
基于卷积神经网络的Android恶意软件检测技术研究
2020-07-10 01:12高杨晨
四川大学学报(自然科学版) 2020年4期
高杨晨, 方 勇, 刘 亮, 张 磊
(四川大学网络空间安全学院, 成都 610065)
1 引 言
根据2018年Android恶意软件专题报告[1]显示,2018年全年360互联网安全中心共截获新增Android恶意样本约434.2万个,平均每天新增约1.2万个,较两年前增长了近三倍. 同一种类的恶意软件变种繁多,并且加壳和自动化混淆加密等技术令查杀难度大为增加,对移动智能终端安全造成极大危害. 因此,对Android恶意软件的精准检测和家族分类显得尤为重要.
目前传统的Android恶意软件检测技术主要通过获取Android应用软件的权限、API以及字节码等动静态信息作为特征,然后使用传统的机器学习算法进行检测和分类. 近年来,图像识别技术发展迅速,相关技术也被应用到Android恶意软件检测和家族分类之中. 通过将Android应用软件的特征以图像的方式展示,然后利用图像特征对Android恶意软件进行检测和分类. 其中将文件转化成图像的方法被称为文件可视化技术. 文件可视化技术在进行Android恶意软件分类时具有较高的效率,因为其不需要对文件内容(包括文件的权限、类以及函数调用序列等)进行提取、总结和分析. 这样减少了Android应用加固对检测方法带来的影响. Kancherla等[2]提出将可执行文件转化成灰度图,然后使用小波变换和Gabor滤波器提取图像的纹理特征,最后使用SVM算法对特征进行分类. 分类准确率达95%. 事实证明,利用图像分类技术对恶意软件检测和分类是有效的.
近年来深度学习在自然语言处理、计算机视觉、语音识别和生物信息学等许多领域的应用中取得了不错的表现. 卷积神经网络(Convolutional Neural Networks, CNN)作为一种深度学习架构在处理图像方面非常成功. 随着深度学习(特别是CNN)在各种分类问题上的成功,我们认为深度学习算法对Android恶意软件进行分类可能会得到比传统机器学习算法(如支持向量机[3])更好的结果.
因此,基于上述提到的Android文件可视化技术和CNN在图像领域上的成果,本文将Android恶意软件进行可视化并通过CNN进行分类以此达到对Android恶意软件检测的目的. 根据文献[4]可知,属于同一类别的恶意软件在视觉上是相似的,这对CNN检测相关模式的能力是有利的. Llaurad′o[5]使用CNN对Windows恶意软件分类,但他们使用的是比较浅层的框架. 在计算机视觉领域当中,研究人员已经证明了更深层次的CNN架构有助于降低图像分类任务中的错误[6]. 同时Android恶意软件与Windows软件之间的差异可能会造成不同的结果. 我们在选择CNN框架时利用迁移学习的思想使用视觉研究者所提供的框架来进行Android恶意软件的检测和分类. 本文的贡献如下.
(1) 本文提出使用深度卷积神经网络对Android恶意软件可视化之后的灰度图进行分类. 本文方法将特征提取过程融合到卷积神经网络当中. 相比于独立提取图像特征之后再分类的方法,这样能够提高分类的效率. 此外,还能够通过修改网络的参数来提升分类的准确率.
(2) 本文在CNN框架选择时利用迁移学习的思想,因此使用的分类模型是通用的,相比于传统的方法具有较高的泛化性能. 现有传统方法可以达到很高的准确率,但是通常是针对特定的数据集进行定制的. 与此相反,本文提出的方法是数据独立的,而不依赖人为设定的特征.
(3) 本文方法在AMD[7](Android Malware Dataset) 和Drebin[8]两个数据集上进行了Android恶意软件检测和恶意家族分类的多个实验,表明本文提出的方法是可以适应不同数据集以及不同的分类需求.
