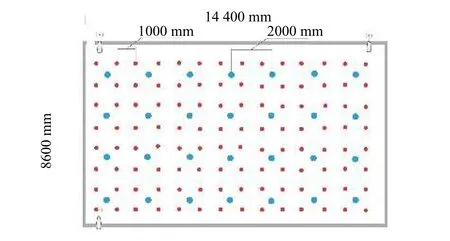
图2 被测区域示意图
移动终端信号的接收能力、所在高度、移动终端和AP 朝向[12]等因素均会引起RSSI值得变化.因此在3个AP 收集数据时,使用5种不同型号的移动终端,分别距地面垂直距离为1 m、1.5 m、2 m的高度以及4个朝向发射数据,尽可能保证每一个参考点数据的完整性.
本文设定CNN模型指纹库参考点的个数为28,所以用于训练得数据集也应当包括28类.每一个参考点训练集和测试集图片数量分别为28×300、28×100 张,且训练集和测试集的数据均来源于对28个参考点的均匀采样.每张图片中包含3个AP在此参考点处采集的共3×14×14 (以28×28的图片输入为例)个RSSI值,使用Python 等软件搭建仿真实验平台.
3.2 实验结果及分析
通过1.2.2节的数据预处理过程,可以获得CNN模型训练使用16×16、28×28、36×36三种格式的图片.这3种输入图片的本质区别在于包含RSSI值的多少.图片越大,其相应的训练时间就会越长.图3左侧为用于CNN模型训练的,格式大小28×28的某参考点预处理的图片,右侧是其局部放大图的截图.图3左侧图像数据的4部分内容分别对应3个AP采集的此参考点的RSSI值矩阵和填补的空白值矩阵;图3右侧图像为左侧图中某一个AP采集的数据放大图,可以看出,此AP采集的某参考点的RSSI值是动态变化的.图4为指纹库中的某点数据预处理的过程结果图.图4中五角形点、三角形点、小圆点分别代表3个AP在被第一步限幅之后的数据,大圆点代表第二步分类后的各类边界点,各AP在此参考点处的最终RSSI值如图4中各类线所示.

图3 某参考点采集数据成像图及局部图
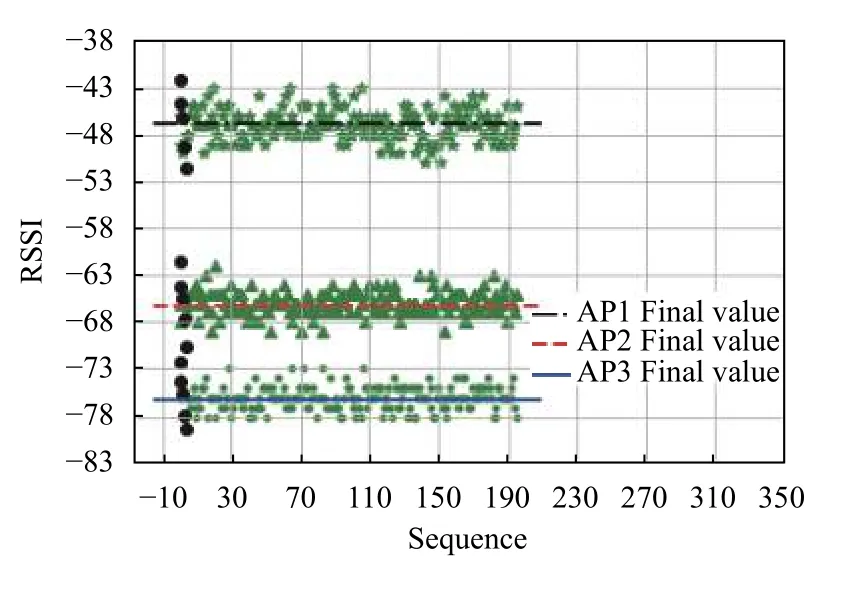
图4 某参考点指纹库数据处理过程图
根据CNN模型设置,采用不同卷积核大小、激活函数等得到训练的时间、准确率如表1所示,网络损失收敛图如图5所示.
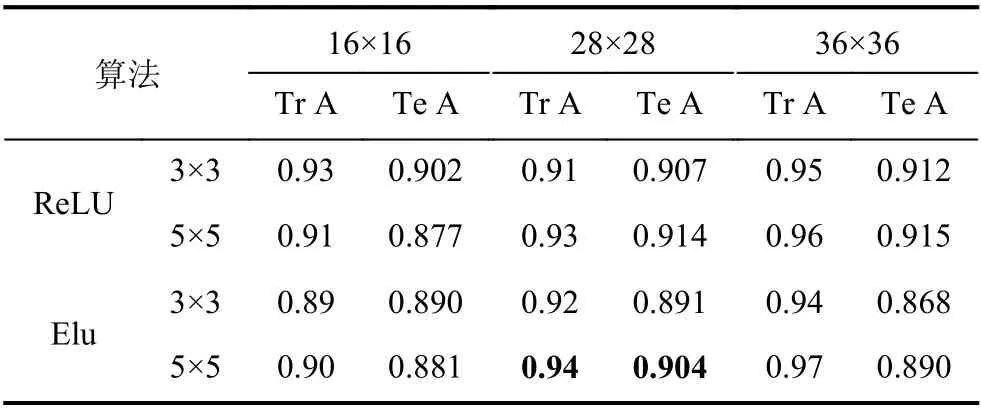
表1 不同参数性能比较
通过表1的数据可以看出,当输入数据包含信息增加,其训练准确率越高.但是测试集并未随之增加而显著提高;对于同一批数据,准确率会随着卷积核模板的规格增加也呈现上升的趋势.
