
山东省冬小麦单产监测与预报方法研究
2020-07-24 05:08朱秀芳李石波侯陈瑶
农业机械学报 2020年7期
郭 锐 朱秀芳 李石波 侯陈瑶
(1.北京师范大学地表过程与资源生态国家重点实验室, 北京 100875;2.北京师范大学地理科学学部遥感科学与工程研究院, 北京 100875;3.中国地质大学土地科学技术学院, 北京 100083)
0 引言
遥感农业监测具有观测范围大、时间分辨率高、数据客观可靠的优点,比工作量大、成本高、效率低的传统估产方式节省了时间和成本,为农作物估产提供了科学有效的手段[1-2]。
利用遥感进行作物产量估算的方法主要包括:遥感统计估产模型、干物质-产量模型和作物模型模拟。遥感统计估产模型通过建立遥感变量与产量之间的关系表达式来进行产量估算[3-5];干物质-产量模型先基于遥感数据估算作物的地上生物量,再通过收获指数转换成作物的经济产量[6-7];遥感作物模型模拟是将遥感数据作为模型校正的数据源之一,对作物模型进行参数本地化后,在气象、土壤、作物种植信息等数据的驱动下进行作物生长模拟和产量的估算[8-10]。3种方法中第1种方法最简单,对数据的要求最低,后两种方法机理性更强,要求大量输入数据,操作更复杂。
在遥感统计估产模型中,使用最多的输入变量是植被指数。植被指数可以反映植被的生产力和健康状况,研究表明,植被指数与作物产量之间高度相关[11-12]。以往研究中用到的植被指数包括归一化植被指数(NDVI)[13-15]、增强型植被指数(EVI)[16]、叶面积指数(LAI)[17]、垂直植被指数(PVI)[18]、植被条件指数(VCI)[19]、光合有效辐射(APAR)[20]等。尽管利用植被构建遥感估产模型取得了成功,但也存在一些问题,比如NDVI在植被高覆盖区容易饱和,对灾害(如干旱、病虫害)的响应滞后,不能很好地反映农业管理和科技进步带来的产量增加趋势[21]。
另外,随着遥感数据产品的进一步丰富,发布了大量环境变量遥感产品(如温度、土壤湿度、降水量和蒸散发量),有研究开始综合使用环境变量和植被指数遥感产品建立统计估产模型。例如, PRASAD等[22]利用NDVI、VCI和条件温度指数(TCI)等遥感数据对植被的健康状况和土壤生产力进行评估,并构建了作物估产模型。DABROWSKA-ZIELINSKA等[23]利用早春和初夏两个时期的VCI和TCI进行波兰作物生长状况的评估与作物产量的估计。上述研究都表明,加入环境变量对作物估产具有积极作用。
本文以山东省冬小麦为例,综合使用技术产量、植被指数和环境变量构建统计估产模型,同时在监测模式和预报模式下进行模型的应用和验证,以期为冬小麦实时产量预报提供方法参考。
1 研究区及数据获取
