
Benefits of past inventory data as prior information for the current inventory
2020-07-16 07:18AnnikaKangasTerjeGobakkenandEriksset
Forest Ecosystems 2020年2期
Annika Kangas,Terje Gobakken and Erik Næsset
Abstract
Keywords: Data fusion, Kalman filtering
Introduction
In forest inventory, many types of information can be used in addition to an actual sample of observations.There are at least two good reasons for using such information in forest inventory: 1) we can either improve the accuracy (mean square error, MSE) of the estimates while keeping the costs the same level as before, or 2)we can reduce the costs without reducing the accuracy.Obviously, this necessitates the auxiliary data to be cheap or free (i.e. the costs are assumed to be sunk costs from some previous use of the data). It is possible to use remotely sensed data, e.g. from satellite images or airborne laser scanning (ALS), as auxiliary information using stratification, model-assisted or model-based frameworks (e.g. Gregoire et al. 2011; Ståhl et al. 2011).In addition, it is possible to combine current data from most recent forest inventory with old data from previous inventories or existing models constructed from old data as prior information (e.g. Tomppo and Halme 2004;McRoberts et al. 2014).
One method for using old data in forest inventory is sampling with partial replacement (SPR, Ware and Cunia 1962). For estimating the current population mean, two independent estimates are combined to form a single linear unbiased estimator. The weight placed on the two estimates depends on the correlation between the re-measured plots on first and second occasions and on the estimated variances of the population parameter estimators on these two occasions.
In the case of three or more successive inventories,SPR results in quite complicated estimators. However,Bickford et al. (1963) published estimators based on a different approach, namely on composites of two estimators, weighted inversely to their variances (Meier 1953).The first estimator is based on the data from old field plots updated to the current occasion using the change observed in re-measured plots through a regression estimator, and the other on the current field plots. Scott(1984) extended this approach to include also change estimation. Scott and Köhl (1994) used a similar approach to provide composite estimators also for a stratified case,by which it would be possible to apply auxiliary information from both remotely sensed data and from previous inventories.
When information of growth is available in the form of a growth model, it can be utilized in a Kalman filter(Dixon and Howitt 1979). In a Kalman filter approach,the old data from previous inventories are updated with growth and harvest information and the updated data are used as prior information. The growth model used in Dixon and Howitt (1979) was crude; it simply gave the proportional change of the state vector over time,and the harvests were assumed known control actions.Kangas (1991) used data updated by tree-wise growth models and stand-level harvest models as prior information. However, for estimating the precision of the resulting estimates, all changes were described using a single proportional change of state, which was used in a Kalman filter-type of analysis.
More advanced types of Kalman filters can be applied by allowing for non-linear growth models (e.g. Ehlers et al. 2013). However, when accurate auxiliary information such as that provided by ALS or digital aerial photogrammetry data is available, utilizing prior information from old data may produce only marginally smaller MSE than using only the most recent data(Nyström et al. 2015).
Even if we have accurate current data, there is still merit to see if the overall performance can be improved by using old data. The aim of this study was to assess if prior information from old inventory enhances the accuracy of the results in a case where auxiliary information from ALS is available. We compared three different approaches: 1) using only current data, 2) using nonupdated old data and current data in a composite estimator and 3) using updated old data and current data with a Kalman filter. We tested three different estimators, namely i) Horwitz-Thompson for a case of no auxiliary information, ii) model-assisted estimation and iii)model-based estimation. We compared these methods in terms of bias, precision and accuracy, as estimators utilizing prior information are not guaranteed to be unbiased.
Materials
The field data
The empirical part of this study was based on data from Våler Municipality in south-eastern Norway. The study area (altogether 853 ha) is located in a boreal forest region. The forest is actively managed, with Norway spruce (Picea abies (L.) Karst.) and Scots pine (Pinus sylvestris L.) as the dominant species.
Prior to the field inventory, photo interpretation was adopted to delineate the study area into forest stands,each belonging to one of four classes related to stand age and species dominance: 1) recently regenerated forests, 2) young forests, 3) mature, spruce-dominated forests, and 4) mature, pine-dominated forests. Only the strata 2-4 were included in this study due to deficient data collected for stratum one in 1999. As part of the plots were harvested during 1999-2010, recently regenerated stands were, however, also included in the analysis. A sample survey was conducted according to a systematic design with random start with sampling intensities approximately equal for the first three strata,but for the fourth stratum the intensity was only one third of that of the other three strata (Næsset 2002;Næsset et al. 2013, 2015).
