
基于随机森林的带宽预测算法研究与实现
2020-07-20 06:15:58李泽平王忠德黄初华
计算机工程与设计 2020年7期
王 烽,李泽平,林 川,王忠德,黄初华
(贵州大学 计算机科学与技术学院,贵州 贵阳 550025)
0 引 言
动态自适应流媒体技术(dynamic adaptive streaming technology)是一种结合了实时流式传输和顺序流式传输的分发传输技术,可以动态调节传输不同码率的视频。随着4G网络以及即将来临的5G网络的发展,大批移动智能终端的普及,大量移动应用的涌现,为移动互联网视频服务提供了良好的基础,流媒体技术在移动互联网中的应用也越加广泛。然而移动流媒体服务仍然面临着诸多挑战,例如在移动的网络环境下,用户在体验视频服务时往往伴随着画面卡顿、画质模糊、切换时间过长等问题。传统的解决方案是将低码率的视频分发给用户,降低了视频的服务质量(quality of service,QoS),导致用户体验质量(qua-lity of experience,QoE)较差,而且容易造成可用带宽的浪费。因此,如何更好地提升用户QoE成为目前流媒体服务迫切需要解决的关键问题之一。本文提出的算法可以预测移动客户端可用带宽大小,检测其网络状况,并根据用户的可用带宽分发最优码率的视频,提高用户视频观看体验,降低服务器压力。
1 相关工作
Ragil等[1]提出了一种基于参考信号接收功率(RSRP)和参考信号接收质量(RSRQ)来估计LTE网络负载的算法。Teerapat等[2]提出了LTE-A网络中基于多方位的手机底层参数验证具有更好的性能评估。GideonKutz等[3]提出了一种低复杂度的,能抵消来自相邻基站干扰的LTE测量算法。DuHaipeng等[4]基于HTTP自适应流(HAS)提出了差异化速率自适应算法,降低了比特率切换频率。Tsung-Han Lei等[5]提出了一种使用随机森林回归方法来预测虚拟化网络功能(VNF)的延迟分布的算法。Rana等[6]通过使用多机学习算法测量视频流来比较性能。结合文献[7]提出的LinkForecast预测框架,本文采集Android端的参考信号参数,使用随机森林处理数据预测带宽,并将其应用于流媒体分发系统中,实现自适应流媒体分发系统。
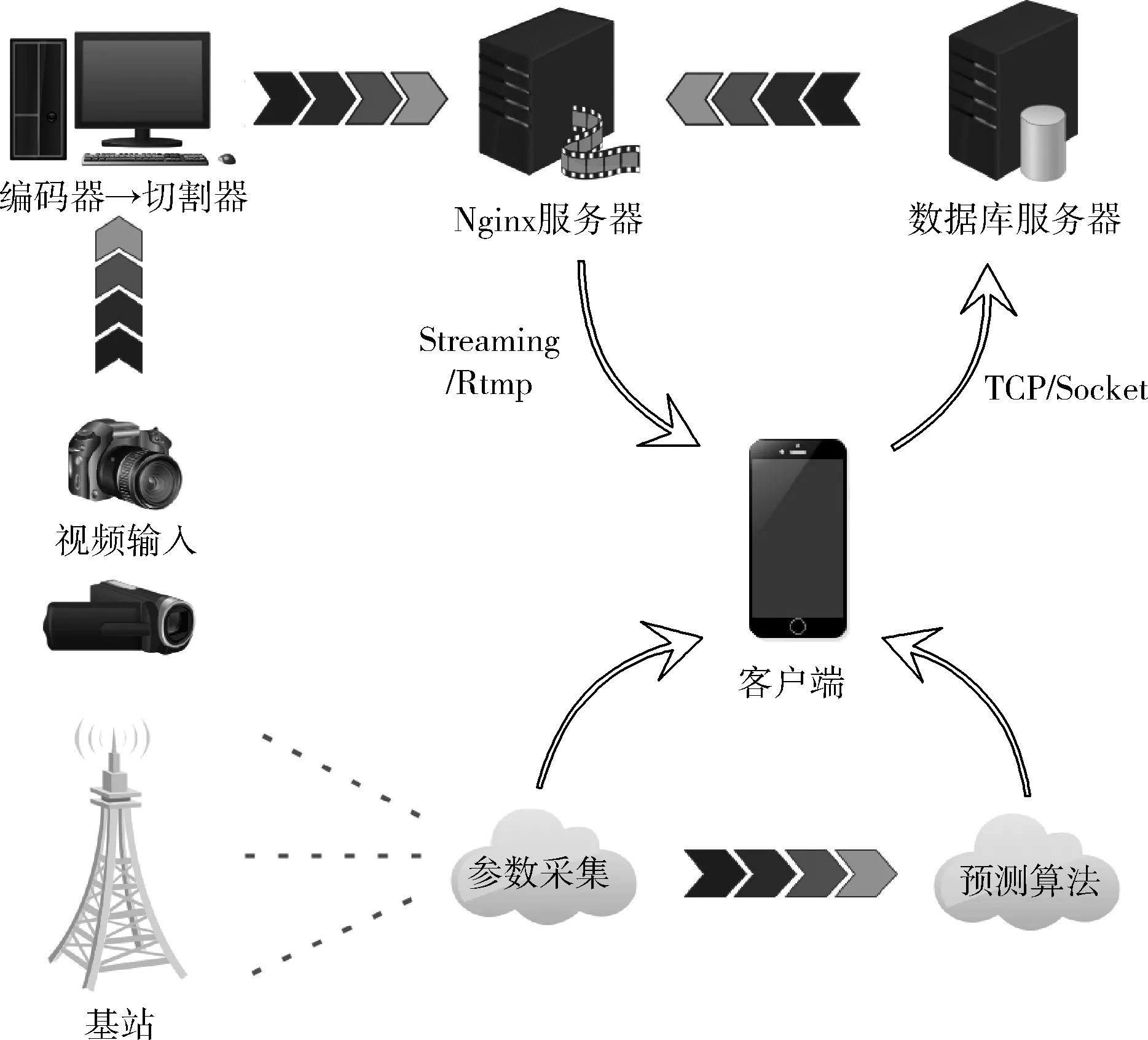
目前流媒体系统解决方案有很多种,其中Apple公司的HLS(HTTP live streaming)比较出色,HLS是一种基于HTTP的自适应流媒体协议,具备良好的兼容性,尤其适用于移动终端观看视频。HLS移动流媒体系统由3部分组成:服务器端、视频分发存储端和客户端。服务器端由编码器和流分割器组成。