
基于深度学习与复合字典的马铃薯病害识别方法
2020-07-24 05:07张建华王关平
农业机械学报 2020年7期
杨 森 冯 全 张建华 孙 伟 王关平
(1.甘肃农业大学机电工程学院, 兰州 730070; 2.中国农业科学院农业信息研究所, 北京 100081)
0 引言
甘肃省是我国重要的马铃薯种植基地。在马铃薯生长期,病害是影响马铃薯产量和品质的主要因素,为确保马铃薯获得较好的经济效益和利用价值,准确和实时识别病害类型是防止病害蔓延和保障其健康生长的前提条件[1-2]。传统的农作物病害识别均由有经验的专家进行诊断,该类方法效率低、工作强度大,且不能实时对病害做出科学、准确的诊断,而机器视觉技术能够实现对病害的快速、准确诊断[3-4]。文献[5-8]通过人工采集病害叶片、并在特定光照和简单背景下拍摄,进而对农作物病害进行识别,该类方法识别准确率相对较高,但由于在人工控制环境下采集图像,无法实现自然条件下病害的自动识别。此外,也有一些研究[9-11]实现了自然条件下病害的识别,但需要在复杂背景中预先分割出叶片的病害区域,该类方法对叶片分割算法要求较高,且分割需要花费大量的时间,无法满足病害的实时诊断。相比传统学习方法,卷积神经网络在特征提取方面具有更强的表达能力,VGG、AlexNet和ResNet网络在图像检测和分类中取得了较好的效果[12]。BRAHIMI等[13]利用卷积神经网络对番茄的9种病害进行训练,识别率达到99.1%。张建华等[14]通过改进VGG-16网络和优化模型结构参数,实现了对棉花5种病害的准确识别。在病害识别中,特征提取也是一项关键技术,很多经典的病害识别方法[15-17]主要依据颜色、纹理和形状等参数或各个参数的组合进行病害识别,但由于实际条件下叶片病斑多样、复杂,且特征易受光照条件的影响,尤其颜色特征很不稳定,使得这类方法的识别效果不佳。词袋特征[18-19]是一种抽象的语义特征,对复杂图像描述能力更强,在目标识别中取得了较好的效果。秦立峰等[20]提出一种基于词袋模型和主成分分析(Principal components analysis, PCA)的多维空间融合的黄瓜叶片病害识别方法,平均识别率达90.38%,但需要手动裁剪拍摄的病害叶片图像的病斑部位,无法满足病害的自动诊断识别。自然条件下获取的病害叶片病斑相对较小,背景区域占比较大,直接在原始图像上提取特征并聚类生成视觉特征单词后,缺乏足够的区分度,因此,直接采用词袋法对病害的识别效果不佳。
针对上述病害识别方法存在背景干扰与病害识别需预先分割的问题,本文引入卷积神经网络对病害斑块区域进行检测,以降低背景对病害特征信息的干扰;采用尺度不变特征变换(Scale invariant feature transform, SIFT)表观特征和颜色特征组合的特征提取方法,构造表观特征词汇字典和颜色特征字典,旨在训练出精度较高的病害识别模型,以期完成自然环境下马铃薯病害的自动识别。
1 材料与方法
1.1 图像采集
试验选取马铃薯常见的早疫病、晚疫病、炭疽病3种病害叶片和健康叶片图像进行识别。病害图像通过2种途径获取:①利用Cannon EOS1200D型数码相机(分辨率为1 080像素×720像素)于甘肃农业大学农作物试验基地进行采集,拍摄方式设置为近拍模式、自动白平衡、自动调节焦距和光圈,相机垂直拍摄,拍摄高度30~50 cm。分别在晴天和阴天光照条件下拍摄病害叶片图像,共采集自然条件下的样本650幅,包含早疫病50幅、晚疫病50幅、炭疽病50幅、健康叶片500幅。深度学习的训练需要大量样本,而大田条件下马铃薯病害样本的收集比较困难,因此对采集的图像随机旋转0°、90°、180°、270°,使自然条件下采集的图像增加了4倍。