Measurements were obtained for 178 systematically distributed, circular, 200-m2(radius 7.98 m) forest inventory plots measured in 1999 and 2010. Four plots were discarded from the analysis due to missing values.Tree-level aboveground biomass(AGB)was predicted using allometric models based on field observations of species and measurements of diameter at-breast-height (1.3 m) and height(Marklund 1988). Plot-level AGB was then predicted as the sums of individual tree AGB predictions, scaled to per-hectare values,and used as ground reference.
Wall-to-wall ALS data were acquired for the study area in 1999 and 2010. Pulse density was approximately 1.2 pulses per m2in 1999 and 7.3 pulses per m2in 2010.Empirical distributions of first and single echo heights were constructed for the 200-m2circular plots.The entire study area was tessellated into 200 m2regular squares (cells)and similar ALS echo distributions were constructed for each cell. A threshold of 1.3 m above the ground surface was used to remove the effects of echoes from ground vegetation whose biomass is not included in tree-level biomass. For each plot and cell,heights corresponding to the 0th,10th, 20th, …, 90th percentiles (p0,p10, p20, …, p90)of the ALS height distributions were calculated. Furthermore, several measures of canopy density were derived.The range between 1.3 m above ground and the 95 percentile was divided into 10 vertical fractions of equal height. Canopy densities were then calculated as the proportions of echoes with heights above fraction 0(>1.3 m),1, …, 9 to total number of echoes (d0, d1, …, d9). Maximum value (hmax), mean value (hmean), and coefficient of variation(hcv)were also computed.Thus,23 ALS metrics were available as explanatory variables. Næsset et al.(2013) provide more details for the study area and the dataset.
The copula population
We used the data from Våler to construct a simulated copula population. In the C vine copula, a multivariate distribution of the variables is formed. This is based on pair copulas that describe dependencies between each pair of the variables when the marginal distributions of these variables are transformed to uniform distributions(see Aas et al. 2009). The pairs are formed using a specific tree structure of the variables depicting the strength of the dependencies. For construction of the copula, we used the same approach as Myllymäki et al. (2017) and Kangas et al. (2016). That is, we calculated the empirical marginal distributions for the variables AGB, p0, p20,p40, p60, p80, d2, d4, d6 and d8 from the data using the logspline package in R (Kooperberg 2015, R Core team 2014) and estimated the C vine copula using the Vine-Copula package in R (Schepsmeier et al. 2015). In the current study, we included the AGB and the ALS metrics from both occasions to be able to analyse the case of using prior information. To our knowledge, this is the first simulation study involving also change.The copula model was used to simulate 10,000 uniformly distributed observations with the modelled (pairwise) dependencies. These 10,000 observations can be interpreted as 200 m2grid cells mimicking similar cells in actual ALS data acquisition in an area of 200 ha. The copula population was then obtained by calculating the quantiles of the empirical distributions at those simulated uniformly distributed values. Figure 1 shows the dependency between the simulated AGBs on the two occasions in time. It reflects both the growth of the plots between the two points in time (dots above the red line)and the cuttings (dots below the red line).
estimator of the meanMethods
Estimators to be compared
First, it is possible to use the field sample from both time points with a Horwitz-Thompson (HT) estimator,and make a composite of these two estimates. The HT estimator of total AGB is(e.g.Särndal et al. 1992, p 42)
where yiis the AGB of cell i and πiis the inclusion probability of cell i. Assuming simple random sampling without replacement this inclusion probability is n/N.The estimator of the mean is
where A is the total area. Its variance estimator is (e.g.Särndal et al. 1992, p. 43)
where πijis the joint inclusion probability of cells i and j.In the case of simple random sampling, when i=j, this joint probability is πi, otherwise it is n(n-1)/N(N-1).These formulas can be extended also to stratified sampling.