1.1 研究区概况
研究区域为山东省(图1),属暖温带季风气候,气候条件稳定,冬季寒冷干燥,夏季高温多雨,光照资源丰富,适合农业种植,主要的种植作物有冬小麦、棉花、玉米。山东省的小麦种植面积常年保持在20万hm2,小麦总产量约占全国小麦产量的18%,是我国仅次于河南省的小麦生产省。干旱是影响山东省冬小麦产量的一大因素,但随着种植方法与灌溉技术的不断进步,山东省冬小麦抵抗干旱、病虫害等灾害的能力逐渐增强,整体小麦产量呈现稳中有升的趋势。
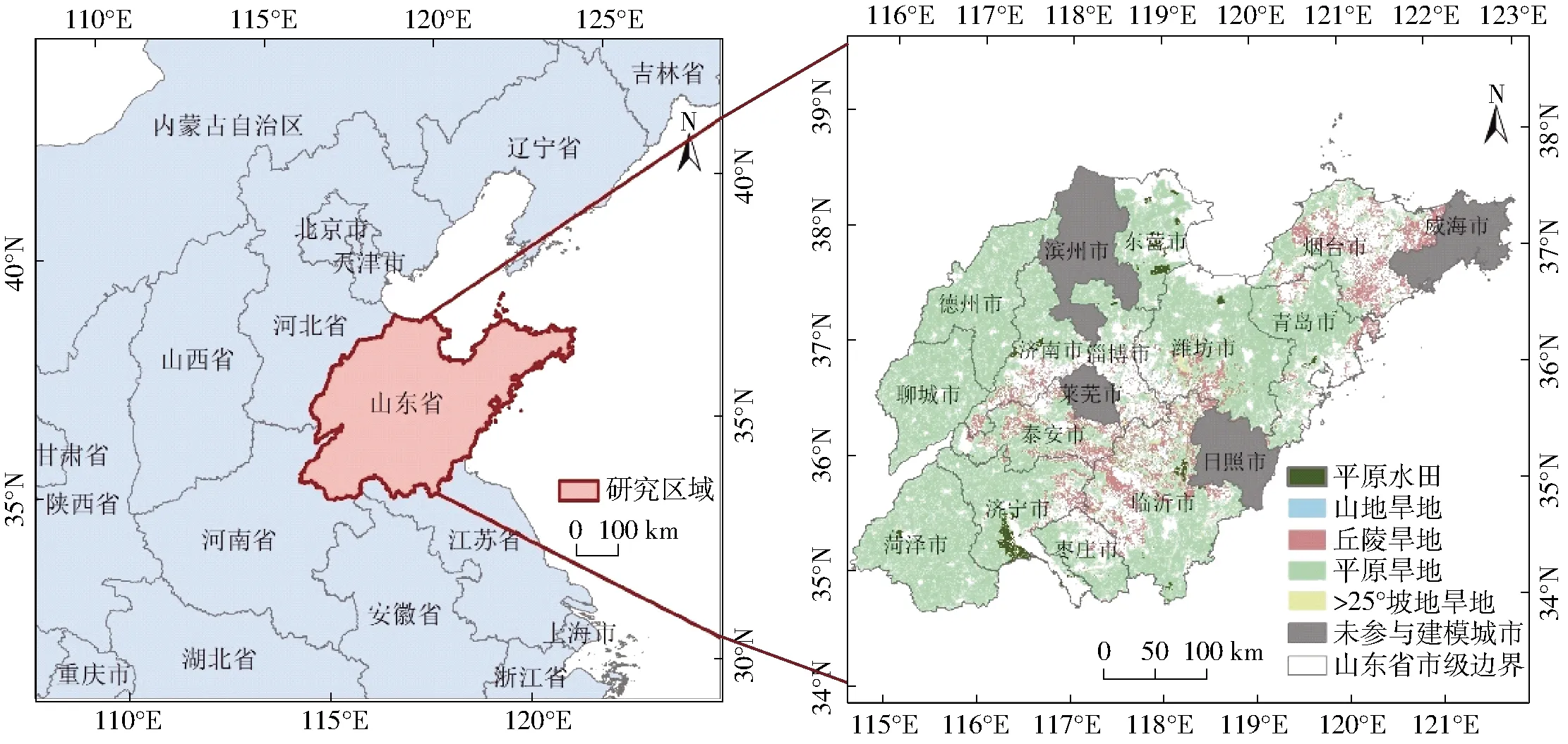
图1 研究区域图Fig.1 Study area map
1.2 数据获取与预处理
本文使用的遥感数据为500 m分辨率地表反射率(Surface reflectance)8 d合成产品MOD09A1和500 m分辨率全球陆地蒸发蒸腾(Global terrestrial evapotranspiration)8 d合成产品MOD16A2,均下载自LAADS DAAC(https:∥ladsweb.modaps.eosdis.nasa.gov/),取水平第27景、垂直第5景数据,位于102.2°~128.8°E、29.3°~40.0°N之间,得到包括河南、山东等省份在内的影像。数据时间为2007—2017年,时间间隔为8 d/景,共计308幅影像。
MOD09A1产品提供了MODIS传感器500 m分辨率1~7波段表面反射率8 d合成的数据产品,投影为正弦曲线投影,数据集中的每个像素包含了8 d内尽可能准确的观测值。由于MODIS数据产品中未包含500 m分辨率的8 d合成EVI数据,为了统一遥感数据的时间与空间分辨率,本文基于MOD09A1数据计算得到研究中所使用的500 m分辨率的8 d合成增强型植被指数(EVI)数据。
MOD16A2产品数据集中包含了实际蒸腾和潜在蒸腾,ET和PET表示500 m分辨率8 d内单位面积通过蒸腾散失水分(0.012 5 kg/(m2·d))的总和。其中ET表示不同植被覆盖度条件下植被区域和非植被区域的加权平均蒸腾量;PET表示在假设水分供应不受限制的情况下,某一固定下垫面可能达到的最大蒸腾量。
使用的非遥感数据包括中国多时期土地利用土地覆被遥感监测数据集(CNLUCC)[24]、山东省矢量边界数据、山东省作物物候观测数据和山东省历史产量统计数据等。使用的耕地掩膜数据由中国多时期土地利用土地覆被遥感监测数据集(CNLUCC)中一级类型为耕地的像元(一级类型编号为1)提取并二值化后获得。数据的预处理主要包括遥感影像的投影转换、数据裁剪、像元筛选等。
2 研究方案与方法
2.1 研究方案