2 相关工作
传统的Android恶意软件分类和检测方法主要分为静态、动态和混合分析三大类. 传统的静态分析方法通过利用APK文件静态特征进行分类,比如Schmidt[9]利用执行代码进行恶意软件分类,与此类似的有Zhou等[10]提出了DroidMoss,将Android应用软件的DEX文件反编译为Dalvik字节码,并通过操作码来计算应用软件的模糊散列值,结合应用软件的作者信息作为应用软件的“指纹”判定Android应用是否被重打包,以此判定Android应用的恶意性. 此类方法能够较为精准的判定Android恶意软件,但是受Android应用加壳与混淆的影响极大. 此外有如Aung[11]和Utku[12]利用Android权限信息进行恶意软件分类,此类方法虽然不受加壳和混淆的影响,但是权限特征区别度较小,分类精准度不高. Sahs等[13]使用静态特征中的控制流图和Android软件的权限作为特征,然后使用SVM机器学习算法进行分类. 总的来说,静态特征对Android恶意软件的分类具有比较明显的效果,但是受到安全策略的限制. 动态分析方法弥补了静态分析方法的一些不足. Shabtai等[14]提出Andromaly,通过持续监听移动设备的不同特征和事件,使用机器学习算法对收集来的数据进行分类,从而实现Android恶意软件的分类. 该方法需要充足的时间来收集特征和事件,否则无法实现有效的检测. Taniya等[15]应用运行时提取收集的系统调用函数进行聚合和分析,以此达到分类的效果. 动态分析手段虽然能够绕过应用的防护措施,但是对时间和空间花销较大. 为了结合静态分析和动态分析的优势,Michael等[16]提出Mobile-SandBox,该系统提出以静态分析的结果用于指导动态分析最终以实现分类. 但是可用性和兼容性上面还有待改进. 为解决上述传统分析方法的问题,本文提出了一种将Android应用文件转化成灰度图像并使用CNN深度学习框架进行分类的方法.
本文方法首先将Android应用文件转化成灰度图像;然后基于迁移学习的思想选择视觉领域中被广泛使用的VGG-16[6]为作为CNN分类器的原型框架;最终根据实际传入的图像特征以及分类的需求对深度卷积神经网络进行微调以此实现对Android恶意软件的分类与检测. 将Android应用文件转化成灰度图像是通过字节码与像素之间的对应关系来实现的. 由于转化过程直接对字节码进行操作,可以克服Android应用混淆和加固保护技术对分析带来的影响,降低了分析的难度并且提升了分析的效率. 分类器使用迁移学习的思想构建,分类器与样本集之间是相互独立的,这样有效避免了分类方法只针对特定样本集有效的情况. 迁移学习选择的是经过其他研究人员大量测试与研究的框架,对训练样本需求量较少,因此也很适合样本集数量不够大的情况.
3 背 景
卷积神经网络(CNN)是受生物学启发的前馈神经网络,特别是受动物视觉皮层[17]的组织影响. CNN是目前最先进的图像分类神经网络体系结构之一. CNN是由具有可学习权重和偏差的神经元组成. CNN主要由卷积层、池化层以及全连接层三部分组成[18].通常神经网络当中存在多个卷积层,多个卷积层依次对图像进行卷积运算提取图像的边缘、颜色和形状等信息. 池化层负责对卷积层产生的数据进行下采样(即降低输入层的空间分辨率),以减少处理时间,使计算资源能够处理更大的数据规模. 全连接层对卷积层和池化层生成的输出进行分类. 这一层的每一个神经元都与前一层的每一个神经元相连. 全连接层可以整合卷积层或者池化层中具有类别区分性的局部信息.
4 方法简介
4.1 Android恶意软件可视化
Android应用软件是压缩包文件,其中包含了整个Android应用软件的资源文件、配置文件、签名文件和执行文件等所有内容. Android是针对嵌入式设备而设计的系统,其所有Java代码都被存储在后缀为“.dex”的文件中,这个文件被称为DEX文件. DEX文件就是Android系统的执行文件,其包含了Android应用的大量特征.
Android恶意软件的开发者通常会通过原来的代码开发出新的恶意软件. 如果将Android恶意软件表示为一个图像,那么这些代码的变化可以很容易地在图像中被察觉到. 本文将DEX文件可视化为灰度图像. 图1展示了Android应用程序转换为灰度图像的过程.

图1 Android应用程序到灰度图像的转化过程Fig.1 Android application converts to grayscale image process
首先,从Android应用程序当中提取出DEX文件,DEX文件是一个二进制文件;然后从DEX文件当中读入一个8位二进制数组成的向量;接着将该向量的每个分量的二进制值转换为其等效的无符号十进制值(例如,二进制中[00000000]的十进制值为[0],[11111111]的十进制值为[255]);最后,将得到的十进制向量重构为二维矩阵,并将其可视化为灰度图像. 二维矩阵的宽度和高度(即图像的空间分辨率)主要取决于DEX文件的大小. 判定标准如表1所示.