Another option is to utilize auxiliary information and adopt a model-assisted estimator. Then, the difference estimator for the mean AGB is (e.g. Särndal et al. 1992,p 222)
Yet another option is to use a model-based estimator for the mean, i.e.,
This is equal to the first part of the estimator in Eq. 4,meaning that the model predictions are used without calibrating with the sample data. Its variance can be estimated with (Ståhl et al. 2011, Eq. 7)
(Kangas 2006). The residual errors of the model are assumed to have a negligible effect on the variance,meaning that the population model mean instead of a finite population mean is estimated (Ståhl et al. 2011,p. 99). If the residual errors are spatially correlated,that would introduce an additional term (McRoberts et al. 2018). In the current case, in the context of a relatively small area,the spatial correlation is likely to have a significant effect.It was,however,assumed negligible,as no mechanism to produce a specific spatial structure to the simulated data was available.
When two HT estimators (or model-assisted or model-based estimators) from two time points are available, a composite estimator can be formulated as
where subscripts c, 1 and 2 denote the composite estimator, the estimator for the first time point and the estimator for the second time point, respectively. α is calculated from the variances of the two estimates as
where
to obtain a composite where the individual estimators have the larger weight, the smaller the variance (e.g.Meier 1953; Scott and Köhl 1994). The variance for this composite estimator is (Shahar 2017)
where t denotes the time points 1 and 2. When the variances are estimated, an unbiased estimator is (Meier 1953; Scott and Köhl 1994)

It is also possible to use a Kalman filter to update the previous sample data using a growth model and combine it with the new sample data information. The growth model can be written using notation from (Ehlers et al.2013; Nyström et al. 2015) as

The model of the sampling system can be written as
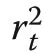
The Kalman estimator of the state vector can be calculated by the following procedure. The Kalman filter has a prediction step and an update step that follow each other in sequence. The predicted conditional mean given all the data through time t is
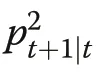
The prior information, xt+1|t, and the sample information, ηt+1, are then combined in the update cycle to yield
where
is the Kalman gain, and the variance of the assimilated value is
Models used
In this study, we estimated the external models (i.e.models estimated from a dataset independent of the sample at hand) to be used in model-assisted estimation from the Våler plot data. As the copula population is simulated based on the same data, the models are not truly independent from the simulated data. However, the external model is fixed across the simulated samples. All the models were estimated using weighted regression to account for heteroscedasticity. This was carried out iteratively: the weights were estimated from the OLS model residuals, and the inverses of squared residuals were then used as weight in WLS.
For 1999,the estimated external model for AGB(t·ha-1)was AGB1999=β0+β1p20_1999+β2p80_1999+β3d8_1999+ε1999(see Table 1). The residual standard error RSE=32.77,R2=0.7827 and adjusted R2=0.7784.The residuals of this model are presented in Fig.2.

Table 1 The coefficients for a model of AGB in 1999
For 2010,the estimated external model for AGB(t·ha-1)was AGB2010=β0+β1p20_2010+β2p60_2010+β3d2_2010+ε2010(see Table 2). The residual standard error RSE=41.81,R2=0.2044 and adjusted R2=0.8010.The residuals of this model are presented in Fig.3. The effect of cuttings after 1999 can be detected from the zero biomass measured in 2010,and also from the greater residual error than that observed in 1999.
The changes between 1999 and 2010 include both growth of the plots and the effect of harvests. Especially the effect of harvests is difficult to predict with a model,but unless the harvests cannot be assumed as known control actions, a model capable for predicting both is necessary for the Kalman filter approach.
The change model can be constructed in several different ways. The first option is to rely on the variables describing the growing stock, in this case the AGB from 1999, which is the typical way to make a growth model.Such a model would allow for predicting changes happening after either 1999 or 2010 inventory, using the AGB from the respective inventory. Another option is to utilize both the growing stock estimate and the ALS metrics. If only the metrics from 1999 are used in the model, the model allows for predicting the changes both after the 1999 or 2010 inventory using the respective metrics. If both 1999 and 2010 metrics are used in a model, the model can only be used to estimate the past changes between 1999 and 2010. However, such model is likely to be more accurate, as the differences in the 1999 and 2010 metrics enable close to direct detection of the changes.
In this case, the first option produced large standard errors, especially with respect to the harvests. Therefore,change (C) was predicted based on the observed AGB in 1999 and the ALS metrics. The first model using only 1999 ALS metrics for change in AGB (t·ha-1) is C1=β0+β1AGB1999+β2p60_1999+β3p80_1999+β4d2_1999+β5d6_1999+εC1(see Table 3).