②在公共网站(中国农业网)和Plant Village数据库上收集3种叶片病害图像,包含病害样本2 000幅、健康叶片156幅。利用2种采集方式获取的病害样本具有随机性,信息更加丰富,且包含不同光照、不同背景、不同生长时期的病害图像,满足试验要求。图1为3种病害叶片图像示例,其中第1行图像为自然环境下的病害图像,背景存在黑色地膜、光斑以及叶片之间相互遮挡的现象;第2行图像为中国农业网和Plant Village 数据库图像,所有样本都是单叶片病害图像,且光照均匀。

图1 病害图像和健康叶图像示例Fig.1 Examples of disease images and healthy leaf images
1.2 斑块区域的检测
病斑区域检测的主要任务是在原始病害叶片图像中提取出病害目标,针对叶片图像背景复杂、目标分割方法提取病害区域耗时长和精度较低的问题,本文采用目标检测中性能表现优异的Faster R-CNN算法提取病斑区域。在检测的病斑区域中将会存在部分病害区域的漏检以及非病害区域的误检,但是斑块中病害区域与背景的占比显著提高,在后期病害识别模型中可以利用斑块区域集合来提取特征信息,该特征信息集中包含了病害的相关信息,一定程度上减少了相似背景的干扰。
1.2.1Faster R-CNN检测网络框架
Faster R-CNN检测网络[21-22]主要由卷积神经网络、生成候选区域的区域建议网络、感兴趣区域(RoI)池化层和Faster R-CNN目标检测网络构成。马铃薯病斑检测框架如图2所示。

图2 马铃薯病斑检测框架Fig.2 Potato plaque detection framework
(1)首先对输入的任意尺寸病害图像利用卷积网络的卷积层、激活层和池化层自动提取图像的特征图。
(2)特征图输入到候选区域网络(Region proposal network,RPN)后,利用3×3滑动窗口生成d维特征向量并输入到Softmax层和框回归层。对于每个滑动窗口的位置可以同时生成k个候选框,则在整个特征图中可生成 60×40×k个候选区域,并在特征图上利用Softmax分类器逐像素对k个候选框预测出前景与背景的概率。在框回归层中,逐像素对k个候选区域拟合出边框中心坐标与宽、高4个坐标信息。
(3)将RPN网络生成的候选区域和卷积网络输出的特征图输入到感兴趣区域池化层,遍历所有的候选区域,将其坐标比例缩小为原来的1/16,通过映射在特征图上生成一个相应区域,并将此区域划分为7×7的小区域,对于每个小区域,使用最大值池化方式处理,形成一个固定尺寸(7×7)的特征图。
(4)将固定的特征图输入全连接层和Softmax后,预测出候选框所属的类别以及回归出精确的边框位置。
1.2.2基于迁移学习的斑块区域检测
深度卷积神经网络实现对目标的准确分类需要具备充分的数据集,在自然环境下获取完整的马铃薯病害数据库相对较为困难,直接采用该数据集对初始化的所有网络参数重新训练,将会出现网络不收敛以及模型的过拟合现象,使得检测模型的精度严重下降。AlexNet和VGG-16等深度卷积网络模型在图像分类识别中具有明显的优势,网络模型是由包含100万幅图像的ImageNet 数据库训练得到,通过模型的卷积层能够提取图像的深度信息,且模型中拥有大量的权重参数,本文利用迁移学习[23-24]的方法完成对病斑检测模型的训练。利用马铃薯病害训练数据集微调AlexNet和VGG-16预训练分类网络的权重参数,优化卷积层参数,可将分类网络迁移到Faster R-CNN检测网络特征提取部分,使得卷积层的权值得到充分的训练。
检测出的斑块区域是外接矩形框出的原图像的子图像,对图像训练集中所有病害图像的斑块区域进行检测后,组成斑块训练集