图5是以28×28的图像、5×5卷积模板为例,分别在ReLU、Elu 两个激活函数下的网络损失收敛图.结合表1的数据可以看出,在相同的数据基础上,Elu 比ReLU少约200轮训练达到最佳收敛值,而且训练效果相当.
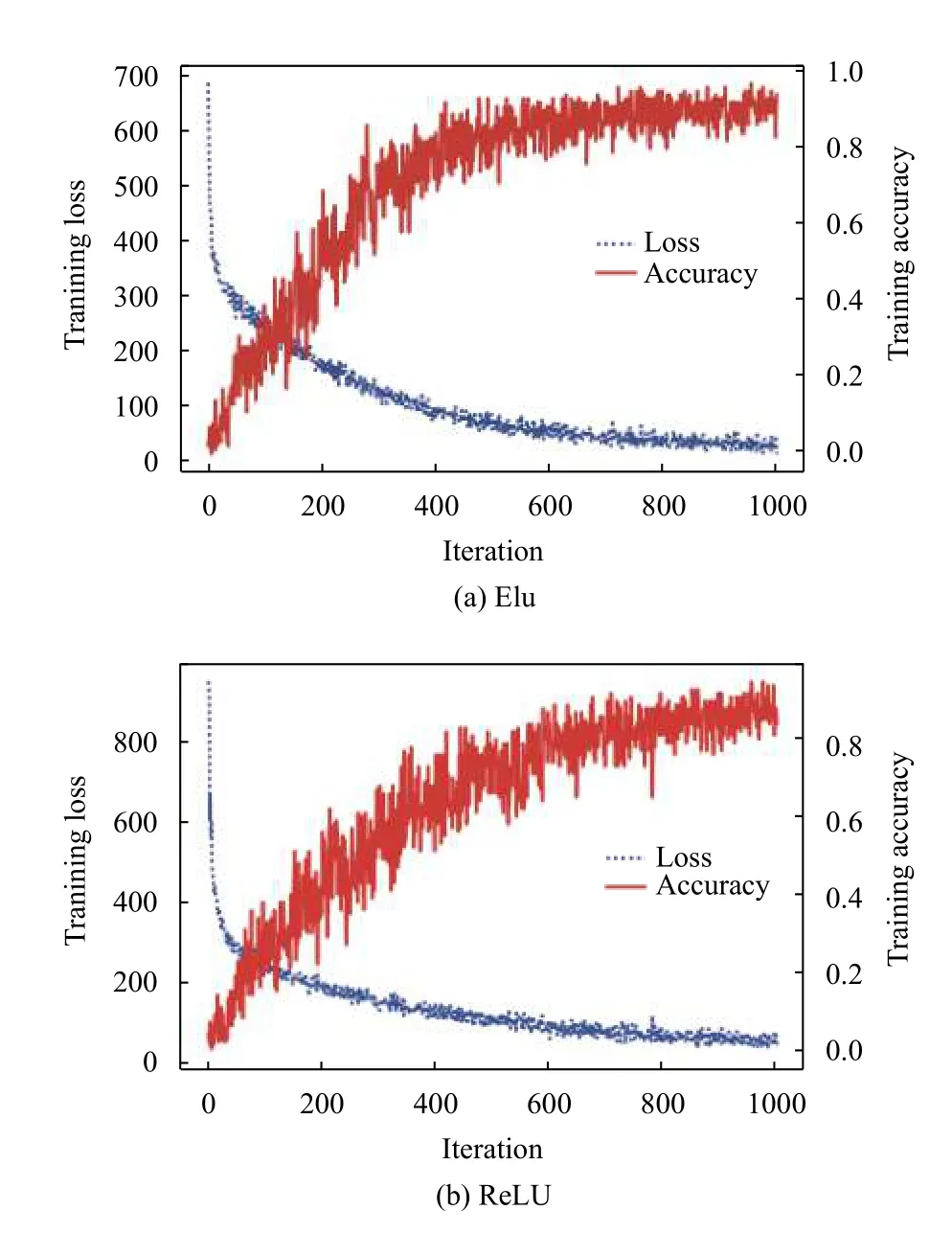
图5 ReLU、Elu激活函数下网络收敛图
考虑到在实际应用中采集的数据数量和匹配时间周期两个主要因素,本文最终选取Elu激活函数、28×28的输入数据、5×5的卷积模板的CNN模型,并在此模型下保存最佳训练参数.