The residual standard error RSE=34.50, multiple R2=0.7792, and adjusted R2=0.7726. The residuals of this model are presented in Fig.4. It is notable that the standard error of the change model is actually a little bit greater than that of the model for the AGB in 1999. The model is to some extent also able to capture the cuttings in addition to the growth. The predicted AGB in 2010 using the true values of AGB in 1999 and the predicted change are presented in Fig.5. In some plots, the predicted AGB is negative,but overall the model behaves logically. Negative predictions can, when the model is applied, be adjusted to zero, but in this case such correction was not made.
To analyse the effect of the change model,we estimated an alternative model for change C using also the 2010 ALS metrics as predictors. The model for change in AGB (t·ha-1) is C2=β0+β1AGB1999+β2p20_2010+β3d2_2010+β4d2_1999+εC2(see Table 4).
The residual standard error RSE=30.27, R2=0.8218 and adjusted R2=0.8176. The residuals are presented in Fig.6. In this model, the change in the density metric d2between 1999 and 2010 can be interpreted to describe the effect of harvests.
Simulations
We present different approaches to utilize data from the old inventory as prior information and assess their accuracy in a simulation study.In the copula population a simple random sample of size n=100 was simulated s=5000 times. Independent samples of size n were selected from the 1999 data and the 2010 data in order to calculate the results utilizing prior information, i.e. no re-measurements were assumed.The simulated (true) variance was calculated as the variance among the 5000 realizations of the sample.The bias was calculated as the difference of the true mean and the mean of the estimates of mean from these 5000 realizations and RMSE was calculated from them with
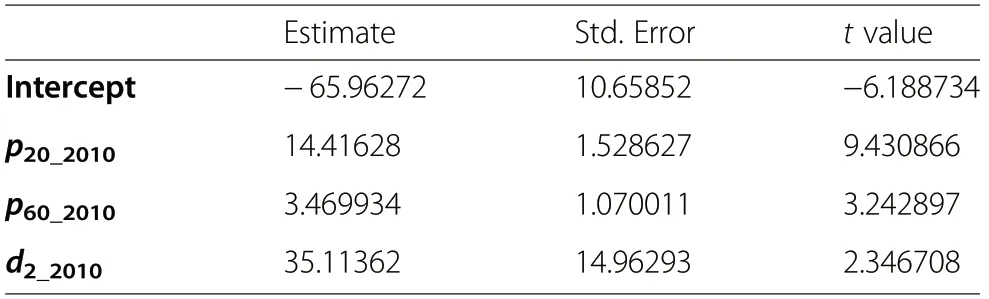
Table 2 The coefficients for a model of AGB in 2010
The estimated variance is a mean of sample variance estimates over these realizations.
In a case of model assisted inference, an external model(i.e.a model estimated from independent data previous to the sampling) is recommended, as using a model estimated from the sample at hand (internal model) has shown to lead to underestimation of variance(e.g. Kangas et al. 2016). While it is possible to reduce the underestimation by using a fixed mathematical form of a model,(i.e.the mathematical form of the model is assumed external while the coefficients are internal),we used an external model for the model-assisted estimation.
In the case of model-based inference, however, the inference is solely based on the model estimated from the sample. Thus, in model-based estimation, using an external model would mean that the sample at hand does not have any effect on the variance estimates, as all the terms in Eq. 7 would be fixed. Therefore, for all occasions, we used a model estimated from the sample for the model-based approach.
In a case of a change model, either an internal or an external model is applicable. Here both the change models (with and without 2010 ALS metrics) were assumed to be external, and the same model was used in all cases where a change was predicted (i.e. both for the model-based and the model-assisted approach). This is justified, as the growth models used for prediction are typically based on separate experimental data sets rather than inventory data. Moreover, change models estimated from the simulated samples proved to be fairly unstable.Both of the external change models had a mean error quite close to zero in the Copula population, with the mean change of 15.79 t·ha-1for the population, and 15.03 t·ha-1with the first change model and 15.31 t·ha-1with the second change model.