对源视频首先进行存储、编码和流处理,然后服务器端的切片器将媒体流分割为一串简短的流媒体文件和索引文件,通常,给定的URL(uniform resource locator)用于标识关于视频流的信息。视频文件需要使用FFmpeg转码为H.264格式,然后存储到服务器中等待用户的请求。视频文件被切片生成相应的M3U8索引文件,然后将其编码为具有多个不同码率的视频流,用以响应不同的需求服务,然而,如何准确地获得可用带宽则是一个有待解决的问题。本文提出的基于随机森林的MABP算法,可在动态网络环境下实时采集客户端的LTE参数并预测客户端可用带宽,使用该预测算法,实现了流媒体自适应技术,提高了用户QoE。
2 带宽预测算法
随机森林(random forest,RF)是由多棵决策树分类器 {T(x,θn)} 组成的一种集成机器学习策略,其中 {θn} 是独立同分布的随机向量,n为决策树分类器的数量,RF通过重采样法,从原始样本数据集x中有放回地重复随机抽取n个样本,生成一个新的训练样本集,之后按照训练样本集生成n个分类决策树,组成随机森林。根据决策树投票原则,将多个分类预测结果统一为最终结果,从而构成结果预测,预测架构如图1所示。RF对噪声数据和具有缺失值的数据具有良好的适应性[8]。
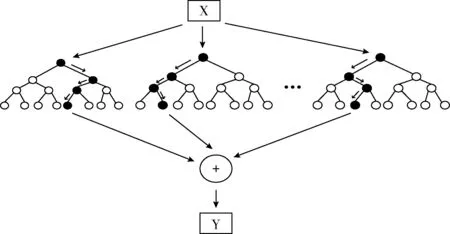
图1 随机森林架构
RF具备分析分类特征的能力,并且具备较快的学习速度,如今已被普遍应用于各种分类、预测、特征选择等问题。本文使用随机森林这种机器学习方法预测视频带宽,并通过HLS协议实现自适应流媒体技术。
以下步骤是对MABP算法的描述:
步骤1 手机端通过编写的LTEinfo程序采集底层参数,每隔2 min采集一次,每次采集20 s~30 s,将采集数据导出为.csv记录文件。
步骤2 加载数据样本,样本进行有放回随机(Bagging)采样,产生独立同分布子集,特征属性采样(每个节点采一次)。
步骤3 当训练集中存在缺失值,按C4.5权重分配。当测试集中有缺失值时,将节点分为两个分支tk,fk并根据tk,fk样本占比,对返回到该节点的结果进行重新计算。
步骤4 计算每个特征属性的Gini值,对节点进行排序并分配节点权重。
步骤5 按照决策树建立算法建立多棵决策树,为了防止决策树过拟合,采用控制Gini值变化大小以及结点样本数等方法。随机森林预测性能采用调参(如max_depth)进行控制。
步骤6 综合多棵树的预测结果,采用投票原则构成最终预测结果。
步骤7 通过TCP通信,将客户端预测数据打包发送给服务器。
步骤8 服务器解析数据,流媒体分发服务器根据HLS协议向客户端分发适宜码率视频,实现自适应流。
对于决策树,我们所获取的结果是训练样本数据集在该区间内最常见的分类类别。为了达到预测目的,很多情况下我们并不会只预测一个类别,而是预测一组类别及其出现的概率。因此我们在决策树中定义叶节点的不纯度来作为二元分割的标准,即一种可以在子集区域R1,R2,…,Rj度量目标特征同质性的方法。在结点m中,通过Nk个样本数据值表示一个区间内Rk类别出现的概率,第n个类别在第k区间下所出现的概率可表示为式(1)