Blob={(Bi,Li)|i=1,2,…,N}
(1)
式中Bi——斑块训练集中的第i个斑块区域
Li——Bi对应的病害类型标签
N——斑块区域数
Blob——斑块训练集
1.3 特征词汇表的构建
病害叶片在颜色上与正常的叶片有很大的差异,且不同类型的病害颜色也不相同,病害识别时提取颜色信息作为有效的表观特征。根据3种病害叶片图像的颜色特点,以Lab为颜色模型,统计斑块区域a、b分量的颜色信息,构建出表观颜色特征向量。由于检测出的病害区域较小,为了提取出丰富的特征信息,本文采用高密度特征提取方法,主要操作步骤如下:
(1)首先将斑块训练集Blob中每个斑块区域的RGB彩色图像转换为Lab图像,并将每个斑块区域均匀划分成m×n个网格。
(2)在Lab图像每个格点上计算该点的a、b值,获得该点的二维颜色特征向量,遍历斑块区域中的所有格点生成m×n×2维的特征向量,最终在整个斑块训练集中生成m×n×2×N维的表观颜色特征向量。
颜色特征容易受光照变化、阴影的影响,单一的颜色特征不能满足病害的识别精度。SIFT特征具有尺度不变性[25],对自然条件下图像的亮度变化以及拍摄角度的旋转具有很好的适应性,在检测的病害区域上提取SIFT特征构建SIFT特征向量。采用与提取颜色特征相同的高密度特征提取方法,将斑块区域转换为灰度图像后在每个网格上计算SIFT特征,通过遍历所有网格形成m×n维特征,最终在整个斑块训练集中生成m×n×N维SIFT特征向量。
1.4 复合字典的构建
利用K-均值聚类算法分别对两类表观特征词汇表进行聚类运算,将特征词汇聚为K个聚族,选取每个族的聚类中心构成特征字典的视觉单词,表观颜色特征字典Wt表示为
Wt={v1,v2,…,vK}
(2)
式中vK——聚类的第K个表观颜色视觉单词
SIFT特征字典Ws表示为
Ws={u1,u2,…,uK}
(3)
式中uK——聚类的第K个SIFT视觉单词
将表观颜色特征字典和SIFT特征字典组合,建立复合字典Wf,表示为
Wf={v1,v2,…,vK,u1,u2,…,uK}
(4)
最终,建立的复合字典Wf中有2K个视觉单词。
1.5 识别模型的建立
对病害训练集中检测出的病害区域提取颜色特征和SIFT特征,通过计算特征点与复合字典Wf中视觉单词之间的最近距离,统计出每个病害区域在视觉单词中出现的频率,获得2K维的特征直方图。对任意的病害图像检测出所有的斑块区域,分别统计出每一个斑块区域Bi的特征直方图hi,通过归一化处理获得第r幅原始病害图像的直方图为
(5)
式中r——训练集中的第r幅原始病害图像
H——第r幅原始病害图像的直方图
每一幅病害图像在复合字典映射后,根据式(5)计算出训练集中所有病害图像的直方图特征,并将该特征数据作为分类器训练的输入特征。为建立识别精度较高的决策模型,在训练过程中采用多分类器的训练方式,分别采用分类中应用广泛的SVM、随机森林和最近邻分类器进行识别正确率对比试验。利用设定的分类器对3类病害训练集样本进行预测,其中SVM分类器的识别正确率为92.15%,随机森林分类器识别正确率为80.26%,最近邻分类器的识别正确率为70.53%,试验结果表明,SVM分类器对小样本和非线性病害数据的分类优势明显,因此本文筛选出精度较高的SVM分类器作为最终的病害识别模型。
2 试验结果与分析
试验基于Caff深度学习框架,硬件配置为NVIDIAteslaK20 GPU,搭载InterXeon E5-2683V3@2.00GHz x56处理器,内存为64 GB。软件环境为Windows 10操作系统,并选用Matlab 2018a作为编程环境。试验主要包括两部分,分别是马铃薯病斑区域检测试验和病害识别准确率试验,其中病害识别试验中完成不同K值下病害识别准确率试验、不同特征组合下病害识别准确率试验、不同光照条件下病害识别准确率试验以及不同方法下病害识别准确率试验4部分,以此展开对马铃薯病害识别的研究。
