
基于Deep-LSTM 的通信信号调制识别算法
2020-07-21 06:30邹海英
现代计算机 2020年16期
邹海英
(四川大学电子信息学院,成都610065)
0 引言
调制识别技术在频谱感知、电子对抗和防御等领域具有十分广泛的应用,因此一直是无线通信领域研究的热点问题。早期的调制识别方法主要是基于统计模式的识别方法[1-2],其特征主要靠人工提取。人工提取特征的方式,依赖人的经验,鲁棒性差,时间复杂度高,同时存在识别率偏低等问题。
近年来,随着深度学习的快速发展,无线通信研究者开始把深度学习用于信号调制识别。Adzhemov S S[3]提出使用神经网络对无线电数字信号进行调制识别的方法,该方法使用多层感知器作为分类识别器,可以使决策规则的形成过程自动化。但多层感知器在低信噪比下分类效果差,识别率低。Hui Wang[4]提出使用主成分分析对提取的循环谱特征做降维处理,再利用ANN分类器对数字调制信号进行分类识别,但该方法需要手工提取特征,时间复杂度较高。ZHIYU QU[5]提出使用时频分析,图像处理和卷积神经网络技术实现雷达信号脉内调制识别的方法,但该方法识别的调制类型偏少。Wu S 等人[6]提出一种基于深度学习网络的远距离通信信号特征的识别算法,但该算法的时间复杂度较高。Ahmed.K.Ali 等提出利用高阶频谱特征和基于神经网络属性的分类算法,但该方法是在AWGN 信道环境下进行的,不适用其他复杂的信道环境[7]。
针对上述调制识别算法存在的问题,结合LSTM在处理时序问题上面的优势,提出一种基于Deep-LSTM 的调制识别算法。该算法通过减少人工预处理和特征提取步骤,直接将输入信号通过Deep-LSTM 网络学习特征之后,后接Softmax 判决输出。
1 信号模型及识别流程
1.1 信号模型
在简单多径信道环境下,信号传输模型可以表示为:
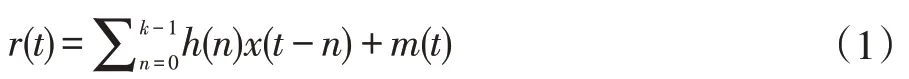
式中x(t)代表未知的调制信号,m(t)代表均值为0,方差为σ2的高斯白噪声序列,r(t)为接收到的调制信号序列,h(n)表示多径信道,n取值为0,1,2,3,…,K-1,h(n)的模型表达式为:

式中h0表示多径主径幅度增益,μ0表示主径相移。ht、θt、μt分别表示第t个多径幅度增益、多径延迟、相移因子。
1.2 调制识别流程
深度学习方法不需要对数据进行预处理和特征提取步骤,直接把数据送入网络输入层,中间经过网络挖掘数据特征信息,最后由网络输出层输出结果。因此使用深度学习方法对信号进行调制识别,可以有效地降低时间复杂度,提高信号调制识别准确率。基于深度学习的调制识别基本流程框架如图1 所示。

图1 基于深度学习的调制识别基本流程框架
2 长短期记忆网络
长短期记忆网络(LSTM)是RNN 的一种变体网络,主要由遗忘门、输入门、输出门和细胞状态4 个部分组成,其内部结构图如图2 所示。
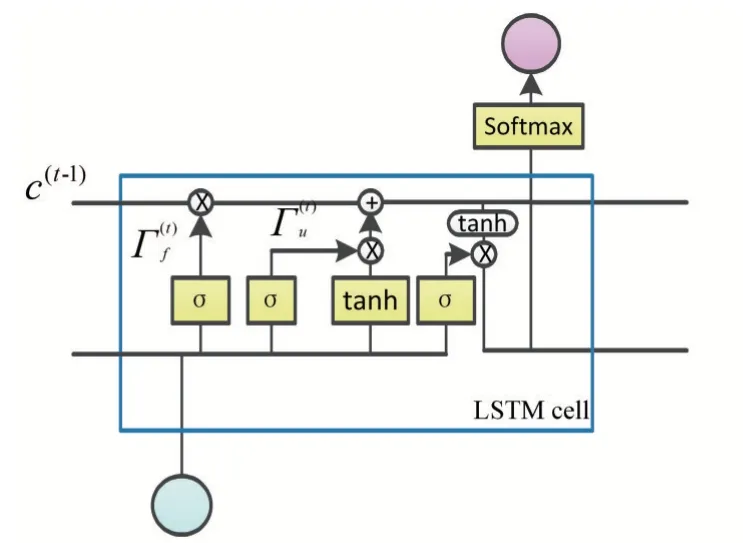
图2 LSTM内部结构图
遗忘门的作用是决定LSTM cell 第一步应该扔掉什么信息,其计算公式为:

其中σ(∙)表示sigmod 激活函数,wf表示遗忘门权重矩阵,bf表示遗忘门偏置向量,a(t-1)代表t-1 时刻LSTM cell 的输出,x(t)表示t时刻LSTM cell 的输入。
输入门的作用是决定在t时刻要新添加哪些信息到LSTM cell 中,其计算公式为:

其中wu表示输入权重矩阵,bu表示输入门偏置向量。
在LSTM cell 中第三层tanh 层的作用是生成一个向量,以用来得到要新添加的信息,其计算公式为:
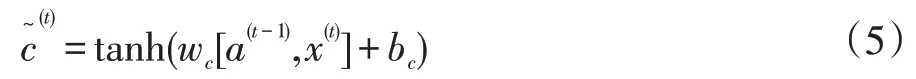
其中wc表示细胞状态权重矩阵,bc表示细胞状态偏置向量。
最终LSTM cell 将更新的细胞状态信息保存下来,其计算公式为:

输出门的作用得到LSTM cell 中的a(t),也即t时刻LSTM cell 的输出,再用a(t)通过Softmax 分类器得到最终的输出y(t)。a(t)的计算公式为:

式(7)中wo表示输出门权重矩阵,bo表示输出门偏置向量。
3 基于Deep-LSTM的调制识别算法
3.1 Deep-LSTM算法模型
LSTM 网络提取信号的调制特征是通过学习信号的调制信息,发现每条输入信号中每个样本点的时序关系,并将这些样本点的时序关系进行特征表达。当LSTM 网络的层数达到一定深度时,可以更有效地挖掘到信号的深层次特征,所以算法通过改进LSTM 网络设计了一个Deep-LSTM(Deep Long Short-Term Memory)神经网络用于对通信信号进行调制识别,其网络结构如图3 所示。Deep-LSTM 网络一共包含8 层,前4层由LSTM 单元组成,后3 层由全连接层组成,最后通过一个Softmax 层判决输出。网络中的激活函数为selu 函数,dropout 值为0.5。
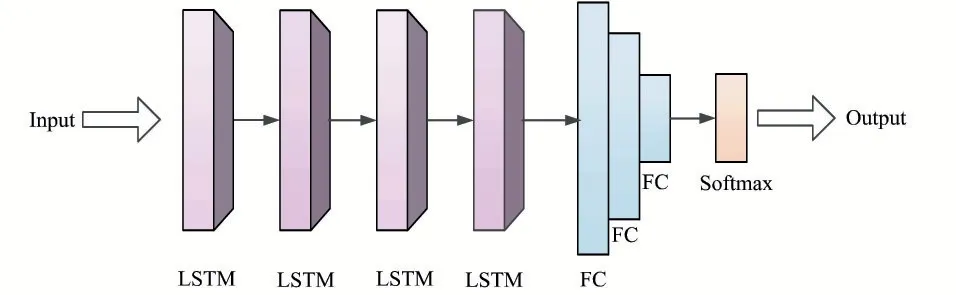
图3 Deep-LSTM网络结构
3.2 Deep-LSTM算法识别流程
Deep-LSTM 算法流程如图4 所示。首先对数据进行预处理;然后构建Deep-LSTM 网络,将网络初始化;接着输入训练数据对网络进行训练;再使用BP 算法对网络权值进行微调得到预测模型;最后把测试数据送入Deep-LSTM 预测模型中,使用Softmax 进行分类检测,输出识别准确率。
