
基于Relief-WSVM的股票预测研究
2020-07-14 18:27李峥嵘韦增欣祝人杰
中国管理信息化 2020年11期
李峥嵘 韦增欣 祝人杰


[摘 要] 股票市场的复杂性和非线性性,使得股票趋势预测成为一个比较棘手的问题。文章通过分析不同特征和不同样本点对模型预测的影响差异,将Relief算法与加权支持向量机(WSVM)相结合对股票价格的涨跌进行预测研究,以华兰生物(002007)等股票为实验对象,验证了Reief-WSVM模型在股票涨跌预测中的可行性和准确性。
[关键词] 加权支持向量机;Relief算法;股票趋势;特征加权
1 引 言
随着我国经济建设的发展、金融市场的完善,越来越多投资者选择购买股票作为自己的投资方式。如何把握股票的价格趋势、进行有效的股票投资管理、提高股票投资效率是投资者获得超额收益的关键问题。股票市场中的金融规律复杂,影响因素众多,其非线性、非平稳、高噪声等特性使得股票预测充满了困难和挑战。在传统的金融分析和理论中,所采用的决策模型较为容易理解和解释,但预测效果往往与实际偏差较大。随着机器学习、数据挖掘领域的发展,金融数据挖掘技术的应用从某种意义上来说可以突破这些限制,得到更贴近现实的预测效果。
支持向量机在解决分类和回归等机器学习问题方面有很好的效果,许多学者在将支持向量机应用于股票预测这个方向进行了深入研究。张玉川[1]等结合股票市场上流行的几种技术指标,应用支持向量机对个股的价格涨跌进行预测分析。Lean Yu[2]等人提出了一种基于混合核的最小二乘支持向量机并应用于股票趋势预测。张伟[3]等将支持向量机和遗传算法结合,对RBF参数和特征集的选择进行了优化。
然而,支持向量机进行训练分类时,不同的样本点对最优超平面的学习有着不同影响,数据集可能会出现野点或噪声对分类带来不好的影响,各个特征对股票趋势预测的贡献影响也不尽相同。为提升预测效果,本文将加权支持向量机(WSVM)与Relief算法相结合,在考虑样本距离加权的同时,利用Relief算法求出各个特征在分类中的影响程度,即各自权值。然后把带权值的特征输入到支持向量机中进行训练,对股票价格趋势进行预测。
2 原理与方法
2.1 加权支持向量机
支持向量机的基本思想是寻找一个满足分类要求的最优分类超平面,使得该超平面在保证分类精度的同时,能够使超平面两侧的空白趋于最大化。为了降低数据集中野点或噪声的影响,根据样本点对本类别的相对重要性,考虑给野点安排一个比较低的权重,以降低野点对整个训练误差的影响。对于给定训练集:{(x1,y1),(x2,y2),…,(xN,yN)},其中x∈Rn,y∈{-1,1},在本研究中y=1记为正类代表股价上涨,即后一天收盘价比前一天收盘价高;y=-1记为负类代表股价下跌,即后一天收盘价比前一天收盘价低。
2.2 Relief算法