本文的研究方案包括:①计算增强型植被指数(EVI)和作物水分胁迫指数(CWSI)。利用山东省2007—2017年冬小麦生育期内的MODIS传感器地表反射率产品(MOD09A1)计算各县区平均累计增强型植被指数(EVI), 利用同时期蒸腾散发产品(MOD16A2)计算各县区平均累计水分胁迫指数(CWSI)。②确定技术产量因子。技术产量反映了该地区的平均农业生产技术水平以及抗灾能力。结合山东省2007—2017年县级历史产量统计数据,利用时间序列趋势方法计算技术产量。③建立估产模型。使用最小二乘线性回归法分别进行山东省市级尺度和省级尺度的冬小麦产量预测模型的构建。④模型的应用及精度验证。分别在监测模式和预报模式下进行估产模型的应用及精度验证。技术路线见图2。
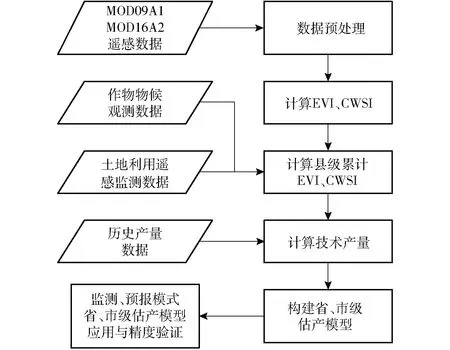
图2 技术路线图Fig.2 Technical flowchart
2.2 平均累计指数计算
2.2.1平均作物水分胁迫指数(CWSI)
作物水分胁迫指数(CWSI)由500 m分辨率全球陆地蒸发蒸腾8 d合成产品MOD16A2计算得到。作物水分胁迫指数可以反映植被不同生长状况下蒸腾量的变化和生长环境的干旱程度[25],计算式为
(1)
式中CWSI——作物水分胁迫指数
ET——实际蒸腾量
PET——潜在蒸腾量
县级平均CWSI具体计算过程如下:首先,利用耕地掩膜数据对CWSI数据进行掩膜处理,得到山东省耕地范围内的CWSI数据。之后,利用山东省县级行政边界矢量数据,分别提取每个县区对应的共计11年、每年14期的所有耕地像元的CWSI平均值,将求得的平均值作为该县区该年该期的胁迫指数。最后,统计县级生育期内的累计平均胁迫指数,对缺失3期及3期以下的数据(缺失期数不超过总期数的20%)使用该县区其他年份的多年平均值作为替代,构成完整的生育期胁迫指数数据;对于缺失3期及3期以上的数据(缺失期数超过总期数的20%),则判定该地区该年的数据缺失过多,舍弃该年的数据,不参与后续的估产建模。最后求得共135个县区、每个县区共11年(除数据缺失年份)的生育期内的累计平均胁迫指数。
2.2.2平均增强型植被指数(EVI)
之前有研究对比了NDVI、LAI、EVI、GPP(总初级生产力)和LST(地表温度)等变量对作物产量估计的影响,指出EVI在多种作物估产的应用中效果最优[11]。因此,本研究中利用500 m分辨率表面反射率8 d合成的数据产品(MOD09A1)进行了EVI的计算[26],计算式为
(2)
式中EVI——增强型植被指数
ρRED——红波段反射率
G——增益参数,取2.5
ρNIR——近红外波段反射率
ρBLUE——蓝波段反射率
L——增益参数,取1