表1 矩阵宽度判定标准
4.2 模型概览
本文使用卷积神经网络(CNN)对Android恶意软件分类,将VGG-16作为分类模型的原始架构. 网络输入是一个Android恶意软件的灰度图像,该图像是长为M宽为N的三通道灰度图. 由于CNN卷积神经网络要求输入图像的尺度相同,因此输入神经网络之前需要对不同大小的灰度图像进行插值式采样转化成相同大小的图像. 神经网络输出是对各个Android恶意软件类别的预测. 在预测Android恶意软件类别时会选择得分最高的家族类别作为预测结果. 本文选择的CNN的详细分类架构如图2所示.

图2 CNN的分类架构图Fig.2 The classification structure of CNN
4.3 学习过程
在深度学习的多分类问题中softmax经常被用作分类器的输出,它将神经网络的输出映射到(0,1)区间内,并且这些值的累加和为1. 这些输出可以看成概率分布来理解,然后选取概率最高的类别作为预测结果,从而来进行多分类. 例如一个神经网络的输出层具有5个节点,其输出的结果为[3.2,6.5,5.6,4.1,3.5],经过softmax后的输出为[0.023,0.631,0.257,0.057,0.031],此时最大项依然为第二项. softmax的公式如下.
(1)
其中,yi表示样本y在第i类别的得分;yj表示样本y从类别1到n类别的输出.
深度学习网络模型的学习,可以通过优化损失来进行,而经常使用损失函数来进行优化. 由于本文提出的模型使用softmax作为输出,因此与之对应的损失函数是softmax损失函数. softmax的损失函数使用交叉熵损失(cross-entropy loss). 交叉熵损失只跟样本的标记类别相关,根据该标记类别的概率计算损失值,而不考虑标记类别之外的其他类别. 因此,其损失函数可以表示为如下的形式.
(2)
其中,L表示某个样本进过模型之后的交叉熵损失;yi表示样本被分到正确类别的输出;yj表示样本y从类别1到n类别的输出.
每次计算损失之后,会根据损失更新模型的参数. 更新模型参数的过程就是学习的过程. 本次实验模型的参数采用随机梯度下降法(Stochastic Gradient Descent, SGD)进行学习,这种方法能够尽快让模型收敛.
5 实验结果和分析
5.1 样本集介绍
目前Android恶意软件相关论文中实验数据集都是研究人员自行收集的样本集,而通常Android恶意样本集是从Drebin,AMD和Android Malware Genome Project三大样本集中获取. 但是目前Android Malware Genome Project样本集已经暂停开放. 因此,我们考虑到与相关研究方法的对比以及后续的工作,本文实验的Android恶意样本从Drebin和AMD两个样本集中获取.
(1) Drebin样本集.Drebin 样本集包含了2010年8月到2012年10月期间收集的来自179个Android恶意软件家族的5 560个样本.
(2) AMD样本集.AMD样本集因为其较大的样本数量以及家族分类明确的优点被广泛使用. AMD总共包含了从2010年到2016年收集的24 553个样本,其中共有71个Android恶意软件家族以及135个变种. 该数据集提供了当前Android恶意软件的最新情况,并且对外开放.
5.2 Android恶意软件家族分类
Android 恶意软件家族分类的研究一直在进行,但目前仍缺少通用的公开实验数据集. 图像分类研究人员可以从各种比赛网站和数据库中下载相同的数据集进行客观的实验对比. 但是Android恶意软件分类实验中没有类似于图像分类的共用的数据集. 因此只能从常用的Android恶意样本集中进行提取来构造实验数据集,5.1节中介绍了常用的Android 恶意样本集.
Drebin样本集中Android恶意软件家族种类繁多,但是每个家族样本数量较少,不适合作为家族分类的样本集. AMD总共包括24 553个样本和71个Android恶意软件家族以及135个变种. 其部分家族的Android恶意样本较多适合作为Android恶意软件家族的分类. 但是直接使用该样本仍然存在一些问题需要对AMD样本集进行筛选. 通过对数据集的分析和统计,虽然有71个恶意家族,但是大多数恶意家族的样本量都较少,因此达不到分类器的要求. 针对这个问题,本文从71个Android恶意家族当中选取了样本数量超过200个的15个家族的样本作为数据集. 经过统计样本合计13 432个,其中包括变种类别合计51个. 所选样本的具体情况如表2所示.
在获取到Android恶意家族数据集之后,首先利用4.1节中提到的方法对13 432个Android 恶意软件进行可视化为灰度图像. 图3是15个Android恶意软件家族部分样本的可视化结果. 从图3中可以看出,属于同一家族的Android恶意软件变种通常有相似的纹理(即视觉外观).