2.1 病斑检测
病斑检测模型训练集由3类病害样本构成,将病害图像库中的2 048幅图像作为训练集, 952幅图像作为测试集,训练集中的200幅图像作为验证集,并对训练集图像采用人工标定的方式制作成PASCAL VOC数据集格式。病斑区域检测的准确性直接影响病害的识别精度,采用病害平均检出率和检测框平均精度2个评价指标评价识别精度。病害平均检出率主要衡量在整个病害叶片测试集中能够检测出目标区域的样本个数,但不能判断检测框是否为病斑目标。利用检测方法在病害叶片上获得的检测框存在非病斑目标的检测框以及病斑区域占比较小的检测框,检测框平均精度主要反映在病害叶片上提取的检测框判断为病斑目标的准确度。病害平均检出率和检测框平均精度计算公式为
(6)
(7)
式中P1——病害平均检出率
P2——检测框平均精度
TP——检测出目标区域的样本数
FN——未检测出目标区域的样本数
T——检测框中病害区域的面积占整个检测框面积的比例大于等于0.5的检测框数
F——病害区域的面积占整个检测框面积的比例小于0.5的检测框数
采用不同深度的特征提取网络训练检测模型后,病斑目标的检测精度存在差异性,为验证特征提取网络深度对检测精度的影响,试验选择AlexNet和VGG-16网络对马铃薯病害叶片数据集进行测试,不同深度特征提取网络的检测结果如表1所示。总体来看,基于AlexNet网络训练的病斑检测模型对3种病害类型的平均检出率和检测框平均精度分别为93.20%和71.90%,而基于VGG-16网络训练的病斑检测模型其病害平均检出率和检测框平均精度分别为95.06%和84.63%。2种网络对平均检出率影响不大,而对于检测框平均精度,VGG-16网络比AlexNet网络提高了12.73个百分点,表明VGG-16网络的检测精度相对较高,并且特征网络层数越深,提取图像的特征信息维度越高,检测精度也越高。鉴于VGG-16网络的优势,本文对病斑区域的检测阶段采用基于VGG-16特征网络的Faster R-CNN算法。
由表1可知,在采用VGG-16特征提取网络后,晚疫病的检测准确度高于其他2种病害,其检测框平均精度P2达到90.42%,而早疫病和炭疽病的检测框平均精度分别为80.74%和82.72%。根据统计结果可知,晚疫病相比其他两种病害,P2分别提高了9.68、7.70个百分点,出现这种检测差异的主要原因与病斑的分布特征密切相关,晚疫病发病的位置出现在叶片的边缘位置,且病斑的面积相对较大,而其他两种病害的病斑呈现出分布密集、位置随机、形状多样和面积较小的特征,这对收集完整的病害训练样本增加了困难,使得本文训练的检测模型对于部分病害样本的检测准确率下降。

表1 基于不同特征提取网络的不同病害检测的准确性Tab.1 Detection accuracy of different diseases based on different networks
本文检测方法的病斑检测效果如图3、4所示。试验测试了复杂自然环境和特定光照背景(Plant Village数据库)下的病害样本,其中红框代表AlexNet特征网络的检测结果,绿框代表VGG-16特征网络的检测结果。2种光照条件下基于AlexNet特征网络检测框出现重叠检测、非病害目标检测和漏检现象较为明显,而基于VGG-16特征网络的检测框基本能够包围病斑区域,漏检的病斑相对较少。VGG-16特征网络在自然环境下的病斑检测结果如图4所示,将背景中的地膜、黑色光斑以及泥土误检测为病斑目标,其误检率相对较高。图4a所示的早疫病叶片中分布的大病斑区域能够完整检测,但对于分布的颗粒状小病斑未能成功识别。总体可以看出,叶片中的主要病害区域能够基本检测出来,且适应于不同大小病斑的检测,但检测出的斑块中存在病害区域的漏检以及非病害区域的误检。

