
基于自编码器的深度对抗哈希方法在覆冰电网图像检索中的应用
2020-07-22 13:40:02张丽敏王继宗史国华
太原理工大学学报 2020年4期
强 彦,何 龙,张丽敏,王继宗,吕 军,史国华,陈 琪
(1.太原理工大学 信息与计算机学院,太原 030024;2.国网山西省电力公司晋城供电公司,山西 晋城 048000;3.吕梁学院 计算机科学与技术系,山西 吕梁 033001;4.俄勒冈州立大学 工程学院,美国俄勒冈州 科瓦利斯 97331)
随着电网互联不断深入和电力市场化的逐步实施,电网的运行环境更加复杂,对电网的稳定性和可靠性提出了更高的要求。我国很多地区经常因为冰雪侵扰和覆冰灾害引起导线断线、杆塔倒塌、绝缘子闪络等事故,导致电能输送的稳定性受到影响[1]。电力公司需要花费大量的人力资源对覆冰图像进行检索,从而得到图像的实际坐标信息,用以指引工作人员前往做好排障处理。近年随着信息科学技术的快速发展,电力行业积累的覆冰图像数据往往呈现出两个新的特征:1) 数据量变得巨大且增长趋势迅速;2) 常常伴随着高维特征。海量数据和“维度灾难”两个问题的叠加,使得精确最近邻搜索算法效率低下,此时寻找更加高效、准确的覆冰图像检索方法就变得越来越重要。
为了保证检索质量和计算效率,近似最近邻(approximate nearest neighbor,ANN)搜索已引起越来越多的关注[2]。ANN搜索返回与其真实最近邻半径在c(c>1)倍误差之内的对象作为结果。当面对大规模的数据时,搜索近似最近邻样本的计算量要小于搜索精确最近邻样本的计算量。哈希学习以其在存储空间和计算时间上的优势受到了较多关注[3]。哈希学习旨在通过哈希函数将高维的图像数据投影到汉明空间,从而将原始空间样本映射为紧凑的二进制哈希码,同时尽量保持原数据空间中样本点的近邻关系,显著减少数据的存储和通信开销,实现有效的图像检索,从而有效提高检索系统的效率。
按照哈希函数来划分,哈希学习可以分为无监督方法[4-6]和有监督方法[7-8]。无监督哈希函数通过在从未标记的数据中进行训练将数据编码为二进制哈希码。尽管无监督方法更为通用并且可以在没有语义标签或相关性的情况下进行训练,但它们受到语义鸿沟困境的限制,即对象的高级语义描述通常与低级特征描述有所不同。有监督的哈希方法可以合并语义标签或相关性以减轻语义差距并提高哈希质量,即以较少的哈希码位数实现准确的搜索。在本文中,我们专注于建立数据依赖型的监督哈希编码的哈希学习方法。
近年,深度哈希学习方法[9-11]表明使用深度神经网络可以更有效地学习特征表示和编码任何非线性哈希函数。这些深度哈希方法已在许多数据集中展示了最新的结果。但是令人满意的性能仅来自大规模的图像数据,这些图像提供了充足的训练数据标签或成对相似性的监督信息。对于电网覆冰图像来说,可用的监督信息不足,而且注释足够的训练数据或收集成对相似性信息以进行深度哈希学习极其昂贵。在缺乏相似性信息的情况下,现有的深度哈希学习方法可能会过度拟合训练图像并严重影响检索质量。生成对抗网络(generative adversarial networks,GAN)以其能够缓解图像数据不足的问题受到广泛关注[12]。GAN可通过极小极大博弈机制生成视觉上近似真实的图像样本,以缓解监督信息图像不足的问题。但是这种灵活的算法也伴随着优化的不稳定性,会导致模式崩溃问题,因此更多的深度对抗哈希研究致力于稳定GAN训练过程。KAMRAN et al[13]提出一种深度无监督哈希生成对抗网络(HashGAN),可以在无需任何预训练的情况下有效获取单张输入图像的二进制表示,并且引入了新的哈希损失和协作损失函数以稳定模型训练。CAO et al[14]基于WGAN框架提出一种基于成对相似信息的条件生成对抗网络(pair conditional wasserstein GAN,PC-WGAN),通过以成对相似性信息为条件来实现图像合成,并且引入余弦交叉熵损失和余弦量化损失函数以优化训练过程。据了解,该方法是目前图像检索领域的最新进展。