Results
The HT estimator using solely the 2010 field data (i.e.without the ALS data or the old inventory data), produced the largest estimated and simulated variances(Table 5). Both the model-assisted and model-based estimators produced markedly (39%-40%) smaller variances(simulated and estimated) than the HT estimator. These results were obtained even though a linear model with a good fit for AGB in 2010 was difficult to obtain as there were many plots with near-zero AGB (clear-felled after 1999) in the data. The reduction in variance was slightly larger for the model-based with respect to the simulated variances, but the difference was minor. In the case of linear models used here, the model-assisted estimator with internal model would actually produce an identical result to the model-based estimator. Since the mean of errors within the sample is zero using the internal model, the estimate (Eq. 4) adjusting the estimate for errors in the model predictions is the same as the modelbased estimate (Eq. 6) not including an adjustment part.This does not, however, hold for non-linear models.
A composite of 1999 and 2010 HT estimates had clearly smaller variance than the HT estimate using solely the 2010 data. Introducing prior information in the form of old data reduced the variance almost as much as utilizing the auxiliary information from ALS:the simulated (true) variance was 5.66 compared to 5.24 in model-assisted.However,as the old sample plots were not updated, the resulting composite estimator for the 2010 AGB was clearly biased, and if the bias is taken into account, using purely 2010 data would be a better choice.

Table 3 The coefficients for a change model using ALS metrics from 1999
When both the prior information and the auxiliary ALS data were utilized, the variances were further reduced. The simulated variance of a composite of two model-assisted estimates was 3.80, i.e. markedly smaller than the pure model-assisted (5.24), but the biases were large. The results clearly show that composite estimators for which the growth and cuttings are not accounted for are highly biased.
A Kalman estimate based on HT estimator of AGB in 2010 and updated HT estimator from 1999 reduced both the bias and the variance, so that the root mean square error RMSE of the estimate was 6.16 compared to 5.24.However, even in this case utilizing model-assisted or model-based estimation instead of utilizing the prior information from old data is advisable.
The smallest RMSE estimates were obtained when the model-assisted approach was combined with a Kalman filter. The estimated variance was 4.23, and the simulated variance 3.73, indicating that the Kalman filter variance estimate was in this setting conservative. The Kalman filter with a model-based approach had an estimated variance of 4.12 and the simulated variance was 3.72, i.e. almost identical to the model-assisted results.
When an alternative growth model C2 with also 2010 ALS metrics included was used in the Kalman filter, the RMSEs were somewhat improved compared to those obtained with model C1 due to the improved accuracy of the model (Table 6). This means that the usefulness of the Kalman approach is highly dependent on the accuracy of the change models.
Discussion
The results of this study confirm that it is not selfevident to reduce the RMSE of the population parameters by using prior data from previous inventories, if the estimation is already enhanced with accurate current remotely sensed auxiliary information. It is possible to improve the results by using a Kalman filter type of approach, but that requires that the auxiliary information obtainable from remote sensing is also utilized efficiently in the analysis.
It is clear from the results that a composite estimation using old and current data is not a feasible approach when the time interval between the acquisitions of these two data sets is as large as in the current study (11 years). It is possible that a composite estimator without the updating would be useful, if the interval was markedly shorter, and if the plots influenced by harvest could be correctly detected.If permanent plots were available,a regression estimator proposed by Bickford et al. (1963) could also be used for updating, but in this study the two samples were assumed independent. Otherwise, it is clear that updating the data using a growth model would be highly advisable.However, even in this case the results are likely to be the more accurate the shorter the time interval, meaning smaller variance of the predicted change. In addition, it is unlikely that an external change model would be correctly specified for the target population in a real case. That would involve considerations as to how large a bias in the estimators would be acceptable. Depending on the use of the data, it may not be enough if the RMSEs of the estimates can be reduced when using old data as prior information: it is possible that in some applications even a small bias is unacceptable.
Typically, in Kalman filtering it has been assumed that the sample estimate is a random sampling estimate.However, there is nothing in the method that prevents using model-assisted or model-based estimator as the starting point, which is updated as in the Kalman filter.Then the resulting estimate can be combined with another model-assisted or model-based sampling estimate to obtain Kalman gains. If the applied growth model is linear, this is straightforward. If the growth model is non-linear, it has to be linearized with a Taylor series approximation (e.g. Ehlers et al. 2013) or by computing the average change as in Kangas (1991). It would also be possible to utilize stratification or post-stratification instead of model-assisted or model-based estimation,which might involve simpler estimators in case of nonlinear change models.