C1——大气修正红光校正参数,取6.0
C2——大气修正蓝光校正参数,取7.5
然后使用TIMESAT软件对EVI时间序列进行平滑,去除图像噪声[27-28],计算县级平均EVI和生育期内的累计平均EVI。其计算过程同2.2.1节中县级累计平均CWSI的计算过程。
2.3 技术产量计算
技术产量代表研究区域长期的社会生产力发展水平所决定的产量分量。本文使用时间序列趋势分析的算法求取技术产量[29]。该方法将整个时间序列内的历史产量,在某个与滑动步长时间内进行线性拟合,形成一条线性函数的直线。随着滑动直线不断向后移动,不断生成新的拟合直线。在直线滑动完成后,各时间点上均对应有大于或等于1个直线的模拟值,再对各时间点上的模拟值求平均值,即得到技术产量。这种模拟方法既不损失样本序列的年数,也避免了主观假定长时间序列产量变化的曲线类型,是一种较为实用的趋势模拟方法。
2.4 估产模型构建
以2017年之前县级数据作为建模样本输入,基于最小二乘法的多元线性回归方法分别建立了省级和市级估产模型。省级尺度上的估产可以反映山东省整体的农作物生产力,对于大范围监测冬小麦长势与实时估算小麦产量有一定的理论意义。市级估产可以反映不同市域范围内由于农作物生产技术、气候和土壤条件所导致的产量差异,对于各市政府针对性地进行科学生产管理与农业政策制定有积极的作用。
对于山东省市级冬小麦单产估产模型,去除了样本点低于50个的城市(威海市、日照市、莱芜市)以及遥感数据有严重缺失的城市(滨州市),最终保留了共13个城市的样本数据,完成山东省市级小麦单产估产建模,得到13个市级线性回归方程。
对于山东省省级冬小麦单产估产模型,首先对全省所有县区的数据样本进行筛选,去除数据缺失和存在异常值的样本点,最终保留736个样本,完成山东省省级小麦单产估产建模,得到1个省级线性回归方程。
2.5 模型应用与精度验证
以2017年山东省小麦产量数据为验证样本,采用监测和预报两种模式进行估产模型的应用与验证。监测模式面向生长季结束后的最终产量估算,需在小麦生长季结束后获得全生长季完整的遥感数据后才能进行;而预报模式是在小麦生长季节开始后进行实时的产量预测。
对于监测模式,首先对各市和全省范围内所包含的县所对应的2017年县级累计平均EVI、县级累计平均CWSI和技术产量数据分别求取市级和省级的平均值,以2017年的生长季内(第65天到第169天)市级累计平均EVI、市级累计平均CWSI和估算的2017年的各市的技术产量数据为输入,分别代入对应的市级估产模型中进行各市的冬小麦单产估算,将省级累计平均EVI、累计平均CWSI和技术产量代入省级估产模型进行全省的冬小麦的单产估算。