本文通过实验得到的定位误差累计分布图如图6所示,其中横坐标表示定位误差值,纵坐标表示定位误差的累积比例.图6中CNN1-JK曲线为本文算法结果;CNN1 曲线为只使用本文算法中的CNN模型得到的结果;CNN2模曲线是以本文CNN模型为基础,提高了分类精度(112类)的算法结果;G-K曲线为使用高斯滤波结合K近邻算法得到的结果.
从图6中可以看出,从CNN1和CNN2模型的结果中可以看出,增加3倍分类精度后,定位误差并没有成比例显著降低,但是CNN2模型前期训练的训练耗时却是CNN1模型的两倍到三倍;在单纯考虑累积误差时,本文算法结果与CNN2模型结果相比,累积误差约在0.75 m 之后本文算法体现出定位精度优势;本文算法结果与传统的G-K算法结果相比,明显的提高了定位精度.通过实验结果对比发现,本文的算法误差有近50%在0.5-1 m 内,约90%均小于1.5 m,相比于同类型单纯的卷积神经网络和传统算法,准确度比较高,误差稳定性较好.
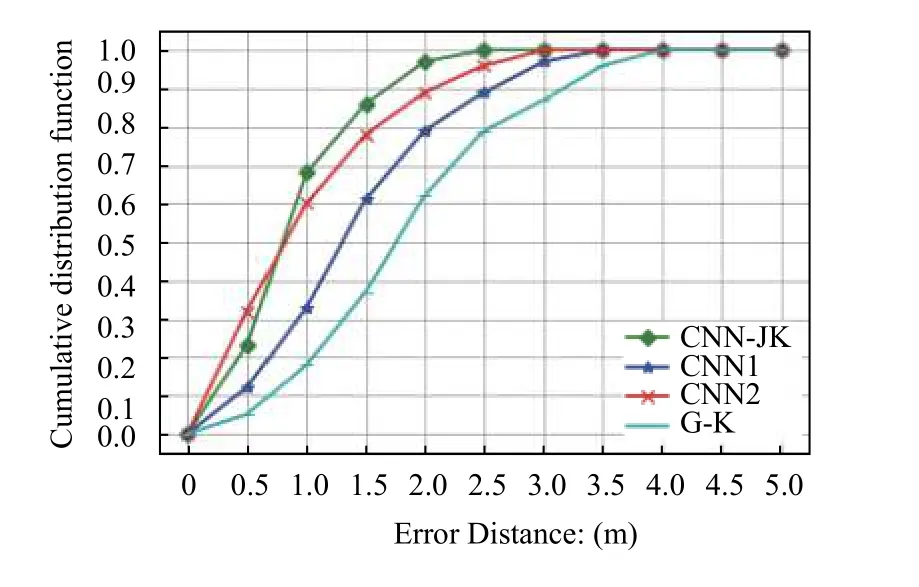
图6 定位误差累计分布函数图
图7为测试点测试的实际结果.区域I-IV分别是待测点在大圆点连线中心点、与大小圆点重合、小圆点连线中心点、一般位置的预测结果(三角形点为实际位置、五角形点为预测位置).实验结果大部分均在0.5-1.5 m之间,实际结果与图6的误差累积结果基本相同,精度在可控范围内.

图7 典型实际定位数据结果示意图
本文算法利用CNN模型能够较好地学习RSSI的波动特性的特点,首先使用CNN模型预测粗略位置,再配合传统指纹库指纹简单计算确定最终定位.选择以字符识别的CNN模型为基础,更符合指纹定位的数据特点;使用限幅加权的滤波方法,从数据参与定位的源头上减少了因异常值引起的定位即便问题的出现.整体上一方面可以提高定位范围准确性,防止发生RSSI值局部畸变而导致整体定位错误;另一方面整体使用数据量较少,定位速度较快.
4 结论
将深度学习应用在室内定位领域中提高定位精度有着重要的意义.本文提出一种卷积神经网络结合传统指纹库的室内定位算法.首先利用卷积神经网络模型,根据实时输入信号强度指示RSSI数据预判出待测点的初步位置,再结合传统指纹库中的指纹点,确定出精确度更高的最终预测位置.实验结果表明,在时效性达到要求的前提下,误差在1 m 以内的定位精度约为65%,误差在1.5 m 以内的定位精度约为85%,定位精度高于传统的基于指纹库的定位方法,且误差较为稳定.
猜你喜欢
导航定位学报(2022年5期)2022-10-13
导航定位学报(2022年5期)2022-10-13
导航定位学报(2021年4期)2021-08-29
小天使·一年级语数英综合(2020年10期)2020-12-16
好日子(下旬)(2020年6期)2020-08-04
计算机技术与发展(2019年8期)2019-08-22
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
儿童时代·快乐苗苗(2016年2期)2016-10-22
青少年科技博览(中学版)(2015年7期)2015-08-12