It is often argued that comparing model-assisted and model-based approaches is not useful, as the underlying assumptions are very different, thereby causing different interpretations of uncertainty. However, here we compared the simulated (true) estimates of variance and RMSE,describing how well these approaches can estimatethe variable of interest, the mean of AGB in 2010. Irrespective of the interpretation of the uncertainty,this is the important issue for the users of the data. Moreover,when the old inventory data are updated with a growth model,the end-result is a hybrid estimate involving the sampling error of the original estimate and the model-based prediction error (e.g. Melo et al. 2018). If the errors in the within-plot estimations (such as the allometric biomass models) were included, all the cases considered would be hybrid estimators (e.g. Ståhl et al. 2014, Corona et al.2014, Fortin et al. 2016, Ståhl et al. 2016, Holm et al.2017). In the case of hybrid estimators, the differences in the theoretical foundations of the design-based and model-based approach are ignored. In the current case,these two approaches produced also empirically very similar results on average.

Table 4 The coefficients for a change model using ALS metrics from 1999 and 2010
In this study, we did not include the uncertainties of the allometric models. In this study, we assumed that these errors are negligible when compared to the errors in the change predictions. However, when the interval between the past and current inventories gets shorter,the relative importance of the uncertainties due to the allometric models will increase (see e.g. Chen et al. 2015,2016). In addition, in this study we ignored the effect of spatial correlation. It can be assumed that the smaller the area over which the results are calculated, the larger is the effect of this spatial correlation (e.g. McRoberts et al. 2018). Both of these aspects need to be studied in the future. Furthermore, the possibility that the two estimators are not independent (like if part or all of the plots are permanent), also needs to be addressed in the future (Grafström et al. 2019).
The most problematic issue in the updating of the data for the Kalman filtering is the harvests. In this study, a fairly simple linear model was utilized. However, even with such a simple model it proved to be possible to also predict the harvests happening between 1999 and 2010(i.e. the model also predicted negative changes). In this study, first a model (C1) based on the 1999 ALS metrics,and secondly a model (C2) based on both 1999 and 2010 ALS metrics were tested. If the purpose is to estimate past changes in order to update the old (1999) data to the current year (2010), it would be possible to utilize the second type of model. If the purpose would be to predict also the harvests happening after 2010 (e.g. between 2010 and time point t3, if ALS data from thattime point are unavailable), only the first type of model is applicable. In this case, the latter model produced more accurate change estimates, as the differences in the density metrics (d2) between the two time points were able to describe the harvests. This model consequently produced more accurate estimates for the current (2010)AGB. It means that all the information available for the updating should be included in the analysis.

Table 5 The results from the simulation using the change model 1 for the Kalman filter. The mean of sample means of AGB (t·ha-1)and sample variance estimates,the simulated variance, the bias and the RMSE
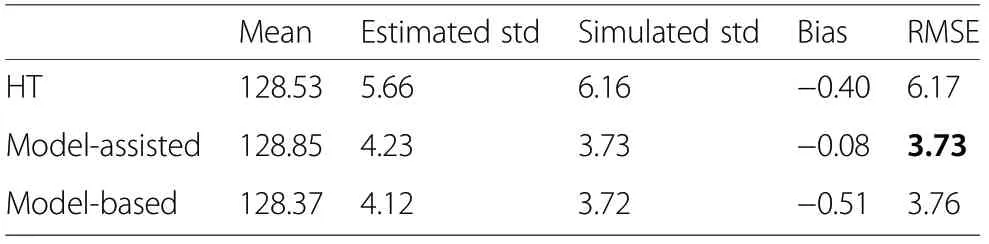
Table 6 The Kalman filter results from the simulation using the change model 2.The mean of sample means of AGB(t·ha-1)and sample variance estimates,the simulated variance, the bias and the RMSE
The prediction of the harvests is also likely to increase the error variance of the change estimates, so that improved accuracy would be obtained if the harvests were directly observed from the differences between remote sensing materials and used as known control actions rather than predicted using a model as was done here.This is possible for clearcuts, which can be accurately delineated from differences between two satellite images(Pitkänen et al. 2020). Moreover, if the change model would reflect purely growth, it would be possible to utilize relative errors (as in Ehlers et al. 2013) rather than absolute errors. This is important, as the errors in predicted growth are often heteroskedastic. Then, relative error may reflect the true situation better. Such an approach was not feasible to adopt in the current study,as the model also predicted harvests, and part of the change estimates were negative.
