
基于深度学习的漏洞检测中样本集预处理的方法研究
2020-07-20 05:56王于叶张皓天许泽遥
无线互联科技 2020年9期
王于叶,张皓天,许泽遥
(南京邮电大学,江苏 南京 210023)
漏洞检测技术是保障软件安全性的主要手段,是软件安全领域不可或缺的一环。为了提升漏洞检测的工作效率,将机器学习中具备良好性能的深度学习算法和漏洞检测技术相结合已逐渐成为一种研究的趋势。对于深度学习而言,选用特征明显的样本集往往会对深度学习的结果产生决定性影响,如何处理漏洞样本才能突出其特征性是一个至关重要的问题。
根据分析对象的不同, 漏洞检测技术可以分为基于源码的漏洞挖掘技术和基于二进制代码的漏洞挖掘技术两大类[1]。两类检测技术对被检测对象也采用了不同的处理方式。
传统的源代码漏洞检测技术对于被检测对象,即源代码的处理主要集中在对其语法语义的分析上。控制流分析技术就是直接从代码中收集程序的各种语义信息,并通过相关算法推测程序的可能执行路径,例如DREAM[2]算法。2012年提出的在代码中提取抽象语法树[3]来分析漏洞的新方法,在后来基于Bi-LSTM的源代码漏洞检测[4]中被用作样本预处理。
针对二进制代码的漏洞检测技术对于被检测对象,即二进制程序的处理更侧重于对程序执行漏洞可疑行为的分析。以动态污点跟踪、模糊检测为例,动态污点跟踪技术是指在程序中人为地引入被标记的污点数据并执行,通过跟踪其运行路径找出漏洞。模糊测试技术通过构造大量畸形样本数据交由目标程序处理从而遍历程序状态空间。
无论是针对源代码,还是针对二进制代码,现存漏洞检测技术以及它们对检测对象的分析处理方式都各自存在不足。针对源代码的检测,由于不断扩充特征库或词典,造成了检测的结果集大、误报率高[5]。针对二进制代码的检测,以汇编语言为例,由于缺少函数、变量、变量类型等信息,不容易找到分析点,效率不高,难以实现自动化发现[5],易导致漏报。
当两类漏洞检测技术与深度学习算法结合时,其缺陷客观反映在深度学习的准确率(precision)和回归率(recall)上。
文章提出了一种在运用Bi-LSTM深度学习对二进制程序进行漏洞检测,基于中间语言VEX IR,针对作为学习样本的二进制程序进行处理的方法,其基本思路如下:
将二进制可执行程序转换为一种兼具二进制代码和源代码部分特性的中间语言代码,并利用这种特性,从程序动态执行过程和代码的语法语义两个维度上对样本代码进行分析,结合Word2Vec等字符处理工具,将分析后的代码转换为抽象的二维向量序列,将得到的数据作为深度学习的样本集,从而在漏洞检测的误报率提升不明显的前提下降低漏报率。