图3 Plant Village数据库病斑的检测结果Fig.3 Lesion detection results of Plant Village database

图4 自然条件下病斑的检测结果Fig.4 Test results of disease detection under natural conditions
2.2 病害识别
马铃薯病害识别数据集由Plant Village数据库图像和试验田拍摄的图像组成,训练集图像共2 700幅,测试集图像952幅,样本总数为3 652幅,其中早疫病图像1 200幅,晚疫病图像1 200幅,炭疽病600幅,健康叶片652幅。训练集从整体样本中随机抽取,不同类型的病害图像数量比例一致,且与验证集和测试集互斥。为验证识别模型的误差,选取训练集样本的10%作为验证集,共计270幅图像。基于Faster R-CNN检测模型,对部分健康叶片区域存在目标检测框,对训练集中健康叶片通过本文检测方法获得Blob集合,利用式(5)训练出4类标签样本的识别模型。
2.2.1K值对识别准确率的影响
复合字典中视觉单词K值反映病斑的直方图空间维数,K值直接影响模型训练精度和识别速度,为了获得最优的K值,本文对K值按照低维、中维和高维3个空间设置了6个不同的取值,利用测试样本分别在对应取值下进行了病害识别准确率试验。表2给出不同K值下3种病害和健康叶片的识别准确率,由表2可以看出,K=10时,病害的平均识别准确率最低,仅为80.47%。随着K值的逐渐增大,病害的平均识别准确率不断提高,当K=50时,平均识别准确率达到最高值90.83%;当K达到100或高维数500时,病害的平均识别准确率与K=50相比最多降低了1.34个百分点,但是平均运行时间最多增加了3.59 s,表明K=50时,病害的平均识别准确率达到了稳定状态,运行时间为1.68 s,耗时相对较短,因此本文K取50。

表2 不同K值下病害的识别准确率Tab.2 Recognition accuracy of diseases under different K values
2.2.2叶片特征对识别准确率的影响
本试验对检测的病斑区域提取颜色特征、SIFT特征和2种特征的组合做了对比试验。试验中K取50,测试样本和训练样本与前文保持一致。表3给出了3种特征下病害的识别准确率,通过对比表中3种病害,单一特征时病害的识别准确率整体较低,采用SIFT+颜色特征组合时3种病害和健康叶片平均识别准确率显著提高,相比SIFT和颜色特征分别提高了13.37、5.64个百分点。颜色特征平均识别准确率比SIFT特征高7.73个百分点,表明颜色特征更能直观表达病害信息,类别之间的区分度相对较好。对于3种病害,采用颜色特征后,早疫病和晚疫病识别准确率分别为90.63%和88.41%,比炭疽病高19.16、16.94个百分点,且早疫病识别准确率比SIFT+颜色特征组合提高了1.01个百分点,这是由于早疫病相对其他两种病害颜色有明显的差异性,通过颜色特征能够正确判断病害类型。总体来看,在颜色特征中融合SIFT特征后,3种病害识别准确率都得到了改善,尤其炭疽病提高显著,表明在自然环境下,SIFT特征能够降低病害亮度信息和拍摄角度旋转变化所引起的识别误差。
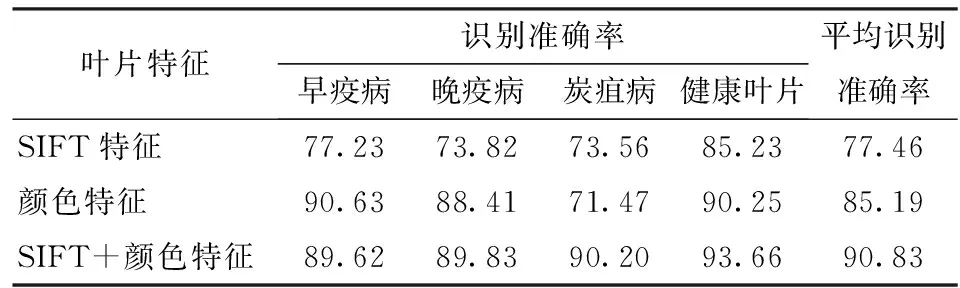