Relief[5]是由Kira和Rendell于1992年提出的一种基于样本学习的特征权重计算算法,是过滤式特征选择算法中的一种。该算法通过考察特征在同类近邻样本和异类近邻样本间的差异来度量特征的区分能力。若某个特征在同类样本间差异小,在异类样本间差异大,则该特征具有较强的区分能力。假设每个样本包含k个特征,即xi={xi1,xi2,…,xik},由于股票数据的特征为数值型,则两个样本xi和xj在特征t上的差定义为:
其中maxt和mint分别为特征t在样本集中的最大值和最小值,1≤i≠j≤N,1≤t≤k。算法首先从样本集中随机选择一个样本xi,从正类和异类样本中各选择一个距离xi最近的样本,与xi同类的样本称为Near Hit用Hi表示,与xi异类的样本称为Near Miss用Mi表示。根据式(4)更新特征t的权重wt,其中r表示抽样次数
由式(4)可知,若样本xi与Hi在某个特征上的距离小于xi与Mi的距离,则该特征异类间差异大而同类间差异小。特征的权重越大,表示该特征的类别区分能力越强,若权重为负,则表示该特征的类别区分能力较弱。
传统SVM方法在数据预处理后便直接进行模型训练,未考虑不同样本和特征对最优分类面的学习存在不同贡献。本文将Relief算法与加权支持向量机相结合,在进行模型训练前,使用Relief算法计算特征权重以增大不同类特征向量的差异性,并根据不同样本点对其类别的相对重要性计算其距离权重以降低野点或噪声的影响,进而提升模型预测的准确率。
3 实证分析
3.1 样本选取与数据预处理
本文选取华兰生物(002007)、科大讯飞(002230)、华夏银行(600015)、上汽集团(600104)这4支不同行业的股票数据作为实验对象,数据来源于东方财富旗下金融數据平台——Choice金融终端。时间跨度为2017年1月1日至2017年12月31日244个交易日的数据,其中前80%个数据作为训练集,后20%个数据作为测试集,在MATLAB R2017a环境下,借助LIBSVM工具箱进行数值实验。
选取股票的开盘价、最高价、最低价、收盘价、涨跌幅、成交量、换手率、振幅、5日移动平均线(MA5)、异同移动平均线(MACD)、6日相对强弱指数(RSI6)、随机指标(KDJ_K、KDJ_D、KDJ_J)、6日乖离率(BIAS6)、心理线PSY作为数据特征(输入变量),股票每日的涨跌趋势作为预测目标(输出变量)。由于各个特征量的计算方式不同,特征量之间存在的数量差异会使得运算过程复杂并导致大值特征主导预测模型的不利情况,为了消除这些不利影响,本文采用公式(5)对特征量进行归一化处理。
3.2 模型训练
总结以往研究发现,RBF核函数在非线性拟合方面具有较好效果,因此本文选用RBF核函数作为WSVM的核函數,用基于10折交叉验证的网格搜索法对惩罚参数C和核函数参数g进行参数寻优。
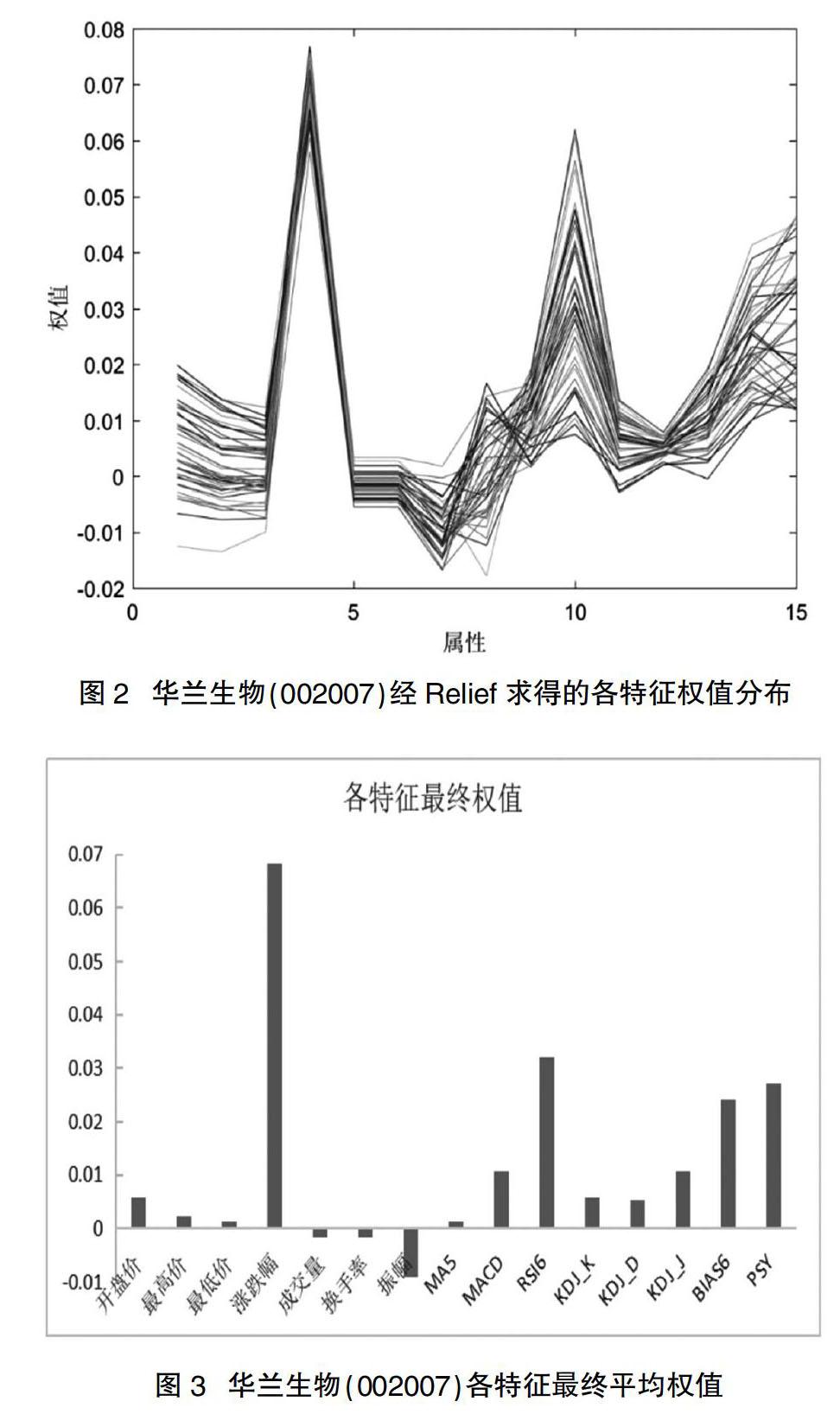