受上述研究启发,本文提出一种基于成对相似信息的自编码生成对抗网络(PC-AEGAN),以从真实图像和生成模型合成的各种图像中学习紧凑的二进制哈希码。具体地,引入自编码生成对抗网络(auto-encoding GAN,AE-GAN)[15],通过在现有的生成器和鉴别器之上添加新的编码鉴别器以解决模式崩溃和图像模糊的问题。另外还引入了新颖的基于长尾柯西分布的损失函数以改善汉明空间检索性能。对比已有的图像检索方法,本文的主要工作如下:
1) 添加新的编码鉴别器以鼓励生成的图像样本更好地表示潜在的数据分布,即将随机可能性转换为合成似然性,将未知后验分布替换为隐含分布。
2) 引入一种新颖的基于长尾柯西分布的交叉熵损失代替原余弦交叉熵损失,用于优化在汉明空间中的相似性学习过程。
3) 进一步引入柯西量化损失代替原余弦量化损失,用于在保持相似性学习的过程中同时控制将连续表示转换为二进制码的量化误差,以优化相似信息编码和二进制码量化过程。
1 相关工作
1.1 自编码生成对抗网络
GAN能够生成视觉上以假乱真的图像样本,但是这种灵活的算法也伴随着优化的不稳定性,会导致模式崩溃问题。一种自然的替代方法是使用变分自动编码器(VAE)。当基于图像进行训练时,VAE方法不会受到模式崩溃问题的困扰,但输出具有模糊性。为了有效地解决GAN模式崩溃和VAE图像模糊的问题,MIHAELA et al[15]提出一种基于变分自动编码器的生成对抗网络e算法,该算法结合了GAN和VAE两种模型,模型结构如图1所示。本文在现有研究的基础上引入编码鉴别器网络以解决模式崩溃和图像模糊的问题。
1.2 柯西损失函数
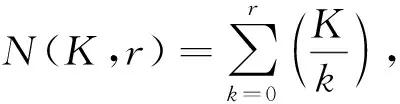
现有研究中通常采用广义Sigmoid函数σ(x)=1/(1+e-αx)作为概率映射关系。但是,广义Sigmoid函数存在一个关键的错误指定问题,如图2所示。当哈希码之间的汉明距离远大于2时,广义Sigmoid函数的概率仍然很高,并且仅当汉明距离接近K/2时概率才开始明显减小。这意味着,以现有的图像检索方法无法将相似数据的哈希码之间的汉明距离映射到小于半径2内,因为广义Sigmoid函数对于小于K/2的汉明距离还没有足够的判别力。这是现有图像检索方法中未考虑到的。对于汉明半径大于2的相似数据,对汉明空间检索指定的损失函数明显不利。CAO et al[17]提出一种基于长尾柯西分布的新型概率映射函数:
(1)
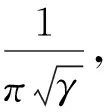
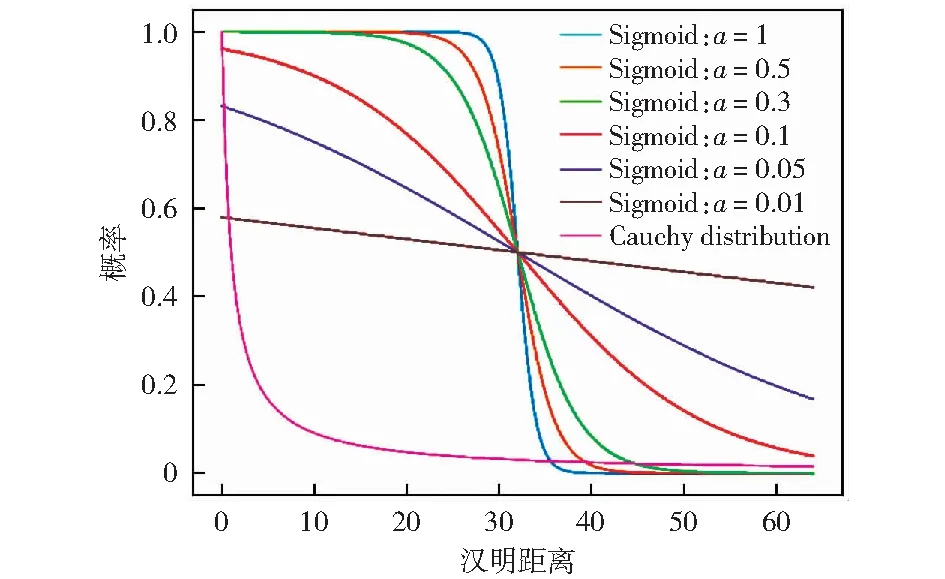
图2 广义Sigmoid和长尾柯西分布函数在相似数据点哈希码之间汉明距离的概率值Fig.2 Probability value of Hamming distance between hash codes of similar data points for generalized Sigmoid and long-tail Cauchy distribution function
由图2可以观察到,当汉明距离较小时,柯西分布的概率下降得非常快,从而导致相似信息被拉至较小的汉明半径内,而广义Sigmoid函数不能做到这一点。在本文中,我们成功引入基于柯西分布的损失函数,通过代替当前最先进的余弦损失函数实现更高效的汉明空间检索。