表3 3种特征下病害的识别准确率Tab.3 Recognition accuracy of diseases under three features %
2.2.3光照条件对识别准确率的影响
为验证本文病害识别方法对光照变化的适应性,本文对自然环境和特定光照2种照明条件做了对比试验,病害识别结果如表4所示。由表4可知,在复杂自然环境下3种病害及健康叶片的平均识别准确率为84.16%,比特定光照降低了6.67个百分点,原因是自然光照下病斑的颜色信息失真和病斑区域误检测增多,对病害的识别效果未能达到最优。总体表明,自然环境下3种病害的识别准确率均不小于80.94%,说明本文方法能够满足自然环境下病害识别任务,并且对光照变化具有一定的鲁棒性。

表4 2种光照条件下病害的识别准确率Tab.4 Recognition accuracy of diseases under two light conditions %
2.2.4不同方法的识别准确率对比
为验证本文方法的有效性,与传统词袋法[26]进行对比,试验结果如表5所示。传统词袋法直接在马铃薯病害叶片上提取颜色和纹理特征,2种光照条件下病害的平均识别准确率分别为58.71%和86.48%,而本文方法平均识别准确率分别为84.16%和90.83%,则说明本文方法对病害的识别性能优于传统词袋法。在特定光照下本文方法平均识别准确率仅比传统词袋法高4.35个百分点,其原因在于该类样本不同病害类型之间差异性较为明显,直接从整体叶片提取特征,包含了病害的所有特征信息,并且样本背景单一,不容易受到光照变化和外界因素的干扰,因而2种方法之间的识别准确率相差较小。此外,在自然条件下传统词袋法对病害的平均识别准确率只有58.71%,识别准确率相对较低,比本文方法低了25.45个百分点,可见本文方法对光照变化和复杂背景干扰具有较好的适应性,能够完成病害的有效识别,可满足在自然条件下对马铃薯病害在线识别的要求。

表5 不同方法识别准确率对比Tab.5 Contrast experiment results of different methods %
3 结论
(1)对病斑区域的准确检测是完成病害识别的前提,本文提出一种基于Faster R-CNN的病斑检测方法,利用迁移学习对病害小样本进行训练,能够缩短训练时间,并且提高了模型的检测精度。对AlexNet和VGG-16 2种不同深度的特征提取网络进行对比试验,其中VGG-16特征提取网络的病害平均检出率为95.06%,检测框平均精度为84.63%,病斑检测的准确性优于AlexNet网络,结果表明,基于VGG-16网络的Faster R-CNN算法能够实现对病斑区域的快速、准确检测,但对一些较小的病害目标存在漏检测。
(2)为克服病害类型的多样性和光照变化对病害识别精度的影响,采用颜色特征和SIFT特征组成的混合特征,并通过特征聚类方法构建复合字典,能够有效降低特征空间维数,提高病害的识别能力。试验结果表明,视觉特征单词量K=50时,对3种病害的平均识别准确率最高,且平均耗时最短;本文方法在特定光照条件和自然环境下对病害的平均识别准确率分别为90.83%和84.16%,识别效果均优于传统词袋法,表明该方法对自然环境下马铃薯病害叶片的识别是可行的。
猜你喜欢
今日农业(2022年3期)2022-06-05
今日农业(2021年8期)2021-11-28
烟台果树(2021年2期)2021-07-21
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
计算机技术与发展(2020年12期)2020-12-25
今日农业(2020年19期)2020-11-06
江苏农业科学(2016年8期)2017-02-15