在Relief算法中,随机选取样本200个,不设阈值,将主程序运行40次,计算特征权重的平均值作为最终权值,把权值组成权值向量,与其相对应的特征一起送入支持向量机进行模型训练。以华兰生物(002007)为例,经过Relief算法计算,每次循环中各个特征的权值分布如图2所示,最终求得各个特征的平均权值柱形图如图3所示。
从图3中可以看出涨跌幅的权重最大,其次是RSI6、BIAS6、PSY、MACD和KDJ_J这几个特征权重较大,这些特征对类别有较好的区分能力。成交量、换手率、振幅这几个特征的权重为负值,这些特征对类别的区分能力相对较弱。预测结果与实际可能出现的情况如表1所示。
本文采用分类模型常用的性能评价指标预测准确率(Accuracy)来衡量模型效果,计算方法如式(6)。
3.3 结果分析
用训练好的模型对华兰生物(002007)等4支股票进行预测,为了验证本文提出模型的优劣性,以常见的预测模型SVM、WSVM和BP神经网络作为参照模型进行对比,预测准确率如表2所示。
由表2可以看出,Relief-WSVM模型的预测准确率均达到70%以上且均比参照模型的准确率高。为避免单只股票的随机性,本文选取了不同行业的4支股票进行对比实验,预测准确率均有一定提高。这也同时说明本文的改进是有效的,本模型可以帮助投资者更好地判断股票趋势的拐点。
4 小 结
本文考虑到不同特征和不同样本点对模型效果的影响不同,将Relief与WSVM进行结合并应用于股票价格涨跌预测中,并通过华兰生物(002007)等股票进行实证分析,验证了该模型的准确性和有效性。股票市场受宏观、微观各方面因素影响,复杂性很高,本文选取的是单个核函数中性能表现较好的RBF核函数,在进一步的研究中可考虑引入混合核对模型做改进以进一步提高预测准确率。
主要参考文献
[1]张玉川,张作泉.支持向量机在股票价格预测中的应用[J].北京交通大学学报,2007(6):73-76.
[2]Yu L,Chen H,Wang S,Lai KK.Evolving Least Squares Support Vector Machines for Stock Market Trend Mining[J]. IEEE Transactions on Evolutionary Computation,2009,13(1):87-102.
[3]张伟,李泓仪,兰书梅,等.GA-SVM对上证综指走势的预测研究[J].东北师大学报:自然科学版,2012,44(1):55-59.
[4]黎金玲,李亚楠,郭海湘,等.一种加权的支持向量机及其在储层识别中的应用[J].数学的实践与认识,2014,44(7):39-46.
[5]王正宇,张扬帆,段向阳,等.基于Relief算法的风电机组故障特征参数提取方法[J].华北电力技术,2017(10):57-62.