预报模式在小麦生长季节开始时就进行预测。然而在生长季初期,模型所需的整个生长季的累计平均EVI和CWSI是未知的。为此,对于未知时间段的EVI和CWSI采用多年平均值进行代替。例如,生长季一开始(第65天)就进行产量监测时,第65天的EVI和CWSI用2017年的实测数据,而后的第73天到第165天用历史平均值替代,最终得到完整的生长季的累计平均EVI和CWSI。随着季节的推进,当前生长季越来越多的观测值被纳入模型,预报模型的结果会越来越接近监测模式的结果。本文在生长季中选取3个时间点进行预报模式下的模型应用,分别是返青期结束(第89天)、拔节期结束(第121天)和乳熟期结束(第145天)时。预报模式下市级与省级模型的应用方法同监测模式所述过程。
本文中估产精度评价的指标包括绝对误差(Absolute error,AE)和绝对相对精度(Absolute relative accuracy,ARA),计算式为
YAE=|Ye-Ya|
(3)
(4)
式中Ye——山东省2017年冬小麦模型估计产量
Ya——山东省2017年冬小麦统计数据的真实产量
3 结果与分析
3.1 自变量与小麦产量的相关性分析
对2007—2017年县级小麦产量数据分别与其对应县区生育期内的技术产量、累计平均EVI、累计平均CWSI进行相关性分析,结果如表1所示。
各市小麦产量和技术产量因子之间的相关性最高,相关系数均不小于0.974,显著性概率均高于0.01水平;其次与产量相关度较高的是累计平均EVI,相关系数均在0.522~0.867之间,也在0.01水平显著;累计平均CWSI与产量的相关系数在0.370~0.650之间,大部分通过0.01水平的显著性检验。
对全省小麦产量数据与全省范围内的生育期内的各指数也进行相关性分析。其中与产量相关性最高的同样是技术产量,相关系数高达0.993,在0.01水平显著;累计平均EVI与产量的相关性达到了0.780,在0.01水平显著;累计平均CWSI与产量的相关性相对较低,为0.388,在0.05水平显著。
由表1可以看出,技术产量、累计平均EVI、累计平均CWSI与实际产量都有良好的相关性,均可作为对冬小麦单产估计进行建模的因子。
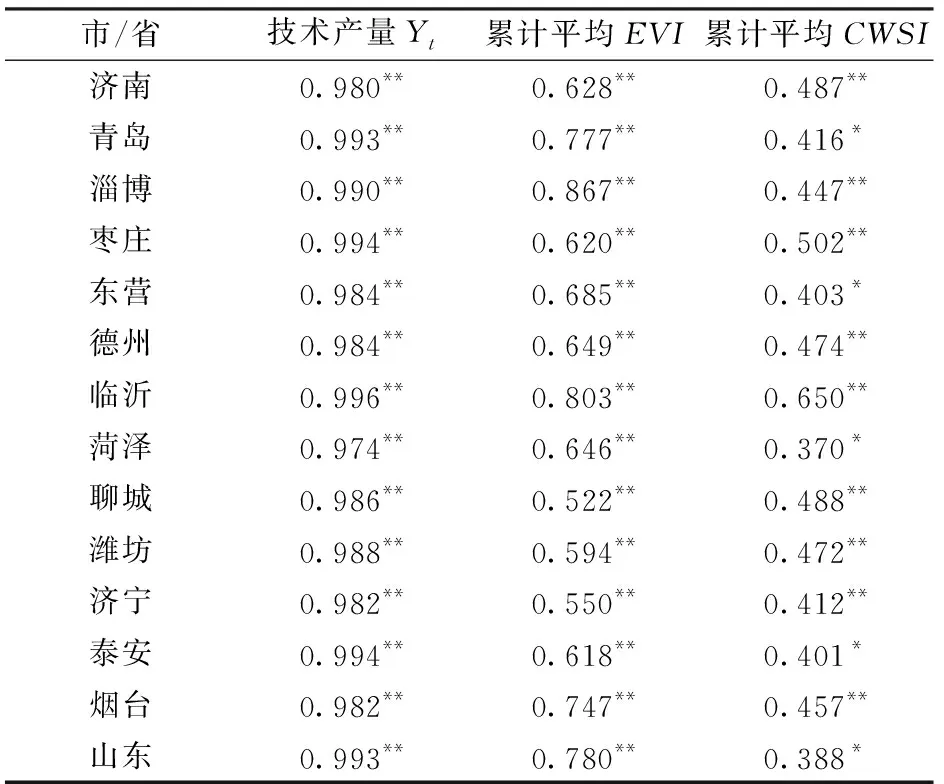
表1 小麦产量与技术产量、累计平均EVI、累计平均CWSI的相关系数Tab.1 Correlation coefficients between wheat yield and trend yield, cumulative EVI and cumulative CWSI
3.2 小麦估产模型