表2 家族分类AMD数据集情况
在本文实验中,对每个家族随机抽取其中的80%Android恶意软件样本构成训练集,剩下的20%组成测试集. 最终训练集样本是10 745个和测试集样本是2 687个.
本文实验是在64位Windows10上进行. 电脑配置选择CPU是Intel(R) Xeon(R) E3-1230 (3.30 GHz)和GPU是NVIDIA GeForce GTX 1080(8 GB内存). 实验深度学习框架使用Pytorch库来实现,python版本为3.6.
初始学习率设置为0.001. 使用VGG-16权值初始化CNN网络中的参数. 由于VGG-16原始的输出类别是1 000,但是本实验的输出类别是15,因此需要对输出类别进行修改. 我们在实验过程中将Epoches设置为30,Batch设置为32. Epoch指的是训练集的全部数据对模型进行一次完整训练,被称之为一代训练. 使用训练集中的部分样本对模型权重进行一次反向传播的参数更新被称为一次训练,其中这一小部分样本被称为一批数据,这一批数据指的就是Batch.
目前基于图像的Android恶意软件家族分类如文献[2,12,19] 中的方法. 通常先将Android应用程序转化成灰度图像,然后利用GIST算法提取灰度图的纹理特征并利用分类器对特征进行分类. 常用的分类器包括K邻近算法(k-NearestNeighbor, KNN),支持向量机(Support Vector Machine, SVM)以及随机森林(Random Forests, RF)等分类器. 随着深度学习被广泛使用,文献[20]将获取到的纹理特征使用BP神经网络进行分类. 上述方法都在各自的样本集上获得了不错的分类效果,为了使得本文提出的方法能够更直观地与现有的方法进行对比,本文在AMD数据集上复现了以上方法. 相比于文献[2,12,19-20] 中的方法中所提到的使用GIST算法获取纹理特征,本文直接将灰度图输入卷积神经网络当中,利用卷积网络对灰度图像进行特征提取. 各种方法的分类结果如表3所示.

图3 Android恶意软件家族部分样本可视化结果Fig.3 Visualization results of partial samples of Android malware family

表3 Android恶意软件家族分类结果
从表3可知,不同分类方法在AMD样本上的分类效果有所不同. 传统机器学习当中,GIST+SVM具有最高的分类准确率92.13%;然而,利用BP神经网络的分类方法取得更高的分类效果,其分类准确率达到94.78%;本文方法具有更高的分类准确率,达到了97.36%.
5.3 Android恶意软件检测
由于本文提到的方法是基于迁移学习,因此需要考虑到在不同的数据集上的分类效果.因此,我们选择目前最先进的 Android恶意软件检测技术与本文方法进行对比. 本文选择了文献[21-24]中的方法来进行对比分析,这些方法在实验过程中使用的数据集都是来自Drebin样本或者AMD样本集. 我们在相同的数据集上进行实验,能够更直观的比较方法之间的差异. 5.1节介绍AMD样本集拥有来自71个Android恶意家族的24 553个样本. Drebin数据集包含来自179个不同Android恶意软件家族的5 560个样本. 用于对比的方法是Android恶意软件检测方法及解决Android恶意软件与正常软件的二分类问题,因此,我们在实验过程中,除了已经拥有的恶意软件,还需要正常软件. 我们通过从Google应用市场中进行获取正常样本集,然后,分别构造两个数据集Drebin数据集(恶意样本:5 400个,正常样本:5 400个)和AMD数据集(恶意样本:24 000个,正常样本:22 000个). 在实验过程中,将样本的80%作为训练集,剩余的20%作为测试集,数据集情况如表4.

表4 Android恶意软件检测数据集情况
本次实验环境与5.2节相同. 卷积神经网络的初始学习率设置为0.003. 使用VGG-16权值初始化CNN网络中的参数. 由于Android恶意软件检测是二分类问题,因此在VGG-16的输出层将1 000调整为2. 本次实验过程中Epoches设置为30,Batch设置为64. 本次实验除了与文献[19-22]方法的实验结果进行对比之外,还将5.2节中实现的GIST+SVM和GIST+BP方法加入到实验对比当中. 表5为实验的结果.