1 方法具体实现
1.1 中间语言生成
VEX IR是由二进制分析框架Valgrind[6]生成的一种中间表示式(IR)。二进制程序转译为VEX后被分成许多小的代码块“超级块”,每个代码块中包含许多指令,这些指令具有语句(Statements)和表达式(expressions)两种类型,语句一般表示寄存器写入、缓存和变量赋值等操作;表达式一般表示算术操作、读取内存和常量表示等操作。此外,还包含函数名、变量名等汇编语言中不具有的语义信息。
以一条汇编指令addl %eax, %ebx对应的VEX代码为例:

因此,VEX IR所包含内存读写和算术运算等指令不仅能够建立起二进制程序数据流的静态分析,确定函数输入与输出之间的联系,而且实现了嵌套的二进制控制流图,能够提取出程序的逻辑语义信息。
1.2 语法语义维度的分析处理
对于经过输出的VEX IR代码,基于其语法语义的表达特性,以一个“超级块”为最小单位,根据漏洞特征存在的层面先后对其进行了函数名和语句跳转关系的特征化处理。
对函数名进行特征化处理,是因为VEX IR代码中的一些语句记录了每个“超级块”所在函数的函数名和地址信息,而这对判断和函数名有直接关系的漏洞(危险函数漏洞)十分有利,因此编写自动化脚本建立函数地址-函数名关系对照表十分必要,如图1所示。
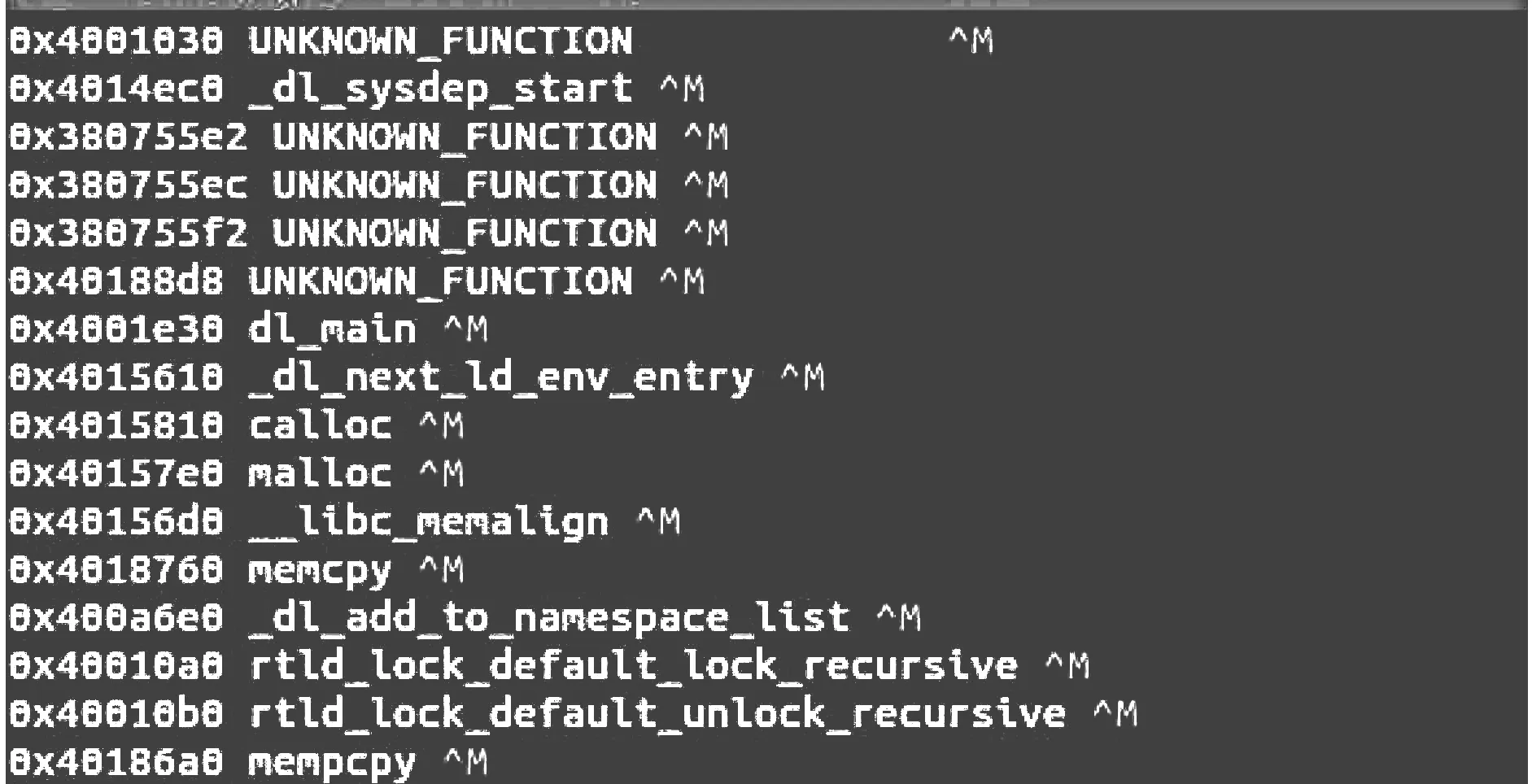
图1 函数地址对照表(Vexfunction工作输出)
随后,对其中的已知函数(如memcpy等)进行直接数字编号,于是尽管同一函数在不同程序中拥有不同的函数地址,也能为其添加相同的数字标注。对于未知函数,采用二进制比对工具Bindiff,对其进行一定的修改,使其能够对比VEX IR中不同未知函数的内容,将相似率超过85%的未知函数定义为同一函数,并对其进行数字编号。
为了体现和函数名没有直接关联的语法特征,通过提取超级块中的跳转语句,分析出程序语句的执行顺序,并按照每个超级块在程序流程中被调用的先后关系,使用二进制数对其编码。对于函数名或跳转关系的编码,构成二维向量的纵坐标。
1.3 程序执行维度的分析处理
对于二进制程序执行维度的特征化处理,参考了Gascon等[7]学者关于使用行为特征图进行机器学习分类的算法研究,以每条指令为最小单位,通过判定运行时刻的大量行为特征图之间的相似之处,来体现恶意行为。以简化VEX IR为目的,从中提取出关键的算术和逻辑操作以及运行时内存空间发生的变化,最终选取了1 100个保留了必要信息的相关操作指令作为VEX IR的程序执行过程描述。
