
一种注意力增强的自然语言推理模型
2020-07-17 07:35李冠宇张鹏飞贾彩燕
计算机工程 2020年7期
李冠宇,张鹏飞,贾彩燕
(北京交通大学 a.计算机与信息技术学院; b.交通数据分析与挖掘北京市重点实验室,北京 100044)
0 概述
自然语言推理也称为文本蕴涵识别[1],是自然语言处理中的一项重要任务,其主要关注的问题是由前提文本推断出假设文本。此项任务需要理解前提和假设文本之间的语义相似性来判断它们之间的关系,包括蕴涵、矛盾和中立3种关系[2-3]。
自然语言推理任务通常被视为一种关系分类任务,其在较大的训练集中学习前提和假设文本之间的关系,在此基础上预测新的前提和假设文本对之间的关系。现有自然语言推理模型大致分为基于特征的推理模型[4]和基于神经网络的推理模型[5-6]两类。基于特征的推理模型主要通过句子的非词汇特征(两个句子长度差的绝对值)和词汇化特征(如n-gram特征)的学习来表示前提与假设文本之间的关系类别。近年来,端到端神经网络模型在机器翻译、情感分类等自然语言处理任务中表现较好,受到大量学者的关注。
虽然将深度学习引入自然语言推理任务中,在现阶段取得了较好的效果,但仍存在不足,如传统的双向LSTM网络[7]忽略了重要单词对于句子向量的贡献,每个单词的相同权重造成句子表征不够准确,
以及前向向量与后向向量被简单地连接到一起,未考虑到每个方向对于句子语义表示的重要程度,从而造成句意缺失。
针对以上问题,本文在ESIM模型双向LSTM网络中引入注意力机制与自适应的权重计算层,分别刻画不同单词和不同方向对于句子向量的贡献度,构建一种注意力增强的自然语言推理模型。
1 相关工作
对于自然语言推理,基于特征的推理模型多为基于统计的方法,对文本的语义刻画不够深入。将深度学习引入自然语言推理领域,端到端深度学习模型取得了较好的效果。
将基于神经网络的自然语言推理模型分为句子编码模型和句子交互模型两类,两种模型的架构如图1所示。

图1 两种自然语言推理模型架构
句子编码模型[8-9]利用预先训练好的词向量来进行编码,将前提文本与假设文本分别编码为文本向量[10-11],两个文本向量相连之后再利用全连接层来学习两个文本之间的语义关系,主要架构如图1(a)所示。在此类模型中,LSTM[12](Long Short-Term Memory)网络及其变体GRU[13](Gated Recurrent Units)以及双向LSTM能够学习句子内部的长距离依赖关系,因此常被用于句子编码。文献[8]提出了一种通用的自然语言推理任务的训练方案,并对比了LSTM、GRU、最大(平均)池化双向LSTM、自注意力机制网络以及分层的卷积神经网络等编码架构。实验结果表明,采用最大池化层的双向LSTM网络具有最佳的性能。文献[9]设计了一个分层的双向LSTM模型(HBMP)进行句子编码,该模型采用上一层双向LSTM的参数初始化下一层双向LSTM的参数进行信息传递,比使用单一的双向LSTM层效果更佳。文献[7]则将单层双向LSTM网络替换成多层双向LSTM网络来加强模型的句子编码能力。
句子交互模型[14-16]与句子编码模型架构相似,首先学习句子对的向量表示,使用更新的单词向量表示计算两个句子之间的相似度矩阵,然后利用相似度矩阵进行句子向量的增强表示,最后做出分类判断,主要架构如图1(b)所示。与句子编码模型相比,句子交互模型能够利用句子对之间的文本相似性,并且能够捕获前提文本与假设文本之间的潜在语义信息。文献[17]将注意力机制引入机器翻译任务中,同步完成翻译和文本对齐任务。文献[18]设计了一个成对词交互模型(PWIM),充分利用了词级细粒度信息,取得了较好的效果。文献[15]提出了双向多视角匹配模型(BiMPM),对比了多种不同注意力机制的匹配策略。文献[12]提出了ESIM模型,利用两层不同的双向LSTM分别进行文本语义编码。实验结果表明,句子交互模型,特别是ESIM模型,优于上述的句子编码模型。
尽管ESIM模型表现优异,但该模型并没有考虑双向LSTM层中每个单词的不同贡献。因此,将注意力机制引入双向LTSM层将有利于刻画词的重要性。已有的双向LSTM层对于前向和后向向量的重要度不加区分,传统的双向LSTM层中只是将它们简单地连接到一起,但前向与后向向量都代表着信息的流动方向,因此,有必要考虑每个方向(向前或向后)对字向量编码是否具有不同的重要性,从而自适应性地将两个方向向量以不同的权重联合在一起。本文使用ESIM模型作为基线,在每个双向LSTM层后添加一个词注意力层,并使用自适应方向权重层来学习前向和后向向量对于词向量的贡献度,将此注意力增强的双向LSTM模型命名为双向aLSTM模型,并将修改后的ESIM模型命名为aESIM模型。
2 aESIM模型框架
假定有2个句子,前提文本p=(p1,p2,…,plp)与假设文本q=(q1,q2,…,qlq),任务目标是预测它们的关系标签y。
2.1 ESIM模型
ESIM模型主要由输入编码层、局部推理层、局部推理增强层以及分类层4个部分组成,模型架构如图2所示。