2 方法
如图3所示,该深度对抗哈希方法主要包括三个学习阶段:1) 近似哈希码学习阶段。给定训练图像和成对相似性矩阵S,学习近似的二进制哈希码矩阵H;2) 近似真实图像生成阶段。通过引入编码鉴别器C,使得随机向量Zr能够学习近似哈希码H的合成似然性,以鼓励生成的图像样本If更好地表示真实数据分布;3) 哈希函数学习阶段。构建哈希编码网络F,将真实图像和生成模型合成的各种图像作为输入,学习生成紧凑的二进制哈希码hi.
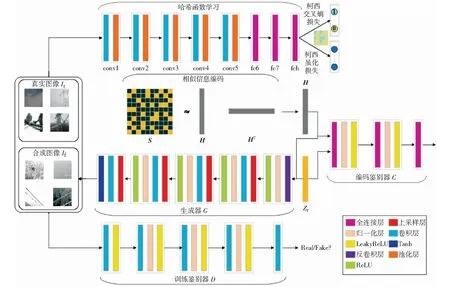
图3 基于自编码器的深度对抗哈希方法框架Fig.3 Framework of deep adversarial hashing method based on Auto-Encode
2.1 近似哈希码学习阶段
给定n张训练图像I={I1,I2,…,In}和成对相似性矩阵Sij:
(2)
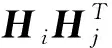
2.2 近似真实图像生成阶段
该PC-AEGAN模型建立在α-GAN的基础上。在生成器G和训练鉴别器D之上采取了编码鉴别器的网络结构以解决模式崩溃和图像模糊的问题,如图3所示。生成器网络G使用近似哈希编码向量H作为条件以约束近似真实图像生成。鉴别器D执行两个任务,一是判别图像的真实性,二是判断输入的成对图像的相似性。
生成器G:使用了缩放卷积操作来减少参数的数量和伪影。此外,在具有3×3卷积核的卷积层之前使用了卷积近邻上采样操作以取代反卷积层。为了训练的稳定性,归一化层和ReLU层在每个卷积层后被应用。在最后的卷积层之后将归一化层移除,并且使用了Tanh激活函数。
训练鉴别器D:具有5个卷积层,所有层均使用4×4大小的卷积核。由于训练鉴别器最后一层的输出必须是单值(Real/Fake),因此要相应地设置输出通道大小。在每个卷积层之后设置了归一化层和Leaky ReLU层。值得注意的是,在首个和最后的卷积层之后,我们删除了归一化层以保持输入和输出中各元素之间的独立性。
编码鉴别器C:在生成器G和鉴别器D之上采取了α-GAN的编码鉴别器网络结构以解决模式崩溃和图像模糊的问题。编码鉴别器C由3个全连接层组成,且Leaky ReLU层和归一化层在每个全连接层后被放置。
2.3 哈希函数学习阶段
2.3.1哈希编码网络
我们使用AlexNet网络作为哈希编码网络F的主要架构,包括5个卷积层conv1-conv5和3个全连接层fc6-fc8.将最后的全连接层fc8替换为具有k个神经元的哈希层,从而将fc7层的特征表示转换为k维二进制码Zi.通过hi=sgn(Zi)获得哈希码hi.然而,由于不适当地梯度导致难以优化该函数,因此使用双曲正切(tanh)函数将连续的二进制码Zi压缩到[0,1]区间,从而减小了连续二进制码Zi和哈希码hi之间的距离。为了进一步保证用于有效汉明空间检索的哈希码的质量,保留了训练对{(Ii,Ij,Sij);Sij∈S}之间的相似性,并控制了量化误差。
2.3.2贝叶斯学习框架
本文使用一种贝叶斯学习框架,通过共同保存成对图像的相似度并控制量化误差,可以对相似数据进行深度哈希处理。给定n张训练图像I={I1,I2,…,In}和成对相似性矩阵Sij,则近似哈希码H=[h1,h2,…,hn]的对数最大后验估计被定义为:

(3)
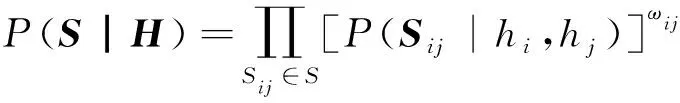
(4)
其中S1和S0分别是相似和不相似训练对的集合。对于每个训练对,P(Sij|hi,hj)是给定哈希码(hi,hj)时Sij的条件概率,这可以由伯努利分布得到:

(5)
式中:d(hi,hj)表示哈希码hi与hj之间的汉明距离,σ(·)是基于柯西分布的概率函数。
2.4 损失函数
本文提出的深度对抗哈希方法通过3个阶段以实现从各种图像中学习紧凑的二进制哈希码,在学习阶段使用了多个损失函数来约束模型的训练过程。
2.4.1近似哈希码学习损失
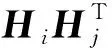
(6)

2.4.2近似真实图像生成损失

对于训练鉴别器D,定义LDS表示判别输入图像真假性的训练损失:
LDS=EIf[D(If)]-EIr[D(Ir)]+λLGP-D.
(7)
类似地,定义了LDC,通过计算训练鉴别器D的输出和成对相似性矩阵Sij之间的二进制交叉熵的总和以表示判别输入的成对图像相似性的训练损失:

(8)
因此,训练鉴别器D的总损失为:
(9)
对于生成器G,目标是最大程度地利用由相似信息编码和随机向量生成的合成图像来欺骗训练鉴别器D,我们定义LGS+LGC表示训练损失。损失由两部分组成:一是合成图像的质量与真实图像相似,因此训练鉴别器输出的概率分布约为0.5(LGS);二是引导训练鉴别器判别输入的成对图像的相似性(LGC).因此,生成器G的总损失LG为:
(10)
对于编码鉴别器C,我们定义LC表示判别近似哈希编码H和随机向量Zr间的分布一致性的训练损失:
(11)
2.4.3哈希函数学习损失
由于含有二进制约束Hi∈{0,1}q的式(3)的离散优化非常具有挑战性,因此为了简化优化,如大多数先前的哈希方法所采用的那样,我们将连续松弛应用于二进制约束。为了控制由连续松弛引起的量化误差‖hi-sgn(hi)‖,并学习高质量的哈希码,使用了一种基于长尾柯西分布的新颖损失:
(12)
为了使用连续松弛,需要使用连续编码的最佳近似值替代汉明距离。对于成对二进制哈希码hi和hj,它们的汉明距离d(hi,hj)与归一化的欧式距离之间存在以下关系:
(13)
因此,本文采用上述d(hi,hj),通过将式(5)和(12)输入式(3)的对数最大后验估计中,得到了下列优化目标:
(14)
其中,β是用于权衡柯西交叉熵损失LFc和柯西量化损失LFq的超参数,F表示要优化的网络参数集。具体而言,柯西交叉熵损失LFc为:
(15)
类似地,柯西量化损失LFq为:
(16)
2.5 模型训练
本文提出的深度对抗哈希方法包括3个学习模块:相似信息编码模块用于学习近似哈希码矩阵H,PC-AEGAN模型用于生成近似真实的图像,以及哈希编码模块用于为每个图像生成紧凑的哈希码。总体模型训练目标是式(6)、(9)、(10)、(11)和(14)的统一集成。由于该深度对抗哈希方法是GAN的变体,因此采用了博弈机制进行优化训练。相似信息编码模块,编码鉴别器C,生成器G,训练鉴别器D和哈希编码器F的优化问题分别计算如下:
(17)
其中,η用于表示哈希编码器F和拟议的PC-AEGAN模型的重要性。该深度对抗哈希方法通过反向传播可以有效地优化网络参数。
最后,通过简单的二值化hi=sgn(Zi)获得每个图像的哈希码。通过式(17)中的博弈优化,可以使用成对信息合成近乎真实的图像,并通过从真实图像和合成图像中保持相似度的学习和量化误差最小化来生成几乎无损的哈希码。值得注意的是,可以通过使用真实数据和合成数据进行深度学习哈希来减轻在监督信息不足的情况下学习的困难,这会产生更高质量的哈希码以提高搜索性能。
3 实验和结果
本文中的所有实验均在以下工作环境中进行:Ubuntu 18.04 LTS,2.90 GHz Intel(R) Xeon(R)W-2102 CPU和NVIDIA GTX Titan XP GPU.