(1)
其中, I(yi=n) 为指示函数,即如果yi=n, 则取1,否则为0。分裂节点处的特征属性使用Gini指数[9]来度量节点的误差率,定义为式(2)
(2)
根据节点误差率对样本进行分割,最后将样本分成不同的子节点,每个叶节点对应一个预测结果。由此提出算法1决策树的建立。
算法1: 决策树建立算法
输入: 原始样本X, 样本数量N, 特征属性数量M
输出: Decision Trees
(1) X→forbagging
(2) //采用bagging抽样循环处理X
(3)endfor
(4)whileextracting ntry(ntry=N)→Xtraindo
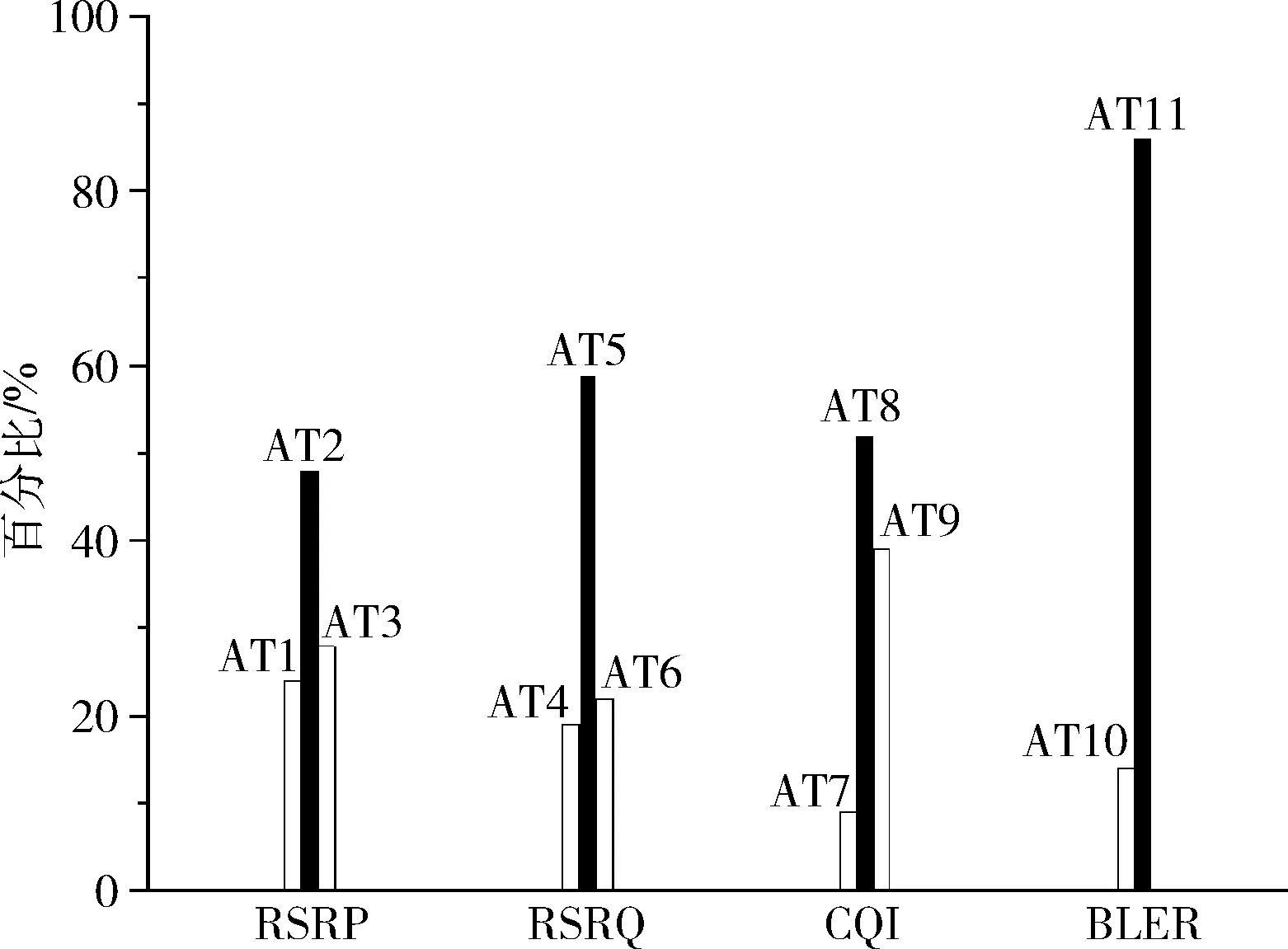
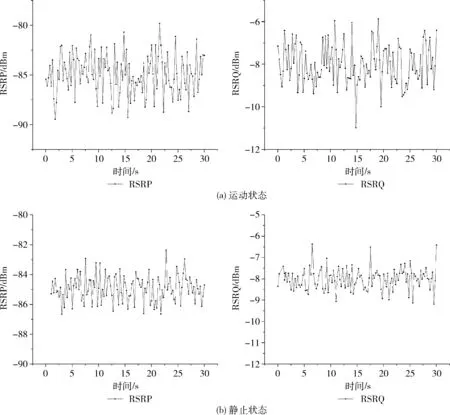
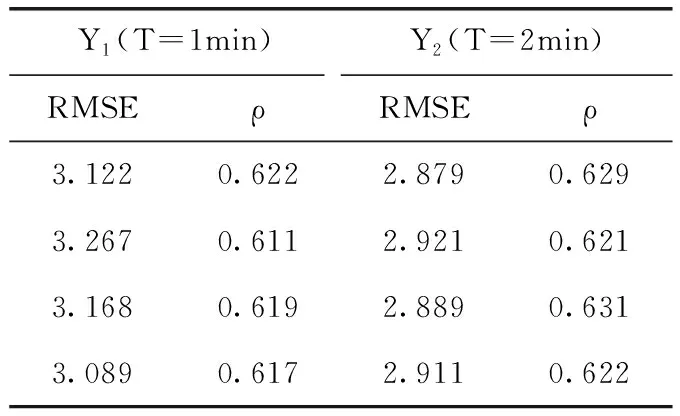
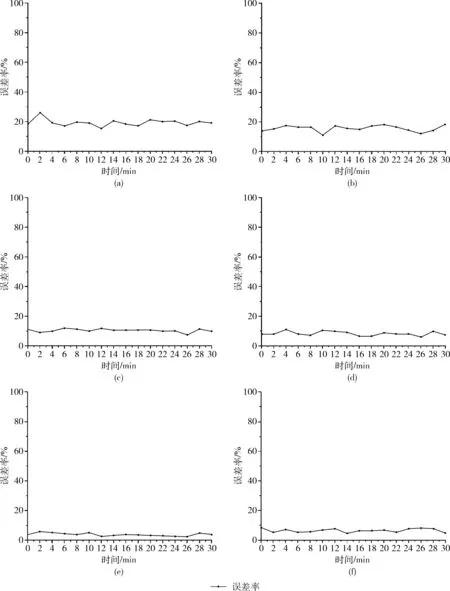
(5) M→mtry(mtry< (6) //随机选取mtry个属性 (7) mtry→the best node (9)endwhile (10)for(itree=0; 1 (11) //按照最优属性进行节点分裂,生成决策树 (12)endfor endProcedure 为保证RF随机性,采用自汇聚法(Bagging)和自抽样法(Bootstrap),Bagging每次从原始数据集中有放回的随机抽样构成自助训练集,这个过程独立重复B次,之后,每一个新的test(测试集)都被独立用于训练一棵决策树。Bootstrap是从大小为N的原始数据集中随机选择n个样本组成一个新的test集,该过程独立重复B次,统计量的估计值定义为θ,如式(3)所示 (3) RF由若干个单决策树组合而成,从而能对测试样本进行分类,比单个分类器具备更好的分类能力和泛化效果。通过对不同决策树进行的多个独立预测进行投票,得到最终预测结果。用于训练单颗树的样本是从训练数据集Xtrain中随机选择的,一些元组可能被选择多次,而有些元组可能永远不会被使用,这反映了随机森林的随机性。本文带宽预测算法如下。 