对于一个IR块,提取其关键指令并将其序列化,形成如[IMark,WrTmp,16Uto32,GET:I32,PUT,…]的形式。将这个文本向量视为具有含义的“句子”,其含义由向量的元素及其序列组成。将这些文本向量元素唯一地映射到一个整数,将这些整数充当“标记”,唯一地标识每个文本元素,以此构成二维向量的横坐标。
二维向量的序列化过程中,使用Word2Vec工具来实现,并使用主成分分析(Principal Component Analysis,PCA)将结果投影到二维平面,如图2所示。由数字表示的VEX指令的平面位置将成为深度学习的样本集。
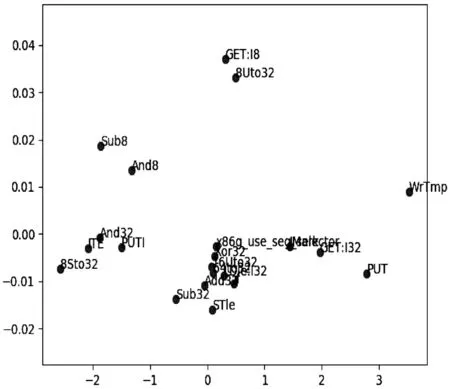
图2 向量投影
2 方法性能检验
先将二进制可执行文件样本用ida转化为汇编语言,仅进行程序执行维度序列化的处理,将完全相同的二进制可执行文件样本用valgrind处理成VEX IR后,采用二维序列化处理方法进行样本集预处理,作为Bi-LSTM的输入,而后两种方法对于测试集的预测结果对比如图3所示。
从漏洞预测得到的结果数据可以看出,Vulnerable一栏的召回率相较单纯,针对汇编语言的学习而言,从0.33增长到了0.77,有了明显的提升。而深度学习的准确率仍然维持在较高水平,为0.96。由此数据可以证明,文章提出的方法成功降低了二进制漏洞检测的漏报率。

图3 针对不同代码的深度学习检测结果
3 结语
经验证,文章基于中间语言的代码特征提出的一种深度学习样本集预处理的方法,成功使原本基于纯二进制代码的漏洞检测技术具备了源码检测的一些优势,最终实现了在基本不增加误报的前提下减少漏报率。但该方法仍存在漏报率大于误报率等二进制检测的固有缺陷,尚有较大的发展空间。
猜你喜欢
计算机仿真(2023年8期)2023-09-20
今日农业(2022年13期)2022-09-15
中等数学(2021年8期)2021-11-22
现代信息科技(2021年21期)2021-05-07
数学大王·低年级(2019年10期)2019-11-25
中等数学(2019年4期)2019-08-30
中国司法鉴定(2018年4期)2018-07-30
中国卫生(2016年5期)2016-11-12
中国房地产业(2016年8期)2016-03-01
中国卫生(2015年12期)2015-11-10