图2 ESIM模型架构
在输入编码层中,ESIM模型利用预训练的词向量(如GloVe向量[20])在双向LSTM层中对输入的句子对进行编码:
(1)
(2)
其中,(p,i)代表句子p中的第i个词,(q,j)代表句子q中的第j个词。
(3)
(4)
(5)

(6)
(7)
在分类层中,ESIM模型并未用到文献[14]提出的向量求和的方法,而是提出同时使用最大池化与平均池化的方法,并将拼接的结果送入最后的多层全连接层进行最终分类。
2.2 aESIM模型
本文基于ESIM模型提出了注意力增强的自然语言推理模型aESIM。类似于ESIM模型,aESIM模型仍包含编码层、局部推理层、局部推理增强层以及分类层4个主要部分。ESIM模型与aESIM模型的区别在于将ESIM模型中的两层双向LSTM层替换为两层双向aLSTM层。如图2所示,ESIM模型中的虚线框将被替换为双向aLSTM层,在右上角用实线框标出,双向aLSTM层的细节展示如图3所示。

图3 基于方向注意力机制的双向LSTM结构

(8)
(9)
aLSTM模型在传统的双向LSTM模型中加入了词注意力层以及自适应方向权重层来增强模型句子表征能力。
2.2.1 词注意力层
在一个句子中,并非所有单词对与句向量的贡献都是相同的。类似于文献[5]的方法,本文引入了相似的注意力机制,它是一项衡量单词重要度且十分有效的工具。在词向量经过双向LSTM层之后,通过添加词注意力层来计算词的重要度以增强模型的语义表示能力。
uil=tanh(Wfil+b)
(10)
(11)
sil=αil*fil
(12)
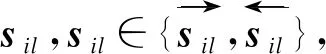
2.2.2 自适应方向权重层
在传统的双向LSTM层中,每个单词的前向与后向向量被认为在生成最终词向量时有着相同的权重,因此,前向和后向向量被简单地拼接在一起,但这并不能体现信息流动方向的差异性。对一个单词,前面的单词与后面的单词在不同的方向上是相反的,而不同方向的词向量对于词向量的贡献度可能是不同的。因此,本文设计一个新的自适应方向权重层来学习不同方向的词向量对于最终的词向量的贡献度。
(13)
其中,W*与b*表示权重矩阵以及偏置项,g表示非线性变换,[·]表示连接操作。在训练过程中,所有的参数都可以进行更新。利用式(14)和式(15)可以得到整个句子的向量表示:
(14)
(15)
本文将添加了词注意力层以及自适应权重方向层增强的双向LSTM层的网络称作双向aLSTM。双向aLSTM层被应用到ESIM模型中替换其中的双向LSTM层。
3 实验与结果分析
3.1 数据集
本文在SNLI、MultiNLI[19]和Quora 3个公开自然语言推理数据集上进行实验。
1)SNLI数据集共包含了共计570 152个句子对,其中训练集包含5.49×105个句子对,验证集与测试集各包含1×105个句子对。每一个句子对都有唯一的一个类标签(“蕴涵”“中立”“矛盾”以及“-”)。标签为“-”表示句子对之间没有明确的可分类结果,因此,在训练,验证以及测试中移除了这些关系不明确的句子对。
2)MultiNLI语料库是由源文本蕴含信息注释的4.33×105句子对组成的众包集合。该语料库以SNLI语料库为模型,但不同之处在于涵盖了一系列口语和书面文本,并支持独特的跨类型生成评估。
3)Quora数据集包含4×105个问题对。这个语料库旨在判断两个句子是否具有相同的语义关系来判断两个文本是否要表达相同的意图。
3.2 实验参数设置
本文使用验证集进行模型选择与参数调试。aESIM模型的超参数设置如下:实验使用Adam算法作为模型的优化方法,第1个动量设定为0.9,第2个动量设定为0.999。初始化学习率设置为0.000 5,训练批量大小设置为128。所有双向aLSTM层以及单词嵌入的隐藏状态的维度设置为300。实验使用了非线性函数f=selu,因为它具有比Relu更快的收敛速度。失活率在训练过程中设置为0.2,实验使用预训练的300D的GloVe向量来初始化词嵌入。未登录词用高斯随机函数来随机初始化。该算法完全使用Keras框架实现,并在TITAN Xp显卡上进行训练。
3.3 实验结果
本文在SNLI数据集上比较多个方法性能,如表1所示。其中,第1行方法是传统特征工程模型,第2行~第6行方法是句子向量编码模型,第7行、第8行方法是句子交互模型,第9行、第10行方法是基准模型ESIM以及本文提出的aESIM模型。ESIM以及aESIM模型是基于Keras实现的。对于MultiNLI数据集,主要用到的基准模型有CBOW、双向LSTM、PWIM模型以及ESIM模型,结果如表2所示。Quora数据集的结果如表3所示。对于每一种方法,本文均使用准确率来进行评价。