In the Kalman filtering approach, the errors in the growth model are an important source of error. The simulated variances for both model-assisted and modelbased with a composite model were smaller than those of the Kalman filter counterparts, as the Kalman filter variance estimates also include the error of the growth model. Optimal weight for the composite estimator would be obtained, if the bias (and therefore also RMSE)was known, but this is normally not the case. On the other hand, as the bias was mostly removed in the Kalman filter approach, the RMSEs of Kalman filter estimates were clearly smaller than those of the composite estimates. While using the variances provides optimal weights, they also can complicate estimation if the weights vary across the domains (Scott and Köhl 1994).Therefore, non-optimal weights based on simply the number of plots might be useful(Scott personal communication 2019).
In the current study, the Kalman filtering approach was used to estimate the mean AGB in the whole population. If this approach was to be used in a real NFI setting (Tomppo et al. 2010), it would require that all variables of interest can be updated to the date of the current inventory. This generally requires a growth and yield simulator with a tree-level growth models (e.g.Kangas 1991). If this requirement can be fulfilled, then the approach is applicable in NFI with the same premises than model-based estimation in general is applicable in NFI.
However, this kind of approach might be more useful for results calculated for smaller domains/categories, for instance for a small area or for a rare tree species. In that kind of situation, it might be useful to use plots measured from a longer period of years than normally in a case of continuous panel inventory. In NFIs, often a continuous panel inventory with 5-year interval is used,but using plots from a 10-year period would be possible.Plots measured during the 5-year interval might not be updated, but if a longer period is used, updating the data would be advisable. In some countries, the inventories are separate campaigns like in this study, and in such a case it might be useful to use data from two or more campaigns for the smaller domains/categories. The usefulness of old inventory data for small area estimation remains to be studied in the future.
In previous studies concerning the Kalman filter,utilization of prior information has mostly been tested in a setting where the interest has been in the individual plot or pixel level results (e.g. Ehlers et al. 2013). It is likely that in such a setting improving the accuracy using the old data is markedly more difficult than in the studied case. This is because in a sampling setting, the prior information can be interpreted as increasing the number of plots in the analysis, which improves the estimates for the population mean and total. In a pixel level analysis such interpretation cannot be made.
Conclusion
Prior information from old inventory data can be useful also when combined with highly accurate auxiliary information,when both data sources are efficiently used.
Acknowledgements
We wish to thank Dr. Charles T. Scott for helpful comments on the earlier phase of the manuscript.
Authors’ contributions
Professor Kangas estimated the models used,produced the copula population and made the simulations.She was also mainly responsible for the writing of the paper.Professors Næsset and Gobakken provided the original field data,and took part in interpreting the results and writing the paper.The author(s)read and approved the final manuscript.
Funding
The analysis and interpretation of the results was partly funded by the Finnish Ministry of Agriculture and Forestry key project “Wood on the move and new products from forests”and partly by the Norwegian Forest Trust Fund (Skogtiltaksfondet) and the Forest Development Fund (Utviklingsfondet for skogbruket).
Availability of data and materials
The simulated population is available as. Rdata file from the corresponding author.
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Author details
1Bioeconomy and Environment, Natural Resources Institute Luke (Finland),Yliopistokatu 6,80100 Joensuu, Finland.2Faculty of Environmental Sciences and Natural Resource Management, Norwegian University of Life Sciences,P.O. Box 5003, NO-1432 Ås, Norway.
Received: 16 August 2019 Accepted: 23 March 2020

- Forest Ecosystems的其它文章
- Trade-offs between wood production and forest grouse habitats in two regions with distinctive landscapes
- Global woodland structure from local interactions:new nearest-neighbour functions for understanding the ontogenesis of global forest structure
- Innovative deep learning artificial intelligence applications for predicting relationships between individual tree height and diameter at breast height
- Wild bee distribution near forested landscapes is dependent on successional state
- Gap models across micro-to mega-scales of time and space:examples of Tansley’s ecosystem concept
- Variation of net primary productivity and its drivers in China’s forests during 2000-2018