算法2: 带宽预测算法 输入: 样本sample, 训练集Xtrain, 测试集Xtest 输出: K棵树和预测结果L (1)foralli = 1 to Kdo (2)whilej ≤ Ndo (3) rowsample= rowsample+ Select(Xtrain) (4) j + + (5)endwhile (6)whilestop condition not truedo (7) colsample= Select(rowsample) (8) split_Attribute = min{Gini(colsample)} (9) //分裂属性由最小Gini值确定 (10) tree = AddNode(split_Attribute) (11)endwhile (12) leaf_node ← node (13)endfor (14)foralli = 1 to Kdo (15) li= Ti_Predict(Dtest) (16) L = MostCommon(li) (17)endfor endProcedure 在文献[7]的基础上研究带宽实时预测算法,并编写程序完成对移动端所需参数(分别为RSRP、RSRQ、CQI、BLER和Handover Events)的调用,使用随机森林算法实现实时带宽的检测。参考信号接收功率(reference signal receiving power,RSRP),是在单个资源块(resource block,RB)中测量的功率,它不包含任何来自相邻单元的噪声或干扰,其单位为dBm。参考信号接收质量(refe-rence signal receiving quality,RSRQ)是评价接收信号质量的一个重要参数,其定义如式(4)所示,接收信号强度指示(received signal strength indication,RSSI)定义为在资源块(RB)中接收的总功率。使用RSRP和RSSI计算RSRQ,在移动网络中作为参考信号进行切换决策。N用于计量RB的数量 (4) 频道质量指标(channel quality indicator,CQI)是一个载有质量信息的指标参数,是网络中用户终端传输的反馈信息。CQI可以反映UE(user equipment)的通道质量,无线信道越好,UE报告的CQI越高。CQI用于确定调制格式、数据包类型、预编码矩阵类型等重要参数的值,这些参数直接影响向用户传输的吞吐量。阻塞错误率(block error rate,BLER)定义为目标用户接收到的错误块除以块的总数,一般BLER不大于10%,否则链路必须切换到较低的速度。交接事件(Handover Events)发生在用户移动过程中,从一个服务区域切换到另一个服务区域时会使带宽下降。 所需参数信息由Android API调用得到,首先将事件接收器注册到操作系统,当一个信号发生变化事件,Android核心模块会向app中的事件接收器发送一个事件,它将捕获事件并将该信号的当前值基于时间戳记录下来,之后建树组成随机森林进行训练预测。表1为参数不同值对应的带宽区间。 表1 预测数值对应 由表1可知,当采集的数据处于不同区间时,对结果预测将会产生不同影响。