
OpenMP环境下线积分卷积的并行化实现
2020-07-14 13:01符晓单
理论与创新 2020年10期

【摘 要】线积分卷积是矢量场可视化的重要的方法之一,但是由于需要对每个矢量点进行卷积积分计算,因而计算量较大。CPU多核环境下的并行实现是现在并行计算技术发展的方向之一。本文在OpenMP 环境下实现了线积分卷积的并行化。结果表明,随着CPU核数的增加,并行线积分卷积的时间逐渐降低,加速比逐渐增加。
【关键词】线积分卷积;OpenMP
Abstract:Line integral convolution is one of the most important methods for vector field visualization. However, it requires the convolution integral calculation for each vector point. Parallel implementation in CPU multi-core environment is one of the development directions of parallel computing technology. In this paper, the parallelization of line integral convolution is realized by OpenMP in a multi-core environment. The results show that the time of parallel line integral convolution decreases and the acceleration ratio increases with the increase of CPU cores.
KeyWords: Line integral convolution; OpenMP
引言
基于線积分卷积(Linear Integral Convolution, LIC)的矢量场可视化是目前矢量场可视化最常用的方法之一。其核心思想是白噪声叠加矢量场数据对矢量场运动信息进行可视化,能够很好的表示矢量场运动方向特性,且易于实现,因此对于矢量场的可视化具有重要意义。但同时该方法也存在不足:积分过程计算量大,需要对流线上的每一点进行积分卷积。在积分过程中即使采用最简单的欧拉积分方法,计算量也不容小觑。针对LIC算法计算量大的问题。文献[1]实现了基于平行坐标的LIC矢量场可视化,并根据netcdf格式数据的特点,提出了基于netcdf数据生成流线的方法。
针对LIC算法积分过程计算量大,计算速度慢的问题,文献[2]中利用GPU的多线程技术,基于cuda平台对LIC算法的计算部分实现并行化,获得了较高的加速比。此外,采用GPU实现LIC并行化的研究如文献[3]。然而基于GPU的并行化通常情况下需要对串行LIC代码进行重构,工作量较大,此外,还需要在内存与显存之间频繁拷贝数据。
文献[4]通过LIC算法模拟高分辨率的矢量场数据,在Windows集群环境下采用MPI实现了并行化,结果显示并行化后的算法能够大幅度缩短计算可视化时间,且与原来串行计算的图像结果一致。基于MPI的LIC的并行化具有良好的扩展性,能灵活的扩充与减少节点,但是该并行模式在通常情况下需要计算机集群,且并行加速比不仅依赖算法的优化,更加依赖计算集群底层网络的传输,即底层网络的带宽往往成为制约提高并行加速比的瓶颈。
随着计算机多核CPU技术的不断进步,共享存储器编程因其能充分发挥各个CPU核的潜力而成为最受青睐的编程模式之一。共享存储器编程的优点是通过共享内存实现线程之间的数据通信,减少网络之间的数据传输,各个线程通过加锁的方式实现对共享内存的读写。常用的共享存储器编程方式包括OpenMP,及调用操作系统API实现多线程等方式。本文将采用OpenMP方式实现线积分卷积的并行化。