以各县技术产量Yt、累计平均EVI和累计平均CWSI为自变量,以相应县的实际历史产量为因变量,基于最小二乘多元线性回归法建立了2007—2017年山东省13个市和1个全省的产量估算模型,如表2所示。估产模型的R2均不小于0.962并且在0.01水平显著。其中,泰安市小麦单产估算模型R2最高(0.990),济南市小麦单产估算模型R2最低(0.962),全省小麦产量估算模型R2为0.985。

表2 冬小麦估产模型Tab.2 Winter wheat yield estimation model
3.3 小麦估产模型的应用与评价
对山东省各个城市和全省的产量估算模型分别在监测模式和预测模式下进行应用,单产估算结果如表3所示,精度验证结果如表4所示。

表3 2017年山东省小麦产量监测和预报结果Tab.3 Monitoring and forecasting results of wheat yield of Shandong Province in 2017 kg/hm2
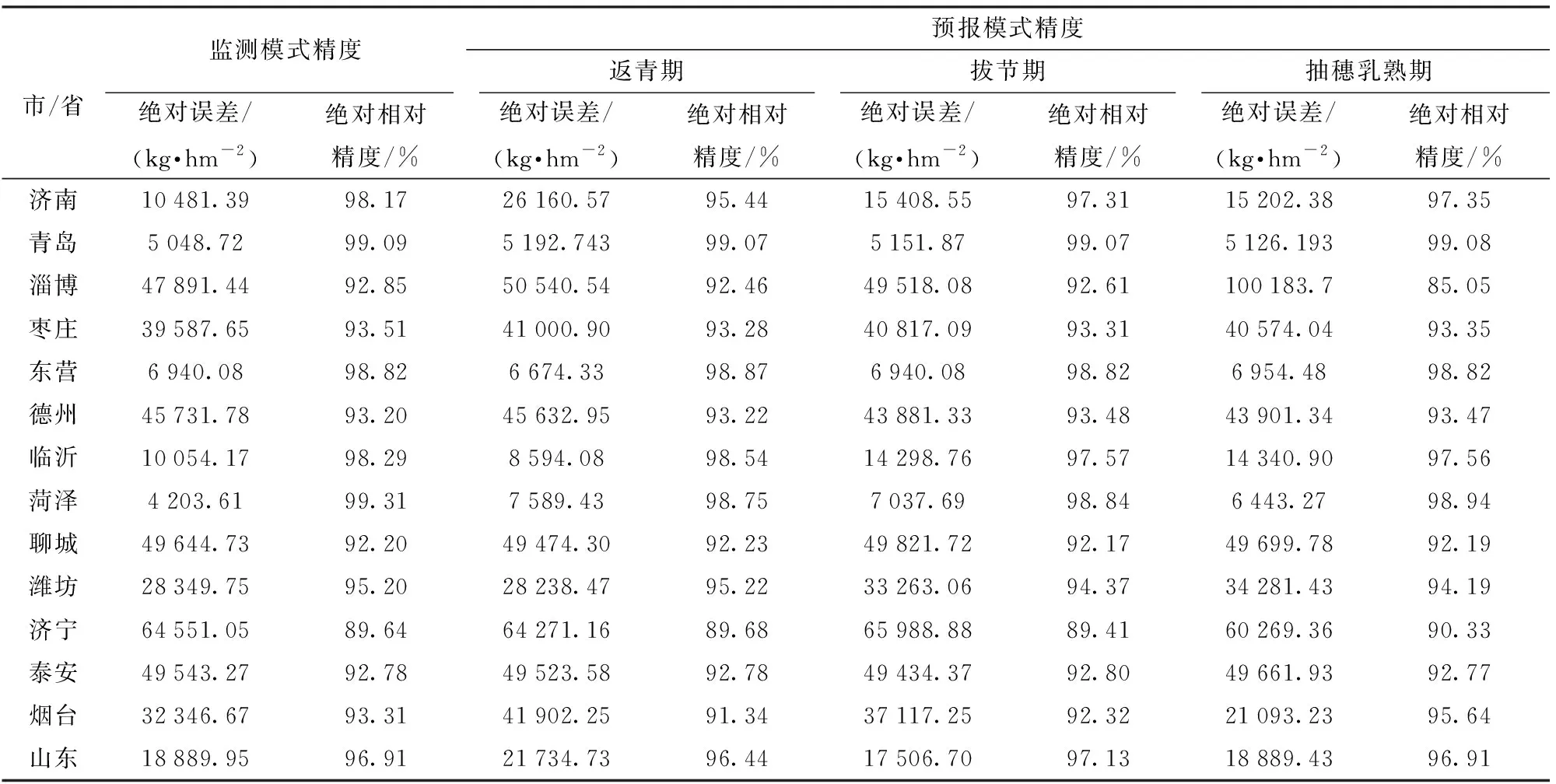
表4 模型精度验证结果Tab.4 Model accuracy verification results
监测模式下精度验证结果表明,所构建的模型在市级和省级作物单产估测中都很可靠。全省范围内的估产精度为96.91%。各市的估测精度均不小于89.64%,其中模型精度最高为菏泽市,高达99.31%,估产精度最低为济宁市,为89.64%。
预报模式下的精度验证结果表明,在大多数地区,随着生育期内时间的推进,现势遥感数据不断加入模型,预报模式下估产模型的精度逐步提高,越来越逼近监测模式下模型的估产结果。全省3个时间点的预报精度分别达到了96.44%、97.13%、96.91%。各市中,青岛市预报精度最高,3个时间点的预报精度均达到了99%以上。
4 讨论
针对小麦的生长特点和研究区域特点,结合历史产量数据和遥感数据,对山东省小麦产量进行建模,并进行了监测模式和预报模式下的应用和验证。该模型在农业遥感产量估算中有一定的参考价值。分析本文对产量预测建模的方法和结果,可能会对建模结果产生影响的因素有:
(1)采用累计平均EVI和累计平均水分胁迫指数反映环境因素对冬小麦产量的影响,但在实际生产过程中,小麦产量会受到多种环境因素的影响,以及各种人为因素造成的产量波动。而这部分影响因素在本文的模型中难以用遥感数据表达和预测。
(2)使用特定的作物掩膜可以改善作物估产模型的精度[30],但由于特定作物的空间分布每年均变化,获取时间序列内每年特定作物的掩膜数据工作量大,且存在分类误差,每年的误差和分布也会不同,作物分布图的误差也会传递到后续的模型中。耕地掩膜相对于冬小麦掩膜更容易获取。此外,有研究指出使用耕地掩膜替代特定作物的掩膜是可行的[1]。综上考虑,本文对冬小麦像元筛选时,使用耕地掩膜,可能导致作物的特异性被忽略,参与运算的像元中混杂了其他作物或裸地的信息,从而影响估产模型的精度。
