
基于Python爬虫的比赛信息查询交流系统设计
2020-07-22 12:00杨雄
无线互联科技 2020年9期
杨 雄
(西北民族大学,甘肃 兰州 730000)
据人力资源和社会保障统计,每年高校毕业生高达数万,势必会造成巨大的就业压力,能否找到心仪的工作还得靠自身的能力,不仅取决于是否具有毕业证和学位证,还取决于在校时获得的其他证书及平时的各类成绩。获得相应的证书可以直观地反应个人的能力大小,例如:获得华为主办的中国区大学生ICT大赛、国际计算机协会主办的ACM国际大学生程序设计竞赛、中国工业与应用数学学会举办的大学生数学建模比赛、武汉大学主办的全国大学生化学实验竞赛等比赛的证书将会在面试时为学生带来更大的信心。但是据调查显示,很多人都不知道这些赛事的举办时间及内容等。通过Python网络爬虫技术将比赛信息抓取到MySQL数据库中,可以方便用户进行查询及关注。
目前发现已经使用的与Python爬取比赛信息有关的系统或APP,具有如下特点:(1)以Python技术作为基础进行开发,综合应用了Python网络函数库。(2)以盈利为目的。(3)销售有关比赛的书籍及课程。
通过问卷调查及走访高校同学发现如下问题:(1)只知道四六级及计算机二级之类常规考试。(2)对将来找工作是否应该具有更多的证书概念模糊。(3)更多的同学对比赛的时间、地点等不清楚,更不知道怎么去复习。(4)找不到一起参加比赛的队友,一个人不想参加比赛等。
对于上述问题,需研发一个系统来解决,这个系统具有以下的特点:(1)通过Python爬虫技术抓取相关比赛信息。(2)实现抓取信息定制化。(3)实现信息查询功能。(4)可以相互交流并寻找参赛队友。
此系统实现爬取过程比较简单,先明确初始网页的统一资源定位符(URL),找到数据对应的网页,分析网页结构,找到数据所在标签位置,模拟超文本传输协议(HTTP)请求,并向服务器发送这个请求,获取到服务器返回的超文本标记语言(HTML),传递给数据解析模块之后,将URL放进已经爬取的URL队列中,数据解析模块解析收到的HTML之后,通过正则表达式来处理所要爬取的具体内容,系统具体框架如图1所示。
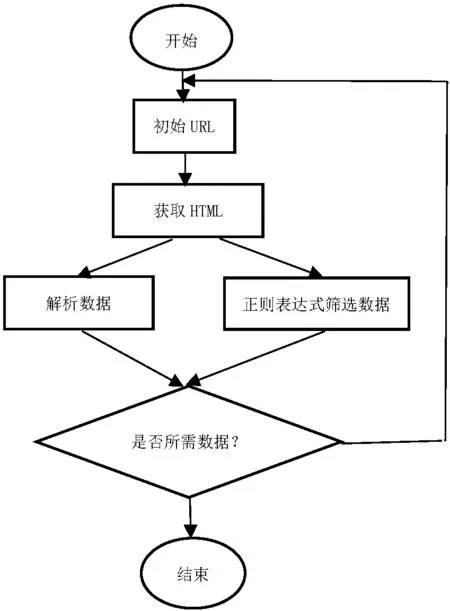
图1 系统具体框架
1 关键技术概述
1.1 网络爬虫
所谓网络爬虫[1-2],就是一段自动抓取互联网信息的程序,从互联网上抓取有价值的信息,就像一张蜘蛛网,顺着这张网爬行,每到一个网页就用抓取程序将网页抓下来,将内容抽取出来,同时抽取超链接,作为进一步爬行的线索。
1.2 Pythpn爬虫及架构
Python爬虫是按一定的规则自动爬取浏览器中信息的程序及脚本,也就是获取Web页面上自己想要的数据;爬虫架构主要由5个部分组成,具体如下[3]:
(1)调度器。相当于电脑的中央处理器(CPU),主要负责调度URL管理器、下载器、解析器之间的协调工作。
(2)URL管理器。包括待爬取的URL地址和已爬取的URL地址,防止重复抓取URL,实现URL管理器主要有3种方式,通过内存、数据库、缓存数据库来实现。
(3)网页下载器。通过传入一个URL地址来下载网页,将网页转换成一个字符,网页下载器有urllib包括需要登录、代理和cookier,requests。
(4)网页解析器。将一个网页字符串进行解析,可以按照用户的要求来提取出有用的信息。
(5)应用程序。指从网页中提取的有用数据组成的一个应用。
1.3 HTML和B/S模式
HTML不是一种编程语言,而是标识语言,用于创建网页,使用标签来描述网页的。
浏览器/服务器(Brower/Server,B/S)模式统一了客户端,将系统功能的核心部分集中到服务器上,简化了系统的开发、维护和使用。
2 爬虫案例实现
计算机二级是本科生阶段最基础的考试,为了能够从大量信息中提取出有关于计算机二级的基本信息,本研究通过具体的代码以及使用正则表达式来实现基本信息的抓取,供后期数据分析。
2.1 数据分析
首先,在I E浏览器中输入ht t ps://bai ke.so.com/doc/5309824-5544749.html,就会出现关于计算机二级的所有信息;其次,按“F12”键进入源代码调试窗口,此窗口中有许多“div”标签,标签中的内容就是待抓取数据。使用正则表达式来筛选。
2.2 具体实现过程及抓取结果
在进行数据抓取时,要先寻找标签或标识符,选取所需标签时要遵循3个原则:
(1)确定唯一能起决作用的标识。
(2)找最接近提取数据的标签。
(3)选取闭合的标签,进入源代码调试窗口之后,左上角就会出现类似于小箭头的按钮(),鼠标点击此箭头。移动鼠标,当鼠标指向基本信息时,源代码调试窗口就会显示包含基本信息的代码,接着就在Pycharm编译器中编写代码(关键代码:form urllib import request;class Spider();url=”…”;root_pattern=”…”;…)。当确定了“url”及“root_pattern”之后,能否提取到所有基本信息取决于在“root_pattern”的“div”标签中灵活使用正则表达式,正则表达式中字符集包括“a.[d D],b.[w 单词字符W],c.[s空白字符S]”等。使用“[s S]*”就可以抓取关于二级的基本信息,抓取结果如图2所示。

图2 抓取到的关于计算机二级的基本信息
2.3 结果分析
当爬取数据量较小时,执行速度快;当数据量较大时,会出现卡顿情况,因为系统要为每个线程分配资源,同时,要具备较好的网速以及较强的硬件,才会提升爬取速率。
3 结语
文章以对计算机二级的基本信息查询为例,介绍了一种基于Python爬虫的比赛信息查询及交流系统的程序设计,面对所爬取对象,文章还存在一定的缺陷,有进一步的优化空间。例如:爬取数据较大时,速度会变慢,可以通过缓存或多线程技术优化爬虫算法效率。文章Python爬虫技术的实现为后续研究工作奠定了一定的基础。
猜你喜欢
计算机仿真(2023年8期)2023-09-20
房地产导刊(2022年10期)2022-10-18
现代信息科技(2021年21期)2021-05-07
现代信息科技(2021年21期)2021-05-07
数码世界(2018年2期)2018-12-21
中国司法鉴定(2018年4期)2018-07-30
电子测试(2018年1期)2018-04-18
电子制作(2017年9期)2017-04-17
中国房地产业(2016年8期)2016-03-01
电子设计工程(2015年12期)2015-02-27