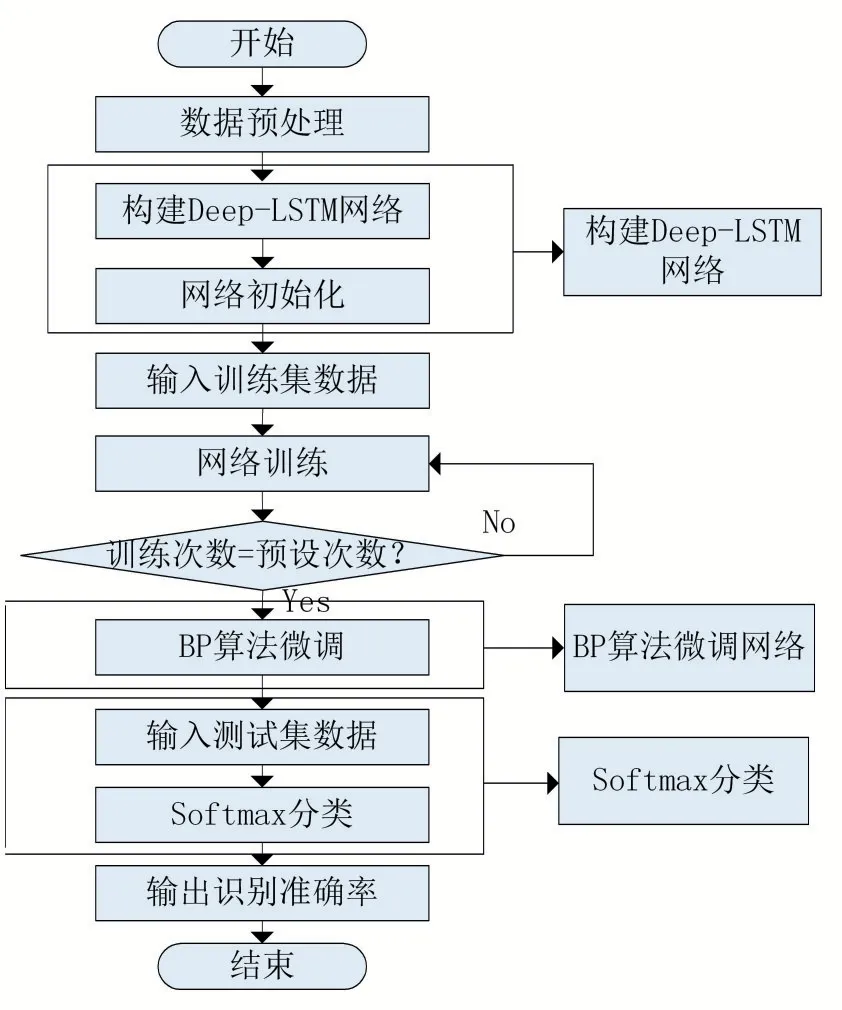
图4 Deep-LSTM算法流程图
4 实验结果及性能分析
4.1 实验数据
算法使用的实验数据为GNU Radio 信道模型生成的RML2016.10b 数据集[8]。该数据集包含10 种信号类型和20 种信噪比。10 种信号类型分别是8PSK,BPSK, CPFSK, GFSK, PAM4, QAM16, QAM64, QPSK,AM-DSB 和WBFM,20 种信噪比为-20dB 到18dB,步长为2dB。10 种信号均匀分布,总样本大小为1200000。使用python 中的numpy 程序库将数据集存储格式转换为Nexamples×Dimen1×Dimen2,其中Nexamples=1200000,Dimen1=2 表示每个样本包含I/Q 两路数据,Dimen2=128 表示每个样本包含128 个采样点数据,即RML2016.10b 数据集的存储维度为(1200000,2,128)。
4.2 评价指标
采用损失函数:交叉熵(Categorical Cross Entropy)和识别准确率(Accuracy)作为评价Deep-LSTM 算法分类识别性能的指标。

Categorical Cross Entropy 的计算公式为:式中n表示样本数目,m表示待分类数,xˆim表示期望输出,xim表示实际输出。
Accuracy 为识别准确率指标,其计算公式为:
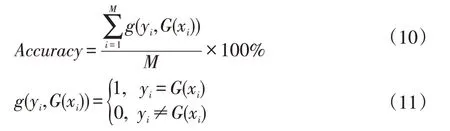
式(10)中M为样本总数,G(∙)表示网络模型预测函数,xi和yi表示第i个样本数据和对应的真实标签值。信号调制类型与对应的真实标签值如表1 所示。
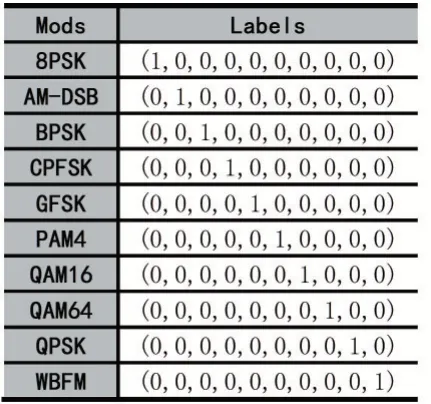
表1 信号调制类型与对应的真实label 标签值
4.3 实验结果
Deep-LSTM 算法使用RML2016.10b 数据集进行了实验仿真,得到信号集的平均识别准确率,如图5所示。