这里我们把BandWidth划分3个区间定义为3个等级:poor(0~1*104kbps)、mid(1*104~2*104kbps)、good(2*104~4*104kbps)。建树过程中,每一次节点切分都涉及到计算切分后的均方误差(mean-square error,MSE),通过计算最小均方误差(MMSE)确定进行建树时所需的特征属性(Attributes),计算公式如式(5),式(6)所示 MMSE=minf,v{mine1∑xi∈R1(yi-e1)2+ (5) (6) 其中,f和v表示特征和特征值,xi和yi是样本数据的输入和输出,R1和R2是该节点切分后的左右子树集,e1和e2表示切分后左子树和右子树的平均值。误差越小,表示切分的效果越好,最终提取为12个特征属性[10],见表2。 表2 特征属性 因为交接事件(Handover Events)发生越多,产生的带宽减少事件就会越多,所以当交接事件越少时,链路可用带宽越大,所以AT12无具体参考区间,其值越小越好。图2 为采集的一个原始样本集下各个特征属性的比例分布图,图3为运动和静止场景下的部分数据具体值采集结果。 图2 特征分布 样本数据每隔一段时间采集一次,为了确定最佳间隔时间T,以保证样本与手机真实性能具有匹配性,我们使用均方根误差(root mean square error,RMSE)与相关系ρ进行验证[11],定义如式(7)所示 (7) (8) (9) 表3列出了计算后的结果对比,从多组数据结果比较来看,样本Y2(T=2min)具有更好的匹配性,因为它的相关系数ρ更高,均方根误差(RMSE)更低,所以综合下来将测量间隔时间T定为2 min,即2 min作为一个测量周期。 构建一个基于HLS协议的流媒体系统,视频数据的输入在服务器端完成,然后使用编码器压缩和编码原始数据,之后,视频被切片并分发到内容服务器。流分割器(stream segmenter)负责将编码文件转码为不同的码率或分辨率,并将它们分成连续且相等的ts片段,并静态生成索引文件存储在服务器上。例如用编译好的FFmpeg软件切 图3 采集数据 表3 结果对比 片生成m3u8索引文件,然后部署到基于Nginx搭建的WEB服务器上进行分发。客户端通信方式采用基于TCP通信模型的Socket通信,通信时序如图4所示。Socket在建立连接时可以直接进行数据传输,可以实现主动推送信息,而不是每次都由客户端向服务器发送请求[12]。系统架构如图5所示。 图4 通信时序 实验环境为Intel CoreTMi5 3.2 GHz CPU,16 GB RAM,Windows7 OS,Oracle VM VirtualBox5.2.18,Android Studio3.4,PyCharm2018.2.4,Android手机一部。使用Speedtest.net的测试值作为对比参照,验证本算法的有效性。