表1 不同模型在SNLI数据集上的准确率

表2 不同模型在MultiNLI数据集上的准确率

表3 不同模型在Quora数据集上的准确率
从表1~表3可以看出,aESIM模型在SNLI数据集上达到了88.1%的准确率,相比于ESIM模型上提升了0.8个百分点,在MultiNLI数据集上相比于ESIM提升了0.5个百分点,并且表现出了最好的性能。在Quora数据集上,达到了88.01%的准确率,对比于ESIM模型提升了1个百分点。由此可以得出结论,本文提出的aESIM在3个数据集上都表现出优于ESIM的性能,表明引入该注意力机制与自适应方向权重的双向LSTM模型具备更强的句子编码能力。
3.4 注意力机制可视化
为了更直观地展示双向aLSTM的提升效果,本文进行了可视化展示,如图4~图6所示。从SNLI测试集中抽取了一个前提文本以及3个相对应的假设文本。其中,前提文本是“A woman with a green headscarf,blue shirt and a very big grin”,3个假设文本分别为“the woman has been shot”“the woman is very happy”“the woman is young”,对应的标签分别是“矛盾”“蕴涵”以及“无关”。

图4 矛盾句可视化展示

图5 蕴涵句可视化展示

图6 中立句可视化展示
从图4~图6可以看出,每对前提假设句子对都会有相应的关键词对,如“grin-shot”“grin-happy”以及“grin-young”,这些关键词对于前提文本能否推断出假设文本具有决定性的作用。图4~图6分别表示ESIM模型与aESIM模型中句向量分别经过双向LSTM层以及双向aLSTM层之后的可视化结果,这样可以直接观察到两个词之间的相似度。在每幅图中,颜色越浅,表明相似度越大。可以看出,aESIM模型对于关键词对的相似度计算结果均高于ESIM模型的计算结果。尤其是在图5中,“happy”与“grin”在aESIM模型中相似度明显高于在ESIM模型中的相似度。因此,本文提出的aESIM模型相比于ESIM模型有着更强的信息提取以及句子表征能力,在计算词相似度方面也有更好的表现。
4 结束语
本文在ESIM模型的基础上提出注意力增强的自然语言推理模型aESIM。在双向LSTM层中引入注意力机制与自适应的权重计算层,将前向与后向向量加权相连,分别刻画不同单词和不同方向对于句子向量的贡献度。在SNLI、MultiNLI以及Quora 3个自然语言推理公开数据集上的实验结果表明,与ESIM模型相比,aESIM模型表现出更优的性能,具备较强的信息提取能力。下一步将对注意力机制的应用方法进行深入研究,同时构建基于字符以及单词联合表示的词向量模型。
猜你喜欢
出版人(2022年11期)2022-11-15
小雪花·成长指南(2022年1期)2022-04-09
今日农业(2021年19期)2021-11-27
数学小灵通(1-2年级)(2021年10期)2021-11-05
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
唐山师范学院学报(2018年6期)2018-12-25
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
通信电源技术(2016年5期)2016-03-22