3.1 数据集
通过和目前最先进的哈希检索方法进行对比,我们在两个数据集上验证了本文提出的深度对抗哈希方法的有效性和鲁棒性:
数据集1是电力公司于2013-2019年从遥感线路巡检图像中收集的覆冰图像数据集,由3 000张图像组成。我们从中随机选择10%的覆冰图像用于测试集,其他图像则用于训练模型。值得注意的是,测试集中的数据从未用于模型训练。
数据集2是ALEX et al[19]收集的可公开获得的CIFAR-10数据集。该数据集由10类图像、共60 000张组成。我们随机选择每类100张图像作为测试集,其余500张作为训练集,共50 000张训练图像和10 000张测试图像。
3.2 实验过程
基于TensorFlow框架实现本文提出的方法,同时通过对训练数据进行10折交叉验证以选择所有比较方法的参数。在训练过程中,采用mini-batch Adam优化器(learning rate=2×10-4,β1=0.9,β2=0.999,epsilon=None,decay=0,batch size=64),并将最大迭代次数设置为700.在模型训练的过程中,保存了在训练集上损失最低的模型参数以便在测试集上进行验证。
为了评估本文提出的PC-AEGAN模型的有效性,遵循FLEET et al[16]提出的标准评估方法,报告了三个标准评估指标:不同哈希编码位数下汉明半径2以内的平均精度均值,汉明半径2以内的精确率曲线,汉明半径2以内的查全率曲线。
3.3 结果
为了验证本文提出的深度对抗哈希方法的检索性能,我们与八种经典或最新的哈希方法进行了比较,包括:有监督的浅层哈希方法(ITQ-CCA[20],BRE[21],KSH[7]和SDH[8]),有监督的深层哈希方法(DNNH[22],DHN[23]和HashNet[24])和有监督的深层对抗哈希方法(PC-WGAN[14]).