(3)本文技术产量是对估产模型精度具有重要影响的变量。在估算技术产量的过程中,所使用的时间序列长度和计算方法是影响技术产量估算精度的两个重要因素。只使用了近10年的冬小麦历史产量数据进行技术产量的估算。长时间序列的历史产量有助于提高技术产量的精度,但在县、村级精细规模上,长时间序列的历史产量数据获取困难。
(4)由于云雨等不良天气的影响,部分地区的数据存在缺失值。在计算县级平均EVI和CWSI的过程中,仅选取了在同期数据中EVI、CWSI均无缺失情况的像元参与平均计算,减少了参与建模的像元数量。若采取插值方法对缺失像元进行插补,可以得到全覆盖的数据集,同时插值的误差也会传递到估产模型中,通过插值得到全覆盖的数据是否可以提高建模精度还需进一步讨论。
(5)仅针对山东省范围内数据进行模型的构建与应用,在预报模式中选取了山东省冬小麦生育期的3个时间节点进行产量预报,并认为在全省范围内冬小麦的生育期节点均一致。若有更详细的,如分县的生育期数据,则可按照各县具体的生育期时间阶段进行模型输入变量的计算。
5 结论
(1)技术产量、EVI和CWSI与冬小麦产量具有显著相关性,可以作为冬小麦估产建模的因子。结果表明,技术产量与冬小麦实际产量的相关性最高,在估产模型中为主要影响因子,体现了研究区域的客观种植条件和农作物生产水平;累计平均EVI与冬小麦实际产量的相关性次之,主要表现了作物的实际生长状况;累计平均CWSI与冬小麦实际产量的相关性相对最低,主要体现了研究区域的气候条件、土壤水分和干旱灾害等情况。
(2)基于技术产量、EVI和CWSI建立的省级和市级估产模型的R2均不小于0.962。监测模式的验证结果表明,本研究所构建的模型对市级和省级作物单产的估测都有较高的适用性,采用技术产量与遥感数据结合的模式可以实现高精度估产;预报模式验证结果表明,采用现势数据和历史数据结合的方式可实现冬小麦实时产量预报。本研究可以为作物生长状况监测提供参考依据。
猜你喜欢
今日农业(2022年4期)2022-06-01
农业灾害研究(2022年1期)2022-05-07
中国集体经济(2022年9期)2022-04-12
杂技与魔术(2022年1期)2022-03-16
少儿科学周刊·儿童版(2021年21期)2021-12-11
古今农业(2021年2期)2021-08-14
今日农业(2021年4期)2021-06-09
今日农业(2020年20期)2020-12-15
今日农业(2020年17期)2020-12-15
今日农业(2020年24期)2020-03-17