图5 信号集的平均识别准确率
由图5 可得随着信噪比从-20dB 到18dB 不断增加,识别率不断提高。当SNR≥5dB 时,平均识别率达到95%,说明算法的调制识别性能优越。
图6 为10 种调制信号在各信噪比下的识别准确率。由图可知,除了16QAM 和WBFM 信号,Deep-LSTM 算法对大部分信号都能很好地识别出来。

图6 各调制信号在各信噪比下的识别准确率
4.4 对比实验
为了进一步验证Deep-LSTM 算法识别性能的优越性,进行了以下对比实验。
实验一:Deep-LSTM 算法与参考文献算法[9]对比

表2 Deep-LSTM 算法与参考文献算法识别性能表
表2 为专家系统算法(基于集成循环矩的调制识别方法,分类器分别采用DNN、DTree、KNN、SVM、NaiveBayes)和Deep-LSTM 算法的调制识别性能表。由表可知Deep-LSTM 算法在各信噪比下的识别率均高于专家系统算法,特别是在低信噪比下算法的识别性能优势更明显。
实验二:LSTM 网络层数对识别性能的影响

表3 LSTM 网络层数对识别性能的影响
表3 为不同的LSTM 网络层数对算法识别性能影响的实验结果。LSTM 的网络层数直接影响Deep-LSTM 网络学习信号调制特征的能力;当LSTM 层数太少时,网络无法有效地学习和提取到信号的调制特征信息,导致算法识别性能低下;当LSTM 层数过多时,网络训练参数过多,训练的时间复杂度较高,也会影响算法的识别性能。由表可知Deep-LSTM 算法网络中LSTM 网络层数选取4 层时算法识别性能明显优于LSTM 网络层数为1,2,3,5 和6 时,故更加充分地说明Deep-LSTM 算法的可行性和有效性。
实验三:dropout 值对识别性能的影响
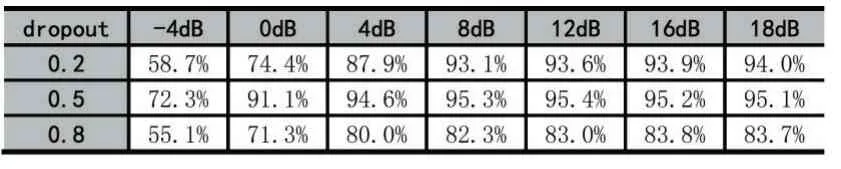
表4 dropout 对识别性能的影响

表4 为dropout 值对识别性能影响的实验结果。dropout 是为了防止模型过拟合的一个参数。由表可知,当dropout 值从0.2 增加到0.5 时,算法识别性能明显提高;当dropout 值大于0.5 时,算法识别性能明显降低了,这是因为dropout 值太大导致模型对样本数据的拟合能力下降了。实验四:batch_size 对识别性能的影响
表5 为batch_size 对识别性能影响的实验结果。batch_size 为批处理样本数量,其值的大小会影响网络模型的训练速度和优化程度,故选择合适的batch_size值才能使网络模型同时在时间和精度上达到最优。由表可知Deep-LSTM 算法设置batch_size=1024 时的识别性能明显比batch_size=512 和2048 更好。
5 结语
针对传统的基于统计模式的调制识别算法存在识别准确率低,特征提取困难、鲁棒性和泛化能力偏差等问题,提出了基于Deep-LSTM 的常规通信信号调制识别方法。仿真实验结果表明,在SNR≥5dB 时,可以达到95%的平均识别准确率,在识别性能、鲁棒性和泛化能力等方面都优于传统的特征提取算法。但算法目前还有以下需要完善的地方:①算法在SNR≤0dB 时,识别效果不佳,未来可以考虑在深度学习网络输入端先对信号进行降噪处理。②算法对16QAM 和WBFM 信号识别效果不佳,需要寻找新的算法来提高16QAM 和WBFM 信号的识别率。
猜你喜欢
现代仪器与医疗(2022年1期)2022-04-19
北京理工大学学报(2021年12期)2022-01-13
北京理工大学学报(2021年8期)2021-09-14
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
领导决策信息(2018年16期)2018-09-27
人大建设(2017年10期)2018-01-23
数学学习与研究(2017年3期)2017-03-09