3.3.1平均精度
表1展示了所有方法在两个数据集上的MAP结果,表明所提出的方法大大优于所有比较方法。具体地,与最佳的浅层哈希方法SDH相比,我们的方法在CIFAR-10和电网覆冰图像数据集上的平均MAP性能分别提升了22.2%和14.4%,这是因为该方法属于深度哈希方法,能够通过端到端框架学习深层表示和紧凑的哈希码,而这是浅层哈希方法无法做到的。在两个数据集上,本文方法的平均MAP性能分别比最先进的深度哈希方法HashNet分别提高了8%和3.3%.相比于DNNH,深度哈希方法DHN和HashNet通过共同保存相似性信息并控制量化误差来学习少损的哈希码,结果表明量化误差的引入对于改善模型性能有积极影响。

表1 所有哈希方法在两个数据集上的平均精度值结果Table 1 MAP@H≤2 results of all hashing methods on two data sets
与最先进的深度对抗哈希方法PC-WGAN相比,本文的方法在两个数据集上的平均MAP性能分别改善了2.7%和1.5%.我们在PC-WGAN的基础上进行了两处重要的改进:1) PC-AEGAN集成了新颖的编码鉴别器结构,可以使得随机向量学习真实数据的合成似然性和隐含后验分布以解决模式崩溃和图像模糊的问题。2) 哈希编码模块采用了新颖的柯西交叉熵损失和柯西量化损失代替余弦损失,可以更精确地近似汉明距离,以学习近乎无损的哈希码。
3.3.2精确率
汉明半径2内精确率曲线(P@H≤2)的性能对有效的图像检索非常重要。如图4所示,本文的方法在使用不同哈希编码位数的所有两个数据集上实现了最高的P@H≤2结果。这表明本文提出的深度对抗哈希方法可以比所有比较方法学习到更紧凑的哈希码,从而建立更有效且准确的汉明排名。当使用更长的哈希码时,汉明空间将变得更高维且更稀疏,从而更少的数据点将落在半径为2的汉明距离中。这也解释了为什么大多数现有的哈希方法在具有更长哈希码位数的P@H≤2性能方面表现较差。

图4 所有哈希方法在两个数据集上的精确率结果Fig.4 P@H≤2 results of all hashing methods on two data sets
3.3.3查全率
汉明半径2内查全率曲线(R@H≤2)的结果对于汉明空间检索至关重要,因为由于高度稀疏的汉明空间,所有数据点都可能被舍弃。如图5所示,本文提出的方法在两个数据集上均达到最高R@H≤2结果,这验证了我们的方法可以比所有比较方法将更多地相关点集中在半径为2的汉明距离内。由于使用较长的哈希码时汉明空间将变得更加稀疏,因此大多数哈希方法会导致R@H≤2性能严重下降。通过引入新颖的柯西交叉熵损失和柯西量化损失,随着哈希码变得更长,所提出的哈希编码模块在R@H≤2上也会产生非常小的性能下降。这表明即使使用更长的编码位数,本文提出的方法相比于所有比较方法也可以将更多相关点集中在汉明半径2之内。使用较长编码位数的能力使得该方法可以在准确率和效率之间进行权衡,而这种可选择性对于之前的哈希方法通常是不可能的。

图5 所有哈希方法在两个数据集上的R@H≤2结果Fig.5 R@H≤2 results of and all hashing methods on two data sets

图6 PC-AEGAN模型在两个数据集上的合成图像可视化结果Fig.6 Visualization results of the synthetic images of PC-AEGAN model on two data sets
3.4 合成图像可视化
如图6展示了本文提出的深度对抗哈希方法在所有数据集上的图像样本,包括生成的近似真实图像(左)和从数据集中随机选择的真实图像(右)。值得注意的是,合成图像的质量是近乎真实的,并且在语义上与真实图像是高度相关的。合成图像的引入能够提升训练图像的多样性,促进生成紧凑哈希码的质量以改善图像检索性能。
4 结语
本文提出了一种基于自动编码器的新型深度对抗哈希方法,该方法可通过合成近乎真实的图像以改善图像检索性能。提出的PE-AEGAN模型通过引入编码鉴别器解决了模式崩溃和图像模糊的问题,并且哈希编码模块通过使用柯西损失代替现有的余弦损失以实现更高效的汉明空间检索性能。该方法在电网覆冰图像的私有数据集和CIFAR-10公开数据集上进行了实验验证,结果表明该深度对抗哈希方法可以通过使用多样的合成图像提高紧凑型二进制哈希码的质量。该方法具有较好的鲁棒性,可以对其他图像检索问题有启发作用。
猜你喜欢
通信学报(2022年10期)2023-01-09 12:33:40
国防科技大学学报(2019年4期)2019-07-29 03:40:14
系统工程与电子技术(2016年5期)2016-11-02 00:37:48
中国铁路文艺(2016年6期)2016-05-14 08:13:13
工业设计(2016年8期)2016-04-16 02:43:34
星星·散文诗(2015年35期)2015-10-27 21:00:08
计算机工程(2015年8期)2015-07-03 12:20:04
应用数学与计算数学学报(2014年4期)2014-09-26 12:16:00
计算机工程(2014年6期)2014-02-28 01:25:40
电子设计工程(2014年12期)2014-02-27 11:58:03