Speedtest.net是ookla公司提供的业界知名的网速测试方案,具有独立性和准确性特点。 实验设置不同的max_depth(树的最大深度)和n_estimators(森林里的树木数量)参数值来控制随机森林的预测性能[13],分别为方案a~方案f,见表4。 本文算法预测值为Bp,对照值为Br,预测值与对照值之间的误差记为Et,绝对误差计算如式(10)所示 (10) 图5 系统架构 表4 参数控制方案 如图6所示,x轴为时间序列,按照T=2min为一个测试节点,y轴为预测值与对照值的绝对误差率。通过使用同一组样本在a,b,c,d,e,f这6种方案中的预测表现进行对比,由图可知,方案e在所有比较方案中表现最佳,具有最低误差率。当n_estimators较小时,随机森林的分类误差较大,性能也较差。当增加决策树数量时也会增大随机森林的构建时间,增大开销,导致预测结果有所偏差。 图6 对比 本文在Chao等[7]的LinkForecast框架基础上,提出了基于随机森林的MABP算法。该算法通过采集LTE参数,计算最小均方误差,将LTE参数分为12个特征属性;然后结合RF算法预测客户端手机的可用带宽,最后使用均方根误差与相关系数计算样本的相关性,确定了算法的预测周期。最终实验结果表明,该预测算法能充分利用采集的LTE参数实现实时带宽预测,为搭建的HLS流媒体系统提供自适应流依据,优化视频分发,提升用户视频观看体验。并且本文的预测算法不会增大网络负载,使我们的预测结果具有匹配性。优化算法,减小系统开销将会是我们下一步将要研究解决的问题。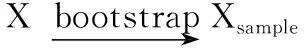
3 数据采集

mine2∑xi∈R2(yi-e2)2}
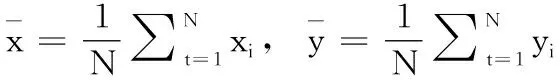
4 实 验


5 结束语
猜你喜欢
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20电子制作(2018年16期)2018-09-26 03:27:06传媒评论(2018年4期)2018-06-27 08:20:24传媒评论(2018年4期)2018-06-27 08:20:16电子测试(2018年10期)2018-06-26 05:53:34作文大王·笑话大王(2017年1期)2017-02-21 16:08:53作文大王·笑话大王(2016年10期)2016-10-18 14:58:58作文大王·笑话大王(2016年7期)2016-08-08 11:28:43中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04作文大王·笑话大王(2016年2期)2016-02-24 11:27:15