1.线积分卷积
线积分卷积是通过跟踪矢量场数据,形成矢量,然后在矢量方向性卷积高斯白噪声从而达到矢量场数据的可视化,具体公式如下:
F(x)表示输出像素点的灰度值,T(s)表示高斯白噪声灰度图像值,k(s)为卷积核函数,积分长度为2L。对于输入的矢量场数据中的每一个点都需要计算流线,并依据上式输出积分卷积值作为输出结果。
2.OpenMP并行实现
本文主要对计算过程中的主要循环迭代加入OpenMP指令实现并行化。即对线积分卷积的迭代跟踪流线和卷积的过程通过加入OpenMP的并行指令 #pragma omp parallel 的方式实现该过程的并行化。
LIC算法的积分过程需要对每一个点沿着矢量方法进行积分计算,计算完成之后根据卷积核函数对高斯白噪声进行卷积计算,卷积完成之后更新图形对应位置的像素值。根据LIC算法的特点,可以设置矢量场数据及高斯白噪声数据为各个OpenMP线程所共享,这样可以减少线程之间的数据通信,减少并行开销。在OpenMP编译指令中加入“default(shared)”子句实现默认数据的共享,共享数据包括矢量场数据,高斯白噪声及输出图像数据。在OpenMP编译指令中加入“private”子句实现循环变量的私有。
3.结果分析
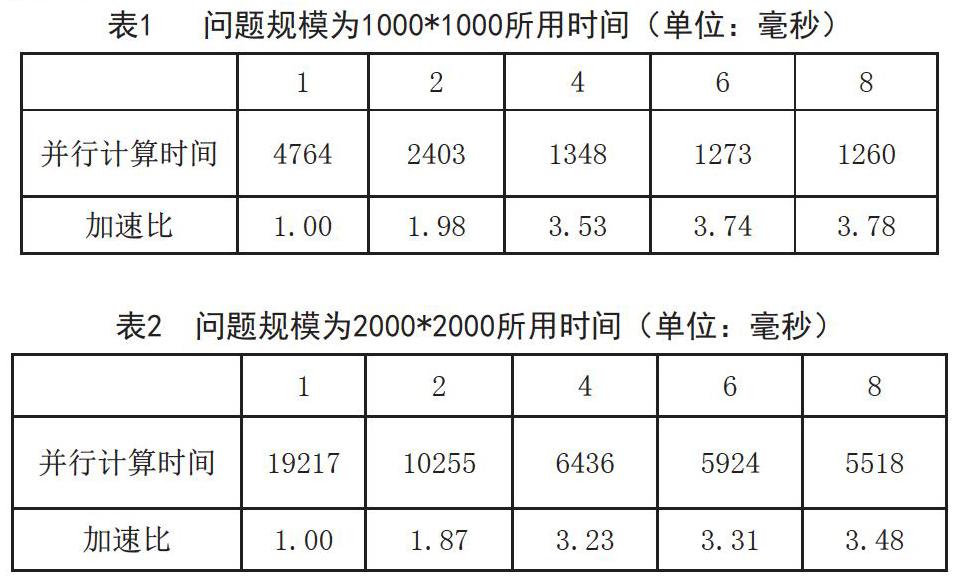
本文在一台8核CPU机器上实现线积分卷积的并行化。为了较好的衡量并行结果,本文设置的线积分卷积的并行计算规模分别为1000*1000、2000*2000。线积分卷积并行计算规模为1000*1000、2000*2000时计算时间分别为表1、表2。对应的加速比分别对应图1,、图2。
由以上2个表格的计算时间可以得到,随着CPU核数的增加,并行LIC算法的计算时间逐渐减少。加速比逐渐增加。在CPU核数较高(CPU核数为6、8时)时,两个问题规模计算时间大幅度减少,均能获得较高的加速比。在CPU核数为8,两种问题规模的加速比达分别达到3.78、3.48。然而在CPU增加过程中,加速比并没有线性增加,这主要是因为两个问题规模并行开销增加。对于OpenMP来说,并行开销主要包括线程的私有资源的分配、同步等开销增加。
综上,并行化后的LIC算法随着CPU核数的增加,运算时间逐渐降低,逐渐获得较高的加速比。随着并行开销的增加,并行化的效率逐渐降低。此外,负载均衡与否也是影响并行效率的一个重要因素。
参考文献
[1] 宋扬扬.基于平行坐标的线积分卷积矢量场可视化方法研究[D].秦皇岛:燕山大学.2016
[2] 吴占斌.基于 GPU 的二维矢量场可视化线性积分卷积方法的研究与实现[D] 青岛:中国海洋大学. 2011
[3]詹芳芳.线积分卷积二维矢量场可视化方法的研究和改进[D].北京:北京化工大学2013
[4]刘天佳.基Fast-LIC的矢量场并行可视化方法研究[D]. 哈尔滨:哈尔滨工程大学 2017
作者简介:符晓单(1985--),男,博士研究生,从事并行程序设计。
猜你喜欢
计算技术与自动化(2022年1期)2022-04-15
科技创新与应用(2020年4期)2020-02-25
上海师范大学学报·自然科学版(2019年5期)2019-12-13
小天使·二年级语数英综合(2019年4期)2019-10-06
学生天地·小学低年级版(2017年10期)2017-12-11
中国新通信(2017年9期)2017-05-27
中国新通信(2016年18期)2016-11-02
科技资讯(2016年7期)2016-05-14
计算机教育(2006年4期)2006-04-19