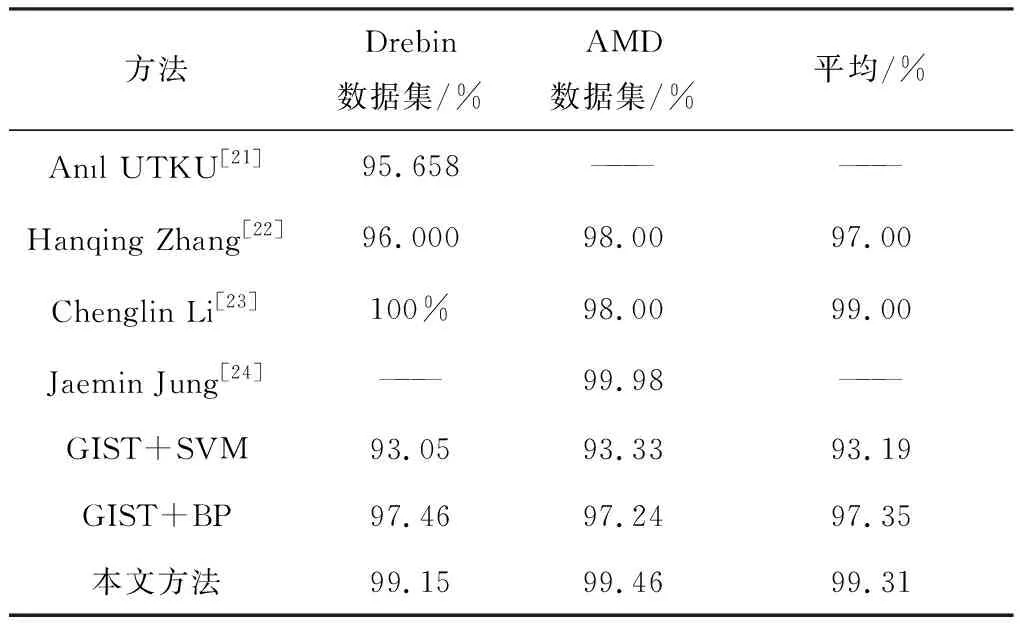
表5 Android恶意软件检测结果
从表5可知,在Drebin数据集上面分类精确度仅次于Chenglin Li[23]所提出的方法,其准确率达到了100%,而本文方法达到了99.15%. 而在AMD数据集上,准确率也仅次于Jung等[24]所提出的方法,他们提出的方法准确率为99.98%. 而本文提出的方法达到了99.46%,仅比文献[24]中提到的方法准确率少了0.52%. 虽然本文提出的方法在每个样本集上都不是分类准确率最高的. 但是通过实验的纵向对比,文献[23-24]方法虽然在某一数据集上拥有最高的分类准确率甚至接近100%,但是在另一个数据集上的实验效果不是最好的. 然而,本文方法能够适应不同的数据集,并且每个数据集上的分类准确率都达到了99%以上,并且是拥有两个数据集实验的方法中平均准确率最高的.
6 结 论
在移动互联的今天,Android恶意软件正日益对人们生产和生活构成严重的安全威胁. 对Android恶意软件的检测及分类是非常必要的. 为此,本文提出了一种基于卷积神经网络(CNN)的Android恶意软件检测与分类的方法. 本方法首先将Android恶意软件样本转换成灰度图像,然后训练CNN框架对灰度图像进行分类以此达到对Android恶意软件的检测和分类的目的. 为了验证方法的可行性,分别在Android恶意软件家族分类以及Android恶意软件检测两个方面进行了实验. 在家族分类实验当中,本文方法与传统的一些方法在AMD样本集上进行比较,准确率达到了97.36%,并且高于其他的方法. 在检测实验当中,本文方法在Drebin数据集和AMD数据集上的分类准确率都达到了99%以上,拥有较高的泛化性能. 因此,本文方法在解决Android恶意软件家族分类和检测上拥有较高的准确率和泛化性能.
虽然,本文方法拥有不错的效果,但是仍存在不足的地方. 本次实验将Android恶意软件转化成灰度图像. 灰度图像所包含的颜色特征较少,而CNN是能够处理彩色图像的. 因此下一步的研究是将Android恶意软件转化成彩色图片并且迁移学习更好的框架以此继续提高分类准确率以及方法的稳定性.
猜你喜欢
北京航空航天大学学报(2022年6期)2022-07-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
集装箱化(2021年1期)2021-04-12
农业科技与信息(2021年2期)2021-03-27
天津医科大学学报(2021年1期)2021-01-26
健康体检与管理(2021年10期)2021-01-03
中国信息技术教育(2020年2期)2020-02-02
